1 Motivation : Seq2Seq 모델의 한계
- Sequential → 병렬 처리 불가능, 속도 느림
- Long Term Dependency
2 Transformer
☑️ what) 인코더와 디코더를 여러 번 쌓아올린 형태이다. Language Model을 차용하였다.
👍🏻 gd) Positional Encoding으로 병렬 처리 문제를 해결
👍🏻 gd) Attention으로 Long term dependency 문제 해결
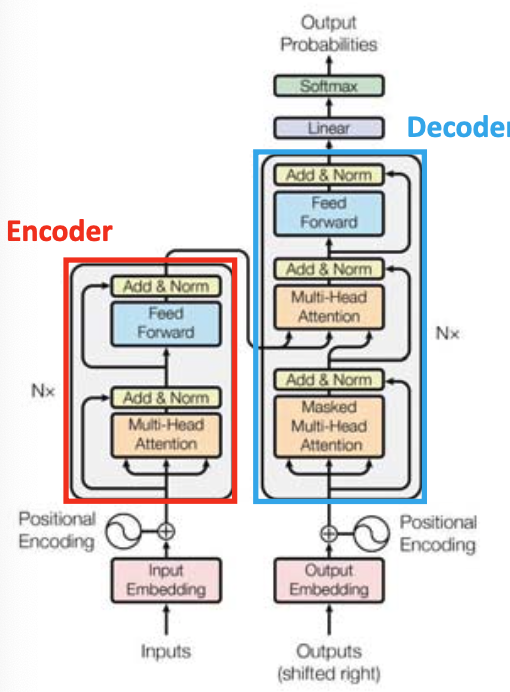
1. Position Encoding
🥲 pb) Transformer는 여러 input이 병렬적으로 들어가므로 순서 정보가 내포되어 있지 않다.
→ sol) 이를 해결하기 위해 순서 정보를 포함한다.
cf) CNN, RNN은 순서 정보가 내포되어 있다.
가 증가함에 따라 (위치가 뒤쪽) 파동함수의 주기가 커진다. 주기로써 위치 정보를 구분할 수 있다.
2. Attention
1) Self-Attention by Scaled Dot-Product Attention
☑️ what) Scaled Dot-Product Attention이란?
주변 단어들과의 유사도를 측정하고, 유사도에 기반한 word vector 가중합을 통해 새로운 word vector를 만들어 내는 기법❓ why) Word2Vec을 바로 사용하면 단어에 문맥을 반영할 수 없다.
Q(query), K(key), V(value)
2) Multi-Head Attention
☑️ what) Q, K, V에 대하여 scaled dot-product attention을 여러 번 시행한다.
❓why) 한 문장에도 여러 문맥이 있을 수 있기 때문.
3) Masted Multi-Head Attention
☑️ what) 앞 단어들에 대해서만 attention을 한다.
❓ why) 아직 예측하지 않은 부분은 알 수 없음을 반영한다.
how) matrix의 일부를 0으로 채운다.
