📜 문제
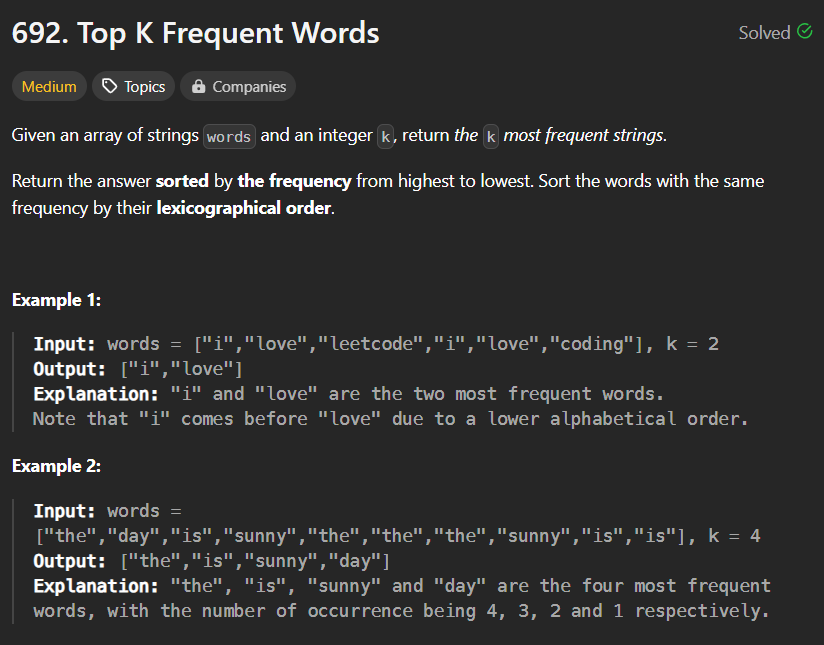
- String 배열
words와 양수k가 주어진다. - words에서 가장 자주 사용된 k개의 String을 반환한다.
- 만일, 사용된 개수가 동일할 경우 사전순으로 출력한다.
문제를 보고 Map을 사용해 key값은 String, value 값은 사용 빈도로 두고 풀어나가야 겠다고 생각이 들었다.
관건은 다중 정렬을 어떻게 효율적으로 풀어나갈 것인가...
✍ 부분 코드 설명
변수 선언
public List<String> topKFrequent(String[] words, int k) {
Map<String, Integer> map =new HashMap<>();
for(String word: words){
map.put(word, map.getOrDefault(word, 0)+1);
}
List<String> answer = new ArrayList<>(map.keySet());
...- map : <문자열, 빈도수> 쌍을 저장하는 변수.
words에 저장된 문자열과 그 빈도수를 map에 삽입한다.
- answer: 반환될 List, map의 Key 값들을 저장한다.
삽입 함수 작성
...
Collections.sort(answer,
new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
if(map.get(o1)!=map.get(o2)){
return map.get(o2)-map.get(o1);
}
else{
return o1.compareTo(o2);
}
}
}
);
return answer.subList(0,k);
}- 정렬 수행
- answer 리스트를 주어진 Comparator에 따라 정렬한다.
- Comparator는 문자열 o1, o2를 비교한다.
- Comparator를 재정의
- 문자열의 빈도수가 다른 경우, 빈도수 기준 내림차순 정렬
- 빈도수가 같은 경우, 사전순으로 정렬
- 부분리스트 반환
- answer은 문제 조건에 따라 정렬되어 있으므로 상위 k개의 요소를 반환
🍳 전체 소스 코드
import java.util.*;
class Solution {
public List<String> topKFrequent(String[] words, int k) {
Map<String, Integer> map =new HashMap<>();
for(String word: words){
map.put(word, map.getOrDefault(word, 0)+1);
}
List<String> answer = new ArrayList<>(map.keySet());
Collections.sort(answer,
new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
if(map.get(o1)!=map.get(o2)){
return map.get(o2)-map.get(o1);
}
else{
return o1.compareTo(o2);
}
}
}
);
return answer.subList(0,k);
}
}✨ 결과
Comparator을 재정의 하는 것까진 생각했는데..
어떻게 재정의를 할까 고민을 많이 했다.
처음에는 List<Map<String, Integer>> 변수를 만들어서 재정의를 진행하고
List<String> answer 을 따로 만들어서 반환했는데 생각해 보니 위 풀이처럼 진행하면 공간낭비를 줄일 수 있었다.
Comparator을 재정의 하여 사용하는 법을 다시 깨닫는 문제라서 좋았따.
