인공지능 공부
1.RAG & LANCHAIN (1)- 기초 문법

RAG란?데이터 적재 및 분할Embedding과 캐싱벡터 저장 및 검색프롬프트와 Chain 설계결과 및 분석기타 고려 사항RAG(Retrieval-Augmented Generation)는 AI 모델이 사전 학습된 데이터 외에도 외부 문서를 참조하여 더 정확하고 신뢰성
2.[혼자 공부하는 데이터 분석 ] 데이터 수집하기
API 사용하기웹스크래핑: 두 프로그램이 서로 대화하기 위한 방법을 정의한 것: 인터넷에서 웹 페이지를 전송하는 기본 통신 방법웹 서버 소프트웨어를 사용해 웹 페이지를 서비스 ex) 엔진엑스(NGINNX), 아파치(Apache)웹브라우저와 \*\*<span sty
3.RAG & LANCHAIN (2)- Langchain 개요
2023년 6월 15일, 온다의 개발자 Elliot(엘리엇, 이은규)이 작성한 글에서는 Langchain 프레임워크를 이용하여 LLM(Large Language Models)을 응용한 프로그램을 개발하는 방법을 상세히 소개하고 있습니다. 최근 GPT-4, Bard, L
4.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.01 Langchain 시작하기
LangChain은 언어 모델을 활용해 다양한 애플리케이션을 개발할 수 있는 프레임워크이다. 이 프레임워크를 통해 언어 모델은 다음과 같은 기능을 수행할 수 있게 된다.문맥을 인식하는 기능: LangChain은 언어 모델을 다양한 문맥 소스와 연결한다. 여기에는 프롬프
5.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.02 프롬프트(prompt)
01. 프롬프트(Prompt) 환경 설정 및 LangSmith 추적 설정 LangSmith 추적을 시작합니다. [프로젝트명] CH02-Prompt LLM 객체 정의 방법 1: from_template() 메소드를 사용하여 PromptTemplate 객체 생성
6.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.03 출력 파서(Output Parsers)
CH03 출력 파서(Output Parsers)01\. Pydantic 출력 파서(PydanticOutputParser)02\. 콤마 구분자 출력 파서(CommaSeparatedListOutputParser)03\. 구조화된 출력 파서(StructuredOutputPa
7.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.04 모델
모델 또는 LLM 단계는 이전 단계에서 구성된 입력을 바탕으로 대규모 언어 모델(LLM)을 활용하여 응답을 생성하는 과정이다. 이 단계는 RAG 시스템의 핵심으로, LLM을 활용해 사용자의 질문에 대해 정확하고 자연스러운 답변을 생성하는 역할을 한다.사용자 의도 이해:
8.RAG & LANCHAIN (4)- Langchain 기본 과정 및 기본 구조
아래는 요청하신 내용을 반영한 LangChain 기본 코드 예시입니다. 출력 파서와 스트리밍 기능을 적절한 단계에 포함시키고, 흔히 사용되는 프롬프트 템플릿으로 대체하였습니다.환경 설정 단계에서는 API 키를 로드하고, 필요한 라이브러리들을 불러옵니다.LangChain
9.RAG & LANCHAIN (5)- Langchain 기반 RAG 기본 구조
API 키 로드, 필요한 라이브러리 불러오기, LangSmith 추적 설정 등은 기본적으로 동일합니다.문서 데이터를 로드하여 검색 가능한 형태로 준비합니다. 이 과정에서는 문서 로더와 텍스트 분할기를 사용합니다.문서의 텍스트를 임베딩(벡터화)하고, 이를 벡터 저장소에
10.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.05 메모리
ConversationBufferMemory 개요문자열로 메시지 추출하기대화 기록 저장 및 확인return_messages=True 옵션 사용ConversationChain에 적용하기ConversationBufferMemory는 메시지를 저장하고, 이후 변수에 메시지를
11.AI 서비스 개발 과정
AI 서비스 개발 과정에 백엔드와 AI 모델의 연결 및 엔드포인트 설정, 배포, 모니터링 등을 반영하면, 전체 개발 과정이 다음과 같이 구체화됩니다. 이 과정은 AI 모델 개발과 백엔드 통합이 주요한 부분을 차지하게 됩니다.문제 정의 및 고객 요구 분석: AI 서비스가
12.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.06 문서로더(Document Loader)
LangChain의 문서 로더(Document Loader)를 사용하면 다양한 형식의 데이터 파일을 문서로 로드할 수 있습니다.Document 로드: 로드한 문서는 Document 객체로 표현되며, 이 객체의 page_content에는 문서의 내용이, metadata에
13.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.07 텍스트 분할(Text Splitter)
문서 분할은 Retrieval-Augmented Generation (RAG) 시스템의 두 번째 단계로서, 로드된 문서들을 효율적으로 처리하고, 시스템이 정보를 보다 잘 활용할 수 있도록 준비하는 중요한 과정이다.이 단계의 목적은 크고 복잡한 문서를 LLM이 받아들일
14.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.08 임베딩
임베딩은 Retrieval-Augmented Generation(RAG) 시스템의 세 번째 단계로, 문서 분할 단계에서 생성된 문서 단위들을 기계가 이해할 수 있는 수치적 형태로 변환하는 과정입니다. 이 단계는 RAG 시스템의 핵심적인 부분 중 하나로, 문서의 의미를
15.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.09 벡터저장소(VectorStore)
벡터 저장소(VectorStore)는 Retrieval-Augmented Generation (RAG) 시스템의 네 번째 단계로, 이전 단계에서 생성된 임베딩 벡터를 효율적으로 저장하고 관리하는 과정입니다. 이 단계는 향후 검색에서 벡터들을 빠르게 조회하고 관련 문서를
16.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.10 검색기(Retriever)
검색기(Retriever)는 Retrieval-Augmented Generation (RAG) 시스템의 핵심 단계로, 데이터베이스에서 사용자의 질문에 관련된 정보를 찾아내는 역할을 합니다. 이 단계는 시스템의 성능과 사용자가 얻는 정보의 정확성에 큰 영향을 미칩니다.정
17.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.08 임베딩 - 캐시와 임베딩 왜 속도에 영향을 주는가?
이 예제는 머신러닝 임베딩을 캐싱하고 이를 로컬 파일 시스템에 저장하여 성능을 최적화하는 방법을 보여줍니다. 특히, 동일한 문서나 데이터에 대해 반복적으로 임베딩을 생성해야 할 때, 캐시를 활용하면 성능이 크게 향상됩니다.OpenAI 임베딩: OpenAI에서 제공하는
18.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.11 ReRanker
아래는 주신 내용을 벨로그에 올리기 위해 더욱 자세하고 체계적으로 정리한 버전입니다.Reranker 개요 Reranker의 작동 원리 Reranker의 기술적 특징 Reranker의 학습 방법 Retriever와의 차이점 Reranker의 장단점 Rerank
19.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 ch.12 Retrieval-Augmented Generation(RAG)
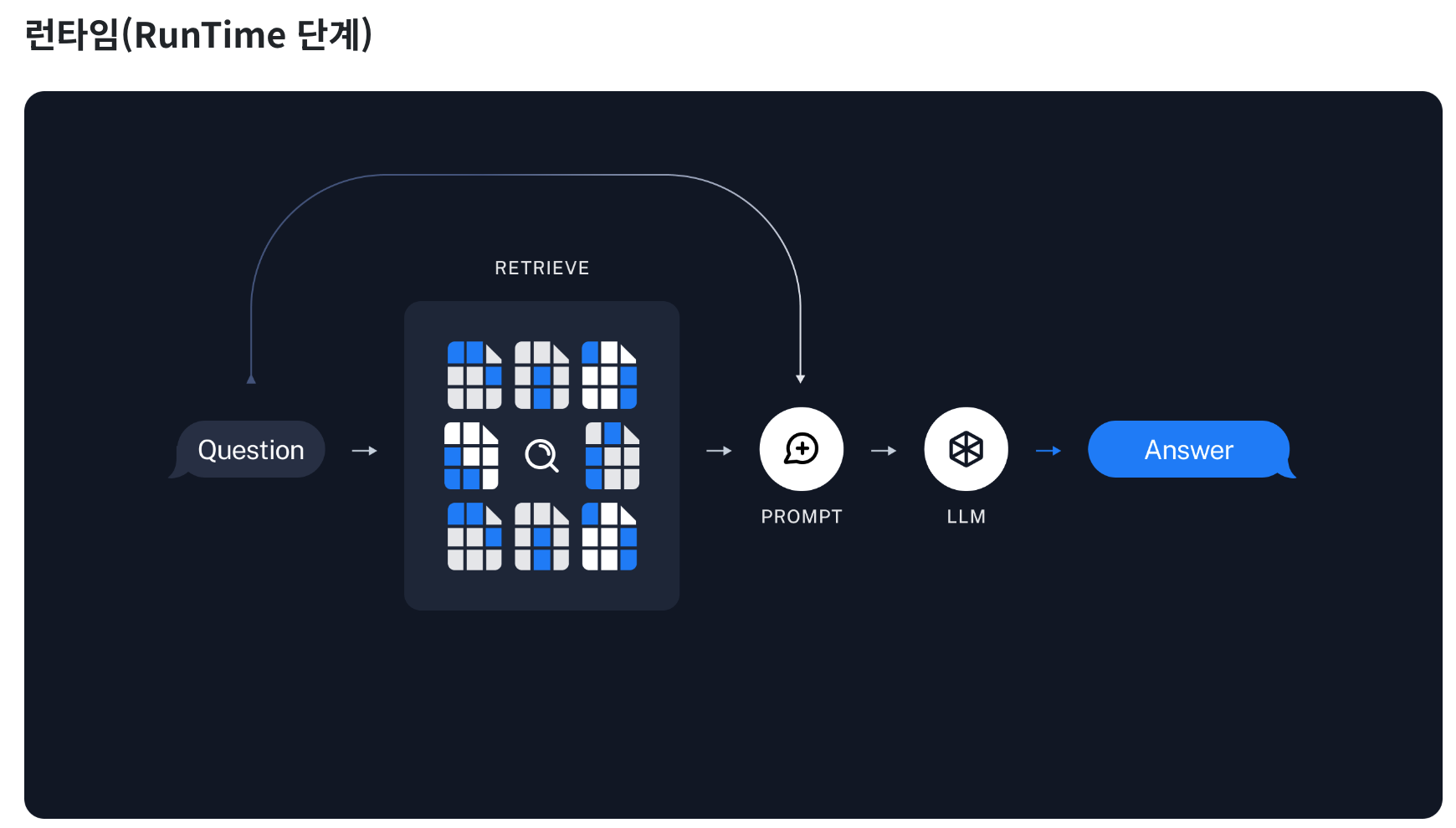
아래는 요청하신 대로 목차 없이 정리한 내용입니다.Retrieval-Augmented Generation(RAG)은 자연어 처리(NLP) 분야에서의 혁신적인 기술로, 기존의 언어 모델의 한계를 넘어서 정보 검색과 생성을 통합하는 방법론이다. RAG는 풍부한 정보를 담고
20.RAG & LANCHAIN (6)- Langchain 기반 RAG 기본 구조 update 버전
API 키 로드, 필요한 라이브러리 불러오기, LangSmith 추적 설정 등은 동일하게 유지합니다.다양한 문서 형식(PDF, CSV, 웹페이지 등)에 대한 로딩과 텍스트 분할 방법을 고려합니다. 다양한 임베딩 모델(Sentence Transformers, Huggin
21.RAG & LANCHAIN (3)- Langchain 개념 & 문법 정리 CH13 LangChain Expression Language(LCEL)
RunnablePassthrough 개요 API 키 관리 설정 데이터 전달과 활용 RunnablePassthrough와 RunnableParallel의 사용 예시 검색기 예제: FAISS 벡터 저장소와의 통합RunnablePassthrough 개념 Runnab
22.seleinum 내용 정리
.
23.[퍼실레이터 공부 추천] sally의 인공지능 추천 공부
sally.lee(이현경) / 퍼실리테이터 — 오늘 오전 11:44학습 참고자료 공유 (Tensorflow recommenders 튜토리얼 후기)안녕하세요 샐리입니다~추천시스템 주제로 질문을 종종 주시는데요 TFRS(TensorFlow Recommenders)라는 추천
24.추천시스템 (1) 추천시스템 기본 개념 / 머신러닝 기법 개념 및 실습
추천 시스템의 개요와 배경 콘텐츠 기반 필터링 추천 시스템 최근접 이웃 협업 필터링 잠재 요인 협업 필터링 콘텐츠 기반 필터링 실습 - TMDB 5000 영화 데이터 세트 아이템 기반 최근접 이웃 협업 필터링 실습 사용자 자신도 좋아하는지 몰랐던 취향을 시스
25.추천시스템 (2) gnn 개요
Author: Shanon Hong번역 및 각색: 사용자이 글은 Shanon Hong의 “An Introduction to Graph Neural Network(GNN) for Analyzing Structured Data”를 저자 허락 하에 번역하고 각색한 내용. G
26.추천시스템 (3) Graph Neural Networks
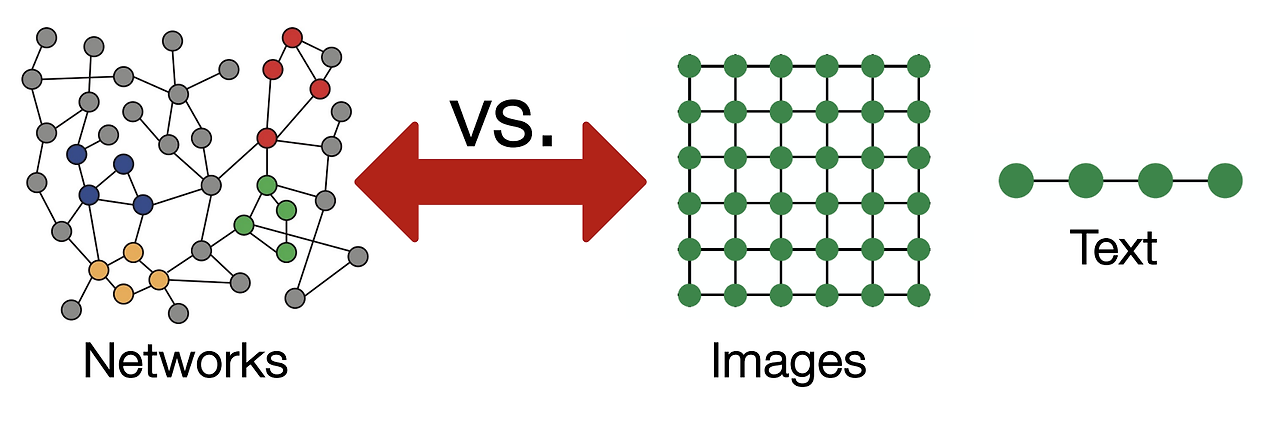
그래프 데이터의 특성과 도전 과제그래프 신경망(GNN)의 기본 아이디어GNN의 계산 그래프와 집계 함수GNN 모델 파라미터 학습그래프 합성곱 신경망(GCN)GNN과 기존 신경망 아키텍처와의 비교그래프 데이터는 이미지나 자연어 데이터와는 다음과 같은 차이점이 있어 전통적
27.추천시스템 (4) GNN : 그래프 선택
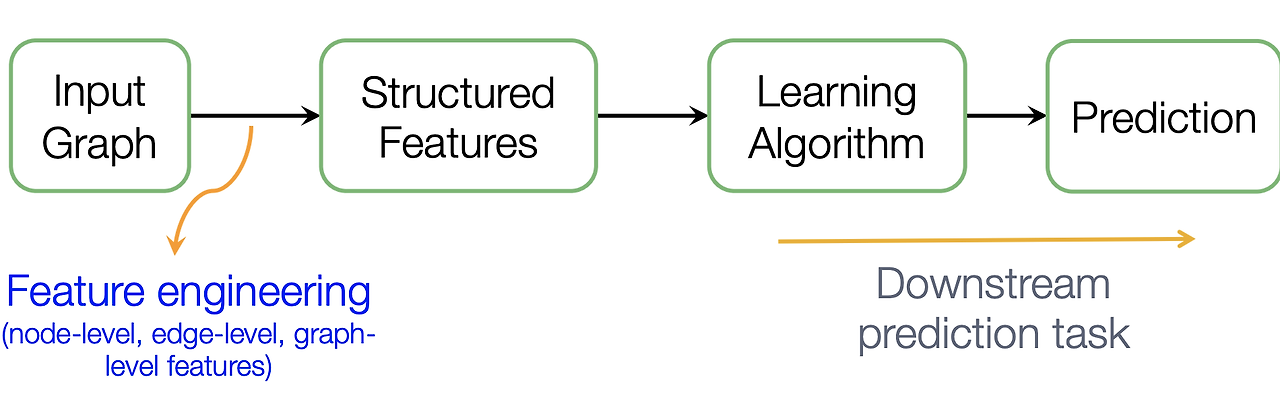
그래프 데이터를 다룰 때, 적절한 그래프 표현 방식을 선택하는 것은 문제를 성공적으로 해결할 수 있는 능력을 결정하는 중요한 요소이다. 그래프는 다양한 방식으로 표현될 수 있으며, 각 도메인에 맞는 표현을 선택하는 것이 매우 중요하다. 이 장에서는 일반적인 그래프의 형
28.추천시스템 (5) Node Embedding
노드 임베딩은 그래프의 각 노드를 저차원 벡터로 표현하는 기법이다. 이는 그래프 데이터에서 노드의 관계와 구조를 벡터 공간에 반영하여 여러 머신러닝 태스크에서 활용할 수 있게 한다. 대표적으로 노드 분류(Node Classification), 링크 예측(Link Pre
29.추천시스템 (5) GNN part2
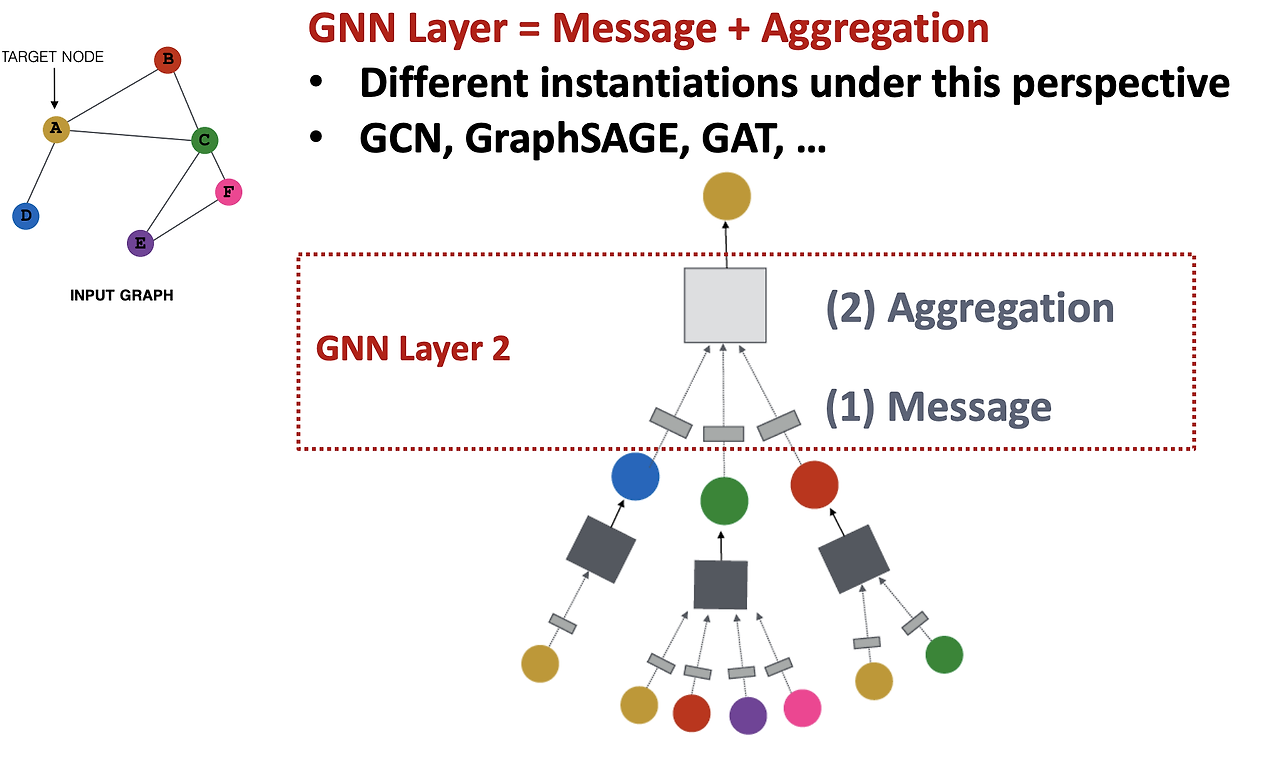
이번 파트에서는 GNN의 레이어 구조와 주요 GNN 모델의 차이점에 대해 알아보겠다. 그래프 신경망의 핵심은 Message 전달 함수와 Aggregation 함수로 구성된 레이어 구조이다. 이 구조는 다양한 GNN 모델에서 공통적으로 사용되며, 각 모델의 차이는 주로
30.추천시스템 (6) GNN기반 추천 시스템 조사 - 논문 리뷰: Graph neural networks in recommender systems: a survey
유튜브, 넷플릭스, 스포티파이 같은 대규모 온라인 플랫폼은 사용자에게 방대한 항목(제품, 영화, 음악 등)을 제공하며, 사용자들이 흥미로운 항목을 탐색하는 것을 돕기 위해 추천 시스템을 사용한다. 추천 시스템은 사용자가 이전에 상호작용한 데이터(예: 클릭, 시청, 구매
31.퍼실레이터 상담
Profile AvatarDaniel.lee/이영락어 맞아요!! go - annotation에서 주석을 사용한 방식에서 맥락으로 넣어볼까 했고, Git에서 그런식으로 Driven(암 유발 변이) /passenger(우연히 일어난 변이) 로 의미를 나누는데 집중하는것 같
32.Model Optimization Techniques & Post-Training Techiniques (모델 구축 이후 작업들)
Fine-tuning은 사전 학습된(pre-trained) 모델을 새로운 작업이나 데이터셋에 맞게 미세 조정하는 방법입니다. 주로 모델의 하위층이나 출력층을 재학습하며, 다른 레이어는 동결(고정)한 채로 일부만 학습하는 경우가 많습니다.Full Fine-tuning:
33.n8n - 코드 자동화 툴 / AI agent 구현

https://insight.infograb.net/blog/2024/07/31/workflow-n8n/