0 Word Embedding
☑️ what) word를 vector로 매핑시키는 것. (Word Representation)
❓ why) NLP에서 text 데이터를 다루기 위해서text를vector로 표현해야 한다.
how) One-hot Encoding, Latent Sentiment Analysis, NNLM, RNNLM, Word2vec, Glove, FastText, …
1 One-Hot Encoding
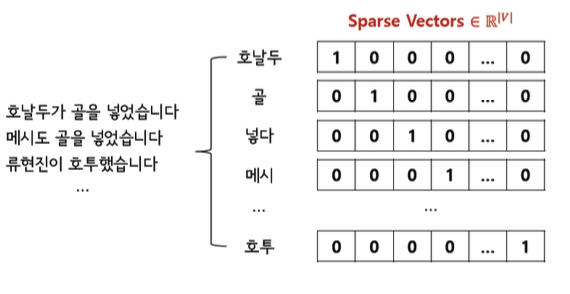
☑️ what) 단어의 개수만큼 차원을 늘려서 단어가 있는 위치에만 1을 표시해준다.
🥲 pb1) Curse of Dimensionality. ( 단어의 개수 vecotr의 차원)
🥲 pb2) Sparsity
🥲 pb3) word 간의 유사성, 연관성을 표현 不可 ( 모든 벡터가 orthogonal 하며 거리가 같다)
2 Word2vec
☑️ what) word의 Disributed Representation을 만드는 word embedding model. 2013년 구글에서 제안.
👍🏻 gd) 이전 모델들보다 계산 복잡도는 작고 성능은 높다.
👍🏻 gd) 단어 간의 유사성, 연관성을 표현할 수 있다.
1) CBOW (Continuous Bag-Of-Words)
문맥 → 단어
2) Skip-Gram (Continuous Skip-Gram)
단어 → 문맥
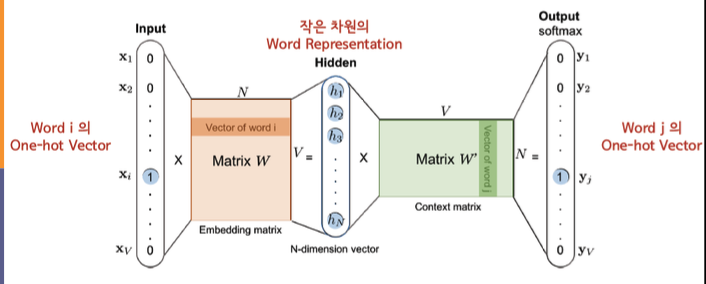
- input, output은
one-hot encoding형태이다. - W의 i번째 행() == Word Representation == Latent Vector ( one-hot encoding)
