pandas
NumPy 기반 설계
시리즈 데이터와 데이터 프레임
NumPy의 array가 보강된 형태
Data와 Index를 가지고 있음
- Series
: values 를 ndarray 형태로 가지고 있음
import pandas as pd
data = pd.Series([1, 2, 3, 4])
print(data)
# 0 1
# 1 2
# 2 3
# 3 4
# dtype : int64pirnt(type(data)) #<class 'pandas.core.series.Series'> print(data.values) # [1 2 3 4] print(type(data.values)) #<class 'numpy.ndarray'>
-
dtype인로 데이터 타입을 지정 가능!
int.정수 -> float.실수data = pd.Series([1, 2, 3, 4], dtype = "float") print(data.dtype) #float64 -
인덱스를 지정할 수 있고 인덱스로 접근 가능
data = pd.Series([1, 2, 3, 4], index = ['a', 'b', 'c', 'd'])
data['c'] = 5 #인덱스로 접근하여 요소 변경 가능
- Dictionary를 활용하여 Series 생성 가능
population_dict = { 'china' : 141500, 'japan' : 12718, 'korea' : 5180 'usa' : 32676 } population = pd.Series(population_dict)

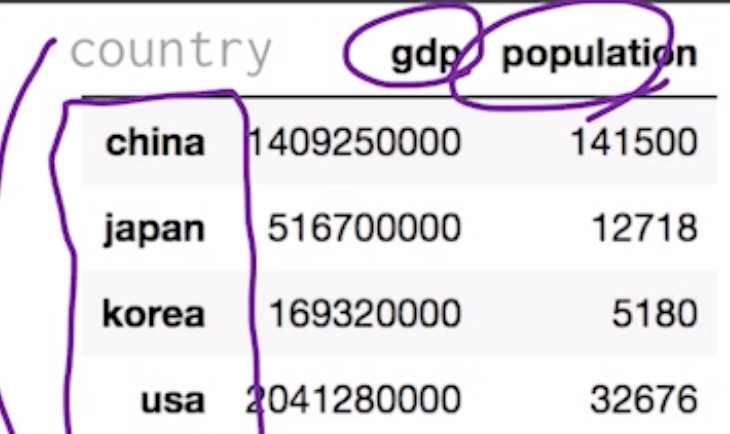
dataFrame
- 여러 개의 Seires가 모여서 행과 열을 이룬 데이터
country = pd.DataFrame({ 'gdp' : gdp, 'population' : population })
- Dictionary를 활용하여 DataFrame 생성가능
data = { 'country' : ['china', 'japan', 'korea', 'usa'], 'gdp' : [140, 51, 16, 204], 'population' : [141, 12, 5, 32] } country = pd.DataFrame(data) country = country.set_index('country')
1) dictionary : data = {key:value}
2) Series : series([1, 2, 3, 4])
3) DataFrame : 인덱스 - 시리즈 데이터
4) 딕셔너리에서 시리즈를 거치지 않고서도 바로 데이터 프레임을 만들 수 있다.
-
DataFrame 속성을 확인하는 방법 (6세대 포캣몬, 프레임은 뚜껑 같은 존재)
print(country.shape) # (4, 2) print(country.size) # 8 갯수 print(country.ndim) # 2 몇 차원인가 print(country.values) #[[ -
DataFrame의 index와 column에 이름 지정 가능
country.index.name = "Country" # 인덱스에 이름 지정 country.columns.name - "Info" # 칼럼 이름 지정 -
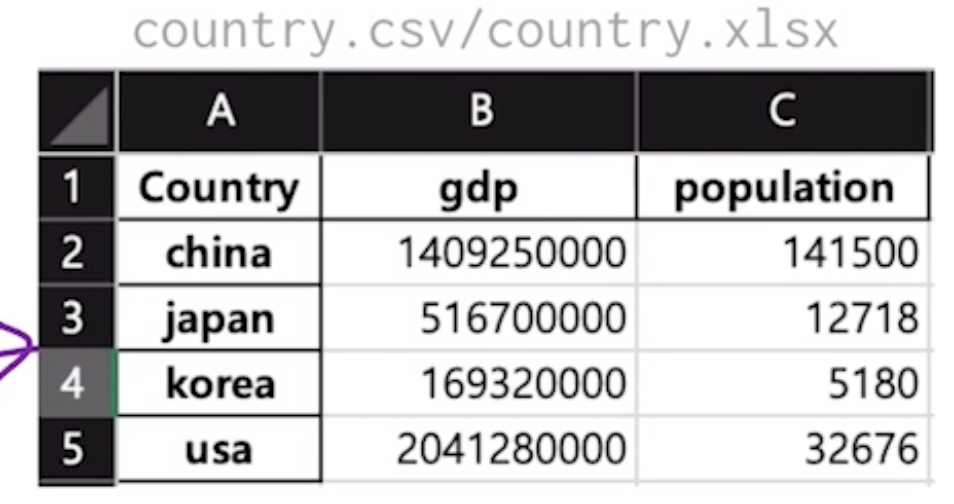
데이터프레임 저장 및 불러오기 기능
country.to_csv("./country.csv") country.to_excel("country.xlsx")
country = pd.read_csv("./country.csv") country = pd.read_excel("country.xlsx")
데이터 선택
indexing/Slicing
- loc : 명시적인 인덱스를 참조하는 인덱싱/슬라이싱
country.loc['china'] # 인덱싱

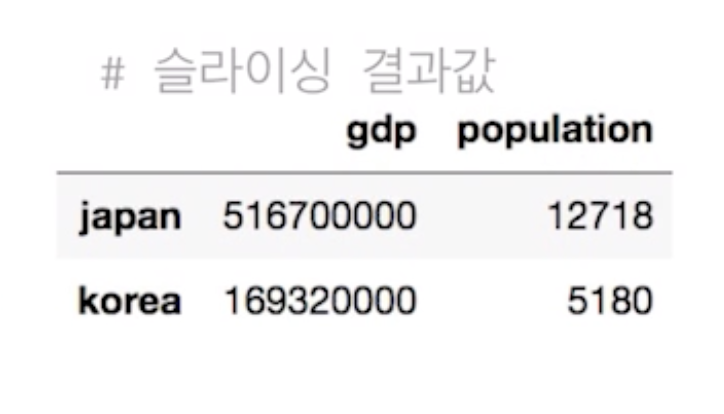
country.loc['japan' : 'korea', :'population'] # 슬라이싱
- iloc : 파이썬 스타일의 정수 인덱스 인덱싱/슬라이싱 (암묵적인 순서가 있고, 그것에 따라서 값을 추출하는 것)
e) 최진사 댁 딸 7명. 그 둘째 딸 시집 갔나? 이런식으로 값을 추출하는 것
country/iloc[0] # 인덱싱

country.iloc[1:3, :2] # 슬라이싱
- 컬럼명 활용하여 DataFrame에서 데이터 선택 가능
country['gdp'] : 컬럼 country[['gdp']] : 데이터 프레임 그 자체
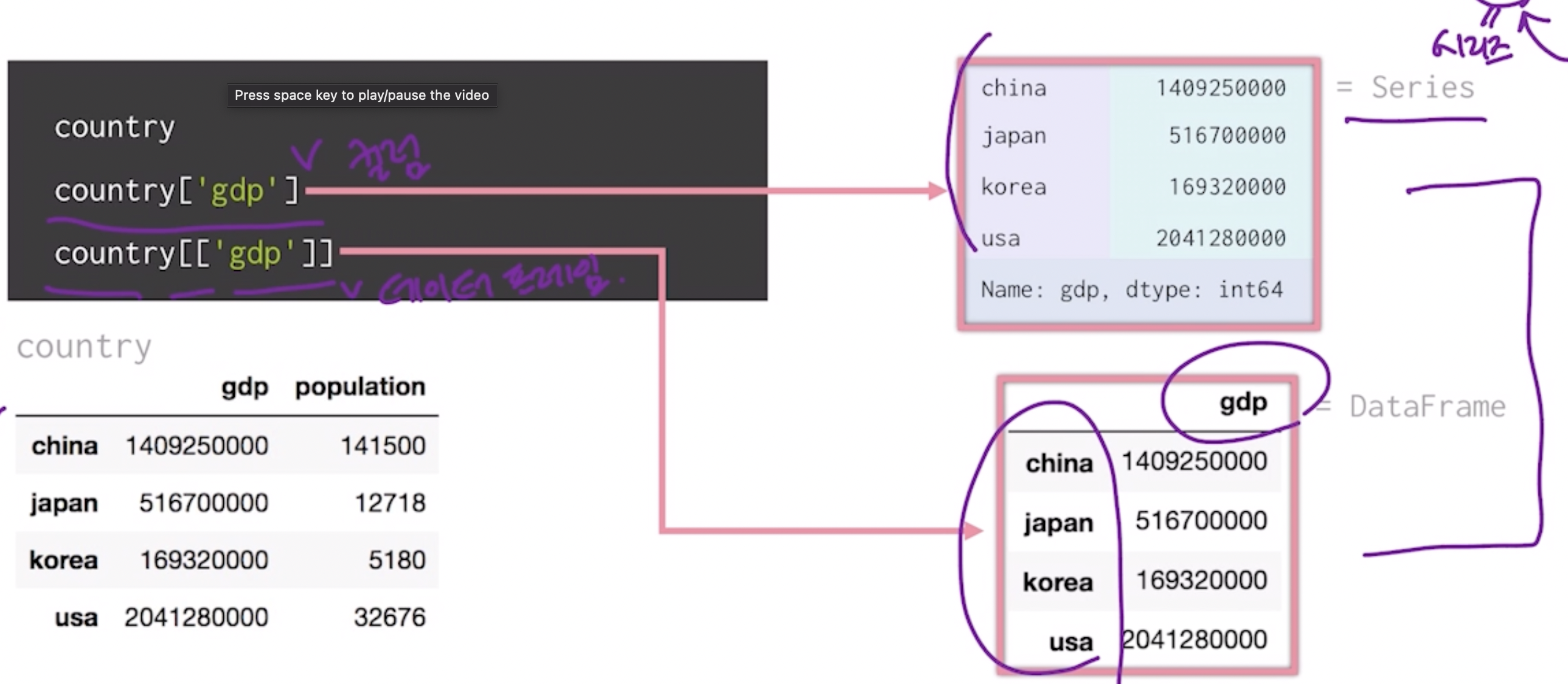
[]는 컬럼, 즉 gdp에 해당하는 값만
[[]]는 데이터 프레임 자체, gdp라는 뚜껑까지 함께
데이터선택 - 조건활용
masking 연산이나 query함수를 활용하여 조건에 맞는 dataframe 행 추출 가능
country[country['population'] < 10000] # masking 연산 활용 country.query("population>100000") # query 함수 활용
- masking은 [country '조건 ' ] 을 넣어줌
- query함수는 쿼리 안에 "조건"을 활용
series도 연산자 활용 가능
gdp_per_capita = country['gdp'] / country['population'] country['gdp per capita'] = gdp_per_capita
데이터 변경 - 데이터 추가/수정
리스트로 추가 or 딕셔너리로 추가
df = pd.DataFrame(columns = ['이름, '나이', '주소']) #데이터프레임 생성 df.loc[0] = ['길동', '26', '서울'] #리스트로 데이터 추가 df.loc[1] = {'이름':'철수', '나이':''25', '주소':'인천'} #딕셔너리로 데이터 추가 df.loc[1, '이름'] = '영희' #명시적 인덱스 활용하여 데이터 수정
데이터 변경 - NaN 컬럼 추가
NaN값으로 초기화 한 새로운 컬럼 추가
@ nan = not a number
df['전화번호'] = np.nan #새로운 컬럼 추가 후 초기화 df.loc[0, '전화번호'] = '01012341234' #명시적 인덱스 활용하여 데이터 수정

컬럼삭제
DataFrame 에서 컬럼 삭제 후 원본 변경
df.drop('전화번호', axis = 1, inplace = True) #컬럼 삭제 #axis = 1 : 열 방향 / axis = 0 : 행 방향 #inplace = True : 원본 변경 / inplace = False : 원본 변경 x

무럭무럭자라라