mysql 8.0 Command Line Client 사용
database 선택
show databases;가지고 있는 데이터 베이스의 목록 출력
한 가지를 결정해
use (database 이름);Table
예제로 student table을 사용합니다.
새로운 table 생성
학생 테이블 생성
create table student (sid int, name char(20),
age int, gpa real);table 삭제
모든 tuple, schema 정보가 삭제된다.
drop table student;table의 datatype 확인하기
해당 테이블의 field와 datatype을 알 수 있다.
show columns from student;Tuple
새 tuple 입력
insert into student(sid, name, age, gpa)
values (500, 'happy', 11, 4.5)
이어서 여러 개의 tuple을 입력할 수 있다.
insert into student(sid, name, age, gpa) values
(501, 'a', 12, 4.3),
(502, 'b', 13, 4.2);해당 tuple 삭제
delete from student a where a.name = 'happy';해당 tuple의 field값 수정
update student a set a.gpa = a.gpa - 0.1 where a.gpa >= 3.3;
key 제약조건
create table student (sid int, name char(20),
age int, gpa real, unique(name, age), primary key(sid)); -
한 relation은 여러 개의 candidate key를 가질 수 있다. (unique)로 표시.
-
primary key는 하나이다. (여러 candidate key 중)
예제에서는 unique(name, age)인데 여러 candidate key 중에 하나라는 primary key는 sid를 가진다는게 뭔지 잘 모르겠다...
foreign key 표현
enroll = 수강 table
create table enroll (studid int, cid int, cname char(20),
primary key (studid, cid),
foreign key (studid) references student(sid));student table에 등록된 student만 과목 수강(enroll) 가능
Referential Integrity (참조 무결성)
등록된 학생이 아니라면 수강 table 입력 거부
학생 table로부터 수강등록학생 삭제하면 삭제 거부
create table enroll(studid int, cid int, cname char(20),
primary key(studid, cid),
foreign key(studid) references student (sid)
on delete cascade on update no action);cascade - 참조 측까지 연쇄 삭제
no action - 작업 거부
set default - 참조 측 값을 default로
set null - 참조 측 값을 null로
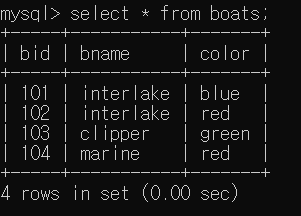
기본 문법과 예제 (Sailors, Reserves, Boats)

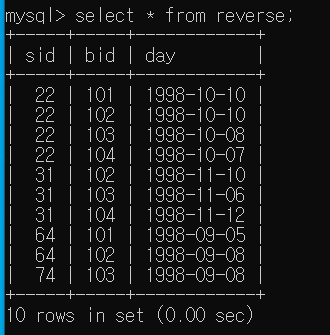
reserves로 수정했습니다.
sql 질의어 기본 형태
select A
from B
where P
Q15. 모든 선원의 이름과 나이를 찾아라
select s.sname, s.age
from sailors s;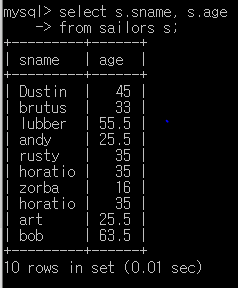
Q11. 7 초과의 rating을 가진 모든 선원을 찾아라
select *
from sailors s
where s.rating > 7;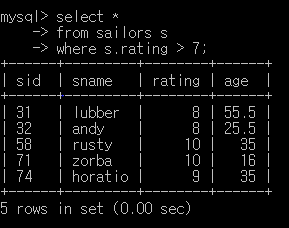
- -> 모든 column을 출력해줍니다.
원래는 from sailors as s 이지만
중간의 as는 생략 가능합니다.
sql 질의어 문법
from 절의 from-list : table의 이름들
select 절의 select-list : table의 column 이름
where 절의 조건 : 수식에 대한 boolean 조합
distinct keyword = 생략 가능, 중복 제거시 사용
질의 처리 순서
-
from-list의 table 에 대한 cross-product 계산
-
cross-product로부터 조건식을 만족하지 않는 tuple 제거
-
select-list에 나타나지 않는 모든 column 제거
-
만약 distinct 키워드가 있다면, 중복 tuple 제거
Q1. 보트 103을 예약한 사람의 이름
select s.sname
from sailors s, reserves r
where s.sid = r.sid and r.bid = 103;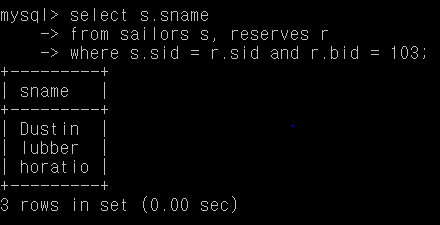
Q16. 빨간 보트를 예약한 사람의 sid를 찾아라
boats, reserves table이 필요하다.
select distinct r.sid
from boats b, reserves r
where b.bid = r.bid and b.color = 'red';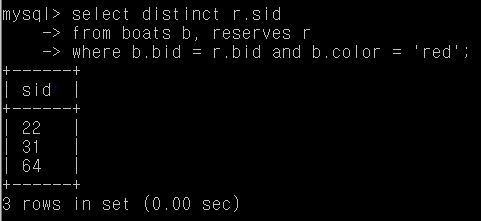
Q1. 빨간 보트를 예약한 사람의 이름을 찾아라
Q16 + sailors table 추가로 필요
select distinct s.sname
from sailors s, boats b, reserves r
where s.sid = r.sid and b.bid = r.bid and b.color = 'red';
Q3. lubber에 의해 예약된 보트의 색깔을 찾아라
select distinct b.color
from sailors s, boats b, reserves r
where s.sid = r.sid and b.bid = r.bid and s.sname = 'lubber';
Q4. 한 보트 이상 예약한 사람의 이름
sailors, reserves table 필요
select distinct s.sname
from sailors s, reserves r
where s.sid = r.sid;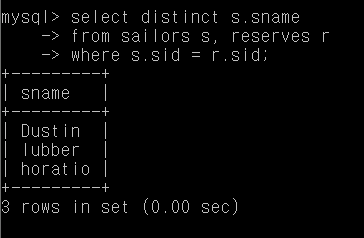
수식과 문자열
Q17. 같은 날에 두 대의 다른 보트를 탄 사람의 rating을 증가시켜라
select distinct s.sname, s.rating+1 as rating1
from sailors s, reserves r1, reserves r2
where s.sid = r1.sid and s.sid = r2.sid and r1.day = r2.day and r1.bid <> r2.bid;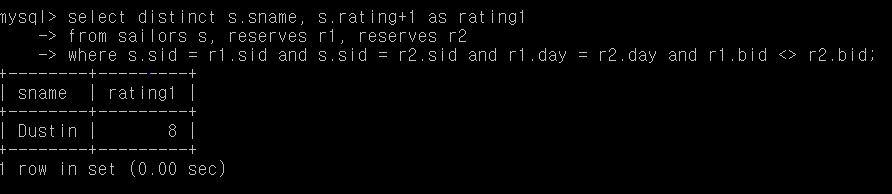
문자열 연산 : like 연산자 사용
% = zero or 임의의 문자 (문자가 있어도, 없어도 된다.)
_ = 임의의 한 문자
예제)
select *
from sailors s
where s.sname like 'b_%b';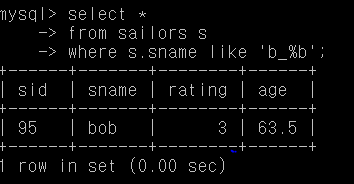
UNION 연산
Q5. 빨간색 혹은 녹색 배를 예약한 사람의 이름
select s.sname
from sailors s, boats b, reserves r
where s.sid = r.sid and b.bid = r.bid and b.color = 'green'
union
select s2.sname
from sailors s2, boats b2, reserves r2
where s2.sid = r2.sid and b2.bid = r2.bid and b2.color = 'red';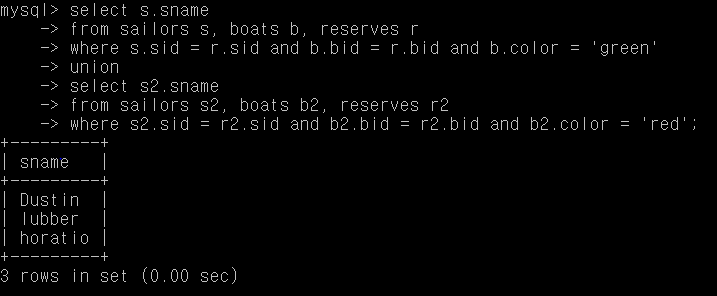
INTERSECT, EXCEPT
except (minus) 연산과 intersect (교집합) 연산을 사용하면 error가 발생하길래
찾아보았더니 mysql에서는 except와 intersect가 없다고 한다...
해결 방법은 이 분의 블로그를 참고했습니다.
(mysql에 대한 책을 여러 권 쓰신 분입니다.)
나는 intersect를 이 문장에 적용하려고 했는데 잘 모르겠다...
select s.sname
from sailors s, boats b1, reserves r1
where s.sid = r1.sid and
b1.bid = r1.bid and
b1.color = 'green'
intersect
select s.sname
from sailors s2, boats b2, reserves r2
where s2.sid = r2.sid and
b2.bid = r2.bid and
b2.color = 'red';
except문
Q19. 빨간색은 예약, 녹색은 예약하지 않은 사람의 sid
select r.sid from boats b, reserves r
where r.bid = b.bid and b.color = 'red'
except
select r2.sid from boats b2, reserves r2
where r2.bid = b2.bid and b2.color = 'green';이 문장을 mysql에서 중첩 질의를 통해 해결했다.
정확한 풀이가 맞는지는 잘 모르겠지만
이 예제에서는 답이 맞게 나왔다.
select r.sid from boats b, reserves r
where r.bid = b.bid and b.color = 'red' and
r.sid not in
(select r2.sid from boats b2, reserves r2
where r2.bid = b2.bid and b2.color = 'green');

또 하나, 뒤쪽을 찾아 보니 not exists 로도 쉽게 except 할 수 있는 것 같다.
union compatible (union연산 호환성?)
같은 column 개수, 각 column에서 같은 datatype을 가지고 있어야 union compatible이 충족된다.
Q20. rating 10 또는 예약 보트 104를 가진 사람의 sid
select s.sid from sailors s where s.rating = 10
union
select r.sid from reserves r where r.bid = 104;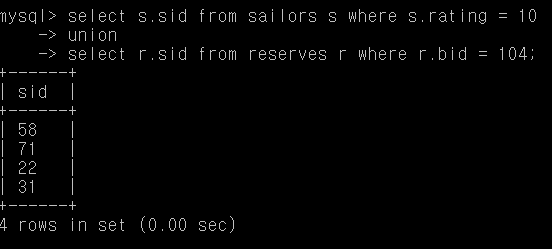
nested query (중첩 질의)
- query 내에 포함된 다른 query
- '주로' where 절에서 사용
- subquery라고 불림
Q1. 보트 103을 예약한 사람의 이름
select s.sname from sailors s
where s.sid in (
select r.sid from reserves r
where r.bid = 103);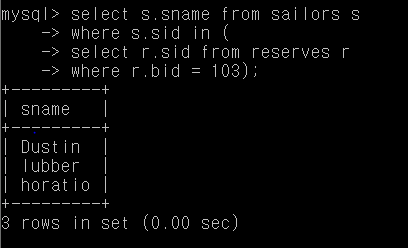
multilevel nested query
Q2. 빨간 보트를 예약한 사람의 이름
select s.sname from sailors s
where s.sid in (
select r.sid from reserves r
where r.bid in (
select b.bid from boats b
where b.color = 'red'));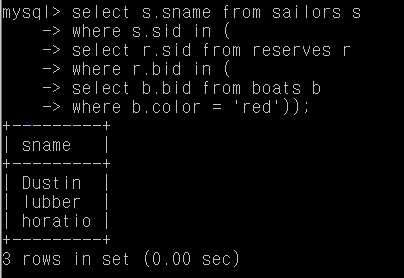
-> (boats b 에서 color가 red 인 b.bid 선택) = B 라고 하겠다.
-> (reserves r에서 r의 bid가 B 안에 있는 sid 선택) = R
-> s.sid 가 R 안에 있는 sailor의 sname 선택
Q21. 빨간 보트를 예약하지 않은 사람의 이름
select s.sname from sailors s
where s.sid not in(
select r.sid from reserves r
where r.bid in(
select b.bid from boats b
where b.color = 'red'));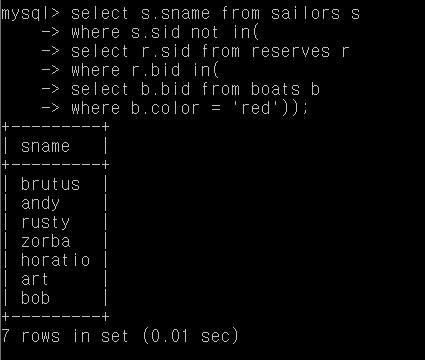
이 때 NOT IN의 위치를 바꾸어준다면?
-
NOT IN의 위치가 안쪽일때
빨간색이 아닌 보트를 예약한 사람의 이름 출력 -
둘 다 NOT IN일 때
빨간 보트만 예약했거나, 어떠한 보트도 예약하지 않은 사람의 이름 출력
상호 연관된 nested query
바깥 질의와 내부 질의가 서로 연관성을 가질 때
EXISTS 연산자 사용
Q1. 보트 103을 예약한 사람의 이름
select s.sname from sailors s
where exists (
select * from reserves r
where r.bid = 103 and r.sid = s.sid);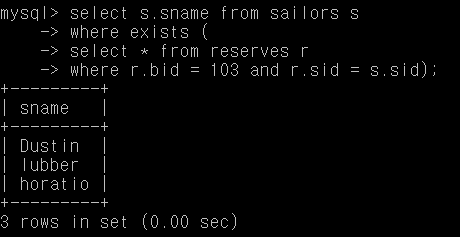
set comparison 연산자
(집합 비교 연산자??)
- IN, EXISTS, UNIQUE
- op ANY (or Some) , op ALL 연산자.
(op는 >, <, <> 등의 비교 연산자)
Q22. horatio 보다 더 높은 rating을 가진 사람의 sid
(동명이인이 존재)
select s.sid from sailors s
where s.rating > any(
select s2.rating from sailors s2
where s2.sname = 'horatio');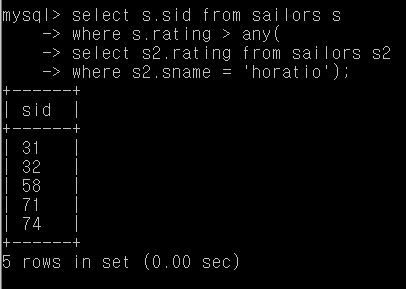
여기서는 horatio의 rating이 7, 9라서 7보다 높은 rating을 가진 사람이 전부 다 출력됩니다.
Q23. 모든 horatio 보다 더 높은 rating을 가진 사람의 sid
select s.sid from sailors s
where s.rating > all (
select s2.rating from sailors s2
where s2.sname = 'horatio');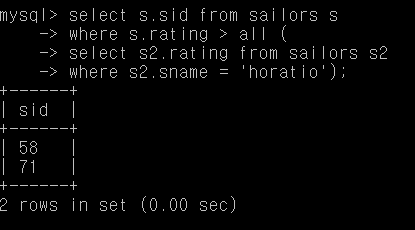
여기서는 rating > 9인 사람만 출력됩니다.
Q22. 가장 높은 rating을 가진 사람의 sid
select s.sid from sailors s
where s.rating >= all (
select s2.rating from sailors s2);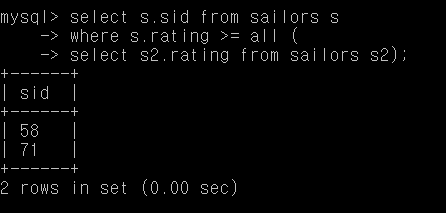
in 은 =any ,
not in 은 <>all과 같다.
NOT EXIST, EXCEPT 차이의 예제
Q9.
모든 보트를 예약한 사람의 이름 출력 (이해 못함)
select s.sname from sailors s
where not exists (
select b.bid from boats b
where not exists (
select r.bid from reserves r
where r.bid = b.bid and r.sid = s.sid));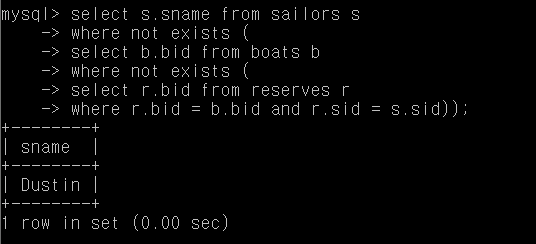
이 문장과
select s.sname from sailors s
where not exists (
select b.bid from boats b
except (
select r.bid from reserves r
where r.sid = s.sid));이 문장의 차이는?
except는 minus 의 개념 (차집합)
not exist는 그 조건에 만족하지 않는 것을 골라낸다고 해야 하나?
except가 (A-B)라면 NOT EXISTS는 그냥 하나의 A' ??
-> 위의 문장은 r.bid = b.bid and r.sid = s.sid
즉 예약된 보트, 그리고 예약한 사람이 있을 때
aggregate 함수
input으로 값들의 집합,
output으로 단일 값 return
Q26. rating 10을 가진 사람의 평균 나이
select avg(s.age) from sailors s
where s.rating = 10;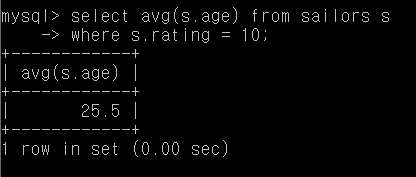
Q27. 가장 나이 많은 사람의 이름과 나이
select s.sname, s.age from sailors s
where s.age = (select max(s2.age) from sailors s2);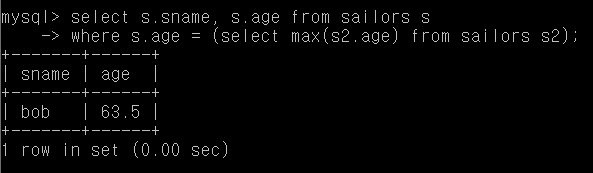
Q28. 선원의 수
select count(*) from sailors s;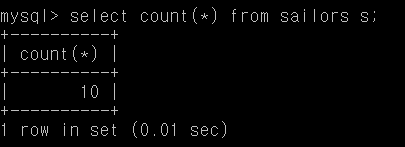
Q29. 서로 다른 선원이름의 수
select count(distinct s.sname) from sailors s;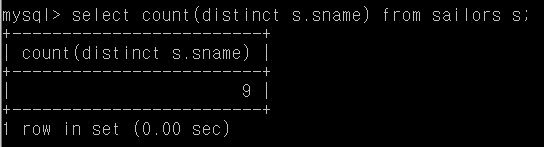
Q30. rating 10의 사람 중 가장 나이 많은 사람보다 더 나이가 많은 사람들의 이름
select s.sname from sailors s
where s.age > (
select max(s2.age) from sailors s2
where s2.rating = 10);
== 둘이 같은 의미의 문장이다. ==
select s.sname from sailors s
where s.age > all(
select s2.age from sailors s2
where s2.rating = 10);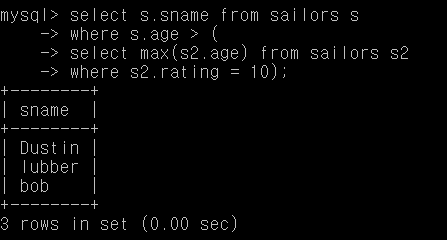
Q30-1. rating 10의 사람 중 가장 나이 많은 사람의 이름
select s.sname, max(s.age) from sailors s
where s.rating = 10;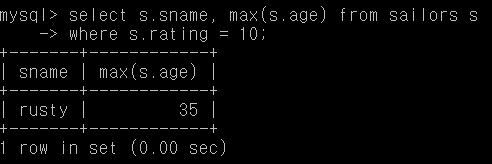
GROUP BY, HAVING 절
Q32. 나이 >= 18인 사람이 2명 이상 있는 rating에서, rating 별 가장 어린 사람의 나이
select s.rating, min(s.age) as minage from sailors s
where s.age >= 18
group by s.rating
having count(*) > 1;
//참고
count(*) O
count (*) X
COUNT와 (*)를 뛰어주니 ERROR가 발생했다.GROUP-BY절 실행 순서
1) from-list 의 cross-product 연산
- 한 relation이라서 s 자체
2) where 절의 조건 (s.age >= 18) 적용
- 조건을 만족하지 않는 tuple 삭제
3) 불 필요한 column 삭제
- sid, sname 삭제
4) group-by 절에 따라 table sorting
5) having 절의 조건 (count(*) > 1) 적용
- rating 개수가 1개 이하인 tuple 삭제
6) 남은 group에 대한 결과 출력
select s.rating, min(s.age) from sailors s
where s.age >= 18
group by s.rating
having count(*) > 1
every(s.age <= 60);
이 문장은 실행되지 않는데 왜일까??..
HAVING 절에 올 수 있는 것은
GROUP BY절에 나타난 Column만 올 수 있다고 한다.
그리고 aggregate 연산도 가능하다고 한다.
그럼 결과 출력이 다르다는데 ??select s.rating, min(s.age) from sailors s
where s.age >= 18 and s.age <= 60
group by s.rating
having count(*) > 1;두 문장은 다르다.
Q33. 각 빨간 보트에 대한 예약의 수
select b.bid, count(*) as sailorcount
from boats b, reserves r
where r.bid = b.bid and b.color = 'red'
group by b.bid;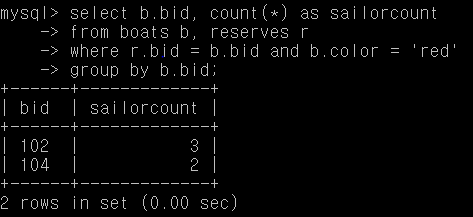
Q34. 적어도 두 명의 사람이 있는 rating에 대한, rating별 평균 나이
select s.rating, avg(s.age) from sailors s
group by s.rating having count(*) > 1;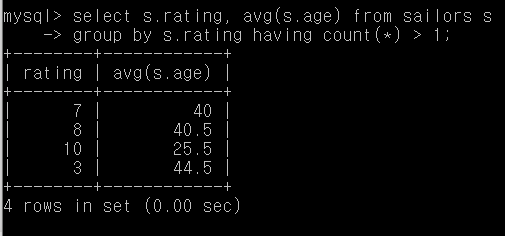
Q35. 적어도 두 명의 사람이 있는 rating에 대한, 18세 이상인 사람의 rating별 평균 나이
select s.rating, avg(s.age) from sailors s
where s.age >= 18
group by s.rating
having 1 < (select count(*) from sailors s2
where s.rating = s2.rating);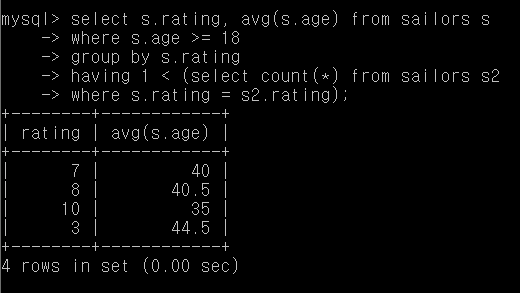
Q36. 18세 이상인 사람이 적어도 2명이 있는 rating에 대한, rating별 평균 나이
select s.rating, avg(s.age) from sailors s
where s.age >= 18
group by s.rating
having 1 < (select count(*) from sailors s2
where s.rating = s2.rating and
s2.age >= 18);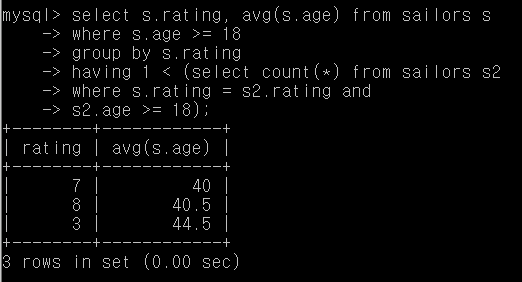
select s.rating, avg(s.age) from sailors s
where s.age >= 18
group by s.rating
having count(*) > 1;두 문장은 같다.
Q37. 모든 rating에 대해서, rating별 평균 나이가 가장 작은 rating과 평균 나이
select s.rating from sailors s
where avg(s.age) = (
select min(avg(s.age)) from sailors s2
group by s2.rating)
//
min(avg()) 과 같이 사용할 수 없다.
//
select temp.rating, temp.average
from (select s.rating, avg(s.age) from sailors s
group by s.rating) as temp
where temp.average = (
select min(temp.average) from temp);
문장에서 오류나는데 모르겠다.null 값
column 값은 unknown일 수 있다.
어떤 사람이 새로 요트club에 가입시, rating이 없다. -> rating unknown
이 때 특별한 column값 null을 사용한다.
null 값을 허용하지 않을 때
not null 사용시
primary key는 묵시적으로 not null 제약조건을 포함한다.
비교
< > = 등을 이용한 null 값의 비교
결과는 ? unknown
(특별 비교연산자 is null, is not null 이 있다.)
sql에서의 영향
where 절에서 true가 아닌 모든 tuple (false, unknown) 삭제
<abc, null>과 <abc, null>의 중복 체크시, true로 취급된다.
argument로 null 값이 포함된 수치연산의 결과는 null
count(*)에서 null값은 다른 값처럼 취급
모두 다른 aggregate 연산에서 null 값은 무시됨.
outer join (left, right, full)
정보의 손실을 피하기 위한 join연산의 확장
join에 참여하지 않는 tuple의 상대 field는 null이 채워줌
예제 table 정보
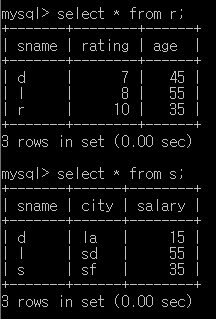
natural join
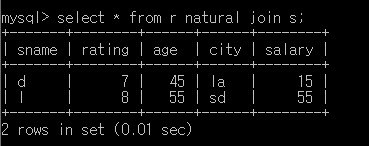
left join
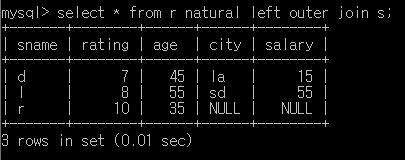
right join
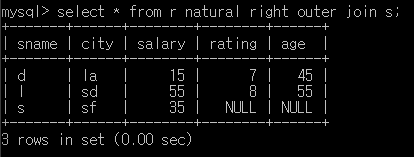
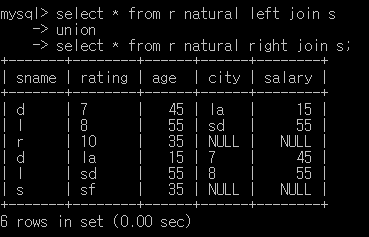
full join (mysql에서는 full outer join이 없어 union을 사용해 만들었다. 중복을 제거하고 싶은데.
제약조건
sql에서의 제약조건
예제) rating의 범위가 1이상 10이하 일 때만 입력을 허용한다
create table sailors (
sid int, sname char(20), rating int, age real, primary key(sid),
check (rating >= 1 and rating <= 10);예제) interlake 보트를 예약할 수 없도록 제한한다.
create table reserves (
sid int, bid int, day date,
foreign key (sid) references sailors,
foreign key (bid) references boats
constraints nointerlakeboats
check ('interlake' <> (select b.bname from boats b where b.bid = reserves.bid)))domain 제약조건
주어진 domain에 맞는 값만 입력 가능하다.
-> 사용자가 새로운 domain을 정의하여 사용 가능하다.
(check 제약조건을 이용해 domain을 더 제한한다.)
예제) ratingval 이라는 새로운 domain 정의
create domain ratingval
integer default 1
check (value >= 1 and value <= 10);- default 값으로 1을 가지고 domain의 범위를 1에서 10사이로 정했다.
domain 개념의 제한
create domain sailorId int
create domain boatId intsailorId와 boatId를 서로 다른 domain으로 취급해 비교하지 못하게 하기 위함이지만
실제로는 같은 int로 취급되어 비교 가능하다.
해결방법
create type ratingtype as intint와 구분되는 새로운 type을 선언한다.
assertion
여러 테이블에 걸친 제약조건
예제) (배 + 사람 수) < 100으로 제한
create table sailors (
...
...
check ((select count(s.sid) from sailors s) +
(select count(b.bid) from boats b) < 100)위 문장의 문제점 - boats 포함에도 불구하고 sailors 관련 제약 조건이다.
해결책 :
create assertion smallclub
check(
(select count(s.sid) from sailors s) +
(select count(b.bid) from boats b) < 100);trigger
database에 특별한 변경 (insert, update, delete)이 생길 때, DBMS에 의해 자동적으로 수행되는 procedure.
사용자는 실행여부를 모르며, side effect로 수행
trigger 집합을 가지는 DB는 Active Database
3단계로 구분한다.
-
Event - trigger를 구동시키는 DB의 변화
-
Condition - trigger가 구동되기 위한 조건
-
Action - Condition = true 일 때 수행되는 procedure
예제)
create trigger init_count
before insert on students // event
declare count int;
begin count = 0; // action
end
create trigger incr_count
after insert on students // event
when (new.age < 18) // condition
for each row
begin count = count + 1; // action
end-
row-level trigger = 수정된 tuple당 한 번 실행
(for each row 절 사용) -
statement-level trigger = tuple 수 관계없이 수정 문장당 한 번 실행
-
키워드 new = 새로 수정된 tuple 참조
예2)
create trigger set_count
after insert on students // event
referencing new table as insertedtuples
for each statement
insert into statisticsTable(ModTable, ModType, count) // action
select 'students', 'insert', count(*)
from insertedtuples i
where i.age < 18student table에 새로 insert된 tuple들의 집합에 새로운 table 이름 insertedtuples 부여
그 table로부터 age<18인 tuple 수를 count하여 statisticsTable에 삽입.
예3)
create trigger overdraft
after update on accounts
referencing new row as Nrows
for each row
when Nrows.balance < 0
begin atomic
insert into borrower
(select customerName, accountNumber
from depositor d
where Nrows.accountNumber = d.accountNumber);
insert into loan values (
Nrows.accountNumber,
Nrows.branchName,
Nrows.balance);
update accounts set balance = 0
where accounts.accountNumber = Nrows.accountNumber
end특징
trigger는 powerful mechanism을 제공한다. (DB의 상태가 바뀔때마다 catch해 실행)
여러 trigger의 효과를 이해하기 어렵다.
trigger는 DB consistency(일관성)를 유지하기 위한 것이다.
trigger 사용 의미의 극대화를 위해 IC(integrity constraint)를 적절히 활용해야 한다.
사용 예 )
- 회계 감사 및 security check 제공
- table access 및 수정에 대한 통계 수집
- integrity 유지 관리
