🚀 우선 이번주 시행했던 플랜을 공유드리겠습니다
⭐️ 이 글에서는 코딩테스트 문제만 리뷰하겠습니다.
제가 이번주에 푼 22문제 중에서 제일 애먹었던 문제 3개만 리뷰하도록 하겠습니다.
1️⃣ 📚 더 맵게 (프로그래머스 레벨2)

이 문제는 전형적인 우선순위 큐 를 사용하는 문제입니다. 이유는 다음과 같은데요.
- 삽입과 동시에 정렬이 필요한 리스트가 필요하다
따라서 저는 위 문제의 풀이에 우선순위 큐를 적극 이용하였습니다.
import heapq
combine_food = lambda x, y: x + 2 * y
def solution(foods, K):
count = 0
q = [] # 우선순위 큐를 이용하기 위한 리스트 객체
# 모든 음식을 우큐에 넣는다
for food in foods:
heapq.heappush(q, food)
# 모든 음식의 스코빌이 K 이상이 되도록 반복한다
while q[0] < K:
try:
first = heapq.heappop(q)
second = heapq.heappop(q)
result = combine_food(first, second)
count += 1
heapq.heappush(q, result)
except IndexError:
return -1
return count원리는 매우 간단합니다.
- Python의 우선순위큐는 min heap이기 때문에 제일 앞의 숫자가 최소값이다. 따라서 최소값 (pop의 결과)이 K 이상이면 모든 음식의 스코빌이 K 이상이다.
- 그렇지 않고 혼합이 계속 필요한 경우에는, 혼합을 하고 계속 우선순위 큐에 push한다
- second를 가져올 수 없어서 IndexError가 검출되면 모든 음식을 스코빌 K 이상으로 못 만들기 때문에 -1을 반환한다.
이 로직을 그대로 코드로 반영하면 되겠습니다.
2️⃣ 📚 불량사용자 (프로그래머스 레벨3)
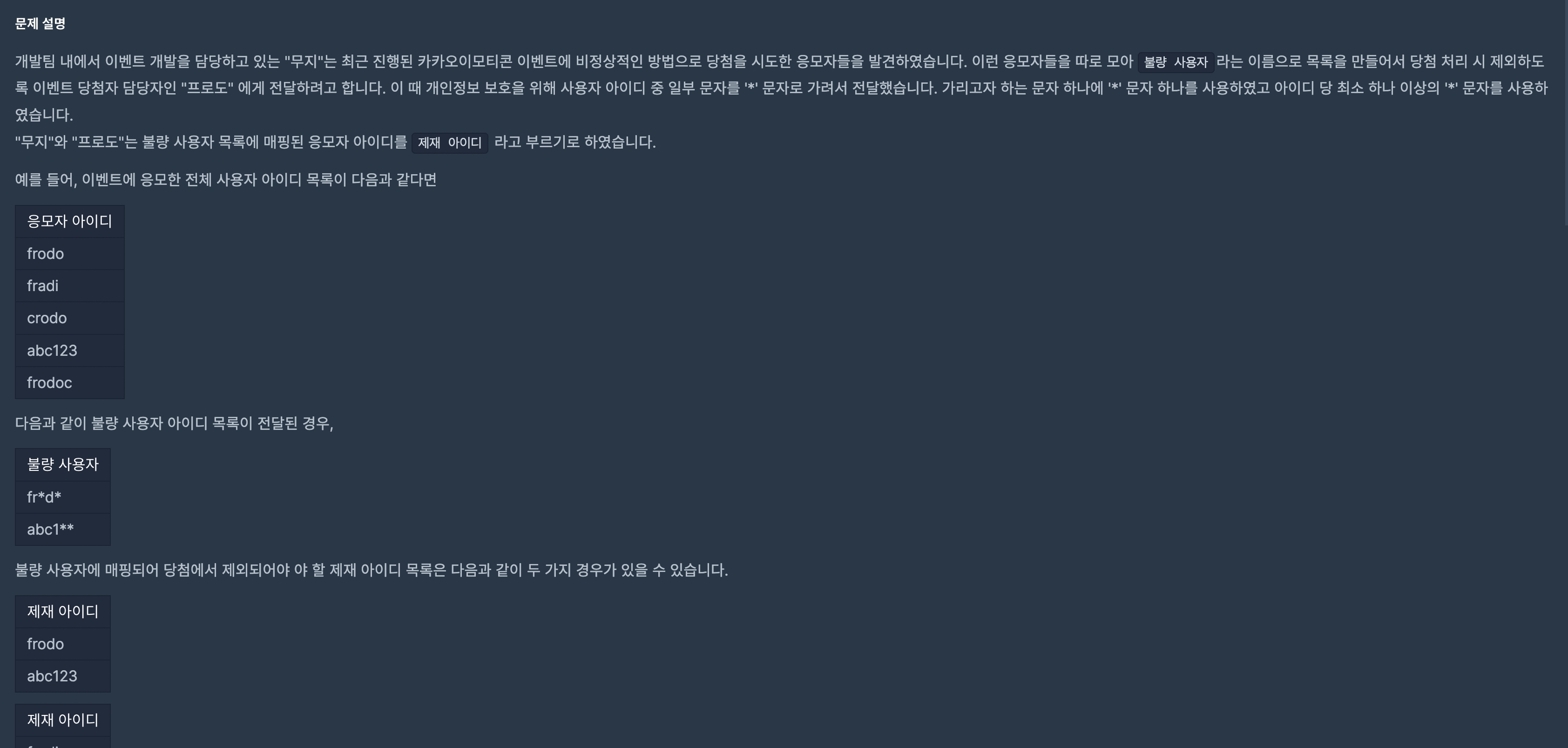
위 문제는 2019년도 카카오 블라인드 채용 문제였습니다. 게다가 레벨3 짜리 문제이기 때문에 상당한 난이도를 가지고있던 문제입니다.
이 문제 풀이를 위해서 저는 set 자료구조와 재귀함수를 적극 이용하였습니다.
import copy
# ban_id에 user를 배열로 엮어서 sequence를 반환해주는 함수
def get_sequence(user_id, banned_id):
sequence = []
# banned_id -> user_id를 탐색하면서 sequence를 채우는 로직
for ban in banned_id:
user_list = []
for user in user_id:
is_equals = False
# 길이가 똑같은 경우에는
if len(ban) == len(user):
is_equals = True
# 각각의 문자를 대조한다
for ban_token, user_token in zip(ban, user):
# 만약에 ban_token이 *인 경우에는 비교를 패스한다
if ban_token == '*':
continue
# ban_token이 문자인 경우에는 비교를 수행한다
else:
if ban_token != user_token:
is_equals = False
# 만약에 일치했다면 user_list에 더해준다
if is_equals == True:
user_list.append(user)
# sequence에 반영한다
sequence.append([ban, user_list])
return sequence
# 중복을 검사해서 result_list에 result를 append 시키는 함수
def append_without_duplicate(result_list, result):
if result not in result_list:
result_list.append(result)
# 재귀함수를 기반으로 sequence를 탐색하는 함수
# count: 현재의 depth, sequence: 주어진 sequence, user_list: 유저의 목록
# result: 현재 탐색한 user의 집합, result_list: 모든 탐색 결과를 저장하는 배열
def func(count, sequence, user_list, result, result_list):
# 만약에 탈출 조건을 만족하는 경우 -> 모든 banned list를 탐색 완료한 경우
if count == len(sequence):
tmp = copy.deepcopy(result)
append_without_duplicate(result_list, tmp)
return
# 순차적으로 계속 탐색
ban_id, target_list = sequence[count] # count index에 해당하는 [ban, user_list]를 탐색
# user를 한명씩 돌면서 ban에 binding 시킨다
for target in target_list:
# 우선 target이 user_list에 계신지 확인부터 해야한다
if target not in user_list:
continue
# 우선 result에 target을 집어넣고, user_list에서는 해당 target을 제외시켜버린다
result.add(target)
user_list.pop(user_list.index(target)) # user에는 중복이 없기 때문에 가능
func(count + 1, sequence, user_list, result, result_list) # depth를 1 늘려서 탐색
# 탐색을 완료한 다음에는 복구시켜야한다
result.remove(target)
user_list.append(target)
def solution(user_list, banned_list):
result_list = []
# banned_id, dup_num, listOf(user_id)를 저장
sequence = get_sequence(user_list, banned_list)
# 재귀함수 호출
func(0, sequence, user_list, set(), result_list)
return len(result_list)제가 이 문제 풀이를 위해서 구현한 함수는 3가지 인데요, 하나씩 소개하겠습니다.
👉 def get_sequence(user_id, banned_id)
ban 정보에 user_id를 여러개 매핑해서 매핑 결과를 리스트로 만들어 반환해주는 함수입니다.
👉 append_without_duplicate(result_list, result)
result_list에 result를 중복없이 append를 해주는 함수입니다.
👉 func(count, sequence, user_list, result, result_list)
본 문제의 가장 핵심이 되는 함수가 되겠습니다. 재귀함수 구현을 이용해서 완전탐색을 수행합니다.
- sequence에서 ban마다 대응하는 user를 한 명씩 조회한다.
- user가 이미 result에 있으면 로직을 패스한다
- 그렇지 않다면 user를 result에 추가시키고 user_list에서 제외시킨다.
- 재귀적인 접근을 이용해서 같은 함수를 count만 1을 추가해서 돌린다.
- count가 모두 다 차면 result를 중복없이 result_list에 append한다.
위의 로직을 코드로 구현하면 위와 같이 작성이 되겠습니다.
3️⃣ 📚 셔틀버스 (프로그래머스 레벨3)

위 문제는 2018년도 카카오 블라인드 채용 문제입니다. 그리고 레벨3이기 때문에 난이도가 매우 상당합니다.
위 문제는 구현 문제인데요, 코드를 소개하겠습니다.
# 주어진 시간 문자열을 정수로 바꿔주는 함수
def time_str_to_int(time):
hour, minute = map(int, time.split(':'))
return hour * 60 + minute
# 주어진 시간 정수열을 문자열 형태로 변환시켜서 반환하는 함수
def time_int_to_str(time):
hour = time // 60
minute = time - (hour * 60)
hour = str(hour) if hour >= 10 else '0' + str(hour)
minute = str(minute) if minute >= 10 else '0' + str(minute)
return hour + ':' + minute
# 주어진 timetable을 모두 정수 타입으로 변환시키는 함수
def transform_timetable(timetable):
result = []
for time in timetable:
result.append(time_str_to_int(time))
return result
def solution(n, t, m, timetable):
answer = 0
timetable = transform_timetable(timetable) # 시간표를 모두 정수 타입으로 변환
timetable.sort() # 타임 테이블을 정렬
bus_timetable = [540 + t * i for i in range(n)] # 버스 시간표
crew_index = 0 # 크루들에 대한 인덱스 변수
# 버스 시간표를 조회한다
for bus_time in bus_timetable:
count = 0 # 현재 버스에 타고있는 사람의 수
# 크루들을 버스에 태운다
while count < m and crew_index < len(timetable) and timetable[crew_index] <= bus_time:
count += 1
crew_index += 1
# 남는 자리가 있는 경우에는 버스 시간에다가 그대로 세우면 된다
if count < m:
answer = bus_time
else:
answer = timetable[crew_index - 1] - 1
answer = time_int_to_str(answer)
return answer위 문제의 핵심은 아래와 같습니다.
- 버스 시간표에 따라서 계속 크루들을 태운다
- 버스에 남는 자리가 계속 있으면 계속 answer을 해당 버스 시간으로 태워버리면된다.
- 끝까지 버스에 남는 자리가 없다면, crew를 한 명 쫓아내고 자기가 타면 된다. 즉, 마지막 crew가 선 시간에서 1만 빼서 서면 된다.
위의 논리를 코드에 그대로 반영하면 위의 코드와 같이 구현이 되겠습니다.
😭 주간 반성 (알고리즘)
이번주에는 원래 24문제를 풀 계획이었으나, 레벨2에 1문제, 레벨3에 1문제를 못 풀게 되었습니다. 이 문제들은 다음주로 이관해서 풀 예정입니다.
그래도 나름 22/24 를 하였기 때문에 만족스러운 것 같습니다!
이번주는 레벨2에서 3문제, 레벨3에서 2문제를 틀렸는데, 다음주는 반드시 레벨2에서 틀리는 문제를 2문제까지 줄여볼 예정입니다.
다음주부터는 제가 약한 완전탐색 유형을 좀 위주로 해볼 계획입니다.
