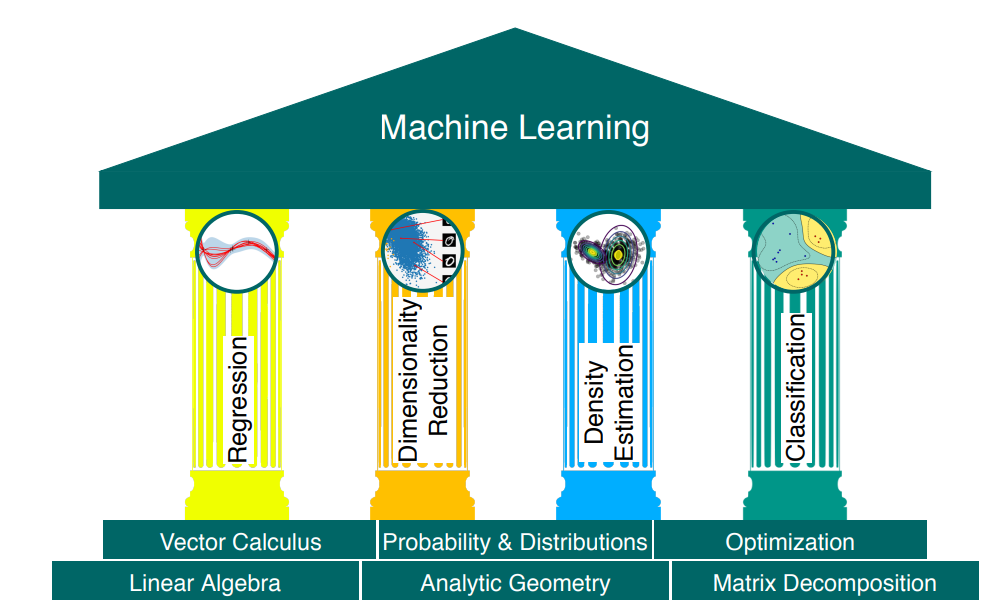
Part1
- Linear Algebra: 데이터를 벡터로, 테이블을 행렬로 표현 (ch2)
- Analytic Geometry: 두 벡터의 유사성과 거리 측정 (ch3)
- Matrix decomposition: 시그널로부터 노이즈 분리 (ch4)
- Probability theory: 예측값에 대한 불확실성, 신뢰도 수치화 (ch6)
- Vector calculus: 벡터에서의 gradients 개념 바탕으로 최적화 (ch5)
- Optimization: 파라미터 학습을 위한 함수의 최대값, 최소값 탐색 (ch7)
Part2
- 기계학습의 3대 요소: 데이터, 모델, 파라미터 추정
- 기계학습의 목표: 새로운 데이터에 대해 적절한 예측하는 기계 만들기
- Linear regression: input x를 실수 label y에 fit하는 함수를 찾는 것으로, maximum likelihood와 maximum a posteriori estimation, Bayesian linear regression으로 model fitting을 한다. (ch9)
- Dimensionality reduction: principal component analysis를 사용하여 고차원의 데이터를 저차원으로 응축시킨다. (ch10)
- Density estimation: 데이터셋를 설명하는 확률 분포 (density model)를 추정하는 것으로, 대표적으로 Gaussian mixture model에서 iterative scheme으로 파라미터를 찾는 방법이 있다. (ch11)
- Classification: input x를 정수(범주) label y에 fit하는 함수를 찾는 것으로, label ysupport vector machine(SVM)으로 가능하다. (ch12)

공부한 내용을 정리한 블로그입니다. 피드백, 오류 지적 언제나 환영합니다.