데이터가 폭발적으로 증가하면서, “나중에 분석하는 Batch 중심 구조”만으로는 서비스 운영과 장애 대응이 불가능해졌다.
결제 실패율이 갑자기 오르는지, 로그인 오류가 특정 지역에서 집중되는지, 서버 응답시간이 급격히 증가하는지와 같은 문제는 발생하고 10분 뒤에 알면 이미 늦었다.
이 문제를 해결하기 위해 등장한 개념이 바로 Stream Processing이다.
Kafka, Flink, Spark Streaming 같은 기술들이 “들어오자마자 바로 처리하는 구조”를 가능하게 만들었다.
이 글에서는 Stream Processing이 무엇인지, Batch와 어떤 점이 다른지, 왜 지금의 서비스 환경에 필수적인지 개념적으로 정리한다.
1. Batch Processing vs Stream Processing
두 방식의 차이를 명확히 이해해야 Stream Processing의 필요성이 보인다.
Batch Processing
- 일정 시간 동안 데이터를 모은 뒤 한 번에 많은 양을 처리하는 방식
- Hadoop MapReduce, Spark Core가 대표적
장점
- 대규모 데이터 처리에 효율적
- 정확성을 확보하기 좋음
- 비용이 적게 듦(EC2 spot 사용, 야간 처리 등)
단점
- 지연 시간(latency)이 크다
- 실시간 장애 감지 불가
- 데이터가 쌓여야 의미 있는 결과가 나옴
Stream Processing
- 데이터가 들어오는 즉시 처리
- 이벤트 중심(event-driven) 아키텍처
- Kafka Streams, Flink, Spark Structured Streaming 등
장점
- 실시간 분석
- 빠른 의사 결정
- 운영 모니터링에 최적
- 이벤트 단위 처리 가능
단점
- 아키텍처 복잡도 증가
- 상태 관리(State store)가 어려움
- 정확도 보장 로직 필요(Exactly-once)
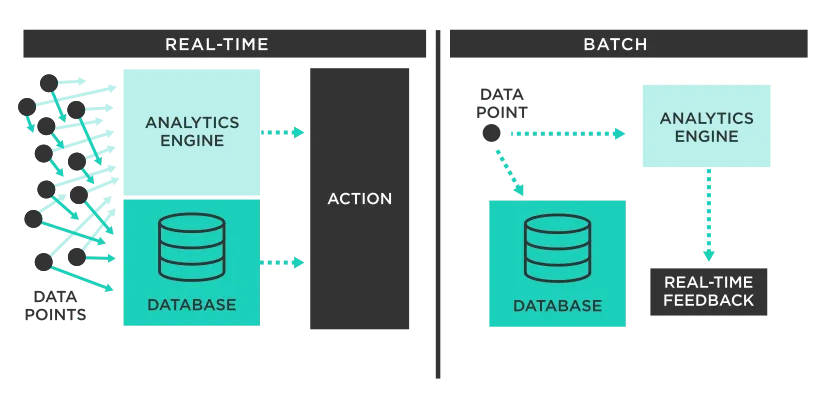
그림으로 다시보자.
- 좌측 Real-Time은 데이터가 들어오자마자 Analytics Engine이 즉시 처리하고 Action으로 이어진다.
- Database도 실시간으로 업데이트되며 초 단위 의사결정이 가능하다.
- 우측 Batch는 데이터가 먼저 DB에 쌓인 뒤 일정 주기마다 Analytics Engine이 묶음으로 처리한다.
- 분석 결과는 실시간이 아니라 사후적으로 제공된다.
- 즉, 실시간은 즉각 반응 중심, 배치는 쌓아두고 요약 분석 중심 구조이다.
2. Real-time vs Near Real-time
많은 사람들이 “실시간 = 0초”라고 오해한다.
하지만 기술적으로 완전한 Real-time은 거의 없다.
Real-time
- 1~100ms 수준
- 보통 금융 결제, IoT 장비 제어 등 초저지연 시스템
Near Real-time
- 0.5초~수 초 단위 지연
- Kafka 기반 스트리밍 시스템이 여기에 속함
현실적으로 Web 서비스, 로그 분석, 장애 감지 같은 분야에서는 Near Real-time이면 충분히 실시간으로 인식된다.
예)
APM 모니터링에서 2초 동안 오류율이 폭증 → 즉시 Slack 알림 전송
이 정도 속도면 운영 측면에서 실시간 대응이 가능하다.
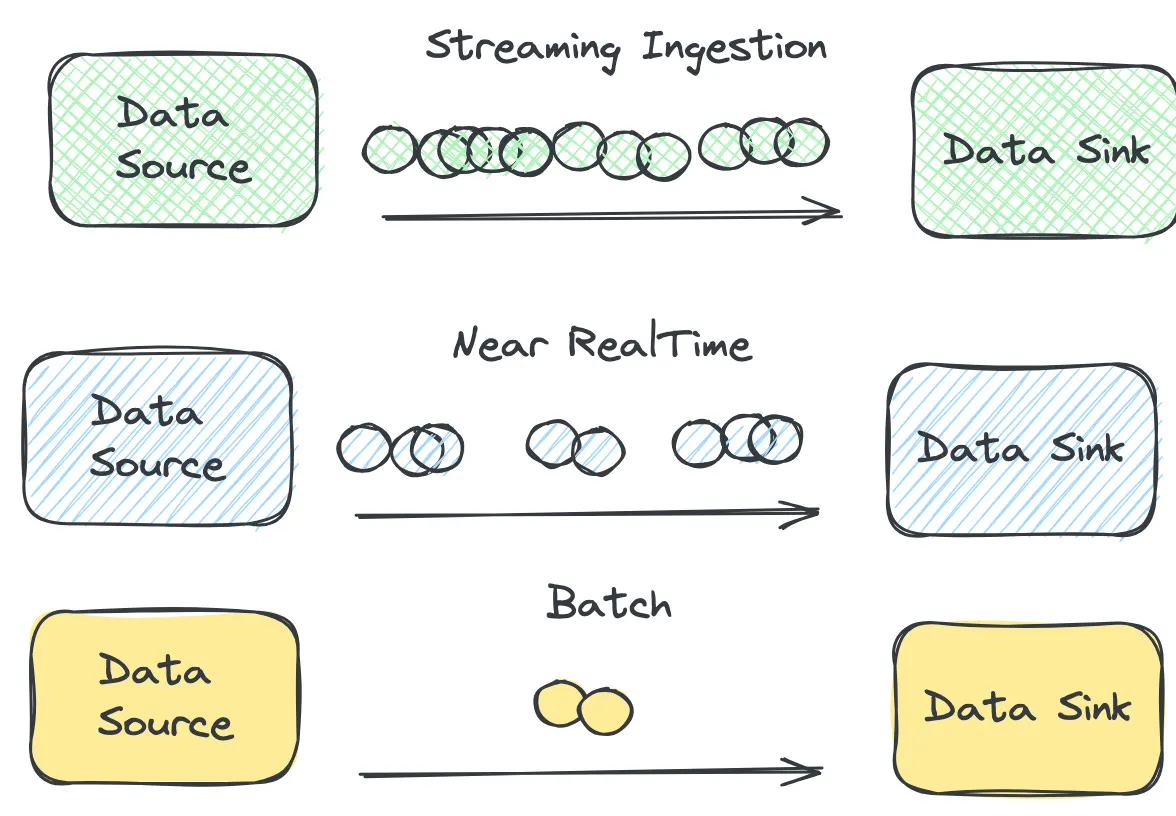
그림으로 다시보자.
- Streaming은 이벤트가 들어오는 즉시 하나씩 연속적으로 전달된다.
- Near Real-time은 작은 묶음(batch micro)이 생긴 뒤 짧은 지연 후 전달된다.
- Batch는 데이터를 오래 모았다가 한 번에 큰 덩어리로 전달하는 방식이다.
3. Kafka Consumer vs Stream Processor
Kafka Consumer를 스트림 엔진이라고 생각하면 안 된다.
일반 Kafka Consumer
동작 방식
- 메시지 poll
- 비즈니스 로직 처리
- offset commit
문제점
- 상태(State)를 유지하기 어려움
- 윈도우 계산 불가(“5분 동안 오류 수” 같은 집계)
- 메시지 재처리(reprocessing) 구조 약함
- Exactly-once 보장 어렵다
- 고도화된 join/aggregation 불가
즉, 단순 소비자로는 실시간 데이터 처리 시스템을 형성하기 어렵다.
Stream Processor (Kafka Streams, Flink, Spark Streaming)
- State store 내장
- Windowed aggregation
- Event-time 기반 처리
- Exactly-once 제공
- Repartition / Shuffle / Join 지원
- 장애 발생 시 자동 재처리 가능
즉, Stream Processor는 단순 Consumer가 아니라 실시간 분산 처리 엔진이다.
4. Event Time vs Processing Time
스트림 처리에서 가장 중요한 개념이다.
Processing Time
이벤트를 “받은 시각”을 기준으로 처리
- Kafka로 도착한 시간
- Consumer가 읽은 시간
- 시스템 time 사용
문제점
하지만 ? 현실 세계에서 이벤트는 절대 순서대로 오지않는다.. 그렇다면 ?
네트워크 지연, 시스템 장애가 발생하면 이벤트 도착 순서가 뒤틀려 잘못된 집계를 하게 된다.
Event Time
데이터가 “실제로 발생한 시각”을 기준으로 처리
- 로그에 기록된 timestamp
- 기기에서 발생한 실제 시간
예시
12:00에 발생한 오류 로그가 네트워크 지연으로 12:03에 Kafka로 들어옴
Processing Time → 12:03에 오류 증가로 판단해서 잘못 분석됨
Event Time → 12:00의 오류로 정확히 반영됨
고도화된 스트림 시스템은 대부분 Event Time 기반이다.
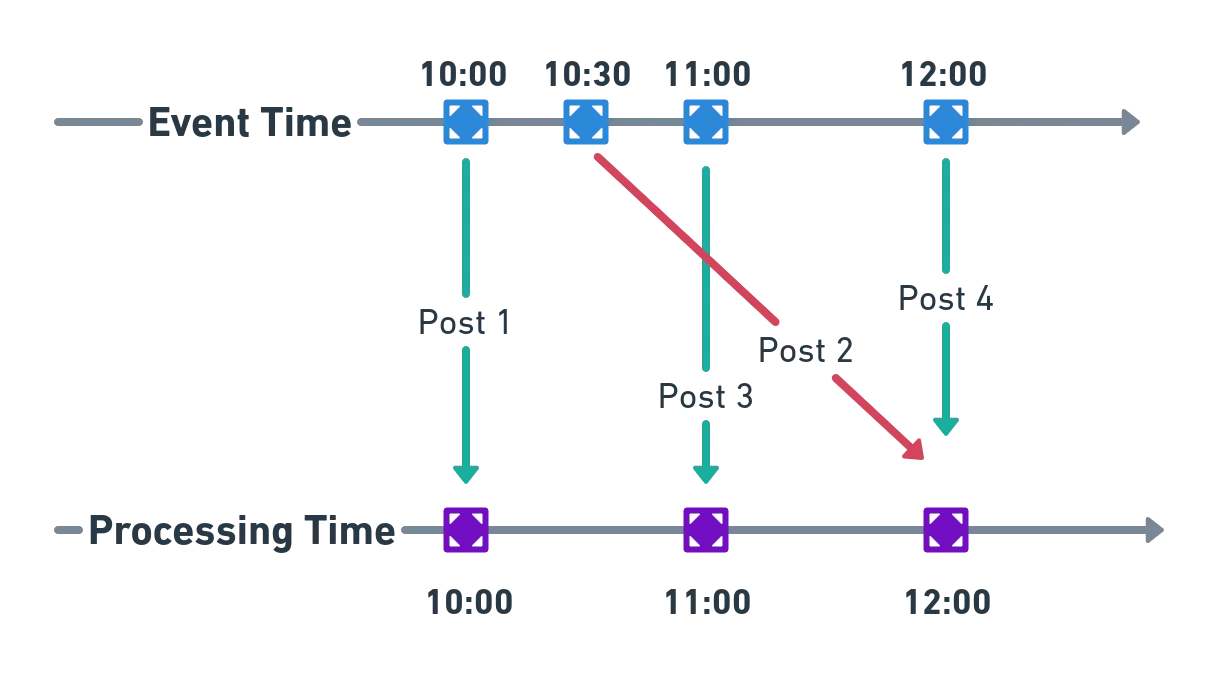
그림으로 다시보자.
- 위쪽 파란 점들은 이벤트가 실제로 발생한 시간(Event Time)을 의미한다.
- 아래쪽 보라색 점들은 이벤트가 시스템에 도착해 처리된 시간(Processing Time)이다.
- Post 2처럼 늦게 도착하는 데이터는 Event Time과 Processing Time이 크게 어긋난다.
- Processing Time만 쓰면 늦게 도착한 이벤트가 잘못된 구간에 들어가 집계가 뒤틀린다.
- Event Time을 사용해야 실제 발생 순서대로 정확한 스트림 분석을 할 수 있다.
5. 메시지 단위 처리 vs 윈도우(Window) 처리
실시간 처리라고 해서 항상 이벤트 하나하나만 처리하는 것은 아니다.
메시지 단위 처리
- 단순 이벤트 처리
- 결제 이벤트 1건
- 로그인 성공/실패 1건
- Audit 로그 1건
이 방식은 직접 처리하는데 윈도우가 필요 없다.
윈도우 기반 처리
대부분의 실시간 분석은 집계(aggregation) 가 필요하다.
예를 들어 다음과 같은 정보는 윈도우 기반으로만 얻을 수 있다.
- 최근 1분간 오류율
- 최근 5분 동안 평균 응답 시간
- 최근 10초 동안 특정 URI에서 실패율 급증
- IP별 30초 동안 로그인 실패 횟수(보안 탐지)
Stream Processing 엔진의 핵심 역할이 바로
시간 단위로 데이터를 모아 의미 있는 지표로 만드는 것이다.
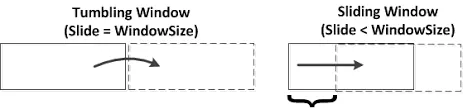
그림으로 다시보자.
- Tumbling Window는 구간이 겹치지 않고 고정된 크기만큼 “뚝뚝” 잘라서 집계한다.
- Sliding Window는 구간이 서로 겹치며 더 짧은 간격으로 계속 이동하면서 집계를 반복한다.
- 즉, Tumbling은 비연속적 집계, Sliding은 더 촘촘한 연속 집계 방식이다.
6. Stream Processing이 왜 필요한가? (핵심 설득 포인트)
장애 감지 속도
APM이나 운영 모니터링에서 “5~10분 뒤 대시보드에 올라오는 정보”는 사실상 무의미하다.
예:
- 로그인 오류가 3분 동안 폭증 → 이미 콜센터 난리
- 결제 실패율 증가 → 이미 매출 손실 발생
- 502가 특정 API에서 급증 → 고객 불편 이미 발생
Stream Processing은 이런 문제를 들어오자마자 즉시 감지한다.
보안 이상징후 탐지
- 특정 IP에서 10초 동안 로그인 실패 20회
- 의심스러운 OTP 요청 빈도
- 세션 탈취 패턴
이런 이벤트는 Batch로 처리하면 보안 사고가 이미 발생한 후다.
실시간 개인화
- 사용자가 앱을 사용하는 흐름을 따라가며 실시간 추천
- 최근 본 상품 기반으로 즉시 추천 API 제공
- 실시간 클릭스트림 분석
서비스 운영 자동화
Stream Processing은
“문제 감지 → 자동 조치” 흐름을 만든다.
예시
로그 분석 → 오류율 급증 → 자동 슬랙 알림
CPU 85% 초과 10초 지속 → 자동 스케일 아웃
특정 지역 장애 감지 → 트래픽 우회
비용 절감
Batch 기반 Spark 클러스터처럼 거대한 연산 자원을 상시 띄워둘 필요가 없다.
Kafka Streams/Flink는 필요할 때만 scale-out
7. 로그 → Kafka → Stream Processor (전체 데이터 흐름)
이 흐름을 이해하면 Stream Processing의 구조가 확실히 잡힌다.
- 웹서버/애플리케이션 로그 생성
- 로그 수집 에이전트(Filebeat, FluentD 등)가 Kafka로 전송
- Kafka는 로그를 분산 파티션에 저장
- Stream Processor는 Kafka의 topic을 실시간으로 구독
- 이벤트를 윈도우 단위로 집계
- 오류율 상승, 지연 시간 증가 등 이상징후 탐지
- 알림 시스템(Slack, PagerDuty 등)으로 통보
- 관리자 또는 자동화된 조치가 대응
이 전체가 1~2초 안에 끝난다.
8. 마무리
1편에서는 Stream Processing의 철학과 구조를 다뤘다.
왜 필요한지, 어떤 문제를 해결하는지,
Kafka Consumer와 어떤 점이 다른지 전체 그림을 잡는 데 초점을 맞췄다.
참고 문헌
https://estuary.dev/blog/batch-processing-vs-stream-processing/
https://dataengineeringcentral.substack.com/p/batch-vs-near-realtime-vs-streaming
https://otee.dev/2021/10/19/event-and-processing-time-semantics.html
https://sunrise-min.tistory.com/entry/Tumbling-window%EC%99%80-Sliding-window
