프로그램의 실행 속도는 프로그램이 동작하는 하드웨어나 컴파일러 등의 조건에 따라 달라진다. 알고리즘의 성능을 객관적으로 평가하는 기준은 복잡도(complexity)라고 한다.
복잡도는 다음의 두 가지 요소를 가지고 있다.
시간 복잡도(time complexity): 실행에 필요한 시간을 평가한 것
공간 복잡도(space complexity): 기억 영역과 파일 공간이 얼마나 필요한가를 평가한 것
시간 복잡도
위에 정의한 대로 시간 복잡도는 실행에 필요한 시간을 평가한 것이다.
아래와 같은 메서드가 있다고 보자.
static boolean nInArray(int[] a, int e) {
for(int i : a) {
if(i == e)
return true;
}
return false;
}배열a의 크기를n이라고 하자.
배열a에 정수e가 있으면 true를 아니면 false를 반환하는 간단한 메서드이다.
메서드 전체에 대한 시간 복잡도
하한선 Ω
해당 메서드에서 최고로 빨리 끝나는 경우의 수는 무엇인가? 최고로 빨리 끝나는 경우를 하한선(lower bound)라고 하고 하한선 표기는 Ω()로 한다.
위 배열의 a[0]이 내가찾는 e인 경우가 최선의 경우의 수로, Ω(1)이 되는것이다.
Ω(n)은 빅-오메가라 읽는다.
상한선 O
해당 메서드에서 최대한 늦게 끝나는 경우의 수는 무엇인가? 최대한 늦게 끝나는 경우를 상한선(upper bound)라고 하고 상한선 표기는 O()로 한다.
위 배열의 마지막에 내가찾는 e이 있거나, 아예 없는 경우가 이에 해당한다.
따라서 O(n)이 된다.
O(n)은 빅-오라고 읽는다.
하나의 경우에 대한 시간 복잡도
시간 복잡도에 대해 검색하다보면 세타기호(θ)를 볼 수 있다. 세타는 영어로 tight bound라고 하며, 세타의 경우는 내가 계산하고자 하는 시간 복잡도의 하한선과 상한선이 둘 다 비슷한 수준에 있을때 세타로 표기할 수 있다. 위 메서드에서 가장 빨리 끝나는 경우만 시간 복잡도로 구해보자, 가장 빨리 끝나는 경우는 a[0]이 e인 경우 밖에 없으므로 Ω(1)이자 O(1)이다. 이런 경우 둘이 같다(비슷) 따라서 θ(1)로 표기할 수 있다.
가장 늦게 끝나는 경우만을 시간 복잡도로 구한다면 Ω(n)이자 O(n)이다. 이 경우에도 θ(n)으로 표기할 수 있다.
물론 하나의 경우에 대한 시간 복잡도에서만 θ기호를 사용할 수 있는 것이 아니라 위 예제 코드에서 세타를 설명할 수 있는 유일한 방법이라 설명하기 쉽기에 이렇게 분리해서 적었다.
! 위의 설명은 이해하기 쉽게 생략해 적었으며 수학적인 개념과는 일부 다릅니다 !
왜 Ω과 θ는 잘 안쓰는가?
나도 따로 찾아보기 전까지는 이런게 있는지 몰랐다.
- 테스트시에 최선의 경우를 굳이 테스트할 필요가 없어서
- 굳이 tight bound(θ)를 사용했다가 태클을 먹을까봐
- 점근적 표기법의 개념을 몰라서
선형 검색의 시간 복잡도
선형 검색과 이진 검색의 시간 복잡도를 자세히 살펴보자.
static int seqSearch(int[] a, int n, int key) {
1 int i = 0;
2 while(i < n) {
3 if(a[i] == key)
4 return i; // 검색 성공
5 i++
}
6 return -1; // 검색 실패
}아래 표는 위의 코드 1~6의 각 단계별로 실행 횟수를 정리한 것이다.

변수 i에 0을 대입하는 1단계는 처음 한 번 실행하고 나서 이후에는 없다. (데이터 수 n과는 무관) 이렇게 한 번만 실행하는 복잡도는 O(1)로 표기한다. 마찬가지로 메서드에서 값을 반환하는 4단계와 6단계도 한 번만 실행하면 되게 때문에 O(1)로 표기한다.
배열의 맨 끝에 도달했는지 판단하는 2단계와, 현재 선택한 요소와 찾고자 하는 값이 같은지 판단하는 if문의 3단계의 평균 실행 횟수는 n/2이다. 어처럼 n에 비례하는 횟수만큼 실행하는 복잡도는 O(n)으로 표기한다.
※ 복잡도를 표기할 때 사용하는 O는 order의 머리글자로, O(n)은 'O - n', 'Order n', 'n의 Order'등으로 읽는다
컴퓨터에서 n/2와 n의 차이는 크지 않다.
n/2번 실행했을 때 복잡도를 O(n/2)가 아닌 O(n)으로 표현하는 이유는 n값이 무한히 커진다고 가정했을 때 그 값의 차이는 무의미해지기 때문이다. 마찬가지로 100번만 실행하는 경우에도 O(100)이 아닌 O(1)로 표기한다. 컴퓨터가 100번을 계산하는 시간과 한 번만 계산하는 시간의 차이는 사람이 느낄 수 없다. (요즘 CPU는 50억개 이상의 트랜지스터를 가지고있다..)
그런데 n이 점점 커지면 O(n)에 필요한 계산 시간은 n에 비례하여 점점 길어진다. 이와 달리 O(1)에 필요한 계산 시간은 변하지 않는다. 일반적으로 O(f(n))과 O(g(n))의 복잡도를 계산하는 방법은 다음과 같다.
- O(f(n)) + O(g(n)) = O(max(f(n), g(n))
max(a,b)는 a와 b 가운데 큰 쪽을 나타내는 메서드이다.
2개 이상의 복잡도로 구성된 알고리즘의 전체 복잡도는 차수가 더 높은 쪽의 복잡도가 지배한다. 둘 뿐만 아니라 셋 이상의 계산도 마찬가지다. 다시 말해 전체 복잡도는 차수가 가장 높은 복잡도를 선택한다. 그러므로 선형 검색 알고리즘의 복잡도를 구하면 다음처럼 O(n)이 된다.
- O(1) + O(n) + O(n) + O(1) + O(n) + O(1) = O(max(1,n,n,1,n,1)) = O(n)
이진 검색의 시간 복잡도
static int binSearch(int[] a, int n, int key) {
1 int pl = 0; // 검색 범위의 첫 인덱스
2 int pr = n -1; // 검색 범위의 끝 인덱스
do {
3 int pc = (pl + pr) / 2; // 중앙 요소의 인덱스
4 if (a[pc] == key)
5 return pc; // 검색 성공!
6 else if (a[pc] < key)
7 pl = pc + 1; // 검색 범위를 뒤쪽 절반으로 좁힘
else
8 pr = pc - 1; // 검색 범위를 앞쪽 절반으로 좁힘
9 } while (pl <= pr);
10 return -1; // 검색 실패!
}위처럼 sortedArray a를 이진 검색하는 코드가 있다고 가정하자. 해당 코드의 각 실행 단계의 실행 횟수와 복잡도는 아래 표와 같다.
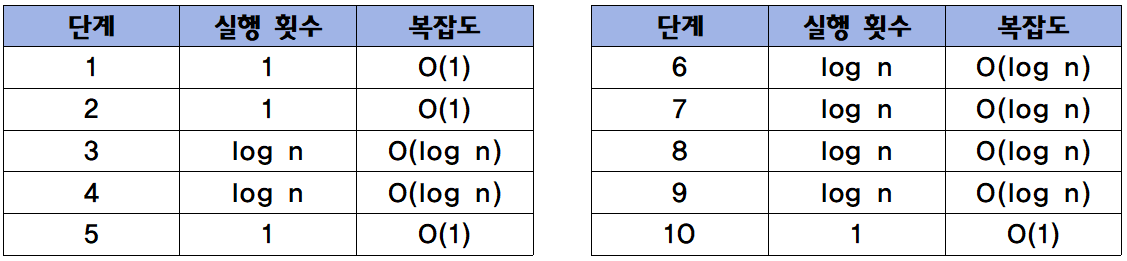
이진 검색 알고리즘의 복잡도는 아래처럼 O(log n)이 됩니다.
- O(1) + O(1) + O(log n) + O(log n) + O(1) + O(log n) + ... + O(1) = O(log n)
복잡도의 대소관계
1 < log n < n < n log n < n^2 < n^3 < n^k < 2^n < n!
오른쪽으로 갈 수록 시간 복잡도가 높다.(실행 속도가 느림)
