아래는 요청하신 대로 목차 없이 정리한 내용입니다.
🏖️ Retrieval-Augmented Generation(RAG) 개요
Retrieval-Augmented Generation(RAG)은 자연어 처리(NLP) 분야에서의 혁신적인 기술로, 기존의 언어 모델의 한계를 넘어서 정보 검색과 생성을 통합하는 방법론이다. RAG는 풍부한 정보를 담고 있는 대규모 문서 데이터베이스에서 관련 정보를 검색하고, 이를 통해 언어 모델이 더 정확하고 상세한 답변을 생성할 수 있게 한다.
예를 들어, 최신 뉴스 이벤트나 특정 분야의 전문 지식과 같은 주제에 대해 물어보면, RAG는 관련 문서를 찾아 그 내용을 바탕으로 답변을 구성한다.
RAG의 8단계 프로세스
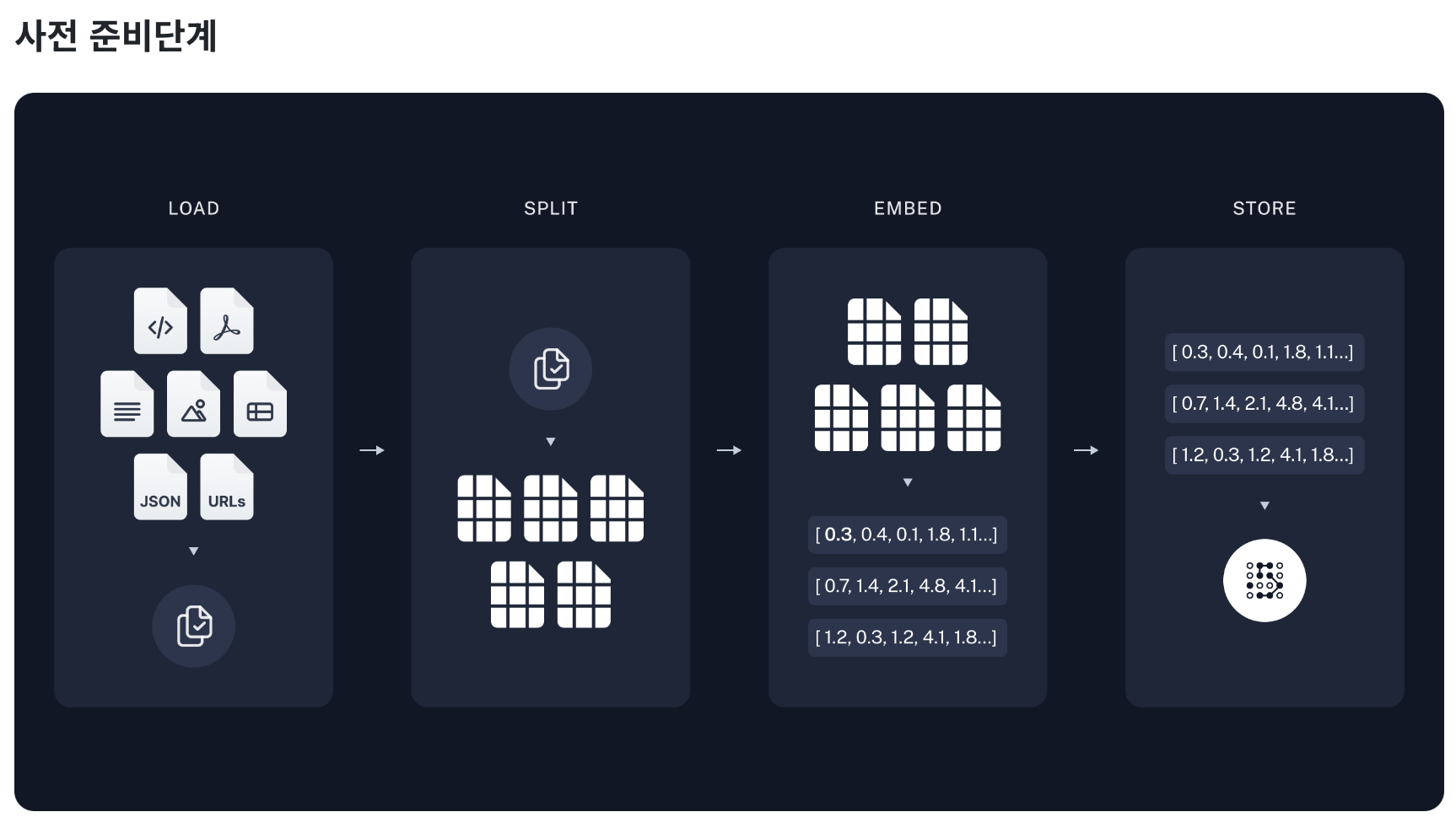
사전 준비단계
도큐먼트 로드 (Document Loader)
- 이 단계에서는 외부 데이터 소스에서 필요한 문서를 로드하고 초기 처리를 한다.
- 마치 책을 여러 권 챙겨 도서관에서 공부하는 것과 비슷하다. 학생이 공부하기 전에 필요한 책들을 책장에서 골라오는 과정이다.
텍스트 분할 (Text Splitter)
- 로드된 문서를 처리 가능한 작은 단위로 분할한다.
- 큰 책을 챕터별로 나누는 것과 유사하다.
임베딩 (Embedding)
- 각 문서 또는 문서의 일부를 벡터 형태로 변환하여, 문서의 의미를 수치화한다.
- 이는 책의 내용을 요약하여 핵심 키워드로 표현하는 것과 비슷하다.
벡터스토어(Vector Store) 저장
- 임베딩된 벡터들을 데이터베이스에 저장한다.
- 이는 요약된 키워드를 색인화하여 나중에 빠르게 찾을 수 있도록 하는 과정이다.
런타임(RunTime) 단계
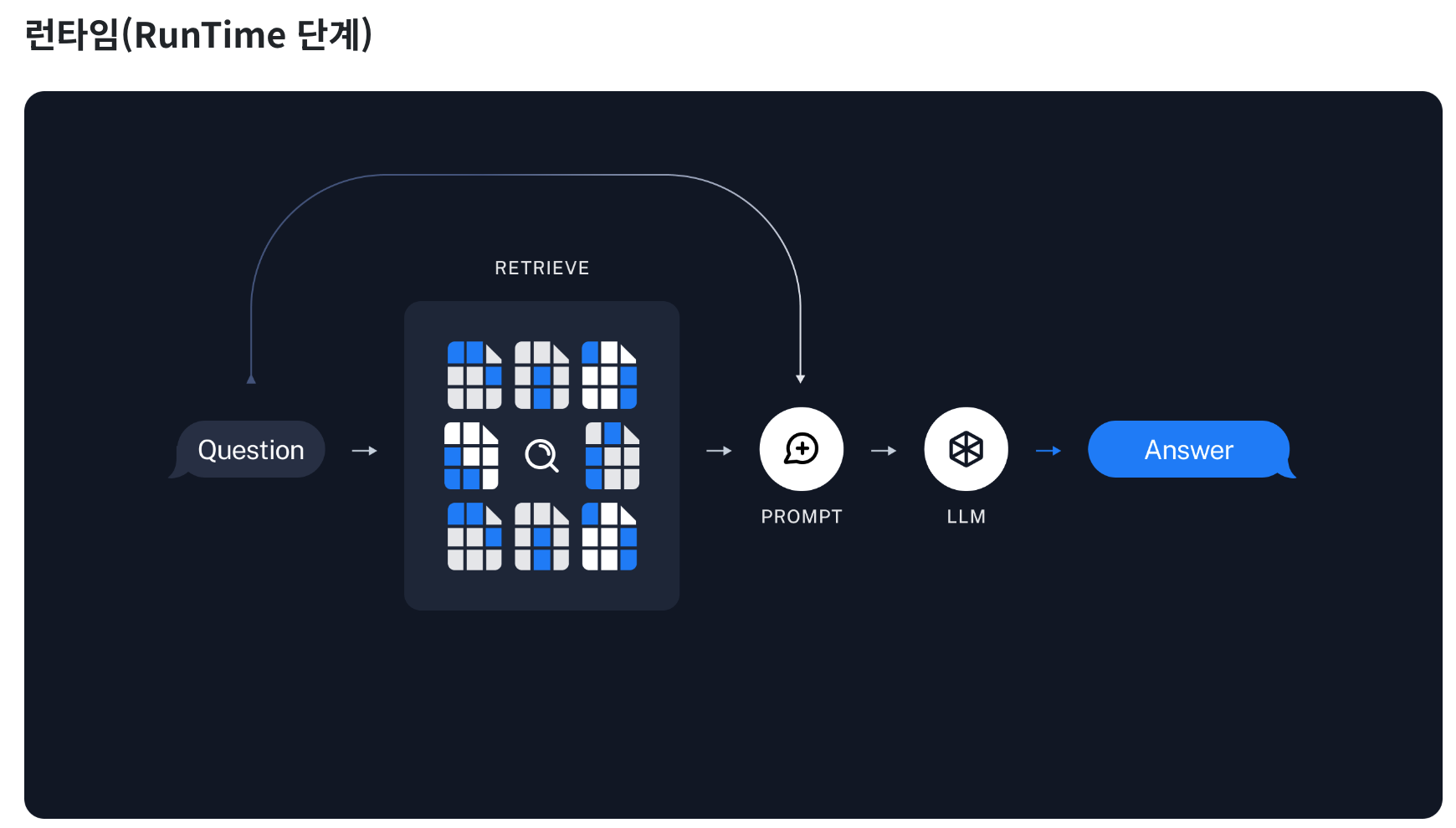
검색기 (Retriever)
- 질문이 주어지면, 이와 관련된 벡터를 벡터 데이터베이스에서 검색한다.
- 질문에 가장 잘 맞는 책의 챕터를 찾는 것과 유사하다.
프롬프트 (Prompt)
- 검색된 정보를 바탕으로 언어 모델을 위한 질문을 구성한다.
- 이는 정보를 바탕으로 어떻게 질문할지 결정하는 과정이다.
LLM (Large Language Model)
- 구성된 프롬프트를 사용하여 언어 모델이 답변을 생성한다.
- 수집된 정보를 바탕으로 과제나 보고서를 작성하는 학생과 같다.
체인(Chain) 생성
- 이전의 모든 과정을 하나의 파이프라인으로 묶어주는 체인(Chain)을 생성한다.
🏖️ PDF 문서 기반 QA(Question-Answer)
RAG 기본 구조 이해하기
RAG(Question-Answer) 프로세스는 크게 두 가지 단계로 나뉩니다. 첫 번째는 사전작업(Pre-processing)이고, 두 번째는 RAG 수행(RunTime)입니다. 이 두 가지 단계를 통해 문서를 처리하고, 질문에 대한 답변을 생성합니다.


1. 사전작업(Pre-processing) - 1~4 단계
사전 작업 단계에서는 데이터 소스를 Vector DB (저장소)에 문서를 로드하고, 분할, 임베딩, 저장하는 4단계를 진행합니다.
1단계 문서로드(Document Load)
- 문서 내용을 불러옵니다.
2단계 분할(Text Split)
- 문서를 특정 기준(Chunk)으로 분할합니다.
3단계 임베딩(Embedding)
- 분할된(Chunk)을 임베딩하여 저장합니다.
4단계 벡터DB 저장
- 임베딩된 Chunk를 DB에 저장합니다.
2. RAG 수행(RunTime) - 5~8 단계
런타임 단계에서는 사전 작업에서 준비된 데이터를 바탕으로 질문에 대한 답변을 생성합니다.
5단계 검색기(Retriever)
- 쿼리(Query)를 바탕으로 DB에서 검색하여 결과를 가져오기 위해 리트리버를 정의합니다.
- 리트리버는 검색 알고리즘이며, Dense(유사도 기반 검색)와 Sparse(키워드 기반 검색) 리트리버로 나뉩니다.
6단계 프롬프트(Prompt)
- RAG를 수행하기 위한 프롬프트를 생성합니다.
- 프롬프트의 context에는 문서에서 검색된 내용이 입력됩니다. 프롬프트 엔지니어링을 통해 답변의 형식을 지정할 수 있습니다.
7단계 LLM(Large Language Model)
- 모델을 정의합니다. (예: GPT-3.5, GPT-4, Claude 등)
8단계 체인(Chain) 생성
- 프롬프트 - LLM - 출력에 이르는 체인을 생성합니다.
실습에 활용한 문서
- 저자: 유재흥(AI정책연구실 책임연구원), 이지수(AI정책연구실 위촉연구원)
- 출처: 소프트웨어정책연구소(SPRi) - 2023년 12월호
- 링크: https://spri.kr/posts/view/23669
- 파일명: SPRI_AI_Brief_2023년12월호_F.pdf
실습을 위해 다운로드 받은 파일을 data 폴더로 복사해 주시기 바랍니다.
환경설정
API KEY를 설정합니다.
# API 키를 환경변수로 관리하기 위한 설정 파일
from dotenv import load_dotenv
# API 키 정보 로드
load_dotenv()
TrueLangChain으로 구축한 애플리케이션은 여러 단계에 걸쳐 LLM 호출을 여러 번 사용하게 됩니다. 이러한 애플리케이션이 점점 더 복잡해짐에 따라, 체인이나 에이전트 내부에서 정확히 무슨 일이 일어나고 있는지 조사할 수 있는 능력이 매우 중요해집니다. 이를 위한 최선의 방법은 LangSmith를 사용하는 것입니다.
LangSmith가 필수는 아니지만, 유용합니다. LangSmith를 사용하고 싶다면, 위의 링크에서 가입한 후, 로깅 추적을 시작하기 위해 환경 변수를 설정해야 합니다.
# LangSmith 추적을 설정합니다. https://smith.langchain.com
# !pip install -qU langchain-teddynote
from langchain_teddynote import logging
# 프로젝트 이름을 입력합니다.
logging.langsmith("CH12-RAG")LangSmith 추적을 시작합니다.
[프로젝트명]
- CH12-RAG
RAG 기본 파이프라인(1~8단계)
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# 단계 1: 문서 로드(Load Documents)
loader = PyMuPDFLoader("data/SPRI_AI_Brief_2023년12월호_F.pdf")
docs = loader.load()
print(f"문서의 페이지수: {len(docs)}")
# 단계 2: 문서 분할(Split Documents)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
split_documents = text_splitter.split_documents(docs)
print(f"분할된 청크의수: {len(split_documents)}")
# 단계 3: 임베딩(Embedding) 생성
embeddings = OpenAIEmbeddings()
# 단계 4: DB 생성(Create DB) 및 저장
# 벡터스토어를 생성합니다.
vectorstore = FAISS.from_documents(documents=split_documents, embedding=embeddings)
# 단계 5: 검색기(Retriever) 생성
# 문서에 포함되어 있는 정보를 검색하고 생성합니다.
retriever = vectorstore.as_retriever()
# 단계 6: 프롬프트 생성(Create Prompt)
# 프롬프트를 생성합니다.
prompt = PromptTemplate.from_template(
"""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Answer in Korean.
#Question:
{question}
#Context:
{context}
#Answer:"""
)
# 단계 7: 언어모델(LLM) 생성
# 모델(LLM) 을 생성합니다.
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# 단계 8: 체인(Chain) 생성
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 체인 실행(Run Chain)
# 문서에 대한 질의를 입력하고, 답변을 출력합니다.
question = "삼성전자가 자체 개발한 AI 의 이름은?"
response = chain.invoke(question)
print(response)실행 결과
삼성전자가 자체 개발한 AI의 이름은 '삼성 가우스'입니다.이 코드는 문서에서 삼성전자가 자체 개발한 AI의 이름을 추출하는 예제입니다.
🏖️ 네이버 뉴스기사 QA(Question-Answer)
RAG 기본 구조 이해하기
RAG(Question-Answer) 프로세스는 크게 두 가지 단계로 나뉩니다. 첫 번째는 사전작업(Pre-processing)이고, 두 번째는 RAG 수행(RunTime)입니다. 이 두 가지 단계를 통해 문서를 처리하고, 질문에 대한 답변을 생성합니다.
1. 사전작업(Pre-processing) - 1~4 단계
사전 작업 단계에서는 데이터 소스를 Vector DB (저장소)에 문서를 로드하고, 분할, 임베딩, 저장하는 4단계를 진행합니다.
1단계 문서로드(Document Load)
- 문서 내용을 불러옵니다.
2단계 분할(Text Split)
- 문서를 특정 기준(Chunk)으로 분할합니다.
3단계 임베딩(Embedding)
- 분할된(Chunk)을 임베딩하여 저장합니다.
4단계 벡터DB 저장
- 임베딩된 Chunk를 DB에 저장합니다.
2. RAG 수행(RunTime) - 5~8 단계
런타임 단계에서는 사전 작업에서 준비된 데이터를 바탕으로 질문에 대한 답변을 생성합니다.
5단계 검색기(Retriever)
- 쿼리(Query)를 바탕으로 DB에서 검색하여 결과를 가져오기 위해 리트리버를 정의합니다.
- 리트리버는 검색 알고리즘이며, Dense(유사도 기반 검색: FAISS, DPR)와 Sparse(키워드 기반 검색: BM25, TF-IDF) 리트리버로 나뉩니다.
6단계 프롬프트(Prompt)
- RAG를 수행하기 위한 프롬프트를 생성합니다.
- 프롬프트의 context에는 문서에서 검색된 내용이 입력됩니다. 프롬프트 엔지니어링을 통해 답변의 형식을 지정할 수 있습니다.
7단계 LLM(Large Language Model)
- 모델을 정의합니다. (예: GPT-3.5, GPT-4, Claude 등)
8단계 체인(Chain) 생성
- 프롬프트 - LLM - 출력에 이르는 체인을 생성합니다.
환경설정
API KEY를 설정합니다.
# API 키를 환경변수로 관리하기 위한 설정 파일
from dotenv import load_dotenv
# API 키 정보 로드
load_dotenv()
TrueLangChain으로 구축한 애플리케이션은 여러 단계에 걸쳐 LLM 호출을 여러 번 사용하게 됩니다. 이러한 애플리케이션이 점점 더 복잡해짐에 따라, 체인이나 에이전트 내부에서 정확히 무슨 일이 일어나고 있는지 조사할 수 있는 능력이 매우 중요해집니다. 이를 위한 최선의 방법은 LangSmith를 사용하는 것입니다.
LangSmith가 필수는 아니지만, 유용합니다. LangSmith를 사용하고 싶다면, 위의 링크에서 가입한 후, 로깅 추적을 시작하기 위해 환경 변수를 설정해야 합니다.
# LangSmith 추적을 설정합니다. https://smith.langchain.com
# !pip install -qU langchain-teddynote
from langchain_teddynote import logging
# 프로젝트 이름을 입력합니다.
logging.langsmith("CH12-RAG")LangSmith 추적을 시작합니다.
[프로젝트명]
- CH12-RAG
네이버 뉴스 기반 QA(Question-Answering) 챗봇
이번 튜토리얼에서는 네이버 뉴스기사의 내용을 바탕으로 질문에 답할 수 있는 뉴스기사 QA 앱을 구축합니다. 이 가이드에서는 OpenAI 챗 모델과 임베딩, 그리고 Chroma 벡터 스토어를 사용할 것입니다.
주요 라이브러리
- bs4: 웹 페이지를 파싱하기 위한 라이브러리.
- langchain: 텍스트 분할, 문서 로딩, 벡터 저장, 출력 파싱, 실행 가능한 패스스루 등을 제공하는 AI 관련 라이브러리.
- langchain_openai: OpenAI의 챗봇 및 임베딩 기능을 사용할 수 있는 모듈.
import bs4
from langchain import hub
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings웹 페이지 로드 및 텍스트 분할
WebBaseLoader를 사용하여 뉴스 기사 페이지를 로드하고, 텍스트를 청크로 나누어 인덱싱합니다.
loader = WebBaseLoader(
web_paths=("https://n.news.naver.com/article/437/0000378416",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
"div",
attrs={"class": ["newsct_article _article_body", "media_end_head_title"]},
)
),
)
docs = loader.load()
print(f"문서의 수: {len(docs)}")텍스트 분할 및 벡터스토어 생성
RecursiveCharacterTextSplitter를 사용하여 문서를 지정된 크기의 청크로 나눕니다. 그리고 FAISS 벡터스토어를 생성합니다.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
splits = text_splitter.split_documents(docs)
vectorstore = FAISS.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()프롬프트 및 체인 생성
PromptTemplate을 사용하여 질문-답변 형식의 프롬프트를 생성하고, 이를 기반으로 LLM 체인을 구성합니다.
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다. 당신의 임무는 주어진 문맥(context) 에서 주어진 질문(question) 에 답하는 것입니다.
검색된 다음 문맥(context) 을 사용하여 질문(question) 에 답하세요. 만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.
한글로 답변해 주세요. 단, 기술적인 용어나 이름은 번역하지 않고 그대로 사용해 주세요.
#Question:
{question}
#Context:
{context}
#Answer:"""
)
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# 체인을 생성합니다.
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)실행 예제
다양한 질문에 대한 답변을 생성하고 출력합니다.
from langchain_teddynote.messages import stream_response
answer = rag_chain.stream("부영그룹의 출산 장려 정책에 대해 설명해주세요.")
stream_response(answer)실행 결과
부영그룹의 출산 장려 정책은 매우 파격적입니다. 2021년 이후 태어난 직원 자녀에게 1억원씩, 총 70억원을 지원하며, 연년생과 쌍둥이 자녀가 있는 경우 총 2억원을 받을 수 있습니다. 또한, 셋째 아이를 낳는 경우 국민주택을 제공하겠다는 계획도 있습니다. 이와 같은 출산장려금은 직원들의 세금 부담을 고려해 정부가 면세해달라는 제안도 나왔습니다.위 코드 예제는 네이버 뉴스 기사에서 특정 정보를 추출하고, 그 정보를 바탕으로 질문에 대한 답변을 생성하는 과정을 보여줍니다.
🏖️ RAG 의 기능별 다양한 모듈 활용기
LangChain의 RAG 파헤치기
RAG (Retrieval-Augmented Generation)는 질문에 대한 답변을 생성하기 위해, 질문에 맞는 데이터를 검색하고, 그 데이터를 바탕으로 언어 모델이 응답을 생성하는 과정입니다. 이 과정에서 LangChain의 다양한 모듈을 활용할 수 있습니다.
1. 질문 처리
데이터 소스 연결
- 사용자의 질문에 대한 답변을 찾기 위해 다양한 텍스트 데이터 소스에 연결해야 합니다.
- LangChain은 여러 데이터 소스와의 연결을 간편하게 설정할 수 있도록 돕습니다.
데이터 인덱싱 및 검색
- 데이터 소스에서 관련 정보를 효율적으로 찾기 위해 데이터는 인덱싱되어야 합니다.
- LangChain은 인덱싱 과정을 자동화하고, 사용자의 질문과 관련된 데이터를 검색하는 데 필요한 도구를 제공합니다.
2. 답변 생성
답변 생성 모델
- LangChain은 고급 자연어 처리(NLP) 모델을 사용하여 검색된 데이터로부터 답변을 생성할 수 있는 기능을 제공합니다.
- 사용자의 질문과 검색된 데이터를 입력으로 받아, 적절한 답변을 생성합니다.
🏖️ RAG 아키텍처
RAG 아키텍처는 두 가지 주요 구성 요소로 나뉩니다:
인덱싱
- 로드: 데이터를 로드하고 인덱싱합니다.
- 분할: Text Splitters를 사용해 큰 문서를 작은 청크로 나눕니다.
- 저장: 임베딩된 데이터는 VectorStore에 저장됩니다.
검색 및 생성
- 검색: 사용자 입력을 바탕으로 Retriever를 사용해 관련 데이터를 검색합니다.
- 생성: LLM이 질문과 검색된 데이터를 포함한 프롬프트를 사용하여 답변을 생성합니다.
실습에 활용한 문서
문서: 소프트웨어정책연구소(SPRi) - 2023년 12월호
저자: 유재흥(AI정책연구실 책임연구원), 이지수(AI정책연구실 위촉연구원)
링크: SPRI AI Brief 2023년 12월호
파일명: SPRI_AI_Brief_2023년12월호_F.pdf
환경설정
API KEY를 설정하고, LangSmith를 사용해 LLM 호출을 추적할 수 있습니다.
import os
from dotenv import load_dotenv
# API 키 정보 로드
load_dotenv()
# LangSmith 설정
os.environ["LANGCHAIN_PROJECT"] = "RAG TUTORIAL"🏖️ 모듈별로 자세히 살펴보기
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader, FAISS, Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings단계 1: 문서 로드(Load Documents)
- 문서의 내용을 로드하고, 청크로 나눕니다.
- 웹 페이지에서 텍스트를 추출할 때는
WebBaseLoader를 사용합니다.
url = "https://n.news.naver.com/article/437/0000378416"
loader = WebBaseLoader(web_paths=(url,), bs_kwargs=dict(
parse_only=bs4.SoupStrainer("div", attrs={"class": ["newsct_article _article_body", "media_end_head_title"]})
))
docs = loader.load()단계 2: 문서 분할(Split Documents)
RecursiveCharacterTextSplitter를 사용해 문서를 분할합니다.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
splits = text_splitter.split_documents(docs)단계 3: 임베딩 & 벡터스토어 생성(Create Vectorstore)
- OpenAI의 임베딩 모델을 사용하여 FAISS 벡터스토어를 생성합니다.
vectorstore = FAISS.from_documents(documents=splits, embedding=OpenAIEmbeddings())단계 4: 검색(Search)
vectorstore.as_retriever()를 통해 생성된 검색기를 사용하여 문서를 검색합니다.
retriever = vectorstore.as_retriever()단계 5: 프롬프트 생성(Create Prompt)
- LangSmith에서 검증된 프롬프트를 다운로드하여 사용합니다.
prompt = hub.pull("rlm/rag-prompt")단계 6: 언어모델 생성(Create LLM)
- OpenAI의 GPT-3.5-turbo 모델을 사용합니다.
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)단계 7: 체인 생성(Create Chain)
- 검색한 문서 결과를 하나의 문단으로 합쳐서 응답을 생성하는 체인을 생성합니다.
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)단계 8: 체인 실행(Run Chain)
- 문서에 대한 질문을 입력하고, 체인을 실행하여 답변을 생성합니다.
question = "부영그룹의 출산 장려 정책에 대해 설명해주세요"
response = rag_chain.invoke(question)
print(response)이 구조를 사용하여 다양한 모듈과 기능을 활용한 RAG 애플리케이션을 구축할 수 있습니다. 필요에 따라 각 모듈을 조정하고, 최적화된 검색 및 생성 과정을 설계할 수 있습니다.
RAPTOR: 긴 문맥 요약 (Long Context Summary)
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval)는 긴 문맥 요약을 위한 고급 기법으로, 문서를 클러스터링하고 요약하여 트리 구조를 생성하는 방법입니다. 이 트리 구조는 문서를 더 높은 수준에서 요약하며, 이를 통해 더 효율적으로 긴 문맥을 요약할 수 있습니다.
설치
pip install -qU langchain umap-learn scikit-learn langchain_community tiktoken langchain-openai langchainhub chromadb langchain-anthropic기본 개념
- Leafs: 시작 문서 집합으로, 이 문서들은 임베딩되어 클러스터링됩니다.
- 트리 구조: 클러스터링된 문서는 재귀적으로 요약되어 트리 구조를 형성합니다.
- 적용 범위: 단일 문서의 텍스트 청크부터 전체 문서까지 다양하게 적용할 수 있습니다.
실습 예시: LCEL 문서에 적용
문서 로드 및 토큰 수 계산
문서를 로드하고, 각 문서의 토큰 수를 계산한 후 히스토그램으로 시각화합니다.
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
from bs4 import BeautifulSoup as Soup
import tiktoken
import matplotlib.pyplot as plt
def num_tokens_from_string(string: str, encoding_name: str) -> int:
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
# LCEL 문서 로드
url = "https://python.langchain.com/docs/expression_language/"
loader = RecursiveUrlLoader(url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text)
docs = loader.load()
# 토큰 수 계산 및 히스토그램 시각화
docs_texts = [d.page_content for d in docs]
counts = [num_tokens_from_string(d, "cl100k_base") for d in docs_texts]
plt.figure(figsize=(10, 6))
plt.hist(counts, bins=30, color="blue", edgecolor="black", alpha=0.7)
plt.title("Token Counts in LCEL Documents")
plt.xlabel("Token Count")
plt.ylabel("Frequency")
plt.grid(axis="y", alpha=0.75)
plt.show()텍스트 연결 및 토큰 수 계산
모든 문서를 하나의 텍스트로 연결하여 총 토큰 수를 계산합니다.
# 문서 텍스트 연결 및 토큰 수 계산
d_sorted = sorted(docs, key=lambda x: x.metadata["source"])
d_reversed = list(reversed(d_sorted))
concatenated_content = "\n\n\n --- \n\n\n".join(doc.page_content for doc in d_reversed)
total_tokens = num_tokens_from_string(concatenated_content, "cl100k_base")
print(f"Num tokens in all context: {total_tokens}")텍스트 분할
RecursiveCharacterTextSplitter를 사용하여 긴 텍스트를 청크로 분할합니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size_tok = 2000
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=chunk_size_tok, chunk_overlap=0)
texts_split = text_splitter.split_text(concatenated_content)트리 구축 및 요약
트리 구조를 구축하고 요약을 생성합니다.
from typing import List, Dict, Tuple
import numpy as np
import pandas as pd
import umap
from sklearn.mixture import GaussianMixture
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
def embed_cluster_summarize_texts(texts: List[str], level: int) -> Tuple[pd.DataFrame, pd.DataFrame]:
# 클러스터링 및 요약 수행
# 클러스터링, 요약 등의 코드 추가
pass # 실제 코드에서는 이 부분을 구현합니다.
def recursive_embed_cluster_summarize(texts: List[str], level: int = 1, n_levels: int = 3) -> Dict[int, Tuple[pd.DataFrame, pd.DataFrame]]:
# 재귀적으로 클러스터링 및 요약 수행
results = {}
df_clusters, df_summary = embed_cluster_summarize_texts(texts, level)
results[level] = (df_clusters, df_summary)
unique_clusters = df_summary["cluster"].nunique()
if level < n_levels and unique_clusters > 1:
new_texts = df_summary["summaries"].tolist()
next_level_results = recursive_embed_cluster_summarize(new_texts, level + 1, n_levels)
results.update(next_level_results)
return results
# 트리 구축
leaf_texts = docs_texts
results = recursive_embed_cluster_summarize(leaf_texts, level=1, n_levels=3)벡터 저장소 구축
Chroma 벡터 저장소를 사용하여 텍스트 데이터를 벡터화하고 저장소를 구축합니다.
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# 텍스트 데이터를 벡터화하고 저장소 생성
all_texts = leaf_texts.copy()
for level in sorted(results.keys()):
summaries = results[level][1]["summaries"].tolist()
all_texts.extend(summaries)
vectorstore = FAISS.from_texts(texts=all_texts, embedding=OpenAIEmbeddings())
# 로컬에 저장
DB_INDEX = "RAPTOR"
if os.path.exists(DB_INDEX):
local_index = FAISS.load_local(DB_INDEX, OpenAIEmbeddings())
local_index.merge_from(vectorstore)
local_index.save_local(DB_INDEX)
else:
vectorstore.save_local(folder_path=DB_INDEX)
# retriever 생성
retriever = vectorstore.as_retriever()RAG 체인 정의 및 실행
RAG 체인을 정의하고 특정 코드 예제를 요청합니다.
from langchain import hub
from langchain_core.runnables import RunnablePassthrough
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
_ = rag_chain.invoke("How to define a RAG chain? Give me a specific code example.")결론
RAPTOR는 긴 문맥을 요약하고 복잡한 데이터를 처리하는 데 유용한 기법입니다. 이 프로세스를 통해 긴 문서도 효율적으로 요약할 수 있으며, 이를 바탕으로 검색 가능한 벡터 저장소를 구축할 수 있습니다.
🏖️ 대화내용을 기억하는 RAG 체인 생성 방법
대화 내용을 기억하는 RAG (Retrieval-Augmented Generation) 체인을 생성하기 위해서는, 대화의 문맥을 유지하고 세션별로 대화 기록을 관리하는 것이 중요합니다. 이 과정에서는 RunnableWithMessageHistory를 사용하여 대화 기록을 관리하며, RAG 체인을 구성합니다.
사전 준비
필요한 라이브러리 설치 및 API 키 설정
먼저 필요한 라이브러리와 API 키를 설정합니다.
from dotenv import load_dotenv
# API KEY 정보로드
load_dotenv()
True
# LangSmith 추적 설정
# pip install langchain-teddynote
from langchain_teddynote import logging
logging.langsmith("CH12-RAG")1. 일반 체인에 대화 기록 추가
대화 기록을 추가하여 사용자와의 대화를 기억하는 체인을 생성합니다.
프롬프트 정의 및 체인 생성
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 프롬프트 정의
prompt = ChatPromptTemplate.from_messages(
[
("system", "당신은 Question-Answering 챗봇입니다. 주어진 질문에 대한 답변을 제공해주세요."),
MessagesPlaceholder(variable_name="chat_history"),
("human", "#Question:\n{question}"),
]
)
# 언어모델 생성
llm = ChatOpenAI()
# 체인 생성
chain = prompt | llm | StrOutputParser()대화 기록 관리
# 세션 기록을 저장할 딕셔너리
store = {}
# 세션 ID를 기반으로 세션 기록을 가져오는 함수
def get_session_history(session_ids):
print(f"[대화 세션ID]: {session_ids}")
if session_ids not in store:
store[session_ids] = ChatMessageHistory()
return store[session_ids]
# 대화 기록을 포함한 체인 생성
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="question",
history_messages_key="chat_history",
)체인 실행
# 첫 번째 질문 실행
response = chain_with_history.invoke(
{"question": "나의 이름은 테디입니다."},
config={"configurable": {"session_id": "abc123"}}
)
print(response) # '안녕하세요, 테디님. 무엇을 도와드릴까요?'
# 이어서 질문 실행
response = chain_with_history.invoke(
{"question": "내 이름이 뭐라고?"},
config={"configurable": {"session_id": "abc123"}}
)
print(response) # '당신의 이름은 테디입니다.'2. RAG + RunnableWithMessageHistory
이제 RAG 체인에 대화 기록 기능을 추가하여 문서 검색 및 대화 내용을 유지하는 체인을 만듭니다.
문서 로드 및 분할
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# 단계 1: 문서 로드
loader = PDFPlumberLoader("data/SPRI_AI_Brief_2023년12월호_F.pdf")
docs = loader.load()
# 단계 2: 문서 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
split_documents = text_splitter.split_documents(docs)임베딩 및 벡터스토어 생성
# 단계 3: 임베딩 생성
embeddings = OpenAIEmbeddings()
# 단계 4: 벡터스토어 생성 및 저장
vectorstore = FAISS.from_documents(documents=split_documents, embedding=embeddings)프롬프트 및 체인 생성
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
# 단계 6: 프롬프트 생성
prompt = PromptTemplate.from_template(
"""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Answer in Korean.
#Previous Chat History:
{chat_history}
#Question:
{question}
#Context:
{context}
#Answer:"""
)
# 단계 7: 언어모델 생성
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# 단계 8: 체인 생성
chain = (
{
"context": itemgetter("question") | vectorstore.as_retriever(),
"question": itemgetter("question"),
"chat_history": itemgetter("chat_history"),
}
| prompt
| llm
| StrOutputParser()
)대화 기록 기능 추가
# 세션 기록을 저장할 딕셔너리
store = {}
# 세션 기록을 가져오는 함수
def get_session_history(session_ids):
print(f"[대화 세션ID]: {session_ids}")
if session_ids not in store:
store[session_ids] = ChatMessageHistory()
return store[session_ids]
# 대화를 기록하는 RAG 체인 생성
rag_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="question",
history_messages_key="chat_history",
)체인 실행
# 첫 번째 질문 실행
response = rag_with_history.invoke(
{"question": "삼성전자가 만든 생성형 AI 이름은?"},
config={"configurable": {"session_id": "rag123"}}
)
print(response) # "삼성전자가 만든 생성형 AI의 이름은 '삼성 가우스'입니다."
# 이어진 질문 실행
response = rag_with_history.invoke(
{"question": "이전 답변을 영어로 번역해주세요."},
config={"configurable": {"session_id": "rag123"}}
)
print(response) # "The name of the generative AI created by Samsung Electronics is 'Samsung Gauss'."결론
이 과정에서는 RAG 체인에 대화 기록 기능을 추가하여 사용자와의 대화를 기억하고, 문서 검색 결과를 활용하는 방법을 구현했습니다. 이를 통해, 사용자는 이전 대화를 바탕으로 지속적인 상호작용을 할 수 있으며, 정보 검색과 함께 대화의 문맥을 유지할 수 있습니다.
