문자열 함수는 텍스트 열에서 다양한 연산을 수행할 수 있도록 해줍니다. 따라서 MySQL에서는 문자열 함수를 활용하여 데이터를 조회할 때 여러 방식으로 표현할 수 있습니다. 먼저 포스팅에 쓸 데이터와 테이블을 선언하겠습니다.
CREATE TABLE books
(
book_id INT NOT NULL AUTO_INCREMENT,
title VARCHAR(100),
author_fname VARCHAR(100),
author_lname VARCHAR(100),
released_year INT,
stock_quantity INT,
pages INT,
PRIMARY KEY(book_id)
);
INSERT INTO books (title, author_fname, author_lname, released_year, stock_quantity, pages)
VALUES
('The Namesake', 'Jhumpa', 'Lahiri', 2003, 32, 291),
('Norse Mythology', 'Neil', 'Gaiman',2016, 43, 304),
('American Gods', 'Neil', 'Gaiman', 2001, 12, 465),
('Interpreter of Maladies', 'Jhumpa', 'Lahiri', 1996, 97, 198),
('A Hologram for the King: A Novel', 'Dave', 'Eggers', 2012, 154, 352),
('The Circle', 'Dave', 'Eggers', 2013, 26, 504),
('The Amazing Adventures of Kavalier & Clay', 'Michael', 'Chabon', 2000, 68, 634),
('Just Kids', 'Patti', 'Smith', 2010, 55, 304),
('A Heartbreaking Work of Staggering Genius', 'Dave', 'Eggers', 2001, 104, 437),
('Coraline', 'Neil', 'Gaiman', 2003, 100, 208),
('What We Talk About When We Talk About Love: Stories', 'Raymond', 'Carver', 1981, 23, 176),
("Where I'm Calling From: Selected Stories", 'Raymond', 'Carver', 1989, 12, 526),
('White Noise', 'Don', 'DeLillo', 1985, 49, 320),
('Cannery Row', 'John', 'Steinbeck', 1945, 95, 181),
('Oblivion: Stories', 'David', 'Foster Wallace', 2004, 172, 329),
('Consider the Lobster', 'David', 'Foster Wallace', 2005, 92, 343);CONCAT
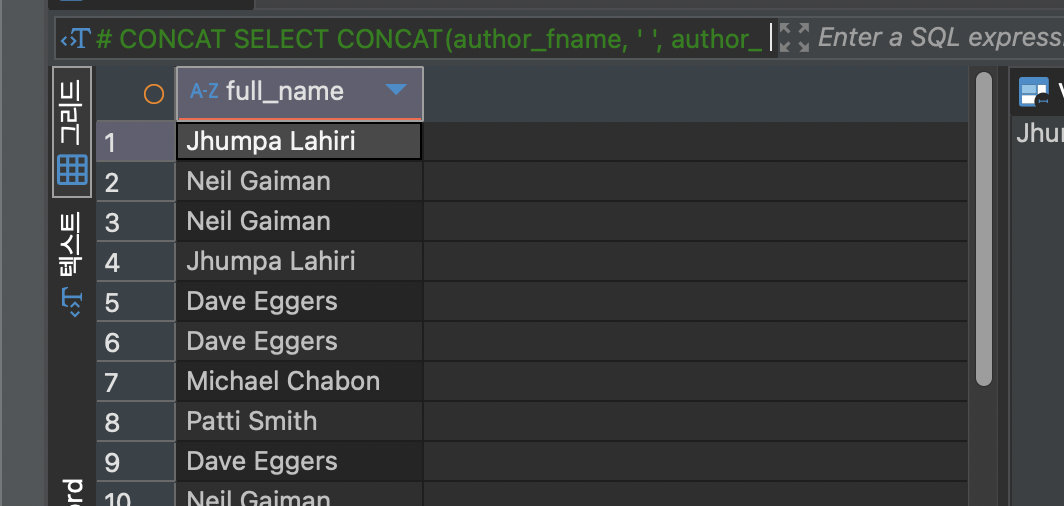
CONCAT 는 문자열을 연결하거나 결합하는 함수입니다.
SELECT CONCAT(author_fname, ' ', author_lname) as full_name FROM books;위 코드는 author_fname 과 author_lname 의 문자열을 합치는 코드입니다.
코드의 결과는 다음과 같습니다.
CONCAT_WS
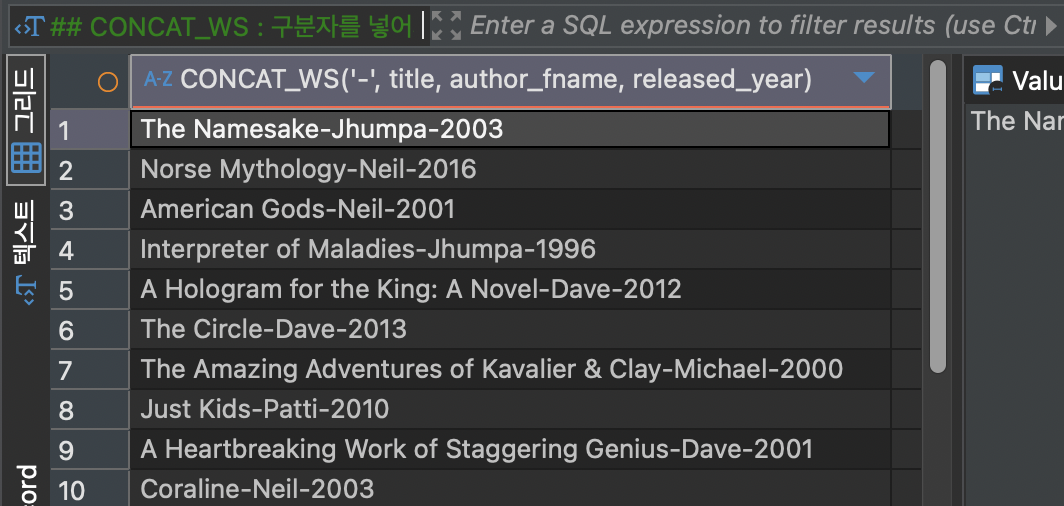
CONCAT_WS 는 문자열 사이에 구분자를 넣어 합치는 함수입니다.
SELECT CONCAT(title,'-', author_fname,'-', released_year) FROM books;위 코드는 title, author_fname, released_year 사이에 '-'를 넣어 합치는 코드입니다.
코드의 결과는 다음과 같습니다.
SUBSTRING
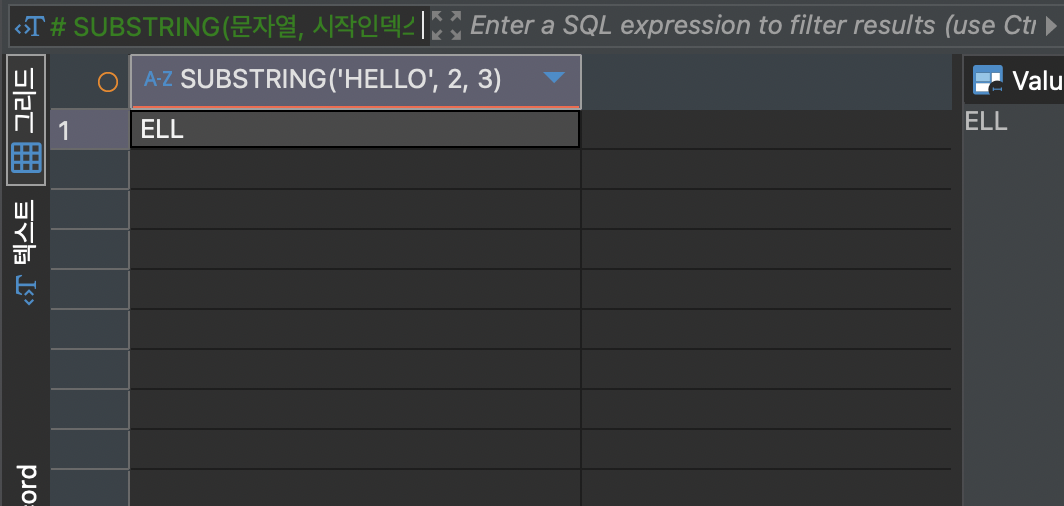
SUBSTRING 은 문자열에서 원하는 부분을 잘라낼 때 사용되는 함수입니다. 파이썬의 슬라이싱과 유사합니다.
하지만 파이썬과 다르게 인덱스는 0번이 아닌 1번부터 시작합니다. SUBSTRING 을 사용하는 방법은 다음과 같습니다.
SUBSTRING(문자열, 시작인덱스, 문자 개수)SELECT SUBSTRING('HELLO', 2, 3);위 코드는 'HELLO'에서 인덱스 2번부터 3글자를 출력한다는 의미입니다. 코드의 결과는 다음과 같습니다.
그리고 문자 개수를 지정하지 않으면 제일 끝에 있는 문자까지를 추출합니다.
SELECT SUBSTRING('HELLO', 2);위 코드의 결과는 다음과 같습니다.
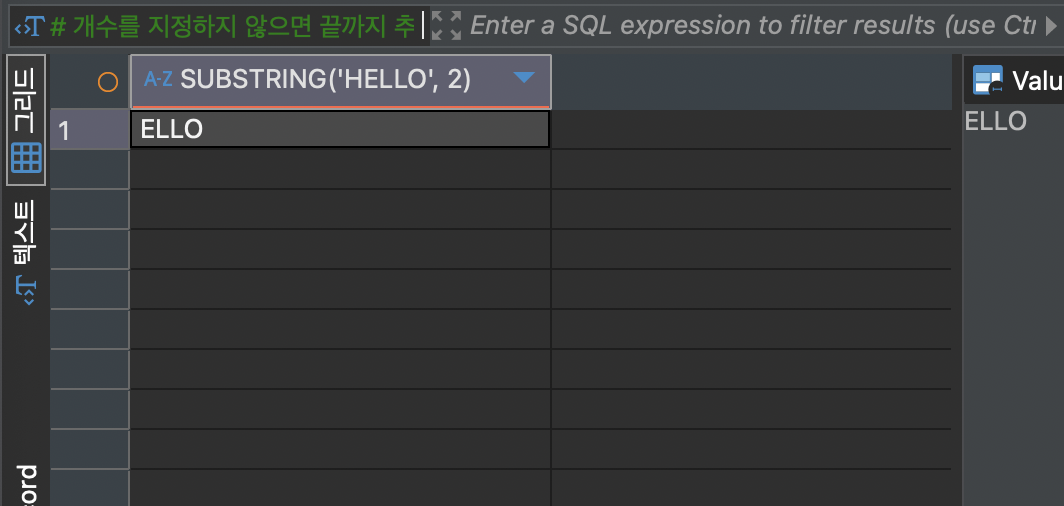
REPLACE
REPLACE 는 문자열을 치환할 때 사용하는 함수입니다. 사용 방법은 다음과 같습니다.
REPLACE(원본 문자열, 바꿀 문자열, 바뀔 문자열)SELECT REPLACE(title, ' ', '-') FROM books;위 코드의 결과는 다음과 같습니다.
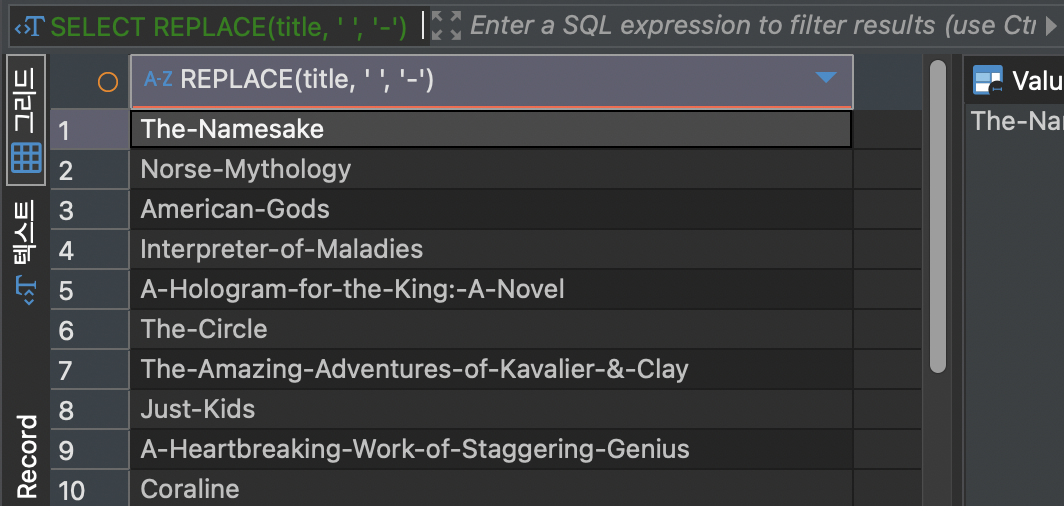
CHAR_LENGTH, LENGTH
CHAR_LENGTH 와 LENGTH 는 문자열의 길이를 잴 때 사용됩니다. 두 함수 모두 영어 문자열에 사용할 땐 같은 값이 나오지만 다른 언어를 사용할 때 다르게 나옵니다. LENGTH 는 문자열의 바이트 수를 반환하는 함수이며 CHAR_LENGTH는 문자열의 문자 개수를 반환하는 함수입니다.
SELECT LENGTH("민수"), CHAR_LENGTH("민수");위 코드의 결과는 다음과 같습니다.
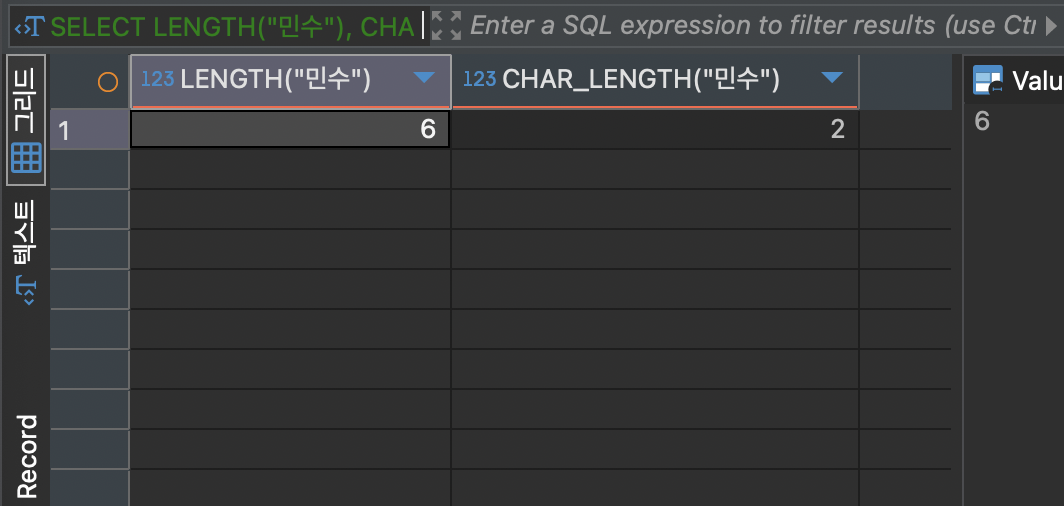
위 결과를 보면 LENGTH은 문자열의 바이트 수인 6이 출력되며 CHAR_LENGTH 은 문자열의 문자 개수인 2가 출력됩니다.
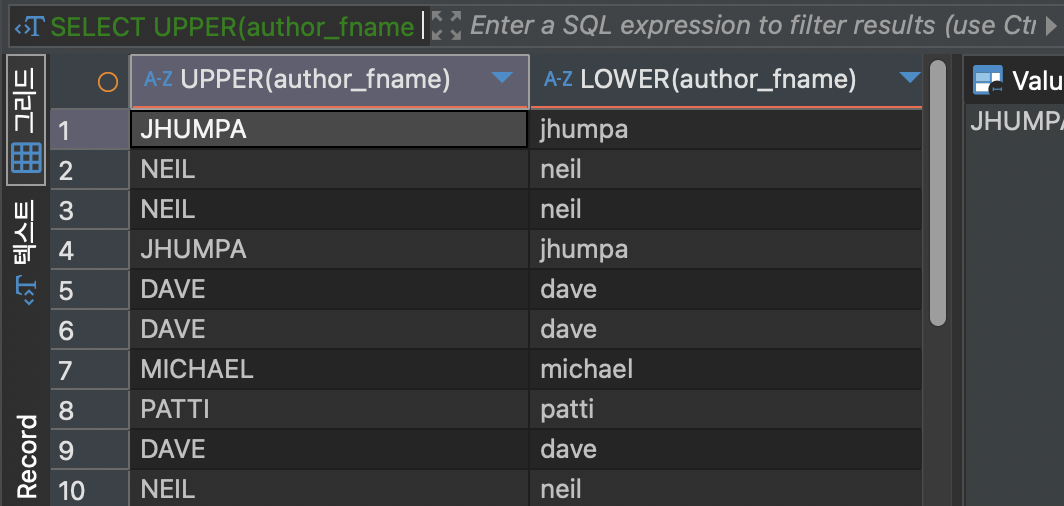
UPPER, LOWER
UPPER 와 LOWER 는 각각 대문자, 소문자로 문자열을 변한하는 함수입니다.
SELECT UPPER(author_fname), LOWER(author_fname) FROM books;위 함수의 결과는 다음과 같습니다.