Computer Systems: A Programmer's Perspective by Randal E. Bryant and David R. O’Hallaron를 읽으며 정리한 내용이다.
이 책은 intel의 x86 microprocessor를 기준으로 작성되었다.
Computer System
컴퓨터 시스템은 하드웨어와 소프트웨어로 구성되어 있으며, application program을 실행하는 장치이다.
Information in Bits
컴튜터 시스템 내의 모든 정보들은 bit 단위로 구성되며, bit란 0또는 1의 값을 갖는다. 모든 source program은 bit들의 나열이라고 할 수 있으며, 이 bit들은 encoding되어 문맥을 가진 정보로 나타나고, 보통 상태 정보(context)에 따라서 다르게 해석된다.
가령, 아래와 같이 hello.c라는 source program이 있을 때,
#include<studio.h>
int main()
{
printf("hello, world\n");
return 0;
}영어 text characters를 encoding할 때에는 ASCII 인코딩을 사용하며, 이 때 bit들을 byte(1byte = 8bits)단위로 재구성하여 각 byte로 나타난 값에 해당하는 character를 매핑한다.

Ch2에서 더 자세하게 다뤄질 예정이다.
Compilation System
source file(예: .c)이 시스템에서 실행되기 위해서는 최종적으로 기계어(machine-language instructions)로 번역되어야 한다. 기계어로 구성된 프로그램을 executable object program(file)이라고 하며 이는 binary disk file로 저장된다. Unix에서 소스 파일을 executable file로 변역하는 시스템을 compilation system이라고 하며, 구체적인 변역 과정은 아래와 같다.
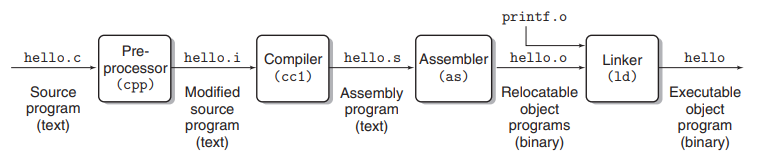
GCC compiler
linux> gcc -o hello hello.cCompilation system의 변역 과정
-
Processing phase
hello.c -> hello.i
Pre-processor가 소스파일(hello.c)을 읽고 directives(#include<stdio.h>)에 따라 header file(stdio.h)를 적용시킨다. -
Compilaton phase
hello.i -> hello.s
Compiler가 어셈블리어(assembly-language) 프로그램으로 번역한다. 서로 다른 high-level languages에 대해 서로 다른 compilers(ex. C compilers, Fortran)로 번역하였을 때 그 결과가 어셈블리어로 동일하기 때문에 매우 유용하다.
assembly-language program 예시:

-
Assembly phase
hello.s -> hello.o
Assembler가 어셈블리어를 기계어(instructions)로 번역해서 relocatable object program이라는 기계어 프로그램으로 재구성하고, 이를 obeject file(hello.o)에 저장한다. object file은 text file이 아니라 binary file이다. -
Linking phase
hello.o ->hello
Linker가 hello.o를 구성하는 여러 precompiled object file(printf.o)들을 병합한다(merge). 이 때 precompiled object file에 속한 함수들(printf)은 컴파일러(C compiler)가 제공하는 라이브러리(standard C library)를 적용해서 실행시킨다. 결과적으로 executable object file(hello)를 도출한다.
이렇게 compilation system을 거쳐 결과적으로 도출된 executable object file은 메모리에 로드되어 시스템에 의해 실행된다.
프로그래머가 Compilation system 과정에 대해 이해해야 하는 이유
Compile 과정을 효율적으로 해주는 C-code를 작성함으로써 프로그램 성능을 높일 수 있고, Linker-related errors를 해결할 수 있으며, 데이터가 프로그램 스택에 저장되는 원리를 이해함으로써(stack discipline) buffer overflow vulnerabilities를 해결할 수 있다.
Hardware Organization of a System
아래와 같이 shell(프롬프트를 출력하고, command line을 타이핑할 때까지 기다린 후에 command를 실행하는 application program, command-line interpreter)에 executable 파일명을 입력해서 실행시킬 때 프로그램이 어떤 과정을 거쳐 실행되는지 알기 위해서는 HW구조에 대한 이해가 필요하다.
linux> ./hello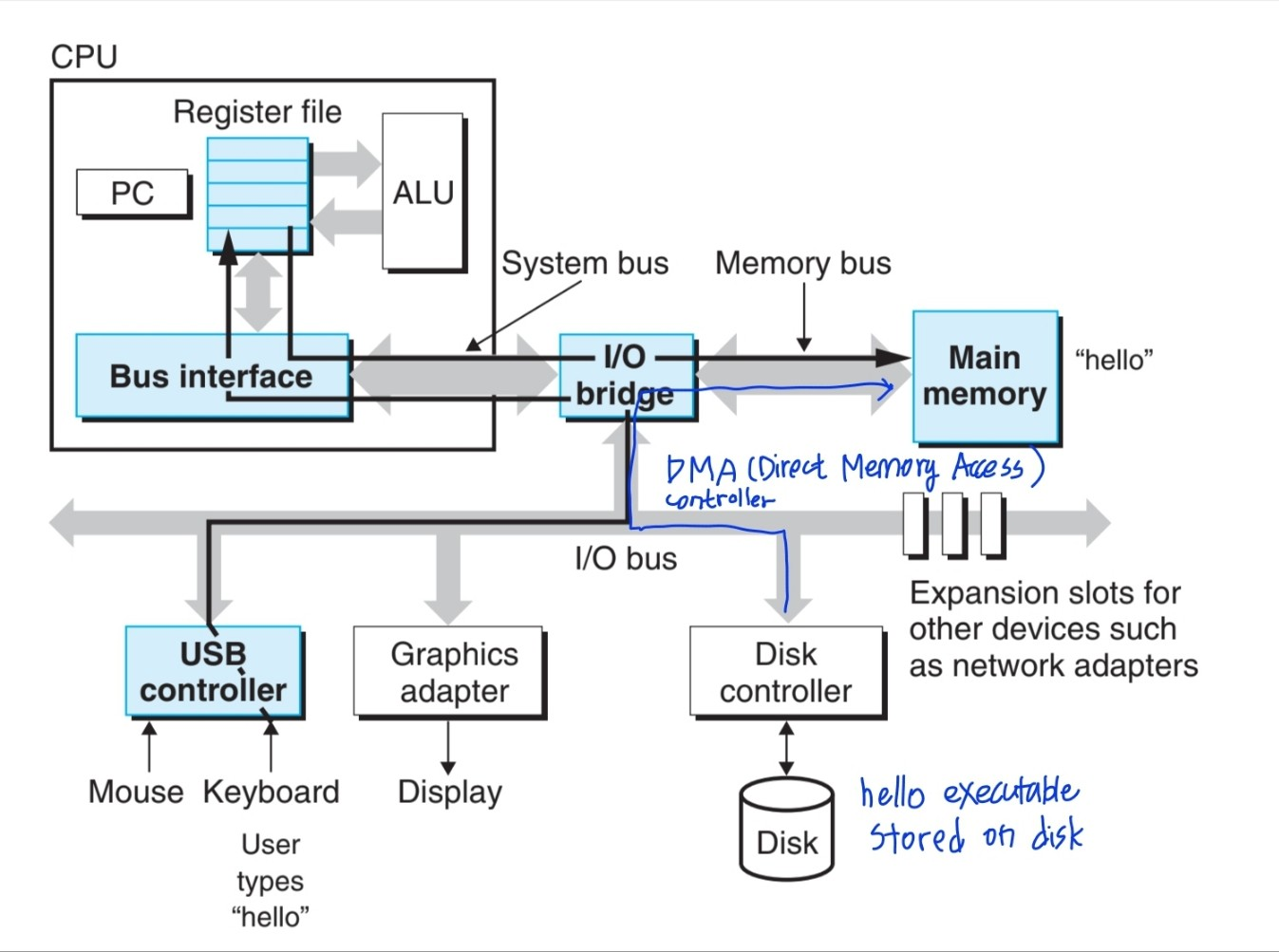
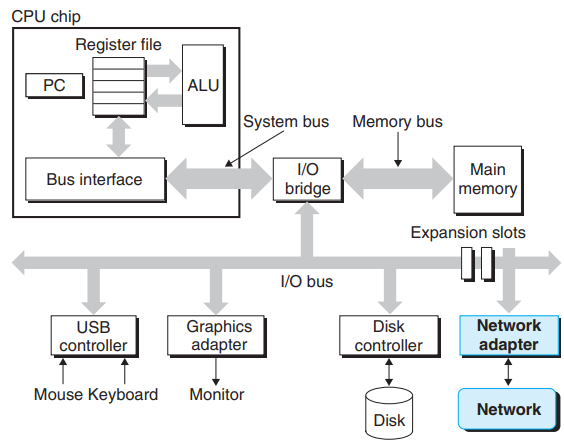
Bus
도식표 상 회색 화살표로 표현된 bus는, words(시스템마다 다르지만, 보통 4bytes나 8bytes) 단위로 정보를 이동시키는 전자 도관이다.
I/O devices
외부세계와 시스템을 연결해주는 장치로, 키보드, 마우스, 디스플레이, 디스크(디스크 드라이브) 등이 있다. I/O device와 I/O bus를 연결해주는 장치로는 controller와 adapter가 있다. 이 둘은 packaging 방법에서 차이가 있는데 Controller는 시스템의 main 인쇄회로기판(printed circuit board, motherboard)에 직접적으로 내장되어 있는 칩셋이고, Adapter는 motherboard에 플러그인되는 카드이다.
Main Memory
프로세서가 프로그램을 실행하는 동안 프로그램과 데이터를 임시로 저장하는 장치이다. 물리적으로는 dynamic random access memory(DRAM)으로 구성되고, 논리적으로는 주소가 0으로 시작하는 byte 단위의 선형 배열(linear array)로 조직되어 있다.
Processor (CPU)
Main memory에 저장되어 있는 기계어(binary instructions)를 읽고 해석하는 장치이다. 코어에는 program counter(PC)라고 불리는 word 크기의 register들로 구성된 저장 장치가 있고, PC가 main memory 상의 instruction을 가리킨다. 어떤 instructions를 실행하면 PC가 그 다음 instructions를 가리키게 업데이트 되는 방식으로, 시스템이 구동되는 기간 내내 프로세서가 반복적으로 실행된다.
insturctions는 instruction set architecture라는 기계어 실행 모델에 따라서 작동한다. 간단한 작동들에는 Load, Store, Operate, Jump 등이 있다. Main memory에서 register로 word를 copy하는 것을 Load라고 하며, register에서 main memory로 word를 copy하는 것을 Store한다고 한다. 두개의 registers에 있는 컨텐츠들을 ALU(arithmetic /logic unit)로 copy한 후에 컨텐츠들에 대해 산술 연산을 수행하고, 그 결과를 어떤 register에 저장하는 과정을 Operate한다고 한다. instruction으로부터 word를 추출해서 PC에 copy하는 과정을 Jump라고 한다. 각 과정에서 copy를 할 때는 전에 있던 값에 덮어쓴다.
프로그램 수행 속력을 높이기 위해 프로세서 메커니즘이 매우 복잡하게 발달되었기 때문에, 메커니즘은 각 기계어(instruction)의 효과를 나타내는 instruction set architecture와 프로세서가 실제로 구동되는 과정을 묘사하는 microarchitecture로 구분된다.
Memory hierarchy
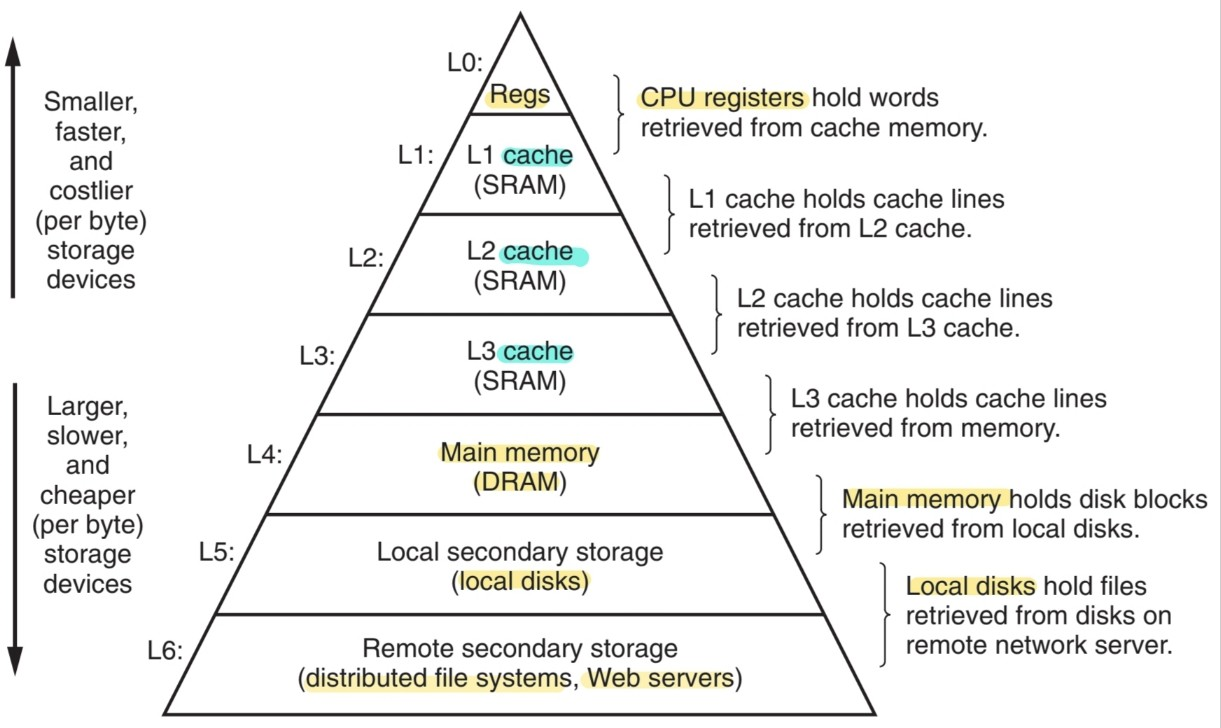
컴퓨터 시스템이 동작하는데 걸리는 대부분의 시간은 정보를 copy하는 데에 걸리기 때문에 I/O devices, CPU registers, storage devices는 계층적인 형태로 (hierarcy) 구성되어 있다. Memory hierarchy란 어떤 저장 장치가 바로 직전 계층의 저장 장치의 cache 역할을 하는 것을 의미한다. CPU(top) - cache memories - DRAM main memory - disk storage(bottom). 높은 계층의 저장장치일수록 빠르지만 저장 용량이 작고 비트당 연산수가 많다. 반면 낮은 계층의 저장장치는 저장 용량이 크고 비트당 연산수가 적지만 느리다.
이때 processor-memory gap을 처리하기 위해 사용하는 것이 cache인데, 이는 높은 계층의 장치과 낮은 계층의 장치 사이에 위치해서 낮은 계층의 저장 장치에 있지만 자주 사용되는 정보를 미리 복사하여 속도 제약을 극복하는 임시 저장 장소이다. 즉 locality(data in localized regions에 access) 특성을 활용하여 큰 용량의 메모리를 빠르게 처리하는 장치이다.
Operating system and Operating system Kernel
Operating System은 application program으로 하여금 hardware를 조작하게하는 소프트웨어로, (1)통제되지 않는 응용프로그램에 의해 하드웨어가 잘못 사용되는 것을 방지하고 (2)응용프로그램에 하드웨어 조작 메커니즘을 제공하는 역할을 한다.
Operating System의 핵심 코드인 Operating System Kernel은 메모리에 상주하며 application과 hardware를 매개한다. 기본적으로 세 개의 추상화(abstractions)로 나타난다.
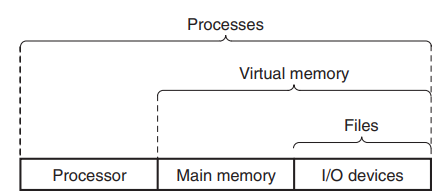
- Processes: processor, main memory, I/O devices를 추상화 한 것
메모리에 적재되어 실행되고 있는 프로그램을 추상화하여 프로세스라고 한다. - Virtual Memory: main memory와 disks를 추상화 한 것
- Files: I/O device를 추상화한 것
Process Context Switching
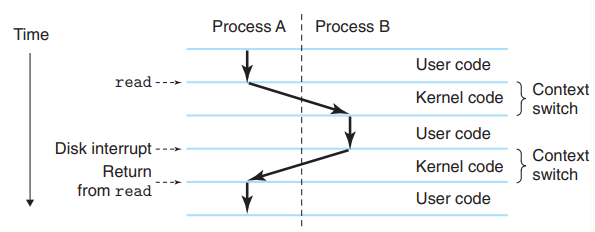
OS는 context라고 불리는, PC, 레지스터, 메인메모리의 현재 값 등의 현재 상태를 나타내는 값을 항시 추적하는데, OS가 현재 process에서 새로운 process로 control을 이동시킬 때 현재 process의 context를 저장하고 새로운 process의 context를 복구하고 control을 새로운 process로 전이시키는 context switching 과정을 거친다.
hello.c 프로그램을 실행시키는 경우, shell process(Process A)에서 hello process(Process B) 간의 control 이동이 필요하다. hello.c 프로그램을 실행시키라는 command를 입력받았을 때, 프로세스는 system call이라는 함수를 활용하여 control을 OS로 전달하고, OS는 context switching을 하는 것이다. 다시 말해 shell process의 context를 저장하고, hello process의 context를 복구한 후에 여기로 control을 이동시킨다. 반대로, hello.c 실행을 종료할 때는 hello process의 context를 저장하고, shell process의 context를 복구한 후에 여기로 control을 이동시킨다.
이 때 system call 함수 호출부터 context switching까지의 전 과정은 Operating System Kernel에 의해 발생한다. Operating System Kernel은 메모리에 존재하며 application과 hardware를 매개하는데 쓰이는 Operating System의 핵심 코드와 데이터 구조를 의미한다.
Virtual Memory
각각의 프로세스가 메모리를 독점적으로 사용함을 나타내는 추상화이다.
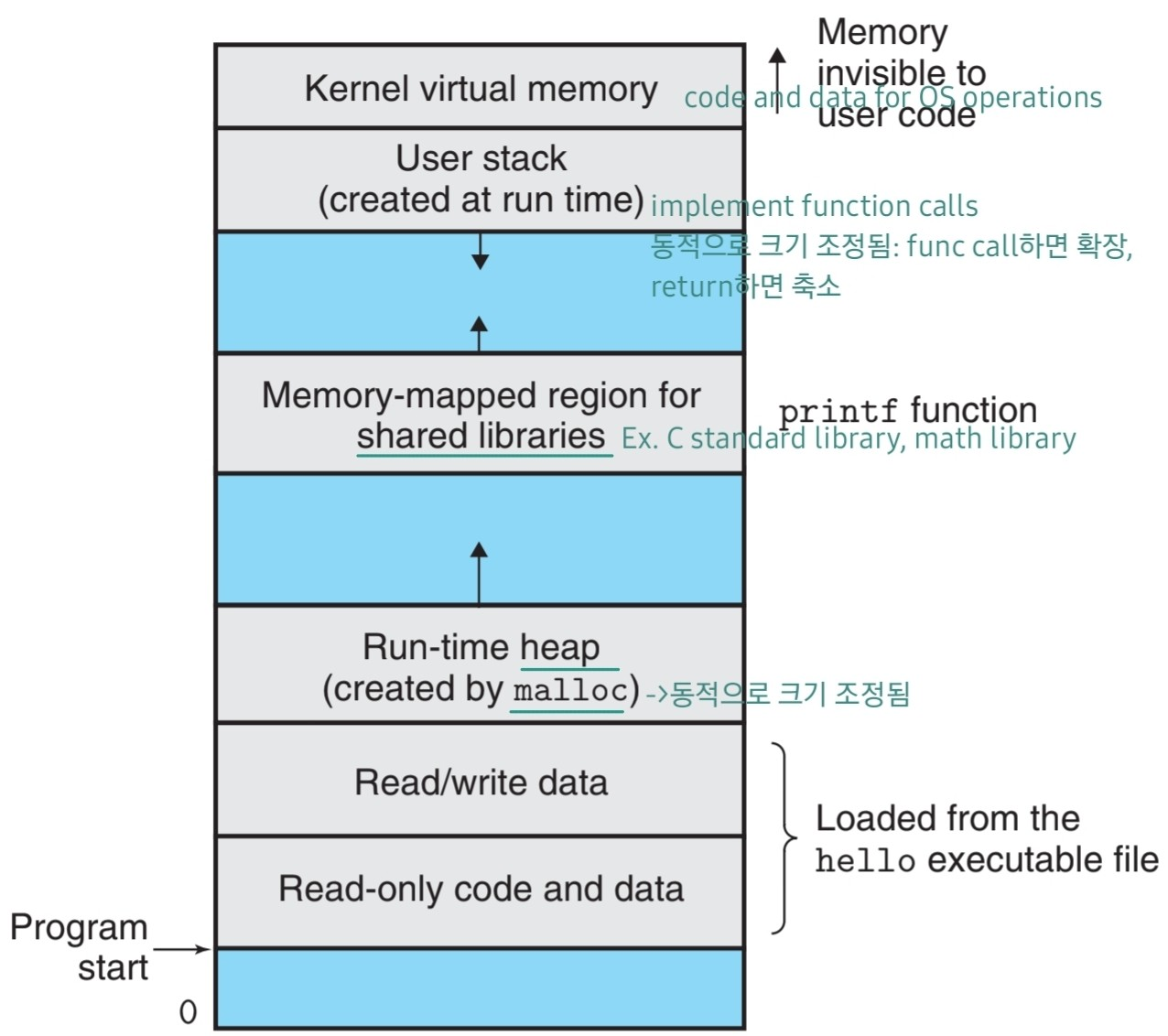
Files
bytes의 나열이다. 키보드, 디스플레이, 디스크, 네트워크 등 I/O device 모두 file 형태로 모델링되어 있다. 즉 시스템의 모든 인풋과 아웃풋은 파일을 읽고 쓰는 형태로 수행되며, 이를 가능하게 하는 system call을 Unix I/O라고 한다.
Network
네트워크는 시스템끼리 연결시키는 장치고, I/O device의 일종이라고 볼 수 있다. 시스템이 main memory에 있던 정보(bytes)를 network adapter로 copy하면, 정보가 network를 통해서 다른 시스템으로 이동하는 형태이다.
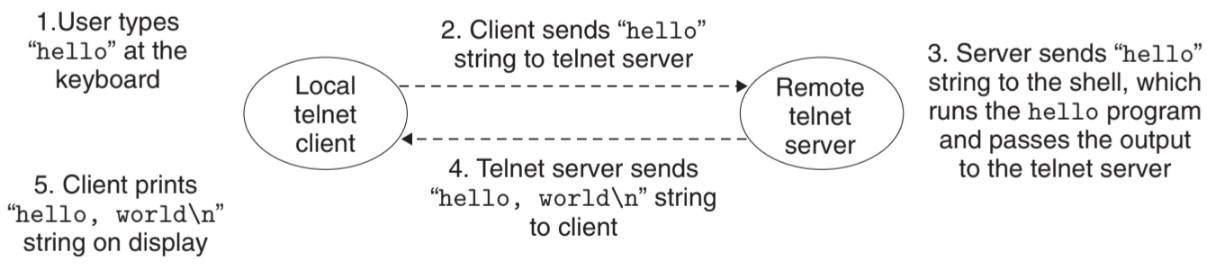
client에 hello를 입력하면, client는 hello를 server로 보내고, server가 hello를 받으면 그것은 원격 shell로 텍스트를 전달한다. shell이 해당 command를 실행하고 그 결과를 server로 전송하면, server는 결과를 다시 client로 전달한다. 결과를 전달받은 client는 local terminal에 hello를 출력하게 된다.
부록
Amdahl's Law (암달의 법칙)
시스템의 특정 부분을 가속화하면, 전체 시스템에 미치는 영향은 그 부분이 전체 시스템에서 차지하는 정도(α)와 가속화하는 정도(k)에 달려있다는 법칙이다.
Concurrency and Parallelism
어떤 시스템이 다중 동시 활동을 지원하는 특성을 concurrency라고 하며, 시스템을 가속화하기 위해 concurrency를 사용하는 활용하는 것을 parallelism이라고 한다.
시스템의 high-level부터 low-level에 걸쳐 각 부분을 조작해서 parallelism을 구현하는 방법이 있는데, 이를 순차적으로 언급하면 다음과 같다.
Thread level Concurrency
Process abstraction(high-level)을 조작하는 방법으로, threads(프로세스 내에서 실행되는 흐름의 단위)를 이용하여 하나의 프로세스 내에 다중 control flows를 구성하는 방법이다. 저글러가 여러개의 공을 공중에 띄우는 방식과 같이, 여러 프로세스를 재빠르게 바꾸는(switch) 방식으로 여러 유저들이 동시에 시스템에서 상호작용하거나, 한명의 유저가 동시에 여러 프로그램을 활용할 수 있게 한다. 이 때 한 개의 프로세서(CPU)가 여러 프로세스를 처리하면 uniprocessor system이라고 불린다.
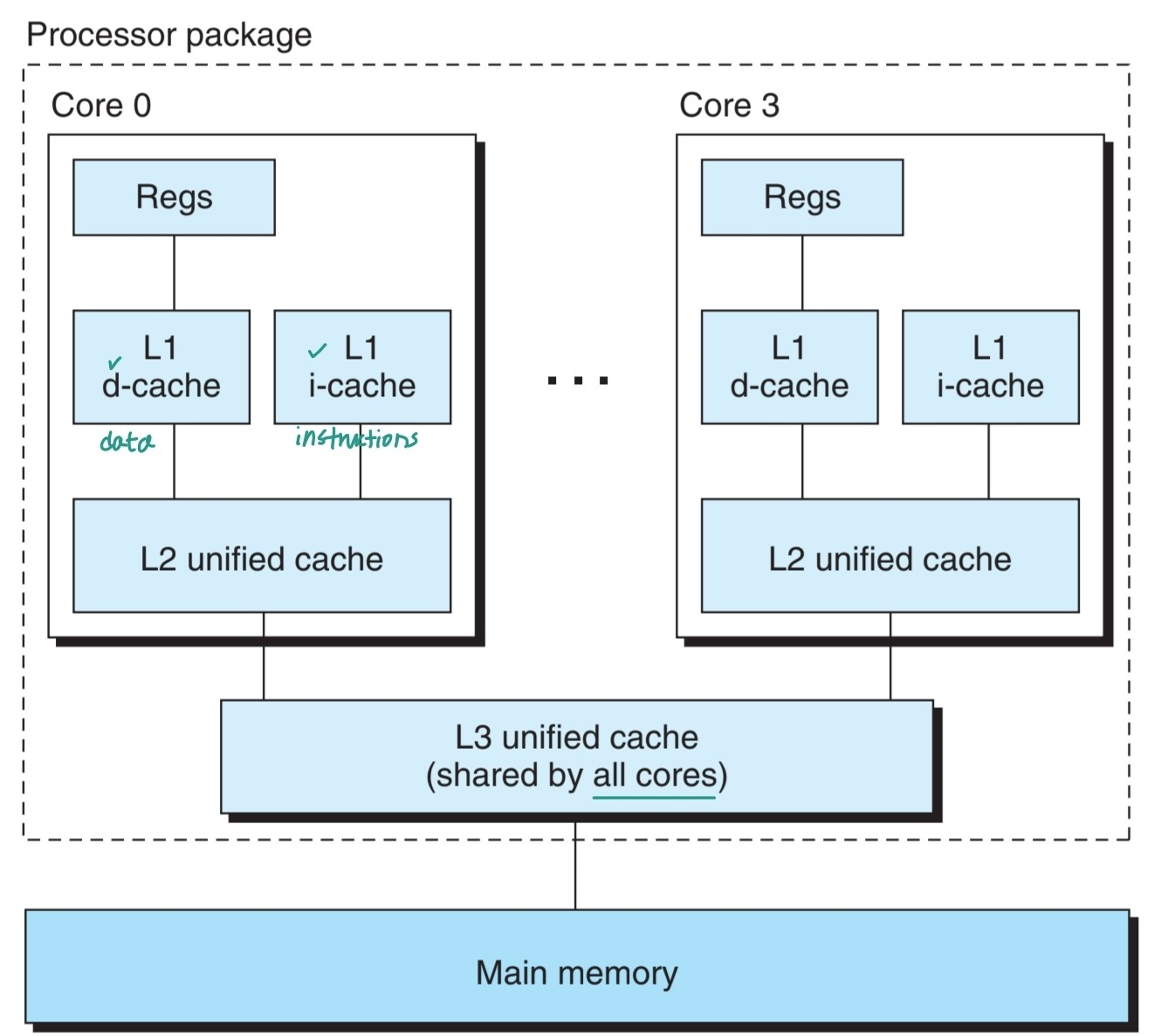
반면, 하나의 OS kernel이 다수의 프로세서를 관리하는 시스템은 multiprocessor system이라고 한다. multi-core processor와 hyperthreading 방식을 통해 작동할 수 있다. Multi-core processor는 하나의 집적회로칩(intergrated-circuit chip)에 다수의 CPU가 있는 것이다.
Hyperthreading(simultaneous multi-threading)은 하나의 CPU가 여러 control flows(threads)를 실행하는 것이다. 다시 말해서, CPU 하드웨어(PC, register)에 대해 복사본을 가지고 있는 것과 같다. 이 경우 각 core는 cycle-by-cycle 방식으로 사이클마다 돌아가며 실행되는데, 이 때마다 여러 thread 중 적절한 thread를 실행시킬 수 있다.
Instruction level Parallelism
Processor hardware가 pipeline상 여러 stage가 서로 다른 instructions에 대해 동시헤 수행되는 방식이다. 이렇듯 한 clock cycle마다 여러개의 instructions를 실행하는 프로세서를 superscalar processor라고 한다.
Single-Instruction, Multiple Data(SIMD) Parallelism
하나의 instruction이 동시에 여러 데이터를 처리하는 방식이다. 주로 이미지, 소리, 비디오 처리 application의 가속화에 이용되며, vector data type을 이용하는 방식 등으로 실현 가능하다.
Abstraction
추상화란 실질적인 내부 작동 방식을 몰라도 핵심 기능에 대한 정보를 도출하는 것이다. 대표적인 사례로 Application program interface(API)는 클라이언트 소프트웨어가 실제 내부 작동 방식에 대한 세부 사항을 알 필요 없이 서버에서 제공하는 추상화된 소프트웨어를 사용할 수 있도록 하는 인터페이스를 제공한다.
