
들어가기
트립드로우 팀 프로젝트를 진행하고 있습니다.
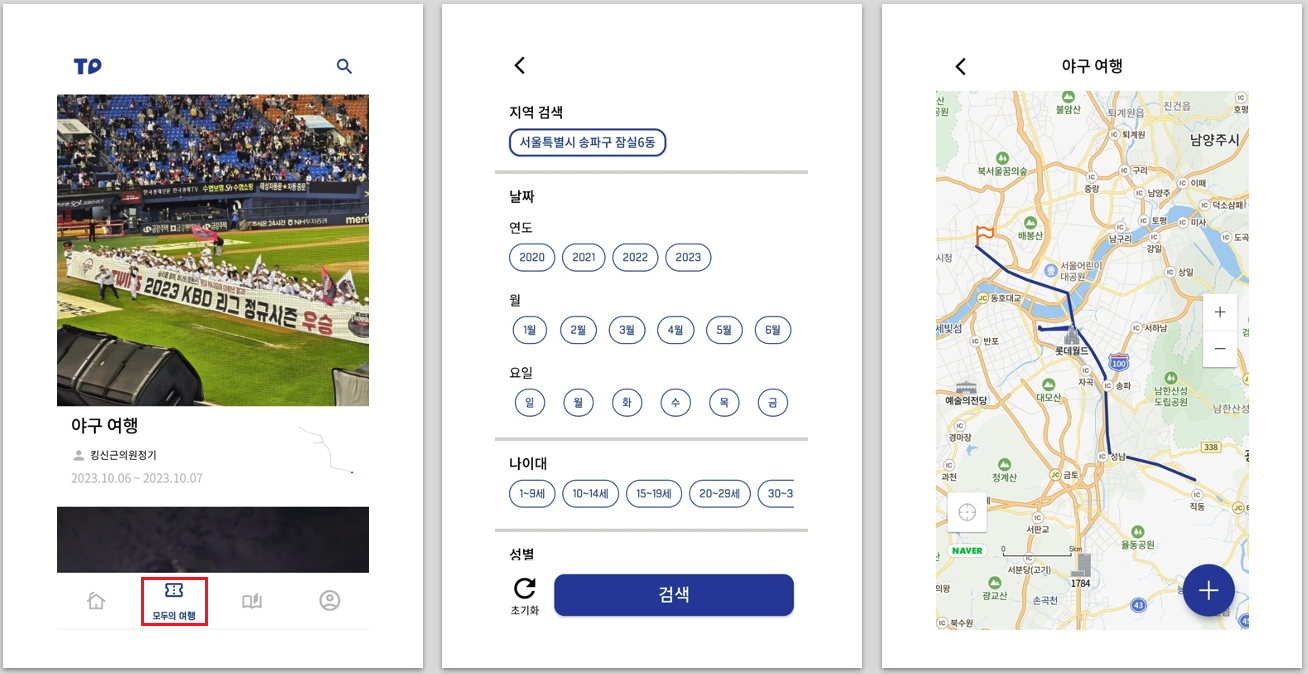
트립드로우 애플리케이션에는 다른 사용자들의 여행을 볼 수 있는 모두의 여행 탭이 있습니다.
모두의 여행 탭에서 스크롤을 내리며 다른 사람이 어떤 경로로 여행을 다녔는지, 어떤 감상을 남겼는지 볼 수 있습니다.
주소(지역), 시간(날짜) 등에 따라 조건을 걸어 검색을 할 수도 있습니다.
이 기능을 통해 사용자가 여행 경로, 음식 맛집, 풍경이 예쁜 장소 등의 여행 정보를 얻어가기를 기대하고 있습니다.
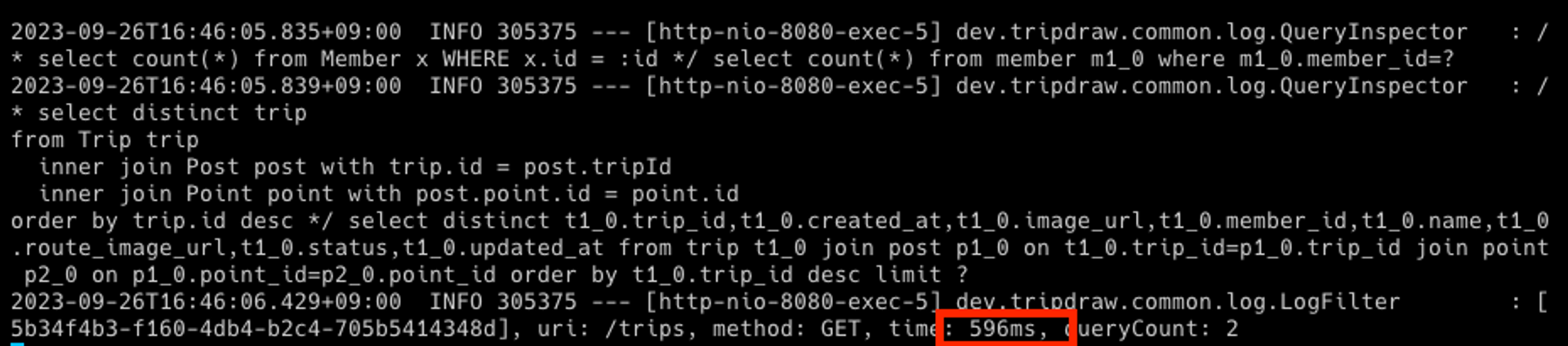
하지만 모든 여행 조회 API의 요청 처리 시간이 예상보다 매우 느렸습니다.
DB에는 여행, 위치정보, 감상 등의 데이터를 합해 약 200,000개의 데이터가 존재했습니다.
아무런 검색 조건 없이 조회할 경우 평균적으로 약 600ms 를 기록했습니다.
검색 조건이 있을 때는 시간이 덜 걸렸습니다만 만족스러운 수준이 아니었습니다.
모든 여행 조회 API 는 애플리케이션에서 사용자가 가장 자주 요청할 API였습니다.
따라서 요청 처리 시간을 단축시키기 위해 조회 쿼리를 살펴보고 수정했습니다.
수정 결과 600ms 의 요청 시간은 13ms 까지 단축 되었습니다. 그 과정을 공유합니다.
조회 쿼리 개선하기
기존 쿼리
DB Schema
DB Schema 는 다음과 같습니다.
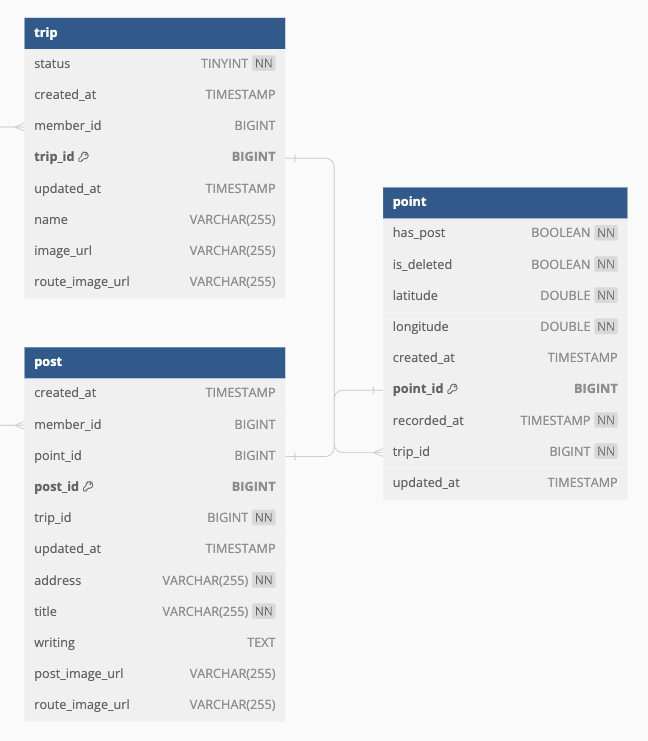
Trip과 Point는 1:N 관계, Trip과 Post는 1:N 관계입니다. Point와 Post는 1:1 관계입니다.
Point 는 trip_id를 외래키로 갖습니다. 또한 Post 를 갖는지 여부를 has_post로 갖습니다.
Post 는 trip_id, point_id 를 외래키로 갖습니다.
이제 쿼리를 살펴보겠습니다.
검색 조건이 없는 경우
모든 여행 조회 API 를 요청하면 DB에 실행되는 쿼리는 아래와 같습니다.
SELECT DISTINCT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
JOIN post ps ON t.trip_id = ps.trip_id
JOIN point poi ON ps.point_id = poi.point_id
ORDER BY t.trip_id DESC
LIMIT 20;trip_id를 내림차순으로 정렬해서 20개의 Trip 데이터를 조회했습니다.
Trip, Post, Point 세 개의 테이블을 JOIN 했고, 중복을 제거하기 위해 DISTINCT 키워드를 사용했습니다.
Pagination 을 위해 ORDER BY 와 LIMIT 을 사용했습니다.
검색 조건이 있는 경우
검색 조건이 있는 경우에는 쿼리가 다릅니다.
주소 조건으로 "서울특별시", 시간 조건으로 "2023년", "5월"을 포함하는 모든 여행을 조회하면 DB에 실행되는 쿼리는 아래와 같습니다.
SELECT DISTINCT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
JOIN post ps ON t.trip_id = ps.trip_id
JOIN point poi ON ps.point_id = poi.point_id
WHERE
YEAR (poi.recorded_at) = 2023 AND
MONTH (poi.recorded_at) = 5 AND
ps.address LIKE '서울특별시%' ESCAPE '!'
ORDER BY t.trip_id DESC
LIMIT 10;WHERE 절에서 Point 의 recorded_at 이 시간 조건에 맞는지 확인합니다.
또한 WHERE 절에서 LIKE 키워드를 활용해 주소 조건에 맞는 데이터를 조회합니다.
문제 인식
DB Schema 를 기반으로 쿼리를 여러모로 바꿔보면서 문제점을 인식했습니다.
크게 두 가지 문제가 있었습니다.
1. 불필요한 Join
첫 번째로 불필요한 테이블 Join 을 발견했습니다.
검색 조건이 없는 경우에 모든 여행 조회 쿼리는 아래와 같았습니다.
SELECT DISTINCT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
JOIN post ps ON t.trip_id = ps.trip_id
JOIN point poi ON ps.point_id = poi.point_id
ORDER BY t.trip_id DESC
LIMIT 20;검색 조건이 있는 경우에는 Point의 recorded_at 혹은 Post의 address 컬럼을 사용합니다. 따라서 Post, Point 테이블을 Join 하는 것이 적절합니다.
하지만 검색 조건이 없는 경우에는 이러한 데이터가 필요하지 않습니다.
동일한 Trip 데이터를 반환하면서 불필요한 Join을 없앤다면 쿼리를 다음과 같이 변경할 수 있습니다.
SELECT DISTINCT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
JOIN point poi ON t.trip_id = poi.trip_id
WHERE poi.has_post = TRUE
ORDER BY t.trip_id DESC LIMIT 20;Trip와 Point만 trip_id를 기준으로 Join 했습니다.
이후 WHERE 절로 Post가 존재하는 Trip 데이터를 조회했습니다.
반환 데이터는 동일하지만 Post 테이블에 대한 Join 을 수행하지 않으므로 성능이 개선될 것을 기대할 수 있습니다.
이처럼 검색 조건에 따라 쿼리 내용을 달리 할 필요성을 느꼈습니다.
2. 불필요한 중복 데이터 생성
두 번째로 불필요하게 중복 데이터를 생성하는 과정을 발견했습니다.
SELECT DISTINCT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
JOIN point p ON t.trip_id = p.trip_id
WHERE p.has_post = TRUE
ORDER BY t.trip_id DESC LIMIT 20;DISTINCT 키워드는 조회 데이터의 중복을 제거합니다.
하지만 Trip 테이블은 본래 중복된 데이터를 갖고 있지 않습니다.
그렇다면, 언제 Trip의 중복이 생기고 있을까요?
그것은 Trip과 Point(혹은 Post)를 Join 할 때 입니다.
앞서 보았듯 Trip 과 Point(혹은 Post) 는 1:N 관계입니다.
따라서 Trip 과 Point 를 trip_id 를 기준으로 Join 하면 필연적으로 Trip 데이터가 중복되게 됩니다.
| trip_id | name | member_id | (...) |
|---|---|---|---|
| 1 | query 여행 | 1 | (...) |
다음과 같은 Trip 데이터가 1개 있다고 가정해봅시다.
| point_id | has_post | trip_id | latitude | longitude |
|---|---|---|---|---|
| 1 | 1 | 1 | (...) | (...) |
| 2 | 0 | 1 | (...) | (...) |
| 3 | 0 | 1 | (...) | (...) |
| 4 | 1 | 1 | (...) | (...) |
| 5 | 1 | 1 | (...) | (...) |
만약 이 Trip 이 5개의 Point 를 갖고 두 테이블을 trip_id 를 기준으로 Join 한다면 그 결과는 아래와 같습니다.
| trip_id | name | member_id | (...) | point_id | has_post | trip_id | latitude | longitude |
|---|---|---|---|---|---|---|---|---|
| 1 | query 여행 | 1 | (...) | 1 | 1 | 1 | (...) | (...) |
| 1 | query 여행 | 1 | (...) | 2 | 0 | 1 | (...) | (...) |
| 1 | query 여행 | 1 | (...) | 3 | 0 | 1 | (...) | (...) |
| 1 | query 여행 | 1 | (...) | 4 | 1 | 1 | (...) | (...) |
| 1 | query 여행 | 1 | (...) | 5 | 1 | 1 | (...) | (...) |
trip_id 가 1인 Trip 이 5개까지 늘어난 것을 볼 수 있습니다.
Trip 을 조회하기 위해 굳이 Trip 데이터를 중복 생성하는 과정을 겪을 필요는 없다고 생각했습니다.
따라서 Trip 과 Point 를 Join 하기 전에 Point 테이블에서 trip_id 의 중복을 제거하는 방법을 떠올렸습니다.
1:N 관계의 두 테이블에서 N 테이블에 DISTINCT 키워드를 적용하는 것이었습니다.
쿼리 변경
쿼리를 살펴보며 깨달은 두 가지를 정리하면 다음과 같습니다.
- 검색 조건에 따라 쿼리 내용을 다르게 한다.
- Trip의 중복을 막기 위해 Point 데이터에 미리 DISTINCT 키워드를 적용한다.
Subquery
"Trip의 중복을 막기 위해 Point 데이터에 미리 DISTINCT 키워드를 적용한다." 를 위해 Subquery 를 도입하고자 했습니다.
SELECT DISTINCT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
WHERE t.trip_id IN (
SELECT DISTINCT p.trip_id
FROM point p
WHERE p.has_post = TRUE
)
ORDER BY t.trip_id DESC
LIMIT 20;Subquery 에서 Point의 trip_id를 조회합니다. 이때 DISTINCT 로 중복을 미리 제거합니다.
단순히 중복을 미리 제거하는 것만으로도 쿼리 시간이 약 600ms에서 60ms 로 단축되었습니다.
그러나 쿼리에서 개선할 수 있는 점이 한 가지 더 보였습니다.
바로 LIMIT 입니다.
IN 절에서 비교할 trip_id의 개수를 미리 줄인다면 성능을 더욱 높일 수 있을 것이라 예상했습니다.
SELECT DISTINCT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
WHERE t.trip_id IN (
SELECT DISTINCT poi.trip_id
FROM point poi
WHERE poi.has_post = TRUE
ORDER BY poi.trip_id DESC
LIMIT 20
)
ORDER BY t.trip_id DESC;따라서 위와 같은 쿼리를 실행하고 싶었습니다.
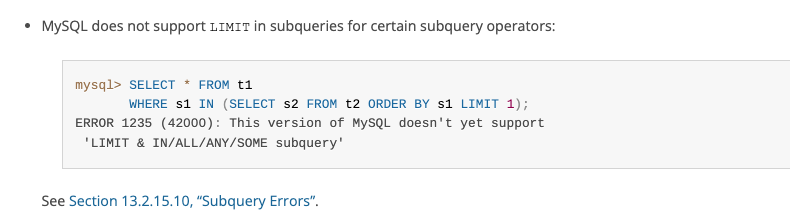
하지만 MySql 공식문서에 따르면 subquery 내에서 LIMIT을 지원하지 않습니다.
쿼리 나누기
따라서 Subquery를 사용하기보다 쿼리를 두 개로 나눠보기로 했습니다.
이것이 첫 번째 쿼리입니다.
SELECT DISTINCT p.trip_id
FROM point p
WHERE p.has_post = TRUE
ORDER BY p.trip_id DESC
LIMIT 20;그리고 두 번째 쿼리입니다.
SELECT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
WHERE t.trip_id IN (?)
ORDER BY t.trip_id DESC;IN() 안에 첫 번째 쿼리로 반환된 trip_id가 입력됩니다.
쿼리를 두 번 나누었을 때 시간은 평균 13ms까지 단축되었습니다.
조건에 따라 Query 나누기
이후 검색 조건에 따라 쿼리를 나누었습니다.
검색 조건에 따라 다루어야 할 테이블 혹은 데이터의 내용이 다릅니다.
조건별로 필요한 데이터는 다음과 같습니다.
- 검색 조건이 없는 경우 : point.has_post
- 시간 조건만 있는 경우 : point.recorded_at, point.has_post
- 주소 조건만 있는 경우 : post.address
- 모든 조건이 있는 경우 : point.recorded_at, post.address
검색 조건이 없는 경우
조건이 없는 경우, 여행 전체를 조회하기 위해 필요한 데이터는 Point 테이블의 has_post 컬럼입니다.
따라서 Trip과 Point 테이블만 다루도록 합니다.
SELECT DISTINCT p.trip_id
FROM point p
WHERE p.has_post = TRUE
ORDER BY p.trip_id DESC
LIMIT 20;SELECT t.trip_id,
t.created_at,
t.image_url,
t.member_id,
t.name,
t.route_image_url,
t.status,
t.updated_at
FROM trip t
WHERE t.trip_id IN (?)
ORDER BY t.trip_id DESC;앞서 설명했듯 첫 번째 쿼리의 결과가 두 번째 쿼리의 IN () 안에 인자로 들어갑니다.
앞으로 모든 조건에서 첫 번째 쿼리는 달라지지만, 두 번째 쿼리는 달라지지 않습니다.
따라서 첫 번째 쿼리만 예시로 들겠습니다.
시간 조건만 있는 경우
시간 조건만 있는 경우 여행 전체를 조회하기 위해 필요한 데이터는 Point 테이블의 recorded_at, has_post 컬럼입니다.
따라서 Trip과 Point 테이블만 다루도록 합니다.
요일 조건이 포함된 첫 번째 쿼리 예시입니다.
SELECT DISTINCT p.trip_id
FROM point p
WHERE dayofweek(p.recorded_at) = 1 AND p.has_post = TRUE
ORDER BY p.trip_id DESC
LIMIT 20;두 번째 쿼리는 검색 조건이 없는 경우와 동일합니다.
주소 조건만 있는 경우
주소 조건만 있는 경우 여행 전체를 조회하기 위해 필요한 데이터는 Post 테이블의 address 컬럼입니다.
따라서 Trip과 Post 테이블만 작업합니다.
주소 조건이 포함된 첫 번째 쿼리 예시입니다.
SELECT DISTINCT p.trip_id
FROM post p
WHERE p.address LIKE '서울특별시%' ESCAPE '!'
ORDER BY p.trip_id DESC
LIMIT 20;두 번째 쿼리는 검색 조건이 없는 경우와 동일합니다.
시간 조건, 주소 조건이 모두 있는 경우
시간 조건, 주소 조건이 모두 있는 경우 Post.address, Point.recorded_at 컬럼이 필요합니다.
따라서 Trip과 Post, Point 테이블을 작업합니다.
시간 조건과 주소 조건이 포함된 첫 번째 쿼리 예시입니다.
SELECT DISTINCT poi.trip_id
FROM point poi
JOIN post ps on poi.point_id = ps.point_id
WHERE (dayofweek(poi.recorded_at) = 1 AND ps.address LIKE '서울특별시%' ESCAPE '!')
ORDER BY poi.trip_id DESC LIMIT 20;두 번째 쿼리는 검색 조건이 없는 경우와 동일합니다.
QueryDsl 코드
기존에 하나였던 쿼리를 두 개로 나누고, 검색 조건에 따라 쿼리를 달리한 것은 모두 QueryDsl과 Java 코드로 구현했습니다.
이전에 비해 코드가 복잡해질 것을 염려했습니다.
따라서 메서드의 이름을 통해 의도가 잘 드러나도록 노력했습니다.
그 결과물은 다음과 같습니다.
@RequiredArgsConstructor
@Repository
public class TripDynamicQueryRepository {
private final JPAQueryFactory jpaQueryFactory;
public List<Trip> findAllByConditions(TripSearchConditions tripSearchConditions, TripPaging paging) {
if (tripSearchConditions.hasNoCondition()) {
List<Long> tripIds = getTripIdsWithoutCondition(paging);
return getTripsIn(tripIds);
}
if (tripSearchConditions.hasOnlyAddressCondition()) {
List<Long> tripIds = getTripIdsWithAddressCondition(tripSearchConditions, paging);
return getTripsIn(tripIds);
}
if (tripSearchConditions.hasOnlyTimeConditions()) {
List<Long> tripIds = getTripIdsWithTimeConditions(tripSearchConditions, paging);
return getTripsIn(tripIds);
}
List<Long> tripIds = getTripIdsWithAllConditions(tripSearchConditions, paging);
return getTripsIn(tripIds);
}
private List<Long> getTripIdsWithoutCondition(TripPaging paging) {
return jpaQueryFactory.selectDistinct(point.trip.id).from(point)
.where(
point.hasPost.isTrue(),
pointTripIdLt(paging.lastViewedId())
)
.orderBy(point.trip.id.desc())
.limit(paging.limit().longValue())
.fetch();
}
private List<Trip> getTripsIn(List<Long> tripIds) {
return jpaQueryFactory.selectFrom(trip)
.where(trip.id.in(tripIds))
.orderBy(trip.id.desc())
.fetch();
}
private List<Long> getTripIdsWithAddressCondition(TripSearchConditions tripSearchConditions, TripPaging paging) {
return jpaQueryFactory.selectDistinct(post.tripId).from(post)
.where(
addressLike(tripSearchConditions.address()),
postTripIdLt(paging.lastViewedId())
)
.orderBy(post.tripId.desc())
.limit(paging.limit().longValue())
.fetch();
}
private List<Long> getTripIdsWithTimeConditions(TripSearchConditions tripSearchConditions, TripPaging paging) {
return jpaQueryFactory.selectDistinct(point.trip.id).from(point)
.where(
yearIn(tripSearchConditions.years()),
monthIn(tripSearchConditions.months()),
dayOfWeekIn(tripSearchConditions.daysOfWeek()),
point.hasPost.isTrue(),
pointTripIdLt(paging.lastViewedId())
)
.orderBy(point.trip.id.desc())
.limit(paging.limit().longValue())
.fetch();
}
private List<Long> getTripIdsWithAllConditions(TripSearchConditions tripSearchConditions, TripPaging paging) {
return jpaQueryFactory.selectDistinct(point.trip.id).from(point)
.innerJoin(post).on(post.point.id.eq(point.id))
.where(
yearIn(tripSearchConditions.years()),
monthIn(tripSearchConditions.months()),
dayOfWeekIn(tripSearchConditions.daysOfWeek()),
addressLike(tripSearchConditions.address()),
pointTripIdLt(paging.lastViewedId())
)
.orderBy(point.trip.id.desc())
.limit(paging.limit().longValue())
.fetch();
}
}
결과

모든 여행 조회 API의 요청 처리 시간은 검색 조건이 없는 경우 약 13ms를 기록하며 매우 빨라졌습니다.
검색 조건이 있는 경우에도 월등히 빨라졌습니다. 가령, "1월" 을 시간 조건으로 포함했을 때 약 100ms -> 12ms 로 단축 됐습니다.
사용자 혹은 DB에 데이터가 많아진다면 또 새롭게 조회 성능을 높일 방법을 강구해볼 수도 있겠습니다!

13ms로 개선 달달하네요