
1. Unsupervised Learning
1) Supervised learning
☑️ data의 형태 → (X, Y)
☑️ goal → f(X) = Y인 f를 찾는 것
ex) Regression
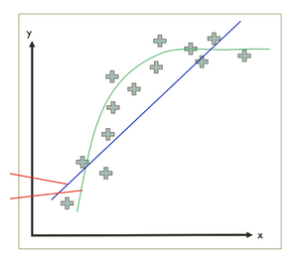
ex) Classification
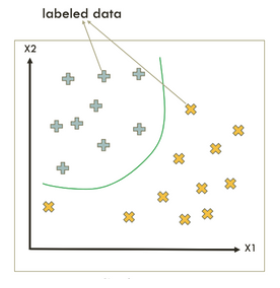
2) Unsupervised Leaning
☑️ data의 형태 → (X)
☑️ goal → X의 feature, featrue들 간의 관계를 찾는 것
▶️ data에 label(Y)가 없는 경우
▶️ data의 일부 값이 없는 경우
▶️ data labeling이 잘못된 경우 (noisy)
➰ ex) Clustering, Compression, Feature & Presentation Learning, Dimensionality Reduction, Generative Models
ex) 차원 축소
-
PCA (Principal Component Analysis) : 고전적인 통계 분석 방법
☑️ 좌표 변환을 통해 다차원 데이터의 차원을 축소한다.
🥲 linear combination에 기반한 기법이므로, non-linearity를 모델링할 수 없다. -
AE (AutoEncoder)
☑️ Encoder (차원 축소) + Decoder (차원 확대)
👍🏻 sol) non-linearity를 모델링 할 수 있다.
2. Autoencoder
☑️ Encoder( featrue extractor) 와 Decoder(Reconstuctor) 부분으로 나뉘며, 마치 identity function 같은 역할을 한다.
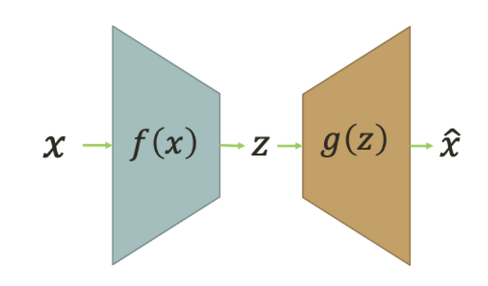
❓ for) data의 distribution을 파악한다!
▶️ 과거) 차원 축소, feature 학습
▶️ 현재) generative modeling의 앞부분
🥲 not use) data compression으로 data loss가 발생하므로, 소실되면 안 되는 data에는 사용할 수 없다.
➰ ex) 이미지, 영상 등은 조금 소실되도 괜찮으므로 사용 可
1) feature 개수에 따른 종류: Undercomplete AE, Overcomplete AE
- Undercomplete AE
☑️ #(hidden) < #(input)
▶️ 압축 O, 특징 추출
➰ ex) 이미지의 특징 추출, 데이터 압축, 노이즈 제거- good feature를 학습해야 한다.
- Overcomplete AE
☑️ #(hidden) > #(input)
▶️ 압축 X, 보다 복잡한 형태로 표현
➰ ex) 이미지에서 새로운 특징 발견, 데이터의 보다 정확한 분류
🥲 pb) 의미있는 feature라는 보장은 없으며, 극단적인 경우, 디코더에서 다른 input이 카피될 수 있다.
2) Simple Latent Space Interpolation
- 0, 9의 feature를 학습한다.
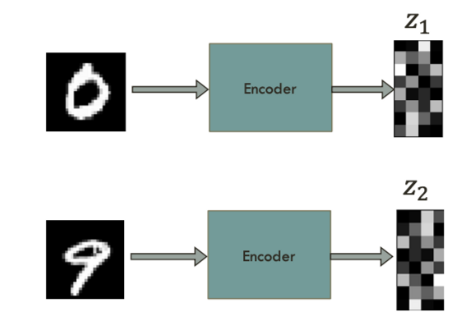
- 학습된 0, 9의 feature의 weighted sum을 하여, decoder에 입력한다.
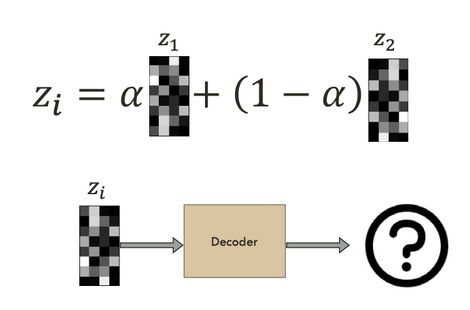
- 다음과 같이 출력된다.

3) Regularization: Sparse Reg.
🥲 pb) overfitting; 다음과 같이, feature가 아닌 data 자체를 학습해버릴 수 있다.
-> sol) 우리는 sparse feature을 학습하길 원한다.
3. DAE (Denoising AutoEncoders)
noisy한 corrupted input ()을 주어 more robust model을 만든다.
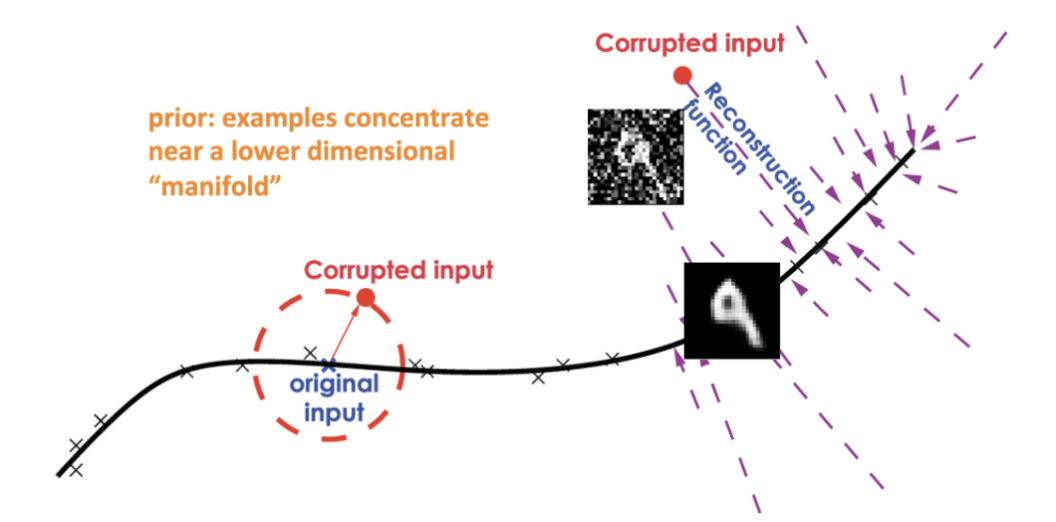
👍🏻 more robust == generalized structure 학습
how) 학습하는 법
1. corrupted input을 준다. ()
2. reconstruction 한다. ()
3. (noiseless x)
4. Semisupervised Learning with DAE
unlabeled data와 labeled data를 모두 사용할 수 있는 방식
▶️ use) classification
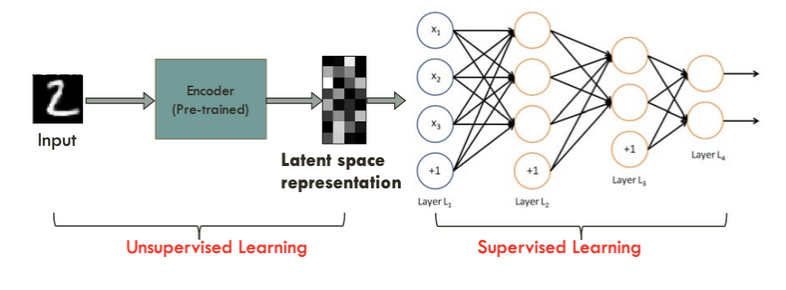
AE로 먼저 data중, x들의 feature를 학습 (unsupervised learning)
→ classification (supervised leaning)
5. Stacked AE
여러 AE를 쌓아서 구성된 신경망 모델
👍🏻 input data를 더욱 복잡한 형태로 변환 可, 더욱 정확한 특징 추출
▶️ 이미지, 음성데이터의 분류
6. Contractive AE
입력 데이터의 변화에 대한 민감도를 감소시키는 AE
