문제 : 생선의 크기, 무게 등이 주어졌을때 럭키백에 들어간 생선의 확률을 알려주자!
① k-최근접 이웃 방법 이용
-
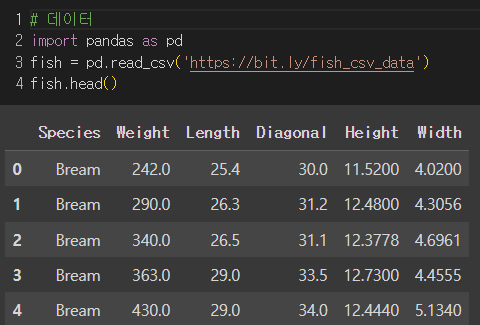
데이터준비
-
타깃데이터 : 생선의 종류

▶ 다중분류 : 타깃데이터에 2개 이상의 클래스가 포함된 경우
이 경우에도 물고기의 종류가 7가지로, 타깃데이터가 7개이므로 다중분류에 해당.
-
입력데이터 : 생선의 무게, 길이 등 총 5가지 특성

-
훈련 세트와 테스트 세트로 나누기

-
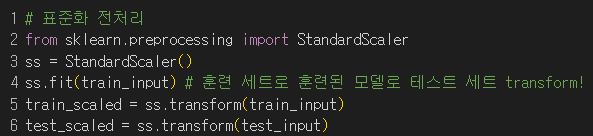
★ 데이터 표준화 전처리
-
최근접 이웃을 3개로 해서 모델 훈련

-
🚨주의🚨
타깃값을 그대로 사이킷런에 전달하면 순서가 자동으로 알파벳순이 되므로 KNeighborsClassifier에서 정렬된 타깃값 kn.classes_를 사용할 것!

-
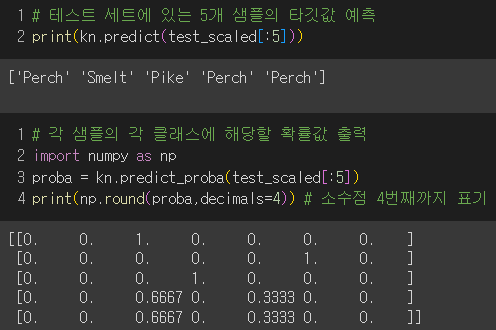
테스트 세트의 5개 샘플에 대해 예측 타깃과 확률값 출력
-
4번째 샘플의 3개의 최근접 이웃이 뭔지?

→ 여기서 원리는 3개의 이웃 중 2개가 Perch이므로 2/3의 확률로 4번째 샘플을 Perch로 클러스터링함!
그러므로, 3개의 최근접 이웃을 사용하면 0, 1/3, 2/3, 1의 확률로 클러스터링하는 방법밖에 없음.
② 로지스틱 회귀
- 선형방정식을 사용한 분류 알고리즘
- ex)
z = a (Weight) + b (Length) + c (Diagonal) + d (Height) + e (Width) + f 일때,
💡로지스틱 함수(시그모이드 함수) :
즉, z가 아주 큰 음수일땐 0 으로, 아주 큰 양수일땐 1이 되도록 바꿔줌.
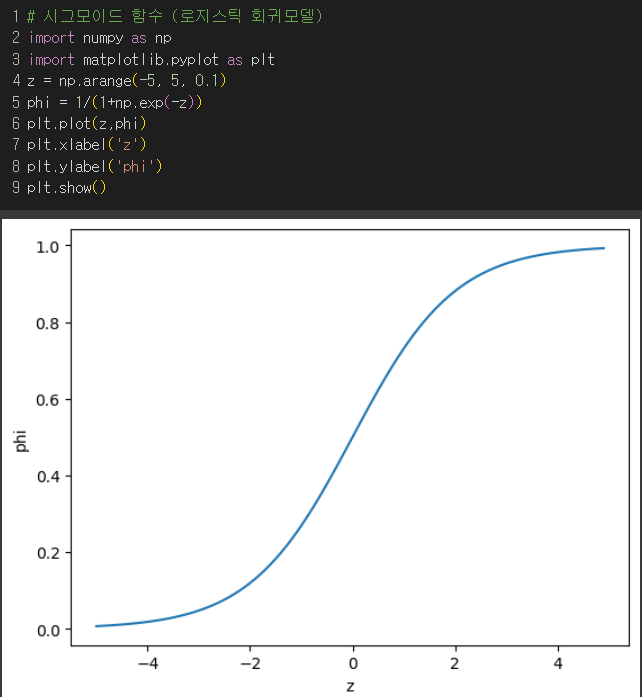
[이진분류]
✔️ 시그모이드 함숫값 ≥ 0.5 : 양성 클래스
✔️ 시그모이드 함숫값 ≤ 0.5 : 음성 클래스
-
도미와 빙어 데이터 골라낸 후 표준화

-
학습세트로 모델 학습
-
5개의 샘플에 대한 예측 타겟과 확률 출력
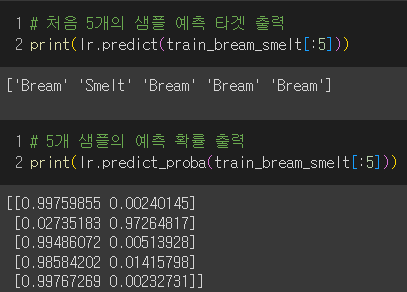
→ 두 개의 클래스(도미, 빙어)에 대한 확률값을 보여주므로 2열로 나타남.
-
타깃 순서 확인

-
로지스틱 회귀계수 확인

→ 무게, 길이 등 5개의 특성에 대한 계수와 상수값
-
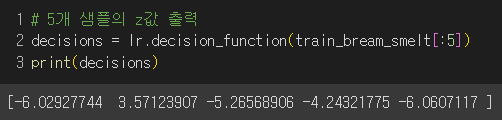
5개 샘플의 z값 출력
-
각 z에 대한 로지스틱 회귀 함숫값 출력

→ 그 결과, 함숫값들과 양성 클래스의 z값과 같은 결과가 나옴.
[다중분류]
-
logistic regression은 반복적인 알고리즘이므로 충분한 훈련을 위해 반복횟수를 1000으로 설정
-
logistic regression은 계수의 제곱을 규제(규제)
이때, 규제를 제어하는 매개변수 C가 커질수록 규제는 작아짐. (C의 기본값 = 1)
cf. 규제인 릿지는 규제를 제어하는 매개변수 α가 커질수록 규제 커짐 -
C = 20, 반복횟수 1000으로 설정 후 모델 훈련

-
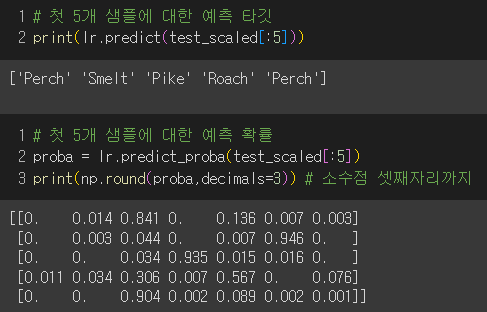
5개 샘플에 대한 예측 타깃값과 확률 출력
-
타깃 순서 확인

-
다중회귀의 계수와 상수 크기 출력

→ 5개의 특성(무게,길이 등)과 7개의 클래스이므로!
- 5개 샘플에 대한 클래스별 z값 구하기
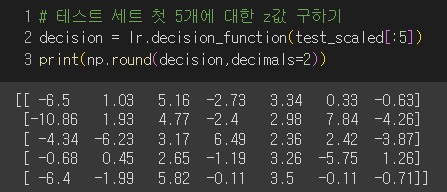
- 💡소프트맥스 함수 : 다중분류에서 z값을 확률로 변환하는 방법
여러 개의 선형방정식의 출력값을 0과 1로 압축하고 전체합이 1이 되도록 만듦.
= + + + + + +
=
- z값을 소프트맥스를 이용하여 각 행에 대해 확률로 변환

→ 앞서 출력한 예측 타깃 확률과 정확히 일치!
미션
p.198 확인문제 2번
답 : ①
- 시그모이드 함수 : 로지스틱 회귀가 이진분류에서 확률을 출력하려고 사용하는 함수
- 소프트맥스 함수 : 다중분류에서 확률을 출력하려고 사용하는 함수
문제 : 기존의 데이터에 새로운 데이터를 추가하여 모델을 매일 다시 훈련해야 한다면?
▶ 점진적 학습 : 기존의 훈련데이터로 훈련한 모델을 버리지 않고 새로운 데이터에 대해 조금씩 더 훈련하는 방법
ex)
ⓐ 확률적 경사 하강법 : 훈련세트로 산 아래 최적의 장소로 가장 가파른 경사를 따라 원하는 지점에 도달하는 것. 이때, 하나의 샘플을 훈련세트에서 랜덤하게 골라서 가장 가파른 길을 찾아 내려가고 산을 다 내려오지 못했다면 훈련세트에 모든 샘플을 다시 채워넣고 랜덤하게 하나의 샘플을 선택해서 경사를 내려감.
ⓑ 미니배치 경사 하강법 : 훈련세트의 여러개의 샘플을 이용해서 경사하강법을 수행하는 방식
ⓒ 배치 경사 하강법 : 극단적으로 한 번 경사로를 따라 이동하기 위해 훈련세트의 전체 샘플 사용
cf. 신경망은 많은 데이터를 사용하므로 한번에 모든 데이터를 사용하기 어렵고 모델이 매우 복잡하여 미니배치나 확률적 경사 하강법을 이용
▶ 손실함수 : 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지 측정하는 기준으로 샘플 하나에 대한 손실을 의미.
ex) 다중분류에서의 크로스엔트로피 손실함수, 평균제곱오차
cf. 비용함수 : 훈련세트에 있는 모든 샘플에 대한 손실함수의 합
✔️손실함수 ↓ : 좋음!
✔️손실함수 ↑ : 알고리즘이 엉터리니까 나쁨.
→ 손실함수의 최솟값을 찾기 위해 확률적 경사 하강법 이용
- 로지스틱 손실함수 : 정확도에 -1을 곱한 후 손실함수가 연속적인 값을 갖도록 로지스틱 함수를 이용
ex)
예측 : 0.9 정답(타깃) : 1 → 손실함수 값 : -0.9
예측 : 0.3 정답(타깃) : 1 → 손실함수 값 : -0.3
예측 : 0.2 정답(타깃) : 0 → 손실함수 값 : -(1-0.2) 1 → -0.8
예측 : 0.8 정답(타깃) : 0 → 손실함수 값 : -(1-0.8) 1 → -0.2
→ 손실이 양수여야 더 이해하기 좋으므로 예측확률에 로그함수를 취한 후 손실값이 양수가 되게 하자!
✔️양성클래스 (타깃=1) : 손실함수 값 : -log(예측확률)
✔️음성클래스 (타깃=0) : 손실함수 값 : -log(1-예측확률)
즉, 예측확률이 0에서 멀어져 1에 가까워질수록 손실은 아주 큰 양수가 됨.
-
데이터 불러온 후 훈련세트와 테스트세트로 나누고 표준화 전처리
-
경사 하강법 이용

-
학습한 모델로 또 학습(점진적 학습)
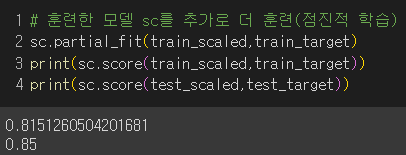
→ 정확도는 향상되었지만 여러 에포크로 더 훈련해볼 필요가 있겠다! 그럼 몇 번이나 해야할까?
✔️ 에포크횟수 ↓ : 훈련세트를 덜 학습 → 과소적합
✔️ 에포크횟수 ↑ : 훈련세트를 많이 학습 → 과대적합
- 에포크 횟수를 늘려가며 점수를 봐보자!
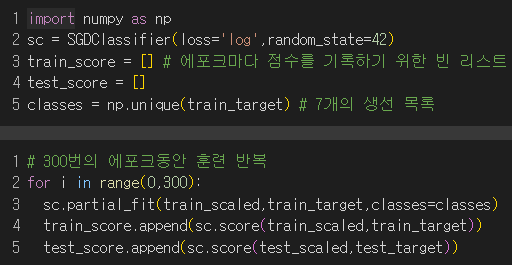
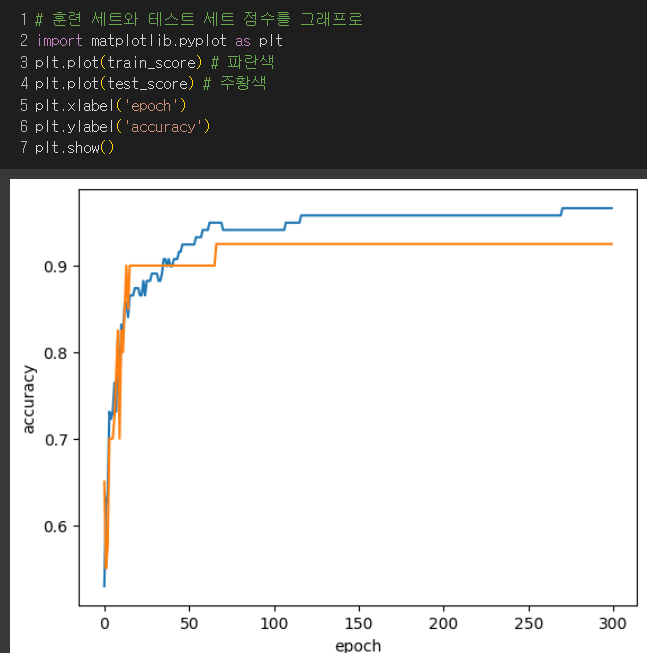
→ 훈련세트와 테스트세트의 점수가 제일 비슷해지는 100번이 적절해보임!
- 100번 훈련
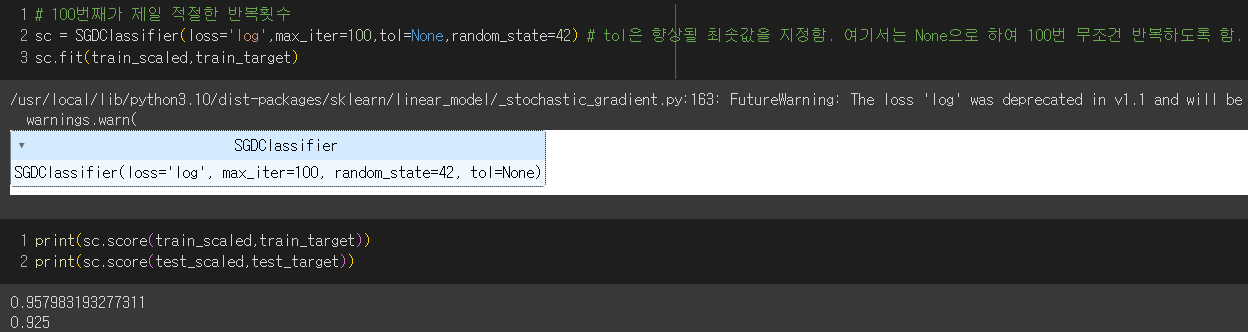
→ 훈련세트와 테스트세트의 정확도 점수가 비교적 높게 나옴!
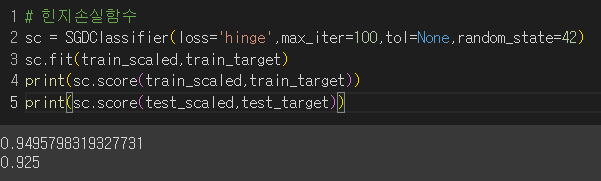
번외) SGDClassifier에서 loss 매개변수 기본값 : hinge (서포트 벡터 머신)