회사에서 인턴으로 근무하며 마지막 페이지 조회 API의 성능을 개선한 경험을 공유합니다.
상황
이미지 출처 : https://canvas.workday.com/components/navigation/pagination/
회사에서 운영하던 서비스에서, 사용자는 맨 마지막 페이지를 조회할 수 있었습니다. 하지만 실제로 맨 마지막 페이지를 요청하면 응답이 매우 느리거나, 504 Gateway Timeout 이 발생했습니다. 이러한 쿼리를 반복적으로 요청했을 때 DB 과부하로 일시적인 서비스 장애가 발생한 경우도 있었습니다. 따라서 쿼리 성능 문제를 해결해보았습니다.
해결 방법 고민
문제를 마주하고, 세 가지 해결 방법을 고민했습니다.
1. Cursor-based Pagination
첫 번째로, Cursor-based Pagination 을 도입하는 것이었습니다. 페이지네이션을 처리하는 방법으로 주로 두 가지 방식이 사용됩니다.
Offset-based Pagination
db.collection.find()
.sort({ created_at: 1 })
.skip(20)
.limit(10)- 특정 페이지의 데이터를 조회하기 위해 해당 페이지 이전의 데이터를 skip(offset) 합니다.
- 페이지가 뒤로 갈수록 skip 해야 하는 데이터가 많아 성능이 저하됩니다.
- 특정 페이지로 바로 이동할 수 있습니다.
Cursor-based Pagination
db.collection.find({
_id: { $gt: ObjectId("lastDocumentId") }
})
.sort({ _id: 1 })
.limit(10)- Primary Key(_id) 를 Cursor 로 사용합니다.
- 성능이 페이지의 수와 무관하고 일정합니다.
- 특정 페이지로 바로 이동할 수 없습니다.
Cursor-based Pagination 을 도입하면, 페이지 수가 뒤로 가더라도 성능 문제를 일으키지 않을 것이라 예상했습니다. 하지만 이전과 달리 특정 페이지를 조회할 수 있다 라는 요구사항을 만족시킬 수 없게 됩니다.
성능 문제가 발생한 API 의 반환 데이터는 Scientific, Academic 한 데이터였습니다. 따라서 서비스 사용자 입장에서 Cursor-based Pagination 으로 동작하는 것이 어색하게 느껴질 수 있고, 특정 페이지를 조회 하는 기능이 필요할 것으로 판단했습니다. 따라서 Cursor-based Pagination 의 도입은 채택되지 않았습니다.
2.양방향 조회
두 번째로, Offset-based Pagination 을 양방향으로 사용하는 것입니다. 사용자 요청 페이지가 전체 페이지의 반을 넘어설 때 역방향으로 조회한다면, 마지막 페이지 조회 요청에 대해 성능을 개선할 수 있습니다.
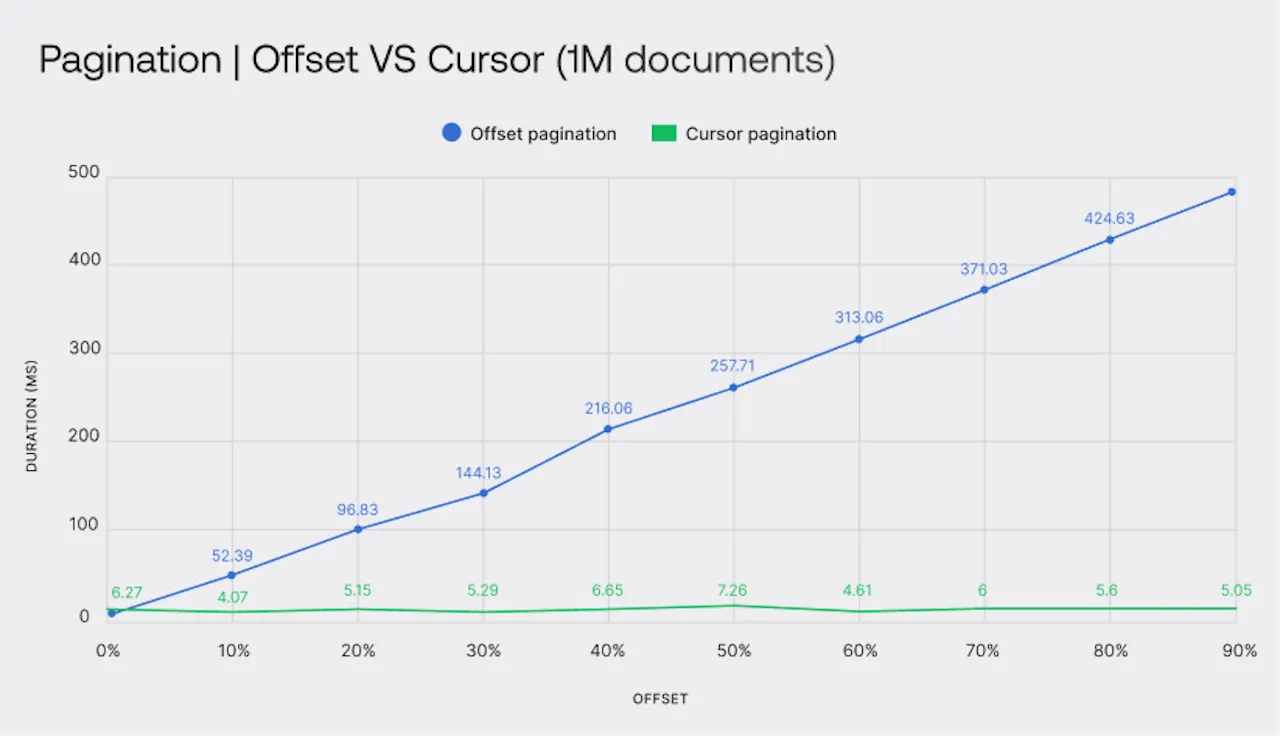
이미지 출처 : https://appwrite.io/blog/post/best-pagination-technique
위 그래프는 Offset-based Pagination 과 Cursor-based Pagination 을 비교하는 글에서 볼 수 있는 자료입니다. 해당 자료를 보며, 요청한 페이지가 중간 이후일 때, 역방향으로 마지막 페이지부터 조회한다면 다음과 같이 성능을 개선할 수 있을 것이라 예상했습니다. 양방향 Offset Pagination 을 통해서, 최악의 경우라도 Offset 50% 정도의 성능이 보장되도록 하는 것입니다.
간단하게 코드로 나타낸다면 다음과 같습니다.
if (page > middlePage) {
const reverseSkip = (totalPages - page) * pageSize;
return db.collection
.find()
.sort({ created_at: -1 }) // 역방향 정렬
.skip(reverseSkip)
.limit(pageSize);
}
return db.collection
.find()
.sort({ created_at: 1 })
.skip((page - 1) * pageSize)
.limit(pageSize);3. MongoDB Query 분석
마지막으로, 현재 사용하는 쿼리를 보다 자세히 살펴보며 병목 지점을 파악하는 것입니다.
DB 로그를 살펴보았을 때 맨 마지막 페이지를 요청하는 전체 쿼리 실행 시간은 10분 이상으로 매우 느렸습니다. 조회 대상이 되는 데이터가 약 700,000 개라는 것을 감안한다면, 10분 이상의 실행 시간은 단순히 skip 하는 데이터의 개수가 많아서 생긴 것이 아니라는 점을 의심할 수 있었습니다.
따라서 두 번째 방법을 사용해보기 전, 쿼리를 자세히 살펴보며 성능이 느린 이유를 찾아보기로 결정했습니다.
결론을 미리 적자면, MongoDB 쿼리 플래너의 index 선택 과정에서 병목이 있었고, 그를 해결하자 쿼리 성능이 매우 개선되었습니다.
MongoDB Query 분석
MongoDB Query 를 분석하기 전에 조회 대상이 되는 데이터를 설명을 드리겠습니다. 아래는 간소하게 나타낸 Document 예시이며, 현업 데이터와 차이가 있음을 알려드립니다.
// MongoDB Document Example
{
"_id": ObjectId("..."),
"conjunction": {
"tca": ISODate("2024-11-20T15:00:00Z"),
"dca": 8500,
},
"type": "MAJOR",
}해당 데이터는 두 우주 물체의 충돌에 관한 내용을 담은 데이터로, Conjunction, TCA, DCA 필드를 갖습니다. 각 필드에 대한 설명은 다음과 같습니다.
- Conjunction(합) : 우주에서 두 물체가 서로 가까이 지나가는 현상
- TCA (Time of Closest Approach) : 두 물체가 가장 가깝게 지나가는 시점
- DCA (Distance of Closest Approach)(Miss distance) : 두 물체가 가장 가깝게 지나가는 시점의 거리
쿼리 성능이 느린 이유 파악
문제가 되는 쿼리는 다음과 같습니다.
db.collection.find({
"CONJUNCTION.TCA": { $gt: ISODate("2024-11-18T02:02:24.195Z") },
"CONJUNCTION.DCA": { $lt: 10000 },
"TYPE": "MAJOR"
}).sort({ "CONJUNCTION.DCA": 1})
.skip(318100)
.limit(5)쿼리 내용을 살펴보면 페이지네이션을 위해 skip과 limit 을 사용하고 있으며 마지막 페이지를 조회하기 위해 skip 하는 데이터 수가 꽤 큰 편입니다.
해당 쿼리를 Mongo Compass 에서 explain() 으로 살펴보았습니다.
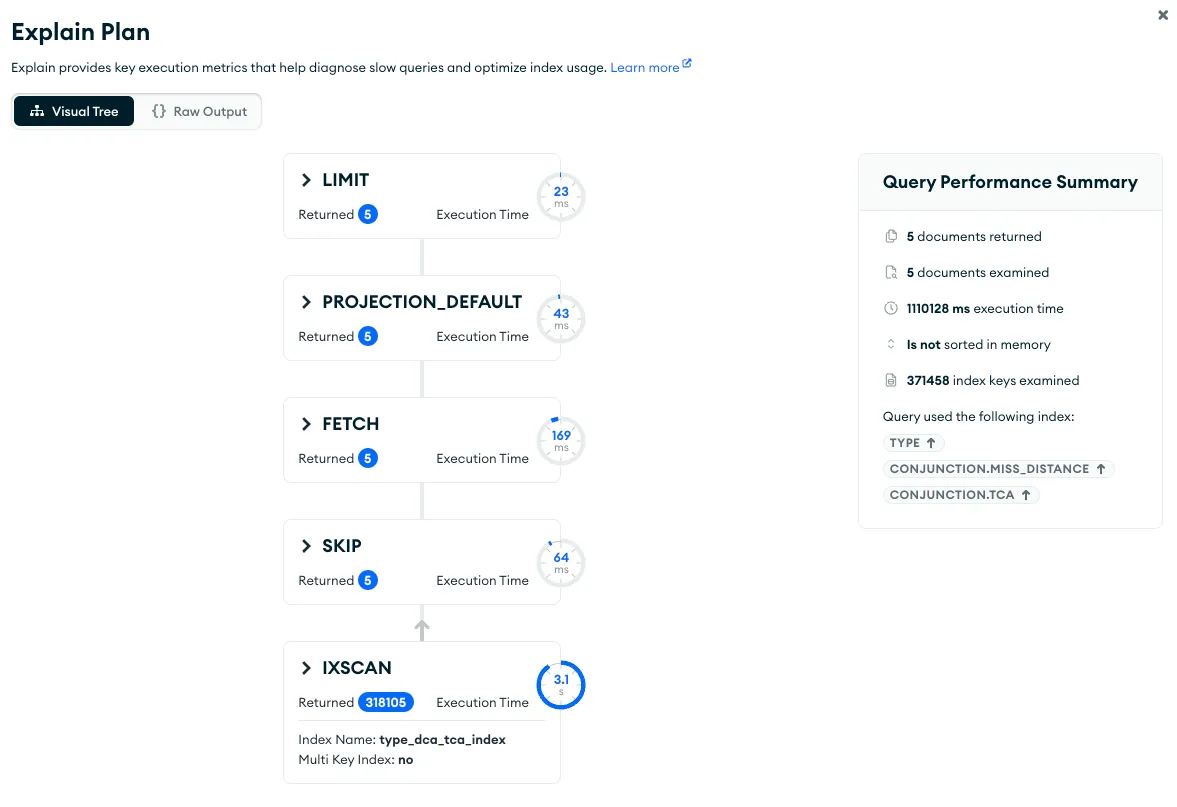
실행 계획에서 다소 이상한 결과를 관찰할 수 있었습니다. 쿼리를 수행하기 위해 총 1,110,238ms (약 18.5분) 을 소요했습니다. 하지만 실제로 데이터를 조회하는 데 걸린 시간은 IXSCAN 단계부터 LIMIT 단계에 이르기까지 3,351ms (약 3.3초)였습니다. 쿼리를 실행하는 데 소요된 총 시간과 실제 수행 시간이 매우 크게 차이가 났습니다.
보다 자세히 쿼리 플랜을 분석해보았습니다. 이중 rejectedPlans 에서 5개의 index로 플랜이 생성되었으며 reject 된 것을 확인할 수 있었습니다.
"rejectedPlans": [
{
// ...
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"TYPE": 1,
"CONJUNCTION.TCA": 1
},
"indexName": "type_tca_index",
// ...
},
{
// ...
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"TYPE": 1,
"CONJUNCTION.COLLISION_PROBABILITY": -1,
"CONJUNCTION.TCA": 1
},
"indexName": "type_prob_tca_index",
// ...
},
{
// ...
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"CONJUNCTION.DCA": 1
},
"indexName": "dca_index",
// ...
},
{
// ...
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"CONJUNCTION.TCA": 1,
"CONJUNCTION.DCA": 1,
"OBJECT1.OBJECT_NAME": 1
},
"indexName": "tca_dca_obj1_name_index",
// ...
},
{
// ...
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"CONJUNCTION.TCA": 1,
"CONJUNCTION.DCA": 1,
"OBJECT1.OBJECT_NAME": 1,
"OBJECT2.OBJECT_NAME": 1
},
"indexName": "tca_dca_obj1_name_obj2_name_index",
// ...
}
]
},쿼리 전체 실행 시간과 실제 실행 시간이 크게 차이나는 것과 rejected plans 이 많은 것이 연관이 있다고 추측했습니다. 따라서 MongoDB 의 Query Planner 가 어떤 방식으로 Plan 을 생성하고 Winning plan 을 결정하는지 내부 동작을 살펴보았습니다.
Query Planner
MongoDB 공식문서에서 Query Planner 의 동작에 관한 다이어그램을 찾을 수 있었습니다.
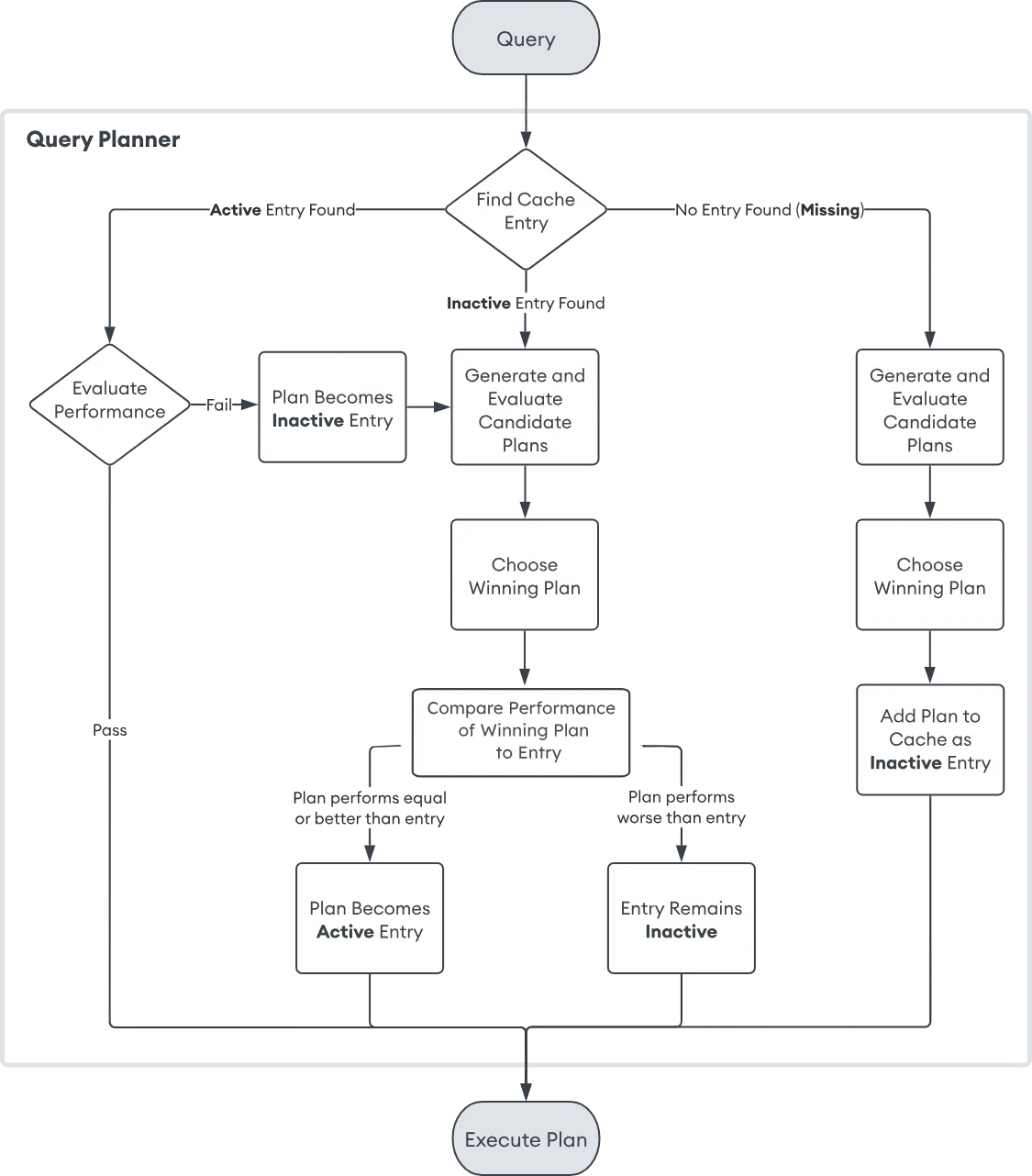
마지막 페이지 조회 쿼리와 Query Planner
위 도식도에 따라 API 에 의해 수행된 쿼리는 다음과 같은 과정을 통해 Plan 을 고를 것으로 예상할 수 있습니다.
- Cache 된 Plan 찾기
맨 마지막 페이지를 조회하는 쿼리는 첫 페이지를 조회하는 쿼리와 패턴이 유사합니다. 따라서 맨 마지막 페이지 조회 시 캐싱되어 있던 Plan 을 찾아 사용할 수 있을 것입니다.
- Cache 에서 찾은 Plan 의 퍼포먼스 측정
캐싱해둔 Plan 이 있다고 하더라도 Query Planner 는 해당 Plan 을 바로 실행하지 않습니다. 새로운 쿼리 조건을 대입해 Plan 의 성능을 측정합니다. 이때 충분한 성능이 나온다면 해당 플랜으로 쿼리를 실행합니다. 반대의 경우 새롭게 플랜을 생성하는 작업을 거칩니다.
앞서 문제가 된 쿼리의 실행 계획을 보았을 때 rejected plan 이 다수 존재했습니다. 이는 기존에 캐싱해둔 플랜을 사용하지 않고, 새롭게 플랜을 생성한 증거입니다. 따라서 Cache 에서 찾은 Plan 의 퍼포먼스가 충분하지 않았다고 판단한 것을 알 수 있습니다.
- 새로운 플랜 생성 및 Winning Plan 사용
입력된 쿼리 조건에 따라 새로운 플랜들을 만들고 각 플랜의 성능을 측정해 Winning Plan 을 고릅니다. 이후 해당 Plan 을 Cache Entry 에 넣을지 결정하는 과정을 거쳐 Winning Plan 대로 쿼리를 수행합니다.
결국 해당 쿼리의 성능이 낮았던 이유는, 쿼리에서 사용할 Plan 을 고르는 과정이 긴 시간을 필요로 했기 때문이라 추측할 수 있습니다. 그렇다면 어째서 캐싱해둔 Plan을 사용하지 않았고, 이후 Winning Plane 을 고르는 과정이 오래 걸렸을까요? MongoDB 의 내부 코드를 직접 살펴보며 Query Planner 의 동작을 조사해보았습니다.
Query Planner 의 내부 동작
1. Cache 된 Plan 의 성능 측정
다음은 캐시된 Plan 의 성능을 측정해보고 성능이 좋다면 Status::OK() 을 응답하고, 아니라면 replan 메서드를 호출하는 과정을 담은 코드입니다.
// 코드 다수 생략
Status CachedPlanStage::pickBestPlan(const QueryPlannerParams& plannerParams,
PlanYieldPolicy* yieldPolicy) {
// 최대 작업량을 초과하면 replan을 트리거하는 임계값 설정
size_t maxWorksBeforeReplan =
static_cast<size_t>(internalQueryCacheEvictionRatio * _decisionWorks);
// trial period 동안 필요한 결과 수
size_t numResults = trial_period::getTrialPeriodNumToReturn(*_canonicalQuery);
for (size_t i = 0; i < maxWorksBeforeReplan; ++i) {
// 계획 실행 중 결과가 충분하면 현재 계획 유지
if (_results.size() >= numResults) {
_bestPlanChosen = true;
return Status::OK();
}
else if (PlanStage::IS_EOF == state) {
// EOF에 빠르게 도달해도 현재 계획 유지
_bestPlanChosen = true;
return Status::OK();
}
// ...
}
// maxWorksBeforeReplan 횟수를 초과하면 replan 수행
return replan(
plannerParams,
yieldPolicy,
shouldCache,
str::stream()
<< "cached plan was less efficient than expected: expected trial execution to take "
<< _decisionWorks << " works but it took at least " << maxWorksBeforeReplan
<< " works");
}MongoDB 는 Plan 의 성능을 측정할 때 직접 해당 Plan으로 쿼리를 일부 실행해보고, 그 결과를 바탕으로 결정하는 방식으로 동작합니다. 코드를 살펴보면 maxWorksBeforeReplan 최대 Work 임계값을 미리 지정해두고, 반복문을 통해 쿼리를 실행해보며, numResults 보다 많은 데이터를 가져왔거나, EOF 에 도달했다면 해당 쿼리를 해당 쿼리를 효율적이라 판단하고 OK를 응답하는 것을 볼 수 있습니다.
여기서 맨 마지막 페이지를 조회하는 쿼리가 캐싱된 플랜을 사용하지 못하고 replan 작업을 하게 된 이유를 추측할 수 있습니다.
db.collection.find({
"CONJUNCTION.TCA": { $gt: ISODate("2024-11-18T02:02:24.195Z") },
"CONJUNCTION.DCA": { $lt: 10000 },
"TYPE": "MAJOR"
}).sort({ "CONJUNCTION.DCA": 1})
.skip(318100)
.limit(5)앞서 살펴본 쿼리의 형태를 다시 보면 skip 하는 데이터 수가 상당합니다. 이로 인해 maxWorksBeforeReplan 번 반복해서 일부 쿼리를 실행하는 동안 numResults 보다 많은 데이터를 가져오지 못했고, EOF 에 도달하지 못했을 것입니다. 따라서 replane 작업에 들어가게 된 것입니다.
2. Replan
다음은 Replan 과정에서 Plan 을 생성하는 코드의 일부입니다.
Plan 생성 시 간략하게 다음의 과정을 거칩니다.
-
인덱스를 선택
hint 가 입력 되었다면 해당 인덱스만 사용합니다. 반대의 경우 모든 인덱스를 선택합니다.
-
관련 인덱스 필터링
입력된 쿼리와 관련된 인덱스를 필터링합니다.
-
인덱스 기반 플랜 생성
인덱스 기반의 플랜을 생성합니다. 이때 컬렉션 스캔 등도 고려합니다. 이후 최종 플랜을 반환합니다.
StatusWith<std::vector<std::unique_ptr<QuerySolution>>> QueryPlanner::plan(
const CanonicalQuery& query, const QueryPlannerParams& params) {
//... 초기 로깅
//... tailable 커서 체크 및 처리
// hint 체크 및 처리
boost::optional<BSONObj> hintedIndexBson = boost::none;
if (!params.indexFiltersApplied && !params.querySettingsApplied) {
if (auto hintObj = query.getFindCommandRequest().getHint(); !hintObj.isEmpty()) {
hintedIndexBson = hintObj;
}
}
//... GEO_NEAR, TEXT 쿼리 필터링
//... hint 관련 특수 케이스 처리
// 1. 초기 인덱스 리스트 설정
std::vector<IndexEntry> fullIndexList;
if (!hintedIndexBson) {
fullIndexList = params.mainCollectionInfo.indexes; // 모든 인덱스 사용
} else {
fullIndexList = QueryPlannerIXSelect::findIndexesByHint(...); // hint된 인덱스만 사용
}
// 2. 쿼리와 관련된 필드 파악
RelevantFieldIndexMap fields;
QueryPlannerIXSelect::getFields(query.getPrimaryMatchExpression(), &fields);
// 2. 관련 있는 인덱스만 필터링
std::vector<IndexEntry> relevantIndices;
if (!hintedIndexEntry) {
relevantIndices = QueryPlannerIXSelect::findRelevantIndices(fields, fullIndexList);
} else {
relevantIndices = fullIndexList;
}
//... min/max 쿼리 옵션 처리
// 각 인덱스의 유용성 평가
QueryPlannerIXSelect::rateIndices(
query.getPrimaryMatchExpression(), "", relevantIndices, queryContext);
//... 불필요한 인덱스 할당 제거
std::vector<std::unique_ptr<QuerySolution>> out;
// 3. 인덱스 기반 플랜 생성
if (!relevantIndices.empty()) {
plan_enumerator::PlanEnumerator planEnumerator(enumParams);
unique_ptr<MatchExpression> nextTaggedTree;
while ((nextTaggedTree = planEnumerator.getNext()) &&
(out.size() < params.maxIndexedSolutions)) {
//... 플랜 캐시 관련 처리
// 인덱스 접근 플랜 생성
std::unique_ptr<QuerySolutionNode> solnRoot(
QueryPlannerAccess::buildIndexedDataAccess(query, std::move(nextTaggedTree),
relevantIndices, params));
if (!solnRoot) {
continue;
}
// 생성된 플랜 분석 및 추가
auto soln = QueryPlannerAnalysis::analyzeDataAccess(query, params, std::move(solnRoot));
if (soln) {
out.push_back(std::move(soln));
}
}
}
//... 정렬, 프로젝션 관련 추가 플랜 생성
//... 컬렉션 스캔 고려
//... 최종 플랜 반환
return {std::move(out)};
}다음은 생성한 다수의 Plan 에서 Winning Plan 을 고르는 과정입니다.
Winning Plan 선택 시 간략하게 다음의 과정을 거칩니다.
-
각 플랜 실행을 위한 제한값 설정
numWorks : 최대 작업량
numResults : 필요 결과 수
-
모든 플랜 실행 및 결과 통계 수집
-
수집된 통계를 바탕으로 최적의 플랜 선택
Status MultiPlanStage::pickBestPlan(PlanYieldPolicy* yieldPolicy) {
//... 이미 best plan이 선택되었는지 체크
//... 디버깅을 위한 sleep 로직
//... 타이머 및 메트릭 초기화
// 1. 각 플랜 실행을 위한 제한값 설정
const size_t numWorks = trial_period::getTrialPeriodMaxWorks(...); // 최대 작업량
size_t numResults = trial_period::getTrialPeriodNumToReturn(*_query); // 필요 결과 수
// 2. 모든 플랜 실행 및 통계 수집
try {
size_t ix = 0;
for (; ix < numWorks; ++ix) {
bool moreToDo = workAllPlans(numResults, yieldPolicy);
if (!moreToDo) {
break;
}
}
auto totalWorks = ix * _candidates.size();
//... 통계 업데이트
} catch (DBException& e) {
//... 에러 처리
}
//... 실행 시간 측정 및 통계 업데이트
// 3. 수집된 통계를 바탕으로 최적의 플랜 선택
auto statusWithRanking = plan_ranker::pickBestPlan(_candidates);
if (!statusWithRanking.isOK()) {
return statusWithRanking.getStatus();
}
auto ranking = std::move(statusWithRanking.getValue());
_bestPlanIdx = ranking->candidateOrder[0];
//... 선택된 최적 플랜 정보 로깅
//... 디버그 로깅
//... 백업 플랜 선택 (필요한 경우)
//... 콜백 호출 및 rejected 플랜 제거
return Status::OK();
}앞서 MongoDB 가 Plan 의 성능을 측정할 때 직접 해당 Plan으로 쿼리를 일부 실행해보고, 그 결과를 바탕으로 결정하는 방식으로 동작한다고 했습니다. 이는 Winning Plan 을 선택하는 과정에서도 비슷합니다. 모든 Plan 에 대해 쿼리를 일부 데이터에 대해 실행하며 numResults 보다 많은 데이터를 가져오거나, EOF 에 도달했는지 여부를 체크합니다.
이때 쿼리의 skip이 318,100 이라는 점을 생각한다면 어느 하나의 Plan 이라도 numResults 보다 데이터를 더 가져오거나, EOF에 도달하는 데 매우 많은 시간이 걸릴 것으로 예상할 수 있습니다. 심지어 Winning Plan 을 결정하기 위해 이러한 작업을 모든 Plan 에 순차적으로 진행하게 되는데요. 이 과정에서 시간과 시스템 리소스 모두 비효율적으로 많이 소모될 것입니다.
문제 해결
Query Planner 의 동작을 살펴보며, skip 키워드로 인해 Winning Plan 을 선택해 쿼리를 실행하기까지 시간과 리소스가 낭비되는 것을 확인할 수 있었습니다. 그렇다면 문제를 어떻게 해결할 수 있을까요?
해결은 매우 간단합니다. Plan의 선택 과정을 없애는 것입니다. 그것은 hint() 메서드를 통해 가능합니다.
db.collection.find({
"CONJUNCTION.TCA": { $gt: ISODate("2024-11-18T02:02:24.195Z") },
"CONJUNCTION.DCA": { $lt: 10000 },
"TYPE": "MAJOR"
}).sort({ "CONJUNCTION.DCA": 1})
.hint({
"TYPE": 1,
"CONJUNCTION.DCA": 1,
"CONJUNCTION.TCA": 1
})
.skip(318100)
.limit(5)앞서 Plan 을 생성하는 과정에서 hint 가 있는 경우, hint 를 통해 선택된 Plan 만 고려하는 코드가 있었습니다. 따라서 hint 를 전달함으로써 Plan 성능을 바탕으로 Winning Plan 을 선택하는 과정을 생략하게 만들 수 있습니다.
실제로 hint 를 입력한 쿼리에 대한 실행 계획을 보면 더 이상 전체 실행 시간과 쿼리 수행 시간이 큰 차이를 보이지 않는 것을 볼 수 있습니다. 또한 IXSCAN 과정도 보다 빨라져, 전체 쿼리 실행 시간이 많이 단축된 것을 확인할 수 있습니다.
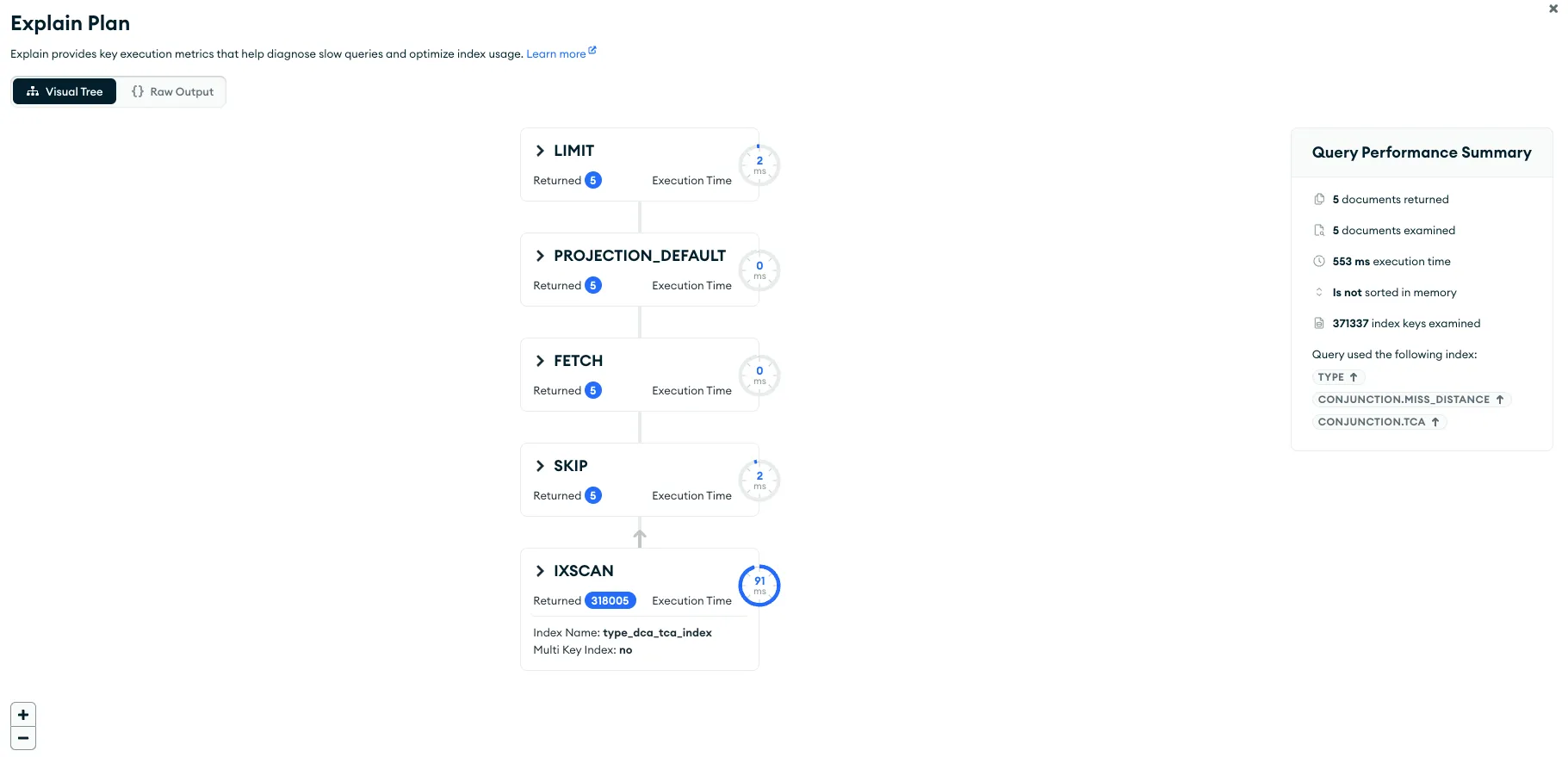
참고
https://studying-penguin.tistory.com/9
https://www.mongodb.com/docs/manual/core/query-plans/
소스코드
https://github.com/mongodb/mongo/blob/master/src/mongo/db/exec/cached_plan.cpp
https://github.com/mongodb/mongo/blob/master/src/mongo/db/exec/multi_plan.cpp
https://github.com/mongodb/mongo/blob/master/src/mongo/db/query/query_planner.cpp
