재귀란?
어떤 사건이 자기 자신을 포함하고 있거나 또는 자기 자신을 사용하여 정의하고 있을 때 이를 재귀적(recursive)이라고 한다.
보통 예시로 이런 그림을 많이 쓴다.
이러한 재귀의 개념을 사용하면 1부터 시작하여 2,3,...과 같이 무한히 계속되 자연수를 다음과 같이 정의할 수 있다.
- 1은 자연수이다.
- 자연수 n의 바로 다음 정수도 자연수이다.
재귀적 정의(recursive definition)를 사용하여 무한으로 존재하는 자연수를 위의 두 문장으로 정의했다. 재귀를 효과적으로 사용하면 이런 정의뿐만 아니라 프로그램도 간결하게 작성할 수 있다.
※ 재귀 알고리즘은 병함 정렬과 퀵 정렬, 이진검색트리 등에서도 사용한다.
팩토리얼 구하기
재귀를 사용한 예로 가장 먼저 음이 아닌 정수의 팩토리얼을 구하는 프로그램을 살펴보자 음이 아닌 정수 n의 n!은 다음과 같이 재귀적으로 정의할 수 있다.
- 0! = 1
- n > 0이면 n! = n x (n - 1)!
10!은 10 x 9!로 바꿀 수 있고 또 10 x 9 x 8!... 이렇게 계속 늘려서 구할 수 있다.
이 과정을 메서드로 표현하면 아래 코드와 같다.
static int factorial(int n) {
if(n > 0)
return n * factorial(n - 1);
else
return 1;
}factorial메서드가 반환하는 값은 다음과 같다.
- 매개변수 n에 전달받은 값이 0 보다 클 때: n * factorial(n - 1)
- 매개변수 n에 전달받은 값이 0 보다 크지 않을 때: 1
※ 참고로 0! = 1이다.
따라서 main 메서드에서 factorial(5)를 호출하면, factorial이 총 6번 실행됩니다. 스택으로 표기하면
│factorial(0)│
│factorial(1)│
│factorial(2)│
│factorial(3)│
│factorial(4)│
│factorial(5)│
│ main │
└─────────────┘위와 같이 factorial이 factorial을 계속 호출하며 계산하게 된다.
factorial(0)에 도달해서야 비로소 첫 return문이 실행된다. 1이 반환되어 factorial(1)에 1 x 1을 실행하여 return하고, factorial(2)에 1이 반환되어 2 x 1을, factorial(3)에서 3 x 2를, factorial(4)에서 4 x 6을 factorial(5)에서 5 x 24를 최종적으로 연산하여 main메서드에 120을 반환한다.
이러한 factorial 메서드는 n - 1의 팩토리얼 값을 구하기 위해 다시 factorial 메서드를 호출한다. 이러한 메서드 호출 방식을 재귀 호출(recursive call) 이라고 한다.
주의 사항
OS는 프로그램 실행 시 자원을 할당하는데 이 때 스택 영역도 같이 할당 해 준다. 만약 재귀함수의 종료 조건이 명확하지 않아 계속 스택이 쌓이기만 하고 return되지 않는다면, 결국 StackOverFlow가 발생하며 프로그램은 종료될 것이다.
방지책
이러한 사태를 미연에 방지하기 위해서는 재귀함수의 종료조건을 명확하게 작성하고, 재귀함수가 필요없는 경우에는 일반적인 반복문을 사용해서 StackOverFlow가 발생하지 않도록 해야 한다.
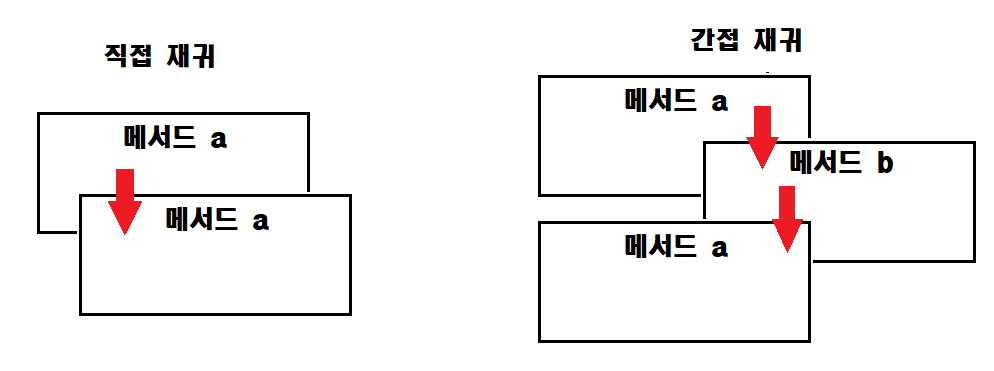
직접 재귀와 간접 재귀
factorial 메서드는 그 내부에서 factorial 메서드를 호출한다. 이처럼 자신과 동일한 메서드를 호출하는 것을 직접(direct) 재귀라고 하고, 메서드 a가 메서드 b를 호출하고, 다시 메서드 b가 메서드 a를 호출하는 구조를 간접 재귀라고 한다.
유클리드 호제법
두 정수의 최대공약수(greatest common divisor)를 재귀적으로 구하는 방법을 알아보자. 두 정수를 직사각형 두 변의 길이라고 생각하면 두 정수의 최대공약수를 구하는 문제는 다음 문장으로 바꿀 수 있다.
-
직사각형을 정사각형으로 빈틈없이 채운다. 이렇게 만들어지는 정사각형 가운데 가장 긴 변의 길이를 구하라.
22x8 인 직사각형에 들어갈 수 있는 최대크기의 정사각형은 각 변이 8인 정사각형일 것이다.
한 변이 8인 정사각형 2개를 넣으면 나머지 공간은 8x6의 직사각형이 남고, 여기에 들어갈 수 있는 최대 길이의 정사각형은 6x6정사각형이다. 1개를 넣을 수 있고 남은 공간은 6x2인 직사각형이남고 여기에는 3개의 2x2정사각형이 들어갈 수 있다. 이 때, 2x2정사각형으로 남은 면적을 꽉 채울수 있었기에 22와 8의 최대공약수는 2임을 알 수 있다. -
y = 0일 때 최대공약수: x
-
y != 0일 때 최대공약수: gcd(y, x % y)
import java.util.Scanner;
public class EuclidGCD {
static int gcd(int x, int y) {
if (y == 0)
return x;
else
return gcd(y, x % y);
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println(" 두 정수의 최대공약수를 구합니다.");
System.out.print("x정수를 입력하세요: "); int x = sc.nextInt();
System.out.print("y정수를 입력하세요: "); int y = sc.nextInt();
System.out.println("x, y의 최대 공약수는 " + gcd(x, y) + "입니다.");
}
}gcd()메서드가 유클리드 호제법을 활용한 재귀 함수인데, 한 번 훑어보면 누구나 이해할 수 있을정도로 쉬운 구성이다.
재귀 알고리즘의 비재귀적 표현
간단한 재귀 메서드 recur을 다음과 같이 정의합니다.
static void recur(int n) {
if(n > 0) {
recur(n - 1);
System.out.println(n);
recur(n - 2);
}
}recur메서드는 n이 1이상이라면 재귀 호출을 2회 실행합니다. 이처럼 재귀 호출을 여러 번 실행하는 메서드를 순수(genuinely) 재귀라고 하는데, 실제 동작은 매우 복잡해진다. 이 메서드에 4를 인자로 넘기면 1231412라는 값을 print하게 된다.
꼬리 재귀의 제거
메서드의 꼬리에서 재귀를 호출하는 메서드 recur(n - 2)는 '인수로 n - 2를 전달하여 recur 메서드를 호출한다'는 의미이다. 따라서 이 호출은 다음처럼 바꿀 수 있다.
- n값을 n - 2로 업데이트하고 메서드의 시작 지점으로 돌아갑니다.
static void recur(int n) {
while (n > 0) {
recur(n - 1);
System.out.println(n);
n = n - 2;
}
}위 코드가 바로 꼬리 재귀를 제거한 코드이다. 반복이 필요하기에 if문 대신에 while문으로 바뀌었다.
재귀의 제거
그런데 꼬리 재귀와는 다르게 앞쪽에서 호출하는 재귀 메서드는 제거하기가 쉽지 않다. 변수 n값을 출력하기 전에 recur(n - 1)을 실행해야 하기 때문인데, 꼬리 재귀를 제거할때처럼 n값을 n - 1로 업데이트하고 메서드의 시작 지점으로 돌아갈 수 없습니다.
예를 들어 n이 4인 경우 재귀 호출 recur(3)가 처리가 완료되지 않으면 n값인 '4'를 저장해야 한다.
- 현재 n값을 '잠시'저장한다.
그리고 recur(n - 1)의 처리가 완료된 다음에 n값을 출력할 때는 다음 과정을 따르게 된다.
- 저장했던 n을 다시 꺼내 그 값을 출력한다.
이러한 재귀 호출을 제거하기 위해서는 변수 n값을 '잠시' 저장해야 한다는 사실을 알았다. 이 때 이런 문제를 해결할 수 있는 데이터 구조가 스택이다.
public class Recur2 {
static void recur(int n) {
IntStack s = new IntStack(n);
while (true) {
if(n > 0) {
s.push(n);
n = n - 1;
continue;
}
if(s.isEmpty() != true) {
n = s.pop();
System.out.println(n);
n = n - 2;
continue;
}
break;
}
}
}
class IntStack { //스택 클래스
private int[] stk;
private int capacity;
private int ptr;
public IntStack(int max) {
ptr = 0;
capacity = max;
try {
stk = new int[capacity];
} catch(OutOfMemoryError e) {
capacity = 0;
}
}
public int push(int x) {
if(ptr >= capacity) {
System.out.println("스택이 가득 참");
}
return stk[ptr++] = x;
}
public int pop() {
if(ptr <= 0) {
System.out.println("스택이 비었음");
}
return stk[ptr--];
}
public boolean isEmpty() {
return ptr <= 0;
}
}recur(4)를 호출한 다음 위 코드가 실행되는 과정을 살펴보자. 매개변수 n에 전달받은 값'4'는 0보다 크므로 맨 앞의 if문에 의해 다음과 같은 과정이 진행된다.
- n값 4를 스택에 푸시한다
- n값을 하나 줄여 3으로 만든다.
- continue문에 의해 while문의 맨 앞으로 돌아간다.
n값 3은 0보다 크므로 맨 앞의 if 문이 실행된다. 그 결과 위의 과정이 반복되고 스택에 4,3,2,1이 쌓이게 된다. 스택에 1을 쌓은 다음 n값은 0이 되고 while문의 맨 앞으로 돌아간다. 그러면 n값이 0이므로 맨 앞의 if문은 그냥 지나가고 그 다음 if문에 의해 다음과 같은 과정이 진행된다.
- 스택에서 pop()한 값 1을 n에 넣는다.
- n값 1을 출력한다.
- n값을 2 줄여 -1로 만든다.
- continue문에 의해 while 문의 처음으로 돌아간다.
메모화
위 recur 메서드는 실행 과정에서 같은 계산을 여러 번 반복하여 수행한다. recur(4)를 실행했을 때에 recur(1) 메서드는 if문에 걸러져서 아무일도 하지 않지만 3번이나 실행한다. n값이 커지면 반복하는 계산 횟수는 더 늘어날 것이다. 이럴때 메모화(memoization) 기법을 사용하면 동일한 계산을 반복하지 않고 1회만 수행할 수 있다.
어떤 문제(이 경우 recur메서드가 전달받는n)에 대한 답을 구할 경우 그것을 메모해 둡니다.
예를 들어 recur(3)은 1,2,3,1을 차례로 출력하기에 출력할 문자열 "1\n2\n3\n1"을 메모합니다. 다시 recur(3)이 호출됐을 때에는 메모해 둔 문자열을 화면에 출력하면 중복하여 계산할 필요가 없게 됩니다.
public class RecurMemo {
static String[] memo;
static void recur(int n) {
if(memo[n + 1] != null)
System.out.print(memo[n + 1]); // 메모를 출력
else {
if(n > 0) {
recur(n - 1);
System.out.println(n);
recur(n - 2);
memo[n + 1] = memo[n] + n + "\n" + memo[n - 1]; // 메모화
} else {
memo[n + 1] = ""; // 메모화: recur(0)과 recur(-1)은 빈 문자열
}
}
}
// n[0] = "", n[1] = "", n[2] = "1\n", n[3] = "1\n2\n", n[4] = "1\n2\n3\n1\n", n[5] = "1\n2\n3\n1\n4\n1\n2\n"
// 1 2 3 1 4 1 2
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.print("정수를 입력하세요: ");
int x = sc.nextInt();
memo = new String[x + 2];
recur(x); // 연산 후 메모화
System.out.println("------구분------");
recur(x); // 메모화 한 내용만 가져옴.
}
}천천히 recur(3)부터 어떻게 진행되는지 눈으로 보면서 메서드를 읽어보면 이해하기 쉽습니다.
recur(-1)의 실행 결과 "" -> memo[0]
recur(0)의 실행 결과 "" -> memo[1]
recur(1)의 실행결과 "1\n" -> memo[2]
recur(2)의 실행결과 "1\n2\n" -> memo[3]
이런식으로 차차 저장이 되는데, n이 작을때에는 그렇게 큰 차이가 아니지만 n = 5이상 일때 부터는 2배이상씩 차이나기 시작한다.
recur()메서드 호출 횟수 ↓

