0 Computer Vision Problems
❓why) 컴퓨터 비전에서 주로 CNN이 활용되는 문제이므로 어떠한 문제들이 있는지 살펴본다.
| Image Classification | Object Detection | Neural Style Transfer |
|---|---|---|
| 이미지 전체를 분류 | 이미지 전체에서 물체의 위치 탐지, 그 박스를 분류 | |
 |  |  |
1 Image Classification
1. Fully Connected (FC)
☑️ what) 각 layer의 모든 input과 output과 연결됨
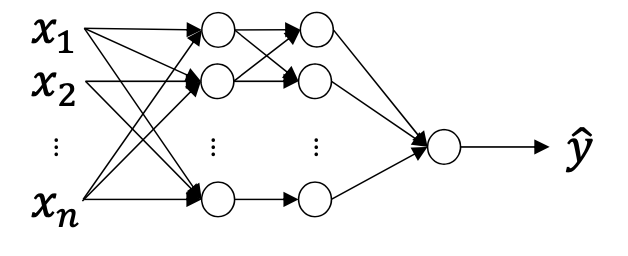
🥲 pb) 일반적으로 image의 dimension이 크므로, FC layer로 네트워크를 구성하면, weight parameter들의 개수가 많아지고, 이에 따라 overfitting 가능성이 높아진다.
👍🏻 sol) 이에 비해, CNN은 image의 크기에 상관없이 filter 크기만큼의 parameter를 학습한다.
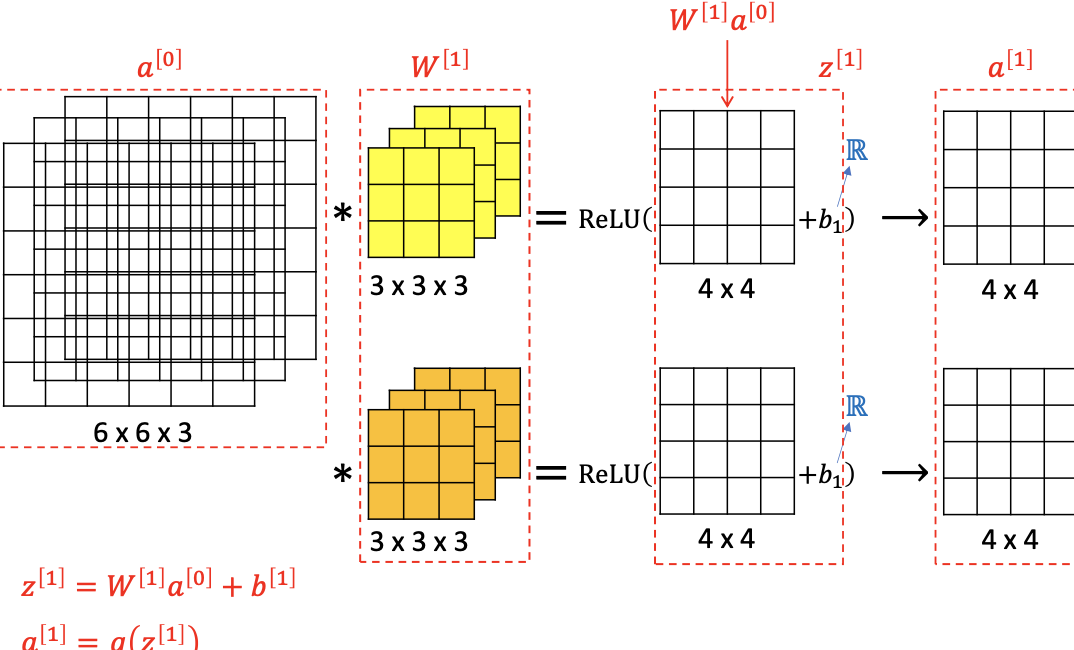
2. Convolution (CONV)
☑️ what) 각 layer의 모든 filter와 이미지를 convolution(합성곱)하여 feature를 학습한다.
👍🏻 gd) Parameter sharing: image에 관계없이 filter를 feature detector로 공유하여 활용할 수 있어서 학습되어야 하는 parameter가 적다.
👍🏻 gd) Sparsity of connection: FC는 이미지 전체를 보지만, CONV는 이미지 일부분에서 connection을 형성하므로 connection이 sparse하다.
3차원 filter가 적용된 feature map이, filter 개수만큼, 다음 layer의 input으로 전달된다.
- filter
이전 layer의 차원에 맞는 3차원의 filter가 사용됨. - padding
filter 사용 시 image 크기가 작아지므로, padding을 사용할 수 있다.
1) valid convolution: padding X
2) same convolution: padding O, output size == input size - stride
filter를 밀도를 조정할 수 있다.
3. Pooling
- Max Pooling
☑️ what) 최댓값을 filtering하며, 가장 현저한 값만을 다음 layer로 전달해준다. - Average Pooling
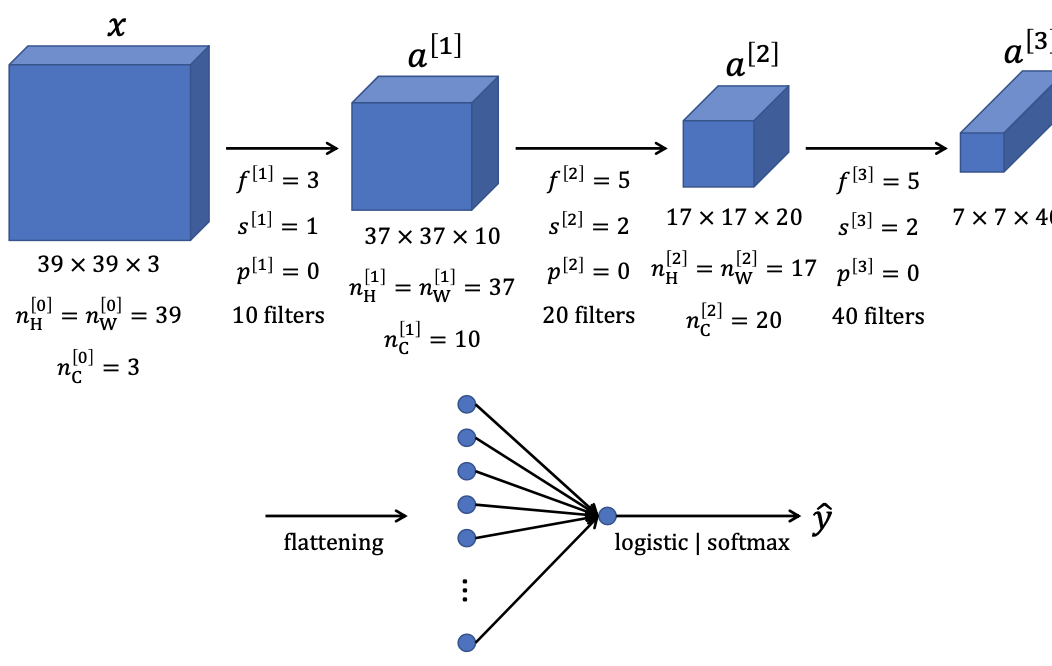
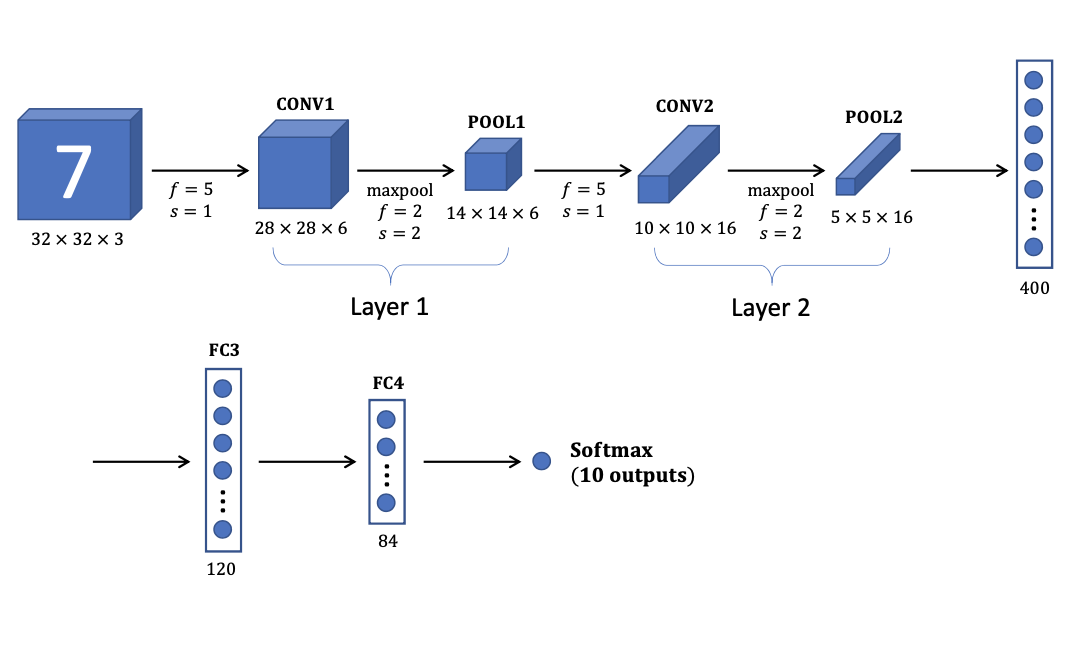
4. CNN Example: LeNet-5
1998년 Yann LeCun이 제안한 CNN 신경망의 구조
2 Object Detection
1. Sliding Window
window가 너무 작으면 비용이 커질 수 있으므로 적정 크기를 선택해야한다
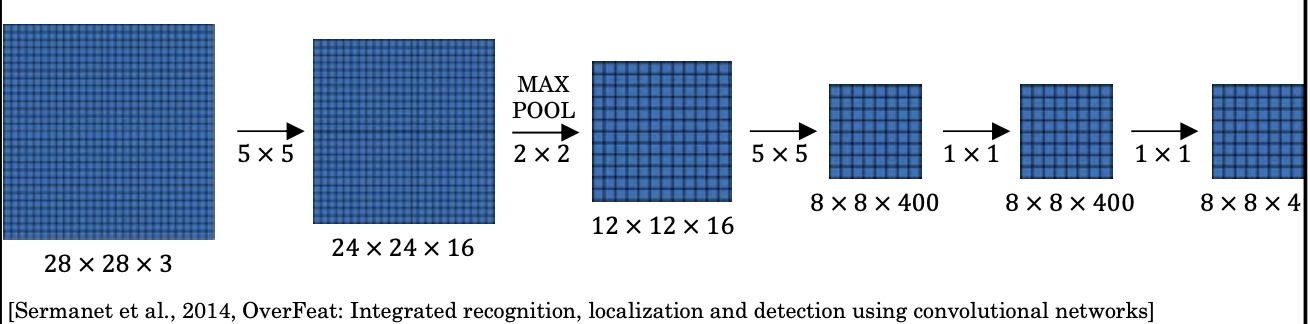
👍🏻 gd) filter로써, convnet의 weight matrix를 그대로 적용해서 사용할 수 있다.
👍🏻 gd) 슬라이딩 윈도우 방식을 활용하면, 학습 시에 조그만 이미지로 학습해도, 사용 시에는 큰 이미지에 적용할 수 있다.
🥲 pb) 윈도우가 object에 걸치면 탐지에 실패한다.

-> sol) YOLO algorithm
2. YOLO Algorithm
[Redmon et al., 2015, You Only Look Once: Unified real-time object detection]
☑️ what) obj의 좌표를 regression하는 방식으로 물체를 탐지한다.

IoU (Intersaction of Union): evaluation measure
3. Non-max Suppression Example
☑️ what) 1obj, 多 bounding box, 최대 확률이 아닌 것은 제외시킨다.
how) algorithm
1. prediction 진행.
2. (너무 낮으면) 제외
3. 가장 큰 값을 가진 박스 선택
4. IoU >= 0.5 인 박스는 버린다.
4. Anchor Box: Overlapping Objects
☑️ what) 多 obj, 1 bounding box
