실시간 스트림 분석의 진정한 핵심은 바로 Windowing + Aggregation이다.
Stream Processing의 난이도는 대부분 “시간 기반 계산”에서 나온다.
예를 들어 아래 같은 정보는 모두 윈도우 계산 없이는 불가능하다.
- 최근 1분간 오류율
- 최근 10초 동안 평균 응답 시간
- 최근 5분간 로그인 실패 증가 추세
- IP별 30초 로그인 실패 횟수
- P95, P99 반응 시간 지표
이 글에서는 Stream Processing의 꽃이라 불리는 Tumbling / Sliding / Session Window, 그리고 Event time, Watermark, Out-of-order 처리까지 실무에서 반드시 알아야 하는 개념만 집중적으로 정리한다.
1. Window 종류: Tumbling / Sliding / Session
스트림 윈도우는 “시간을 잘라서 처리하는 기법”이다.
Batch는 모아서 처리하지만, Stream은 들어오자마자 처리하므로 기간을 정의해야 계산이 가능하다.
스트림 엔진은 아래 세가지를 기본적으로 제공한다.
1) Tumbling Window
- 겹치지 않는 고정 크기(window-size)의 윈도우
- 예: 1분 단위 정확한 집계
- 00:00~00:01 / 00:01~00:02 이런 식으로 딱딱 끊김
내부 동작
- 이벤트는 event-time 또는 processing-time 기반으로 특정 구간에 매핑됨
- 윈도우 끝나는 시점에 집계 결과를 emit
- Late Event는 allowed lateness 정책에 따라 처리되거나 버려짐
장점
- 구현 간단
- 정확한 시간 단위 집계(1분 단위 오류율 등)에 적합
단점
- 구간이 고정이라 실시간 감지에는 반응성이 떨어짐
사용 예
- 1분 오류율 보고
- 10초 평균 응답 시간 계산
- TTL 처리 용이
실제 예시
00:00~00:10 동안 1400개의 요청 → throughput = 140 req/sec
2) Sliding Window
- 일정 간격(step)으로 움직이는 윈도우
- 겹치는 부분 존재
- 예: window-size=1분, slide=5초
즉, 매 5초마다 최근 1분 데이터를 계산하는 구조
왜 중요한가?
장애 감지는 대부분 “Sliding Window 기반”이다.
내부 동작
예: window=60초, slide=5초
- 00:00~01:00
- 00:05~01:05
- 00:10~01:10 … 이런 식으로 계속 마지막 1분 데이터를 재계산한다.
Stream Processor는 각 윈도우마다
- 부분 집계(state)를 유지하고
- slide가 발생할 때마다 결과물만 계산해 emit한다.
예시
30초 응답 오류율이 10% 이상 증가하면 알림
→ 이건 Tumbling Window로는 실시간성이 부족하다.
사용 예
- 실시간 장애 감지
- 실시간 지연율 증가 탐지
- 5초 단위 rolling average
3) Session Window
- Tumbling/Sliding은 시간중심, Session Window는 사용자 행동 중심
- 사용자/세션의 비활동 시간(gap)을 기준으로 window가 결정됨
- 예: 30초 동안 새로운 이벤트가 없으면 session 종료
내부 동작
- 동일 Key(userId)의 이벤트들이 들어오면 세션을 열고 이벤트를 추가
- 이벤트가 일정 시간(gap) 동안 없으면 윈도우 종료
- 세션 별로 전체 행동 집계(클릭 수, 체류 시간, 평균 등)를 출력
- Late Event는 해당 세션이 이미 닫혔는지에 따라 처리 여부 결정
사용 예
- 사용자 활동 패턴 분석
- 로그인 후 행동 분석
- 장바구니 세션 분석
예시
사용자가 10초, 5초 간격으로 이벤트를 발생시키다가 마지막 이벤트 이후 40초 동안 아무 입력이 없으면 그 40초 구간을 포함하는 세션 윈도우가 끝남
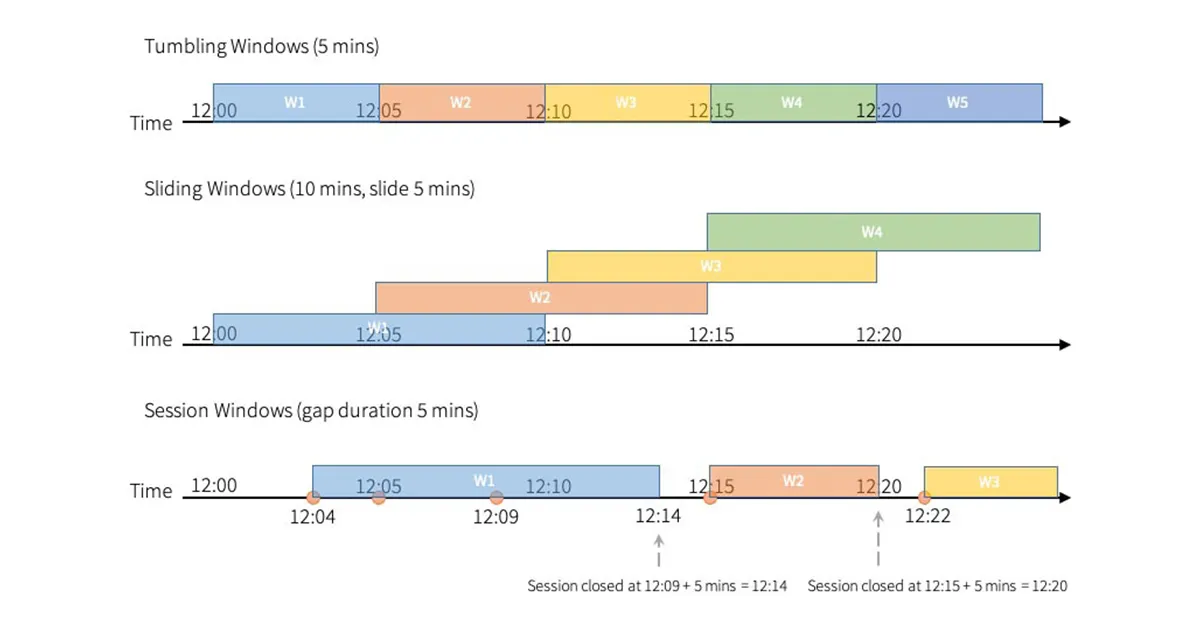
그림으로 다시보자.
- Tumbling Window는 5분 단위로 구간이 딱딱 끊어져 서로 겹치지 않는 방식이다.
- Sliding Window는 크기는 10분이지만 5분마다 이동하며 겹치는 구간을 계속 계산한다.
- 그래서 Sliding은 더 촘촘하게 “최근 데이터”를 분석할 수 있다.
- Session Window는 시간 기반이 아니라 이벤트 사이의 간격(gap 5분)으로 윈도우가 자동으로 닫힌다.
- 즉, Tumbling은 고정·비중첩, Sliding은 고정·중첩, Session은 동적 윈도우 구조를 시각적으로 잘 보여주는 그림이다.
2. Event Time vs Processing Time
Stream Processing 시스템(Flink, Kafka Streams, Spark Streaming)은 “시간”을 기준으로 집계, 윈도우, 트리거, watermark 등을 처리한다.
Stream Processing에서 시간이 무엇인지를 명확히 정의해야 한다.
그 모델이 바로
Event Time (이벤트 발생 시간)
Processing Time (처리 시간)
이다.
Processing Time
스트림 엔진이 이벤트를 읽는 순간의 시간
- Consumer가 “지금 시계” 기준으로 처리하는 시간
- 시스템 처리 속도에 따라 변동 가능
- 지연, 네트워크 장애에 취약
예시
12:00에 처리하고 싶었는데 네트워크 지연 때문에 12:04에 도착
→ Processing Time 12:04로 집계됨
→ 오류율 왜곡 가능
Event Time
데이터 내부에 기록된 timestamp를 기준으로 스트림을 처리하는 시간 모델
- 이벤트가 “실제로 발생한 시간(timestamp)”
- 로그 자체에 들어 있는 timestamp 기준
- 스트림 분석에서 거의 표준 방식
장점
- 지연, 재전송, 네트워크 문제와 무관하게 정확한 집계 가능
왜 Event Time이 중요한가?
실시간 장애 분석에서 정확한 타이밍은 필수다.
예시
실제 오류는 12:00~12:01에 폭증했는데 로그는 12:03~12:04에 들어왔다고 가정하자.
Processing Time 기준 → 12:03에 장애로 판단 (틀림)
Event Time 기준 → 12:00에 장애로 판단 (정확)
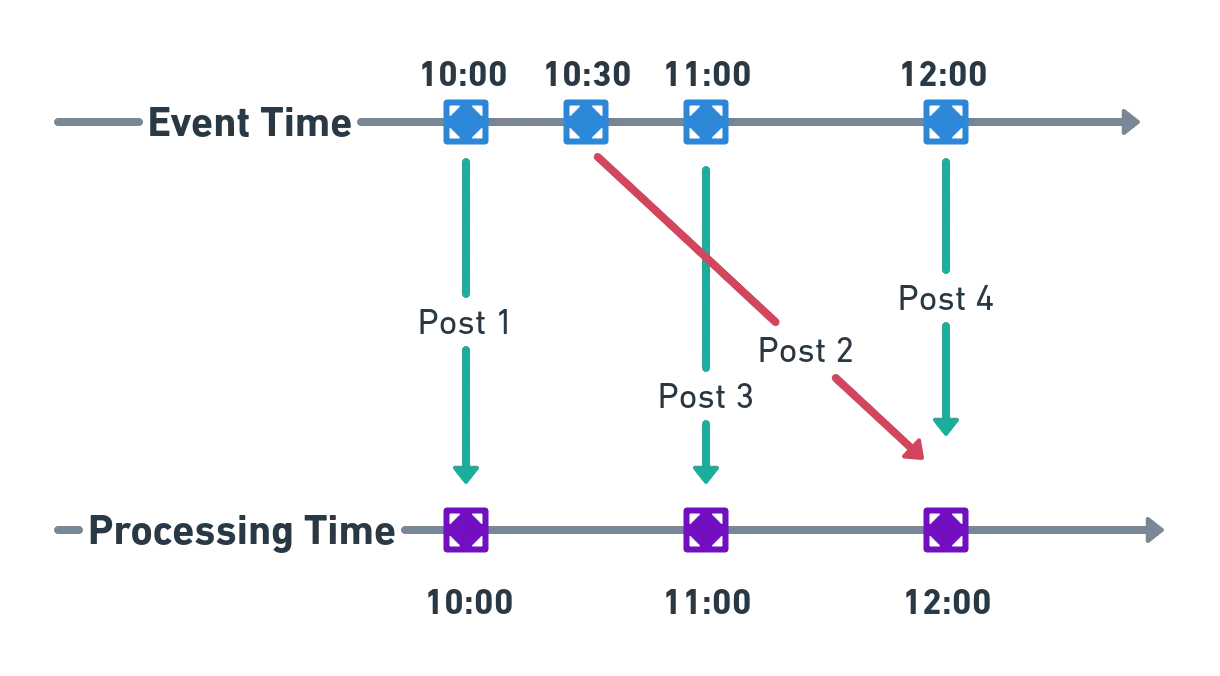
그림으로 다시보자.
- 위쪽 축은 이벤트가 실제로 발생한 시간(Event Time) 을 나타낸다.
- 아래쪽 축은 시스템이 이벤트를 처리한 시간(Processing Time) 을 나타낸다.
- Post 2처럼 늦게 도착한 이벤트는 Event Time 순서와 다르게 처리된다.
- 이런 Out-of-order 상황 때문에 Processing Time만 쓰면 분석 결과가 왜곡된다.
- Stream Processing에서 Event Time + Watermark가 필요한 이유를 잘 설명하는 그림이다.
3. Watermark 개념 (Out-of-order 해결 핵심)
Event Time을 쓰려면 반드시 Watermark를 이해해야 한다.
Event Time 기반 스트리밍을 쓰려면 현실에서 항상 “늦게오는 데이터(Out of order)” 문제와 싸워야한다.
Watermark는 이를 해결하는 핵심 기법이다.
Out-of-order 문제란?
네트워크/시스템 지연 때문에 이벤트가 늦게 도착하거나 순서가 뒤죽박죽으로 들어오는 현상
예시
이 순서로 발생했지만 t=1 → t=3 → t=2 순으로 Kafka에 들어올 수도 있다.
Watermark란?
“이 시점 시간 이전의 이벤트는 더 이상 도착하지 않을 것”이라는 기준선
즉 스트림 시스템이 내부적으로 유지하는 하나의 시간 기준선이다.
Watermark가 12:00:30이라면
→ 12:00:30 이전의 이벤트는 늦게 와도 버리거나 처리 방식을 바꾼다.
Watermark는 다음 문제 해결을 위한 장치다.
- Out-of-order 이벤트 처리
- 윈도우 종료 시점 결정
- 집계 완료 여부 판단
그럼 Watermark는 왜 필요한가 ?
Event Time 윈도우는 “발생 시간 기준”으로 계산된다.
그러나 이벤트가 늦게 들어오면 계산을 언제 끝내야 할지 모르기 때문에 watermark가 없는 Event Time 윈도우는 영원히 닫히지 않는다.
Watermark 설정 전략
보통
watermark = max_event_time - allowed_lateallowed_late를 크게 잡으면
→ 정확도 ↑
→ 지연도 ↑
allowed_late를 작게 잡으면
→ 빠른 처리
→ 늦게 온 이벤트 처리 불가(정확도 ↓)
실시간 알림 시스템에서는 보통 1~5초 BI/배치 성격 스트리밍에서는 10~60초까지도 사용한다.
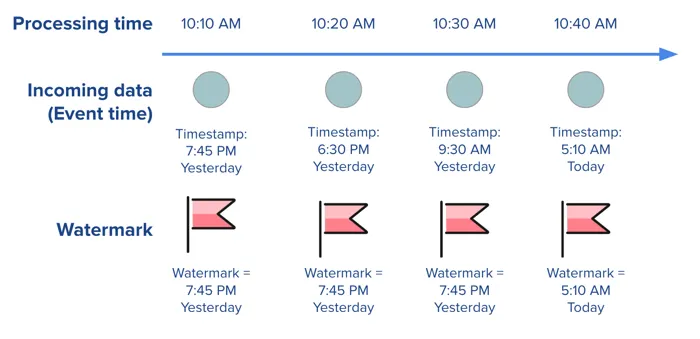
그림으로 다시보자.
- 위쪽은 Processing Time(실제로 이벤트가 도착한 시간 흐름)이다.
- 가운데는 각 이벤트의 Event Time(실제로 발생한 시각)이다.
- 처음 세 개 이벤트는 모두 Watermark보다 과거 시간이라 Watermark가 변하지 않는다.
- Watermark는 “이 시점 이전 이벤트는 더 이상 도착하지 않을 것”이라는 기준선이다.
- 최신 Event Time(오늘 5:10 AM)이 들어오면 Watermark가 그 시점으로 이동한다.
- Watermark가 이동하면 이후 도착하는 오래된 이벤트는 늦게 온(out-of-order) 이벤트로 처리된다.
4. Rolling Aggregation (계속 굴러가는 집계)
Sliding Window와 함께 가장 많이 사용되는 방식이다.
Rolling Aggregation은 "이전 값이 다음 계산에 계속 누적되는 형태"다.
즉, 일정 시간 범위를 계속 유지하되, 새로운 이벤트가 들어올 때마다 집계 결과를 즉시 갱신하는 방식
예시
최근 1분 평균 값이 매 5초마다 다시 계산됨
즉, “움직이는 평균(moving average)”과 동일하다.
대표 계산들
- rolling average
- rolling count
- rolling sum
- rolling max/min
- 최근 1분 오류율 (매 3초 계산)
- 최근 30초 평균 지연 시간
이 방식은 실시간 장애 감지에서 거의 필수다.
5. P95, P99 계산 방법
실시간 성능 모니터링에서 가장 중요한 지표가 바로 P95, P99 지연 시간이다.
Percentile 계산 방식
P95 = 전체 요청 중 95%가 이 값 이하에 처리됨
P99 = 전체 요청 중 99%가 이 값 이하에 처리됨
예시
- 윈도우 데이터 100개 → P95 = 95번째 윈도우 데이터
- 윈도우 데이터 100개 → P99 = 99번째 윈도우 데이터
즉,
P95 = “상위 5% 느린 요청을 제외한 응답시간”
P99 = “가장 느린 상위 1% 응답시간”
이 지표는 평균보다 훨씬 정확하게 병목을 보여준다.
스트림 환경에서 Percentile 계산 방법
전체 데이터를 메모리에 쌓을 수 없으므로 다음 기법을 사용한다.
- 윈도우 내부에서 응답 시간 정렬 후 Percentile 계산
- 작은 윈도우(5초, 10초 등)에 적합
- t-digest 알고리즘 사용
- 대량 데이터에서 효율적
- Spark/Flink 대부분 지원
- Kafka Streams는 custom 구현 가능
- Histogram 기반 버킷팅
- 응답 시간 범위를 구간(0~50ms, 50~100ms...)으로 나누고
- 각 버킷 count를 기반으로 percentile 계산
이 방식으로 P95/P99를 실시간 업데이트할 수 있다.
6. 에러율, 지연율 계산 논리
장애 감지는 대부분 “최근 일정 구간에서의 비율 변화”로 판단한다.
1) 오류율(Error Rate)
최근 30초 Sliding Window 기준
error_rate = error_count / total_count실제로는 더 정교하게 계산한다.
예시
최근 30초 오류율이
- 이전 5분 평균 대비 3배 증가 → 알림
- 절대 기준 5% 이상이면 → 알림
이런 규칙 기반 경보(rule-based alert)가 가장 널리 쓰인다.
2) 지연율(Latency Rate)
지연율 = 특정 기준 응답 시간 이상 비율
예: 500ms 이상 비율
latency_rate = slow_count(> 500ms) / total_count또는
- P95 > 400ms
- P99 > 700ms 둘 중 하나라도 초과하면 장애 경보
7. TTL, 상태 저장(State Store)
윈도우 연산에는 상태(state)가 필요하다.
왜 ?
- 스트림은 계속 흐르는 데이터다..
- Kafka 같은 스트림은 무한대 데이터가 계속 들어온다.
- 윈도우 연산인 이런 무한 스트림에서 일부 구간만 잘라서 계산하는 연산인데..
- 윈도우에 속하는 데이터를 저장해두는 공간(상태)가 필요하다
Kafka Streams는 RocksDB 기반 State Store를 사용한다.
State Store가 필요한 이유
- 윈도우별 카운트 저장
- 이전 집계 값 유지
- 세션 윈도우 상태 유지
- P95/P99 계산 시 히스토그램 유지
Without State Store → 실시간 Aggregation은 불가능하다.
TTL(Time-To-Live)
State Store에는 TTL이 필요하다.
왜?
- 윈도우가 끝난 뒤 데이터를 무한정 보유하면 메모리 폭발
- 오래된 상태는 필요 없음
예시
1분 윈도우면 TTL = 1분 + allowed-late(5초) 정도가 적당하다.
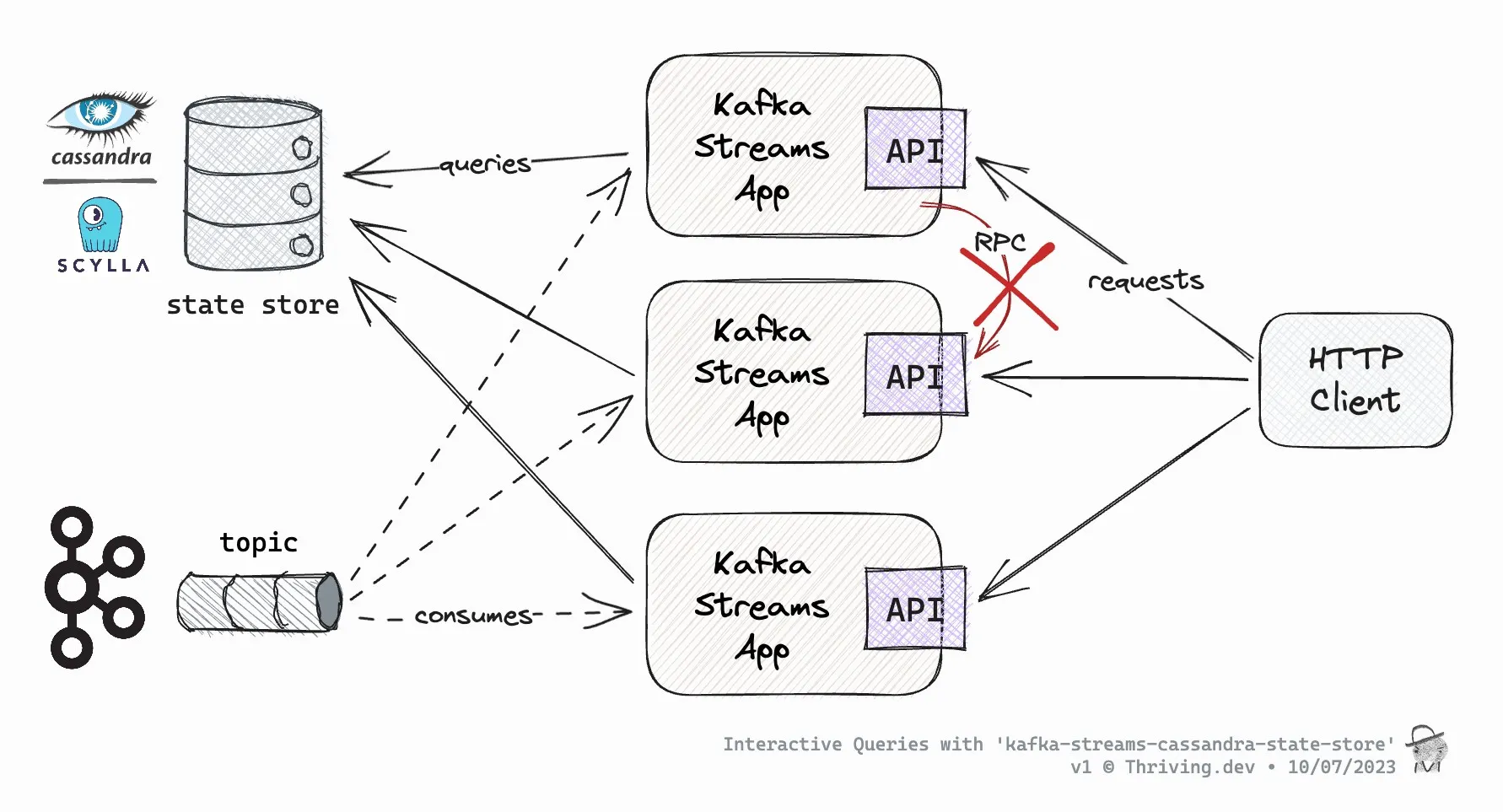
그림으로 다시보자.
- Kafka Streams 앱들은 Kafka Topic에서 데이터를 소비하며 각자 로컬 State Store를 유지한다.
- State Store는 RocksDB 대신 Cassandra/Scylla 같은 외부 저장소로 확장 가능하다.
- HTTP 클라이언트는 특정 Kafka Streams 인스턴스로 직접 RPC를 보내지 않고,
- 각 Streams 앱이 로컬 또는 외부 State Store에 직접 질의해 결과를 반환한다.
- 인스턴스 간 RPC를 피함으로써 분산 시스템의 복잡성을 줄인다.
- 이 구조 덕분에 Streams 애플리케이션이 스케일아웃되면서도 상태 일관성을 유지하고 빠르게 응답할 수 있다.
8. Out-of-order 문제 해결
실시간 로그는 절대 순서대로 들어오지 않는다.
네트워크 지연, retry, 로그 수집기 문제 등 다양한 이유가 있다.
이를 해결하려면 3가지가 필요하다.
1) Event Time 기반 처리
순서가 맞지 않아도 “실제 발생 시간(timestamp)”으로 정렬 가능
2) Watermark 사용
“이 시점 이전은 더 이상 신규 이벤트 없다”고 선언하여 윈도우 종료 시점을 명확히 한다.
3) Late event 처리 정책
늦게 도착한 이벤트를 어떻게 처리할지 결정해야 한다.
정책 예시
- drop: 버리고 집계에 포함하지 않음
- update: 이미 끝난 윈도우 값을 수정
- side-output: 별도 토픽으로 늦게 도착한 데이터 전송
- log only: 장애 원인 추적용 로그만 남김
실무에서는 정확성이 중요한 BI 쪽은 update 사용 / 실시간 알림 시스템은 drop 많이 사용한다.
마무리
Windowing + Aggregation은 실시간 스트림 분석의 완성이다.
장애 감지, 성능 모니터링, 지연/오류율 분석, 보안 탐지 등 대부분의 실시간 시스템이 Sliding Window와 Aggregation 기반으로 동작한다.
이번 편에서 다룬 주요 개념
- Tumbling / Sliding / Session Window
- Event Time과 Processing Time
- Watermark와 Late Event 처리
- Rolling Aggregation
- P95/P99 계산 방식
- 오류율/지연율 계산
- State Store & TTL
- Out-of-order 처리 전략
이 내용을 이해하면 Kafka Streams나 Flink에서 실제 장애 감지 로직을 구현할 수 있는 수준 정도가 될거라고 생각한다..
참고 문헌
https://otee.dev/2021/10/19/event-and-processing-time-semantics.html
https://www.gcpstudyhub.com/pages/blog/dataflow-watermarks-and-triggers
https://thriving.dev/blog/interactive-queries-with-kafka-streams-cassandra-state-store
