Tensorflow.js로 백엔드 없이 딥러닝 모델 이용하기

Tensorflow.js 시작하기
https://js.tensorflow.org/api/latest/?hl=ko
위 API 문서를 읽어보면, 파이썬 텐서플로우 라이브러리에 있던 웬만한 함수들은 다 사용할 수 있다는 걸 알 수 있다. (스네이크 케이스에서 자바스크립트 컨벤션에 맞게 카멜 케이스로 변경했다는 점 정도의 차이가 있다)
머신러닝 입문자에게 선택지가 파이썬밖에 없었던 과거와 달리 우리는 참 살기 좋은 세상에 살고 있다.
무려 자바스크립트로, 무려 웹 프론트엔드에서 백엔드 없이(물론 백엔드로도 할 수 있다) 공짜로 텐서플로우를 사용할 수 있다니 .. 난 감동을 받지 않을 수 없었다.
이러한 바탕에도 불구하고 한글로 tensorflow.js 관련 작업을 한 문서가 많지 않아서 글을 작성하기로 마음먹었다.
프로젝트 소개
자바스크립트로 머신러닝 라이브러리를 쓸 수 있는 살기 좋은 세상에 살면서 이를 활용한 토이프로젝트를 하지 않을 수는 없었다. 방학 시작하고 계속 바빴지만 조금이라도 짬을 내서 토이프로젝트를 완성했다.
결과물
아래 깃허브 배포 사이트에서 볼 수 있다.
깃허브 배포 사이트에서 볼 수 있다는건!! 따로 백엔드를 안 썼다는것!! 텐서플로우 만세만세만만세!!
https://seojinseojin.github.io/frontend-practice/tensorflow-js/
모델
https://colab.research.google.com/drive/1MrlSBHAftjE1SpLnIkcSExgfxypr0N_P?usp=sharing
딥러닝 스터디에서 만들었던 포켓몬 분류 모델을 사용했다. 정답률은 0.6으로 그렇게 높지는 않은 친구였고, 나중에 레이어 수정 및 이미지 처리를 통해 오버피팅을 막아야 한다.
일단 헐레벌떡 텐서플로우js를 써보고 싶어서 가져온 모델이다.
구현 과정
WebCam을 사용하여 이미지 얻기
webcam의 경우, 라이브러리인 webcam-easy를 쓸 것이다.
https://www.npmjs.com/package/webcam-easy
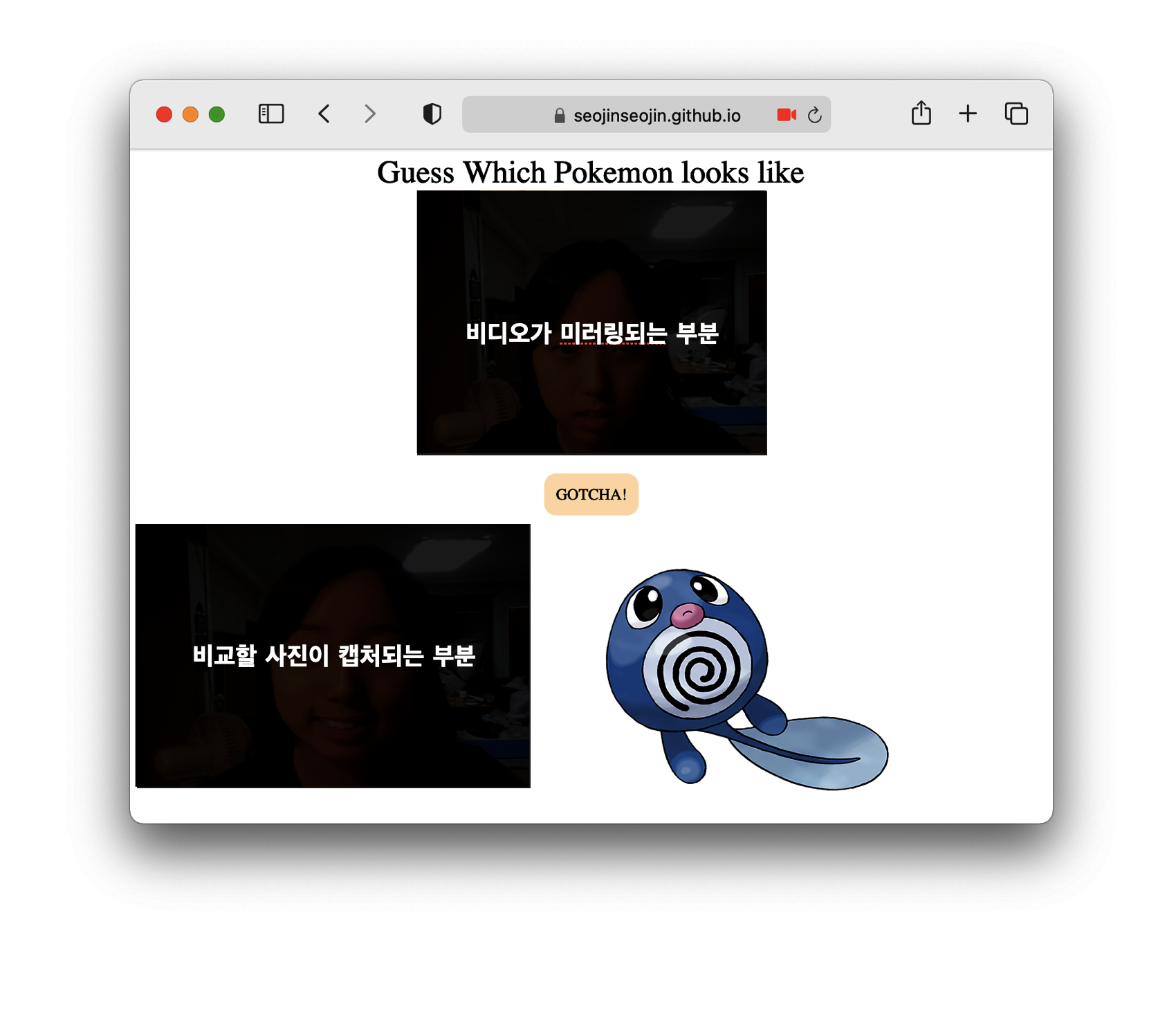
index.html
<script type="text/javascript" src="https://unpkg.com/webcam-easy/dist/webcam-easy.min.js"></script>우선 상단에 webcam-easy를 쓸 수 있는 cdn을 넣어준다.
<video id="webcam" autoplay playsinline width="600" height="400"></video>
<div id="btn-capture">GOTCHA!</div>
<canvas id="canvas" class="d-none"></canvas>
<image id="result" src=""></image>웹캠을 사용할 HTML 요소들을 정의해준다.
video는 현재 웹캠에서 찍히고 있는 영상이 출력되는 부분,
canvas는 webcam.snap() 함수를 호출할 경우 찍힌 사진이 저장될 부분이다.
const webcamElement = document.getElementById('webcam');
const canvasElement = document.getElementById('canvas');
const snapSoundElement = document.getElementById('snapSound');
const snapBtn = document.getElementById("btn-capture")
const webcam = new Webcam(webcamElement, 'user', canvasElement, snapSoundElement);
const pokemonData = JSON.parse(JSON.stringify(pokemons));
webcam.start()
.then(result =>{
console.log("webcam started");
})
.catch(err => {
console.log(err);
});
snapBtn.onclick = () => {
const picture = webcam.snap()
}각 요소들을 js에서 불러오고 콜백함수를 달아 줬다.
이제 snapBtn이 눌릴 때마다 canvas에 사진이 담긴다.
h5모델을 Tensorflowjs에서 쓸 수 있는 모델로 변환하기
https://www.tensorflow.org/js/tutorials/conversion/import_keras?hl=ko
위 가이드라인을 따라 변환해준다.
tensorflowjs_converter --input_format keras path/to/my_model.h5 path/to/tfjs_target_dirpath/to/my_model.h5에 h5파일의 상대 경로를 적어주고
path/to/tfjs_target_dir에 변환된 모델들이 저장될 경로를 적어준다.

해당 명령어를 수행하면 위와 같은 파일들이 생성되고,
const model = await tf.loadLayersModel('./model/model.json')위의 명령어로 모델을 불러올 수 있다.
즉, 이제 model.json의 위치만 알면 모델을 사용할 수 있다.
Tensorflowjs로 이미지 분류하기
let myFaceImage = tf.browser.fromPixels(webcamElement)
myFaceImage = tf.image.resizeBilinear(myFaceImage, [128,128])
myFaceImage = tf.expandDims(myFaceImage, 0)
const prediction = model.predict(myFaceImage)//.strides.findIndex(ele => ele==1)
const predictionArray = prediction.dataSync()
console.log("prediction", prediction)
const maxValue = predictionArray.indexOf(Math.max(...predictionArray))나름 많은 시행착오 끝에 작성된 코드이다.
-
tf.browser.fromPixels: 다른 문서에는tf.fromPixels함수를 사용하는 경우도 있는데, 이는 deprecate되었으니 꼭tf.browser.fromPixels를 써줘야 한다. -
tf.image.resizeBilinear(),tf.expandDims()
tensorflow js expected conv2d_6_input to have 4 dimension(s), but got array with shape __이라는 에러를 해결해주기 위해 이미지의 형태를 맞춰준 것이다
from PIL import Image
from tensorflow.keras.preprocessing.image import img_to_array
image = image.resize((128, 128))
image=img_to_array(image)
prediction_image=np.array(image)
prediction_image= np.expand_dims(image, axis=0)
파이썬 코드에서 돌려볼 때는 위와 같이 실행한 것과 같은 셈이다.prediction.dataSync(): predict한 결과값인 array를 받으려면 위와 같이 받아와야 한다.
결과

내 얼굴로 하면 이상한 포켓몬이 나와서 모델에 이상이 있나 걱정이 됐는데 다행히 파이리를 넣으니 파이리가 잘 나온다.
다음번에 만약 얼굴 갖고 비슷한 포켓몬을 찾고 싶다면, 귀엽고 예쁘고 사람같은 아이들만 데이터셋에 넣어야 겠다는 생각이 들었다.

만약 즐거운 마음으로 테스트를 했는데 이런 포켓몬이 자신과 닮았다고 하면 얼마나 상처받을까?
그런 일을 막을 수 있는 귀염예쁨 데이터셋을 만들어서 다시 업데이트해야겠다는 결심을 할 수 있엇다.
https://github.com/SeojinSeojin/frontend-practice/tree/master/tensorflow-js
작성된 코드는 이곳에서 볼 수 있습니다.
잘 활용하셔서 즐겁고 유익한 프로젝트 하시길 바라요!
