Kafka는 단순 메시지 큐가 아니라 “분산 스트리밍 플랫폼”이다.
Stream Processing을 구현할 때 Kafka를 중심으로 설계하는 이유는 내부 구조가 실시간 처리에 최적화되어 있기 때문이다.
이번 편에서는 Kafka 기반 스트림 처리의 근간이 되는 Topic, Partition, Group, Exactly-once 등 필수 개념을 조금 더 깊이 설명한다.
이러한 대부분은 내 벨로그의 Kafka를 공부하면서 다뤘던 내용들이다.
Stream Processing을 더 깊게 학습하기위해 이번 편에서 복습하는 느낌으로 해보려한다.
1. Kafka Topic 모델
Kafka Topic은 단순 메시지 큐가 아니라 append-only 로그의 논리적 묶음이다.
중요한 특징은 다음과 같다.
1) 메시지가 삭제되지 않고 보존된다
일반 MQ는 Consumer가 읽으면 메시지가 큐에서 사라지지만, Kafka는 읽어도 사라지지 않는다.
Consumer는 단지 “offset 커서만 이동할 뿐”이다.
즉, Kafka는 읽기/쓰기 모두 시간에 독립적인 구조다.
2) 여러 Consumer 그룹이 독립적으로 읽을 수 있다
토픽 하나를 서로 다른 애플리케이션이 자유롭게 읽어도 된다.
예시
- A팀: 실시간 모니터링 시스템
- B팀: 배치 분석
- C팀: 보안 이상징후 탐지 시스템
Kafka는 동일 데이터를 여러 팀이 공유하도록 설계되어 있다.
3) Partition 단위 스케일링
Topic 자체는 단순한 논리 개념이며, 실제 스케일링의 기준은 Partition이다.
2. Partition / Offset
Partition은 Kafka 성능의 핵심이므로 조금 더 자세하게 설명한다.
1) Partition은 "순서를 보장하는 세그먼트"
Partition 안에서는 절대 순서가 뒤섞이지 않는다.
이는 "정확한 스트림 처리"에 필수적이다.
예시
사용자 클릭 이벤트가 click_1 → click_2 → click_3 순서로 Partition에 들어가면 Consumer는 반드시 같은 순서로 읽는다.
2) Partition이 여러 개면 순서는 보장되지 않는다
Partition이 3개면 Kafka는 Key 해시 기반으로 메시지를 분산한다.
따라서 전체 Topic 레벨 순서는 없다.
→ 그래서 Keying 전략이 중요해진다.
3) Offset은 “읽기 위치”
Kafka 메시지는 삭제되거나 이동되지 않는다.
그저 offset이 증가할 뿐이며, Consumer가 “어디까지 읽었는지” 기록할 뿐이다.
offset=100에서 장애가 나면 재시작 후 offset=101부터 다시 읽으면 된다.
이 단순하고 강력한 구조가 Kafka 안정성의 기반이다.
3. Consumer Group 구조
Consumer Group은 Kafka를 스트리밍 플랫폼으로 만드는 핵심 메커니즘이다.
1) 병렬성을 자동으로 확보한다
Partition 개수가 10개라면 최대 10개의 Consumer가 병렬로 처리할 수 있다.
Kafka가 자동으로 partition → consumer 매핑을 설정한다.
2) Consumer가 죽어도 서비스는 중단되지 않는다
어떤 Consumer가 장애가 나면 남아있는 Consumer가 해당 Partition을 자동으로 가져간다.
즉, Failover가 자동화되어 있다.
3) Consumer Group별로 offset을 독립적으로 유지한다
Group A가 offset=500까지 읽었어도 Group B는 offset=0부터 새로 읽어도 상관없다.
이 구조 덕분에 하나의 Kafka Topic이 여러 시스템에서 재사용된다.
4. Producer / Consumer 동작 구조
Producer
Producer는 Kafka로 메시지를 전송하기 전 다음 단계를 거친다.
1) RecordAccumulator에 적재
메시지는 메모리 버퍼에 모였다가 batch로 전송된다.
Batch가 커질수록 전송 속도(throughput)는 기하급수적으로 증가한다.
2) Partitioner로 Partition 결정
Key를 기반으로 Hash를 계산해 Partition을 선택한다.
Key가 없으면 round-robin 방식으로 분배된다.
3) acks 옵션으로 내구성 제어
- acks=0 → 가장 빠르지만 데이터 손실 가능
- acks=1 → Leader만 쓰면 OK
- acks=all → ISR 모두 쓰기 완료해야 성공(안정성 최고)
Producer는 “속도 vs 안정성"을 설정하는 구조다.
Consumer
Consumer는 다음과 같은 방식으로 동작한다.
1) poll()로 일정량을 가져온다
단일 메시지가 아니라 batch로 가져와 처리 속도를 올린다.
2) 비즈니스 로직 처리
지연이 발생하면 heartbeat 지연 → rebalance 발생
따라서 처리 시간을 잘 관리해야 한다.
3) offset commit
- auto-commit 사용 시 일정 간격으로 자동 commit
- manual-commit 사용 시 처리 후 개발자가 명시적으로 commit
offset commit 전략에 따라 중복 처리 / 손실 처리 여부가 결정된다.
5. At-most-once / At-least-once / Exactly-once
Kafka 스트림 처리에서 가장 중요한 개념 중 하나다.
At-most-once
- commit → 처리 순으로 동작
- 중복 없음
- 대신 메시지 손실 가능
- 로그 중요도가 낮거나 실시간성이 최우선일 때 사용 (예: 단순 metrics, tracking)
At-least-once
- 처리 → commit 순으로 동작
- 메시지 손실 없음
- 대신 중복 가능
- 가장 일반적이고 안전한 방식
Exactly-once
Kafka Streams에서만 완벽 지원한다.
프로듀서/컨슈머 상태 저장소를 하나의 트랜잭션처럼 묶어 “중복도 없고, 손실도 없는” 가장 안정적인 처리를 지원한다.
예시
- 금융 처리
- 재고 수량 계산
- 여러 데이터 소스를 join하는 스트림 처리
6. Backpressure
Backpressure는 스트림 시스템에서 흔히 발생하는 핵심 문제다.
Backpressure란?
하위 처리 단계가 상위 단계 속도를 감당하지 못해 시스템이 밀리는 현상이다.
즉, 소비자가 처리하는 속도보다 생산자가 훨씬 빠를 때 발생하는 “압력 역전 현상”이다.
발생 원인
- Producer가 너무 빠르게 보냄
- Consumer 응답이 느림 (DB 호출 등)
- 특정 Key로 메시지 쏠림
- Kafka Partition은 Key에 의해 결정되므로 특정 Key로 이벤트가 몰릴수있다.
- Partition 수가 충분하지 않음
- Consumer가 poll을 자주 못함 (GC, 스레드 블로킹)
Backpressure 결과
- Kafka Lag 급증
- Partition의 끝 offset - Consumer가 읽은 offset
- 즉 Lag가 커진다 ? → 처리 효율이 낮다..
- 처리 지연 증가
- 알림 시스템 폭주
- Rebalance 연속 발생
Backpressure는 “시스템이 위험 신호를 보내는 상태”이며 이를 감지하기 위해 Kafka 모니터링에서 Lag은 절대적 지표이다.
7. Rebalancing
Rebalance는 Kafka Consumer Group의 재조정 작업이다.
언제 발생하는가?
- Consumer 추가
- Consumer 제거
- Consumer poll 지연 → heartbeat timeout
- Coordinator는 Consumer가 죽었다고 판단..
- 남은 Consumer에게 Partition을 재할당
- Rebalance 발생
- Topic Partition 개수 변경
Rebalance의 문제점
Rebalance가 일어나는 동안에는 모든 Consumer가 작업을 중단하고 협의를 진행한다.
이는 Stream Processing에서 치명적인 지연을 만든다.
그래서 아래 설정을 매우 중요하게 다룬다.
- heartbeat.interval.ms
- Consumer가 Coordinator에게 “나 살아있어 !”라고 신호를 보내는 주기
- session.timeout.ms
- Coordinator가 Consumer를 “죽었다”고 판단하는 시간
- max.poll.interval.ms
- poll() 사이 최대 허용 시간
- 이 값을 초과하면 Consumer를 죽은것으로 판단
애플리케이션이 오래 처리하면 → poll 지연 → heartbeat 지연 → Rebalance 발생 → 전체 서비스가 멈춘 것처럼 느려진다.
즉, Rebalance는 “필요한 기능이지만 최대한 적게 일어나야 하는 기능”이다.
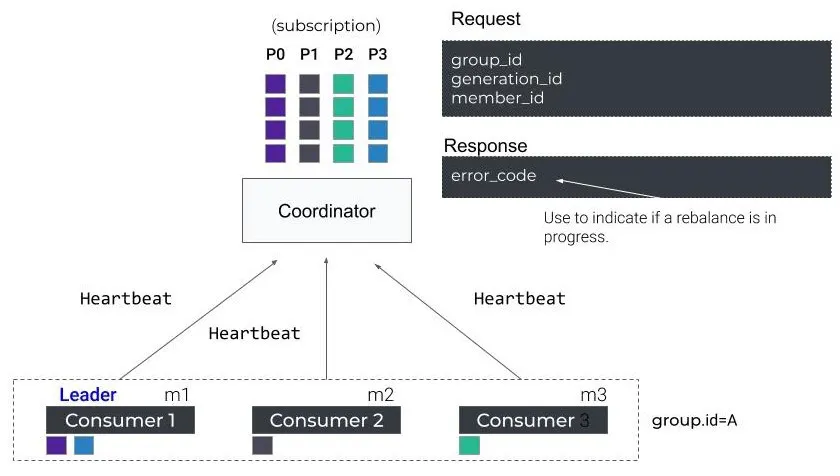
그림으로 다시보자.
- 여러 Consumer들은 Coordinator에게 주기적으로 Heartbeat를 보내며 “나는 살아있다”고 알린다.
- Coordinator는 각 Consumer의 subscription 정보를 기반으로 Partition을 배분한다.
- Consumer 요청(Request)에는 group_id, generation_id, member_id가 포함된다.
- Coordinator 응답(Response)의 error_code는 Rebalance가 진행 중인지 여부를 나타낸다.
- Consumer 1이 Leader 역할을 하여 최종 Partition assignment를 그룹에 전달한다.
8. Keying 전략 (Path / Service / Node 기반)
Partitioning은 Key를 기준으로 이루어진다.
따라서 어떤 Key를 넣느냐에 따라 스트림 처리 품질이 완전히 달라진다.
Kafka에서 Partition을 결정하는 요소 = Key이다.
즉,
Partition = hash(key) % partition_countKey 전략이 중요한 이유
- Partition 분산 여부가 결정된다.
- Key가 치우치면 하나의 Partition에만 과부화 → BackPressure 발생
- Lag 증가 → 전체 스트림 지연..
- Aggregation 정확도가 Key에 의해 결정된다.
- Kafka Strams/Flink의 Window 집계는 Key 단위로 수행된다.
- Key가 곧 집계 단위가 된다.
- Hot Key 문제가 생길수있다.
- 특정 Key에 트래픽이 몰리면 해당 Partition만 장애 수준의 Backlog가 생긴다.
1) Path 기반
REST API 경로에 기반해 Key를 설정하는 방법
예시
- /order/** → order
- /user/** → user
장점
- API 단위로 트래픽을 묶기 좋다.
- 특정 API에서 오류율이 폭증하는지 바로 알 수 있다.
- Monitoring 지표가 직관적
2) Service 기반
마이크로서비스 구조에서 추천되는 방식
즉, Key가 서비스 이름이 되는경우
예시
- payment-service
- auth-service
- inventory-service
서비스 단위 KPI 집계에 효과적이다.
3) Node 기반
노드 ID, IP, Pod ID 등을 key로 사용
장점
- 특정 서버의 이상징후를 즉시 감지
- 장애 서버 탐지 가능 단점:
- 특정 서버에 트래픽 쏠리면 Hot Partition 발생 위험
Keying 전략의 핵심 기준
- 파티션 간 트래픽 분산
- Key가 너무 적다 ? → 특정 Partition만 과부화
- Key가 너무 많다 ? → 집계의 의미가 없어진다.
- 비즈니스 단위 집계 가능
- Hotspot 방지 (Hot Key / Hot Partiotion)
- 방지 전략
- Key randomizer
- composite Key
- round-robin Partitioner
- consistent hashing 개선
- 방지 전략
9. Kafka Streams vs Consumer 기반 처리
일반 Consumer
- 단순히 메시지를 읽고 처리
- join/aggregation/window 등을 직접 구현해야 함
- 중복/재처리/오프셋 관리 복잡
- 상태 저장 불가
- 병렬 처리도 직접 구현
간단한 이벤트 처리에는 충분하지만 “실시간 분석 시스템”에는 부적합하다.
Kafka Streams
- Topology 기반으로 Stream → Processor → Sink 연결
- State Store로 상태 저장
- Changlog Topic으로 Store 내역을 백업
- Event-time 기반 window 연산
- Exactly-once 구현
- Failover 자동
- Repartition 자동
Kafka Streams는 “실시간 데이터 처리 엔진”이며 일반 Consumer는 “단순 메시지 소비자”다.
둘은 목적 자체가 다르다.
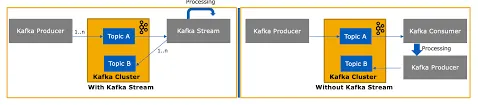
그림으로 다시보자.
- 왼쪽은 Kafka Streams가 Topic A/B를 직접 읽어 내부 Topology에서 처리하고 다시 Kafka에 쓰는 구조다.
- Streams 내부에서 join, aggregation, windowing 같은 고급 처리를 자동으로 수행한다.
- 오른쪽은 Consumer가 Topic A/B를 읽어 직접 처리한 뒤 필요하면 다시 Producer가 Topic으로 기록한다.
- 즉, Consumer 기반은 모든 처리 로직과 상태 관리, 재처리, 병렬화를 개발자가 직접 구현해야 한다.
- 반면 Kafka Streams는 “실시간 처리 엔진”이기 때문에 상태 저장, window, 재처리, failover 등을 자동 처리한다.
마무리
이번 편에서는 Kafka 기반 스트림 처리에서 반드시 알아야 하는 핵심 개념들을 좀 더 깊게 다뤘다.
- Topic이 로그 기반이라는 점
- Partition/Offset의 구조적 의미
- Consumer Group의 자동 Failover
- Exactly-once의 본질
- Backpressure가 발생하는 이유
- Rebalance가 왜 위험한지
- Keying 전략이 얼마나 중요한지
- Kafka Streams의 강점
이 개념들만 정확히 이해해도 Kafka 기반 실시간 분석 아키텍처를 어느정도 이해했다고 볼수있을거같다.
참고문헌
https://seonkyukim.github.io/kafka-rebalancing/
https://stackoverflow.com/questions/44014975/kafka-consumer-api-vs-streams-api
