
브라우저의 돔 객체에 접근하기 위한 방식으로는 querySelector와 getElementById 양대산맥을 이룬다.
<div>
<div class="apple" id="apple__1"></div> <!--이 요소를 선택하는 상황-->
<div class="apple" id="apple__2"></div>
</div>// querySelector 이용
const apple = document.querySelector("#apple__1")
// getElementById 이용
const apple = document.getElementById("apple__1")두 방식 모두 매개변수로 '가져오고 싶은 돔 요소의 특징'을 받고
해당 특징을 가진 [Element](https://developer.mozilla.org/en-US/docs/Web/API/Element)를 리턴한다. (그런 요소가 없다면 null을 반환한다)
똑같은 기능을 수행하는데 왜 함수가 여러개 있는걸까? 둘의 차이점은 무엇일까?
라는 궁금증이 생겨 여러가지를 공부해 보았고
관련한 한글 자료가 별로 없는 것 같아서
이 글에는 두 DOM 메소드의 특징과 차이점을 위주로 정리하였다.
querySelector('선택자')
The matching is done using depth-first pre-order traversal of the document's nodes starting with the first element in the document's markup and iterating through sequential nodes by order of the number of child nodes.
querySelector는 깊이 우선 탐색(DFS) 방식으로 DOM Tree를 순회해 해당 속성을 가진 요소를 찾는다.
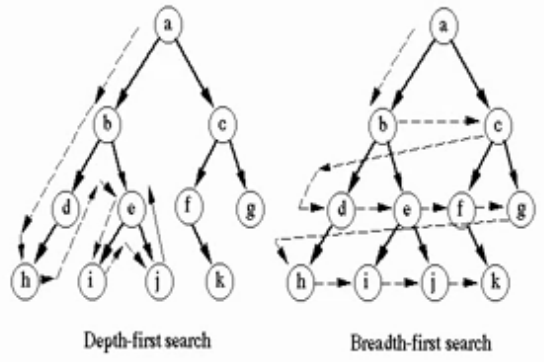
출처 : https://12bme.tistory.com/122
위 그림 중 좌측 방식으로 요소를 탐색하기 때문에
(각 노드가 HTML Element 노드라고 생각하고 이해하면 편하다)
querySelector() 메소드의 특징
- HTML에 적혀 있는 순서대로 탐색이 일어난다.
- 하나의 요소만 찾아도 탐색이 중단되고 그 요소를 리턴한다.
- 부모 이후 순서로 부모의 자식을 순회하러 가기 때문에 다음 선택자 또한 사용 가능하다.
const loginInput = document.querySelector("div.user-panel.main input[name='login']");document뿐만 아니라 하위 Node에 대해서도querySelector()을 사용할 수 있다. 이 때는 해당 노드를 루트로 하는 서브 트리에서 DFS로 요소를 찾는다.
getElementById('id')
The Document method getElementById() returns an Element object representing the element whose id property matches the specified string. Since element IDs are required to be unique if specified, they're a useful way to get access to a specific element quickly.
getElementById는 매개변수로 받은 id값을 id로 갖고 있는 Element를 리턴한다.
getElementById의 경우 브라우저 별로 구현 방식이 다를 수 있다.
각 ID와 요소에 대한 해쉬 테이블을 만들어 getElementById를 수행할 수도 있으며, querySelector와 같이 DFS를 이용할 수도 있다.
이 부분에 대해서는 더 조사하고 싶었지만 자료가 부족했다..
getElementById() 메소드의 특징
- id값은 unique하므로 (해당 HTML에서 유일하므로), 특정된 엘리먼트에 빠르게 접근해야 할 때 유용하다.
document에 대해서만getElementById()를 사용할 수 있고, 하위 Node들에 대해서는 사용할 수 없다.
* id 값은 전체 document에서 유일하므로 범위를 좁혀 탐색하는 함수가 존재할 필요가 없기 때문이다.- 만약 해당 id를 가진 요소가 여러 개 존재한다면, (DFS로 구현하는 브라우저의 경우) HTML 상에서 더 위에 적혀 있는 요소를 리턴한다. (이런 경우는 없어야 한다!!!!)
결론
위 특성들과 작동 원리를 공부하며 얻은 결론은 다음과 같다.
- id가 특정된 요소에 대해서는 가급적 getElementById를 사용하는게 좋다.
DFS로 구현된 브라우저에서는 성능이 같겠지만, 그렇지 않은 브라우저에서는getElementById가 더 빠를 테니까! - 트리 순회로 탐색이 일어나므로 무의미하게 트리 깊이를 키우지 말자.
- HTML 표준을 어겨가며 한 문서 안에 unique하지 않은 id를 넣어두지 말자. (=id 값에는 중복이 없도록 하자!)
참고 문헌
https://stackoverflow.com/questions/34756944/how-is-document-queryselector-implemented
https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector
https://developer.mozilla.org/ko/docs/Web/API/Document/getElementById
https://www.tutorialspoint.com/how-getelementbyid-works-in-javascript
https://stackoverflow.com/questions/30371253/how-does-document-getelementbyid-search-the-dom-tree

이런 차이가 있었네요. 좋은 글 감사합니다!