Kafka는 “메시지를 큐처럼 바로 삭제하는 시스템”이 아니다.
Kafka는 로그 저장 시스템(Log Store)이며, 메시지를 보존(retain)하는 전략은 데이터 구조와 비용, 성능에 직결된다.
Retention은 크게 두 가지로 나뉜다.
- 삭제 기반 Retention (Time/Size Retention)
- Compaction 기반 Retention (Log Compaction)
이 두 방식의 차이를 정확히 이해하면 토픽 설계, 로그 보존 전략, Kafka Streams(KTable/ChangeLog) 구조가 명확해진다.
1. Kafka Retention의 기본 개념
Kafka의 메시지는 Consumer가 읽었다고 해서 삭제되지 않는다.
메시지는 Retention 정책에 의해 삭제되거나 정리된다.
Retention의 목적은 다음과 같다.
- 디스크 무한 증가 방지
- 오래된 이벤트 제거
- ChangeLog(상태 변경 로그) 유지
- 장애 복구를 위해 일정 기간 데이터 유지
- 분산 시스템에서 재처리 가능하게 함
Retention은 Kafka 운영에서 가장 중요한 정책 중 하나이다.
2. Retention 시간(Time) 기반 삭제
가장 기본적인 정책이며, 다음 옵션으로 설정한다.
retention.ms예시
7일 보관
604,800,000ms → 7일
동작 방식
- Segment 단위로 삭제
- Segment의 가장 오래된 메시지 timestamp가 retention.ms를 초과하면 삭제
- 메시지를 개별 삭제하는 것이 아니라, 파일 단위로 삭제
장점
- 이해하기 쉽고 단순
- 로그 저장 비용 제어 가능
단점
- 일정 기간이 지나면 데이터 완전히 제거
- 장애 시 과거 데이터 재처리 불가능할 수 있음
Kafka Retention Policy – 로그 보존, 삭제, Compaction 완전정복
Kafka는 “메시지를 큐처럼 바로 삭제하는 시스템”이 아니다.
Kafka는 로그 저장 시스템(Log Store)이며, 메시지를 보존(retain)하는 전략은 데이터 구조와 비용, 성능에 직결된다.
Retention은 크게 두 가지로 나뉜다.
- 삭제 기반 Retention (Time/Size Retention)
- Compaction 기반 Retention (Log Compaction)
이 두 방식의 차이를 정확히 이해하면 토픽 설계, 로그 보존 전략, Kafka Streams(KTable/ChangeLog) 구조가 명확해진다.
1. Kafka Retention의 기본 개념
Kafka의 메시지는 Consumer가 읽었다고 해서 삭제되지 않는다.
메시지는 Retention 정책에 의해 삭제되거나 정리된다.
Retention의 목적은 다음과 같다.
- 디스크 무한 증가 방지
- 오래된 이벤트 제거
- ChangeLog(상태 변경 로그) 유지
- 장애 복구를 위해 일정 기간 데이터 유지
- 분산 시스템에서 재처리 가능하게 함
Retention은 Kafka 운영에서 가장 중요한 정책 중 하나이다.
2. Retention 시간(Time) 기반 삭제
가장 기본적인 정책이며, 다음 옵션으로 설정한다.
retention.ms예시
7일 보관
604,800,000ms → 7일
동작 방식
- Segment 단위로 삭제
- Segment의 가장 오래된 메시지 timestamp가 retention.ms를 초과하면 삭제
- 메시지를 개별 삭제하는 것이 아니라, 파일 단위로 삭제
장점
- 이해하기 쉽고 단순
- 로그 저장 비용 제어 가능
단점
- 일정 기간이 지나면 데이터 완전히 제거
- 장애 시 과거 데이터 재처리 불가능할 수 있음
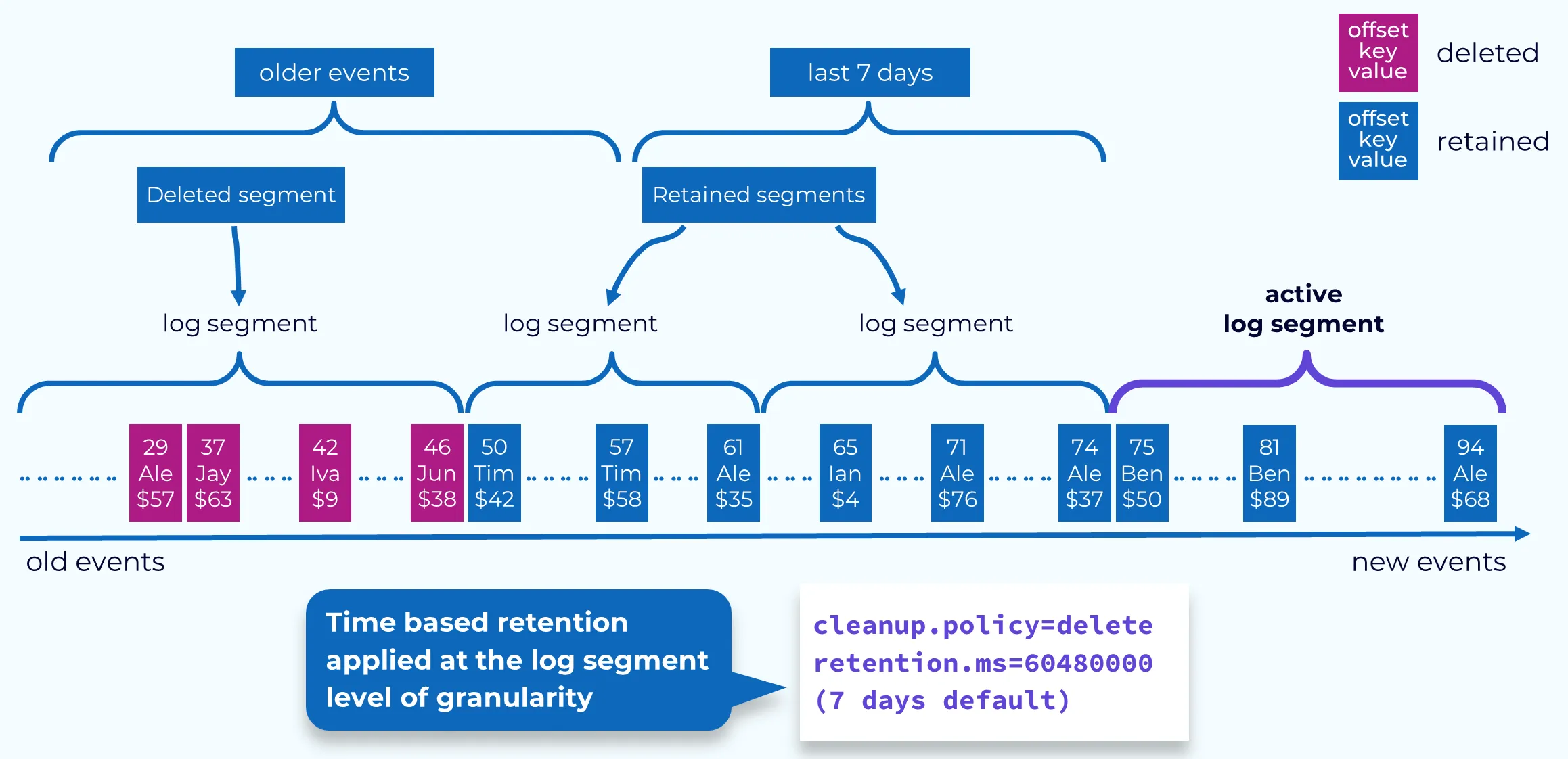
그림으로 다시보자.
- Kafka는 오래된 메시지를 하나씩 지우지 않고 Segment 파일 단위로 삭제한다.
retention.ms기간(예: 7일)을 기준으로, 그 기간을 벗어난 Segment는 통째로 삭제된다.- 그림에서 보라색(Deleted)은 retention 초과로 삭제된 Segment를, 파란색(Retained)은 보존되는 Segment를 의미한다.
- 최신 데이터가 쌓이는 구간은 active log segment로 유지된다.
- 결국 retention.ms는 “보존 기간 안의 Segment만 남기고 나머지는 제거”하는 정책임을 시각적으로 보여준다.
3. Retention 용량(Size) 기반 삭제
retention.bytes토픽 전체 용량이 지정한 크기를 초과하면 오래된 Segment부터 삭제된다.
예시
retention.bytes=100GB
→ Topic 전체가 100GB를 넘지 않도록 자동 관리
장점
- 디스크 용량 보호 확실
- 무한 데이터 스트림 처리에도 안정적
단점
- 오래된 데이터가 얼마나 빨리 없어질지 예측 어려움
대규모 실시간 로그 플랫폼(ELK ingest pipeline)은 보통 size 기반 retention을 많이 사용한다.
4. Log Compaction – 최신 상태만 유지하는 방식
Retention Delete 정책과 완전히 다른 구조다.
Compaction은 Key 기반으로 최신 값만 남기는 방식이다.
예시
orderId=123 이 여러 번 업데이트된 경우
→ Compaction 후에는 가장 최신의 메시지 한 개만 남음
Compaction은 다음 옵션으로 활성화한다.
cleanup.policy=compact
cleanup.policy=compact,delete #이것도 가능 !Compaction은 “삭제”가 아니라 “정리(clean)” 이다.
Compaction이 일어나는 과정
- Log Cleaner가 백그라운드 스레드로 동작
- 동일 Key의 오래된 메시지들을 무시
- 최신 Key-Value만 유지
- Tombstone(삭제 표시) 메시지가 있으면 나중에 제거
Compaction은 Kafka가 “Key-Value 저장소처럼 동작”하도록 만들어준다.
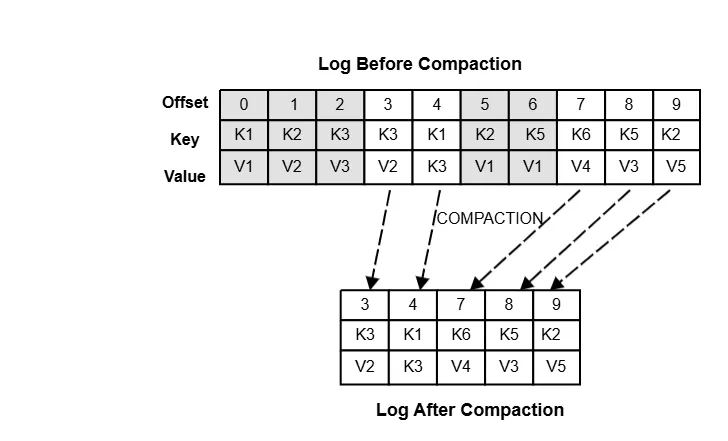
그림으로 다시보자.
- Compaction 전(Log Before Compaction)에는 동일 Key(K3, K5 등)의 여러 버전이 존재한다.
- Compaction은 각 Key의 가장 최신(offset이 가장 큰) 메시지를 선택한다.
- 오래된 메시지(K3의 V2 이전 값 등)는 무시된다.
- Compaction 후(Log After Compaction)에는 Key당 최신 레코드만 남는다.
- Kafka가 Key-Value 저장소처럼 “최신 상태”만 유지하도록 하는 구조를 시각적으로 나타낸 그림이다.
5. Delete vs Compact – 근본적인 차이
Delete 정책
- 시간/용량 기반
- Segment 단위 삭제
- 과거 로그가 사라짐
- 일반적인 이벤트 스트림에 적합 (로그/트랜잭션 추적)
Compaction 정책
- Key 최신값만 유지
- ChangeLog/상태 기반 스트림에 적합
- 데이터가 영구적으로 “정상화(normalize)” 됨
- 오래된 key는 tombstone 메시지로 제거 가능
정리 표
| 항목 | Delete | Compaction |
|---|---|---|
| 삭제 기준 | 시간/용량 | Key 최신값 기준 |
| 삭제 단위 | Segment 파일 | 메시지 단위 |
| 사용 목적 | 로그 스트림 | 상태 저장 |
| 저장 비용 | 적음 | 다소 증가 |
| 주 사용처 | 이벤트 로그 | Kafka Streams, KTable |
6. Log Cleaner 구조 (Compaction 엔진)
Compaction은 Log Cleaner라는 별도 쓰레드가 담당한다.
Log Cleaner의 목표는 딱 하나다.
“각 Key에 대해 가장 최신 메시지만 남기고 오래된 메시지는 로그에서 제거하자.”
Log Cleaner의 동작
- Dirty Segment 스캔
- Key별 최신 offset 찾기
- 새로운 Segment로 복사 (compact)
- 불필요한 데이터 제거
- cleanup 후 새로운 파일로 교체
Log Cleaner는 CPU와 Disk IO를 소모하므로 대규모 compact topic에서는 브로커 리소스 사용량이 증가할 수 있다.
성능 팁
- heap 크기 안정적으로 유지
- cleaner.threads 수 조절
- 고성능 디스크 권장
7. KTable, ChangeLog와 Compaction의 관계
Kafka Streams에서 KTable은 “Key-Value 상태 저장소”이다.
KTable의 모든 상태 변경은 Compaction이 적용되는 ChangeLog Topic에 저장된다.
예시
userId=10 name=kim
userId=10 name=park (업데이트)
userId=10 name=lee (업데이트)Compaction 후
userId=10 name=lee즉, KTable은 사실상 Compacted Topic을 기반으로 동작하며, Kafka는 이를 통해 지속적이고 정확한 상태 저장 구조를 제공한다.
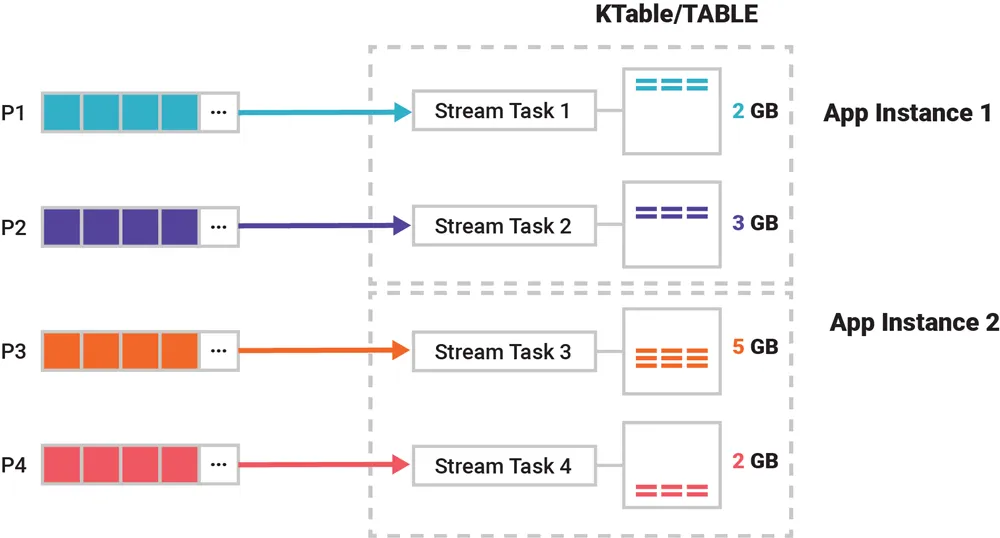
그림으로 다시보자.
- KTable 입력 토픽의 각 파티션(P1~P4)은 각각 다른 Stream Task로 매핑된다.
- 각 Stream Task는 해당 파티션의 데이터를 처리하고 자체 State Store(로컬 저장소)에 상태를 유지한다.
- 그림의 2GB, 3GB, 5GB 등은 파티션별 로컬 상태 크기를 의미한다.
- App Instance가 여러 개 존재하면 파티션은 인스턴스 간에 분산된다.
- 이 구조 덕분에 KTable은 분산 Key-Value 저장소처럼 동작하며, 각 Task가 ChangeLog Topic을 기반으로 상태를 유지한다.
8. 토픽 설계 시 Retention 전략
Retention은 “데이터 처리 철학”과 직결된다.
1) 단순 이벤트 스트림 (로그, 분석)
- cleanup.policy=delete
- retention.ms = 요구 보존기간
- retention.bytes = 한계 디스크
2) 재처리가 필요한 분석/머신러닝
- retention.ms 매우 길게 설정 (예: 14~30일 이상)
- 또는 S3 Connect sink로 영구 보관
3) 상태 저장 (KTable, DB CDC, Customer State)
- cleanup.policy=compact
- segment.bytes는 작게(빠른 compaction)
- min.cleanable.dirty.ratio 설정 중요
4) 결제/주문/금융 이벤트(감사로그)
- 삭제 정책 매우 조심
- 반드시 acks=all + replication >= 3
- retention.ms 길게 유지하거나 external storage backup 필수
5) ELK 연동 로그 수집
- retention.bytes 중심으로 관리
- 3~7일 rolling이 일반적
9. 정리
Kafka의 Retention은 단순한 삭제 정책이 아니라
데이터 철학, 비용, 시스템 신뢰성, 재처리 전략을 결정하는 핵심 구조이다.
핵심 요약
- Delete retention: Segment 단위 삭제 (시간/용량 기반)
- Compaction: Key 최신값만 유지하는 log cleaner 구조
- Delete/Compact는 목적이 완전히 다름
- KTable/ChangeLog는 compaction 기반
- 토픽 설계 시 retention 전략을 반드시 사용 목적에 맞게 설정해야 함
Retention 정책을 이해하면 Kafka의 저장 구조와 데이터 흐름을 훨씬 사용자 중심적으로 설계할 수 있다.
참고문헌
https://developer.confluent.io/courses/architecture/compaction/
https://cloudoses.com/log-compaction-cleanup-policy/
https://www.confluent.io/blog/kafka-streams-tables-part-3-event-processing-fundamentals/
