[자격증]빅데이터분석기사 필기 합격 후기는 여기로 😋
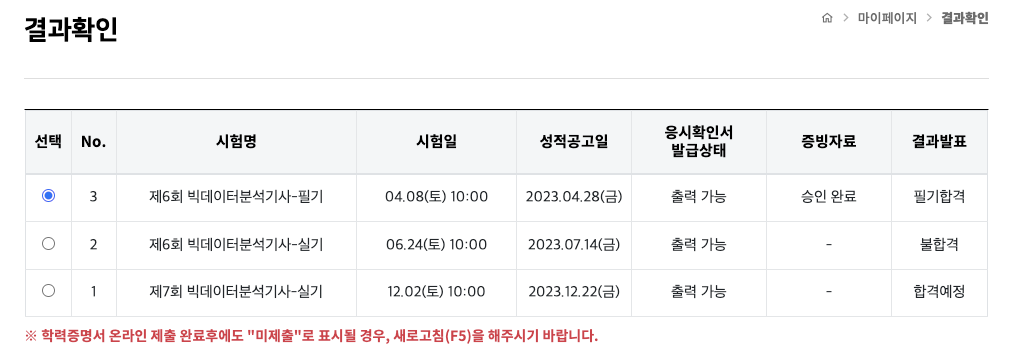
제7회 빅데이터분석기사 실기 시험을 보고 왔습니다!
시작하기에 앞서 6회 실기 후기를 먼저 적겠습니다..
저는 이번이 두 번째 실기 시험이었는데요.
6회 실기가 학교 시험과 겹쳐서 공부를 전혀 하지 못했습니다ㅠ
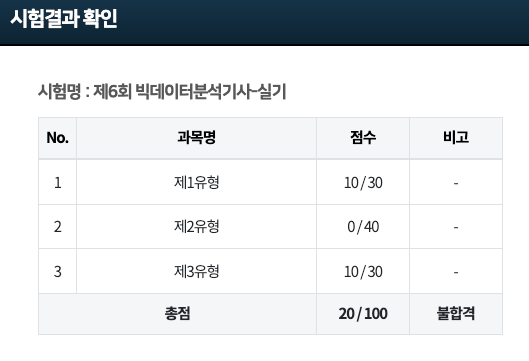
개수를 구하는 문제와 p-value를 구하는 문제만 풀었더니 20점이 나왔네요.
그래도 시험 직전에 여러 블로그를 보고 푸는 방식을 익히고 들어가서 풀 수 있었던 것 같습니다.
1. 공부 기간
11.10부터 공부를 시작해서 총 12일 공부했습니다.
제주ICT이노베이션에서 제공하는 45강짜리 강의를 듣는데 11일이 걸렸고 시험 전날에는 3, 4회 기출을 풀었습니다.
2. 공부 방법
작업1유형(30점), 작업2유형(40점), 작업3유형(30점) 중에서 60점을 맞으면 합격입니다.
작업 1유형
작업1유형에 주로 나오는 아래 3가지 유형에 대해 정리해봤습니다.
코드와 설명은 나중에 덧붙여볼게요..
이상치 처리, 결측치 처리
MinMaxScaler, StandardScaler
조건에 맞는 데이터 찾기(개수 세기)
참고
date 처리df['date'] = df['date'].astype('datetime64') df['year'] = df['date'].dt.year df['month'] = df['date'].dt.month df['day'] = df['date'].dt.day
작업 2유형
작업2유형이 40점으로 가장 높은 비율을 차지하고 있어서 무조건 다 맞아야겠다고 생각하면서 공부했습니다.
7회에서는 회귀 문제가 나왔습니다.
다중분류
# [0] import
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from lightgbm import LGBMClassifier
from sklearn.metrics import f1_score, roc_auc_score# [1] score 함수 작성
def get_scores(model, x_train, x_test, y_train, y_test):
A = model.score(x_train, y_train)
B = model.score(x_test, y_test)
y_pred = model.predict(x_test)
y_proba = model.predict_proba(x_test)
C = f1_score(y_test, y_pred, average='macro')
D = roc_auc_score(y_test, y_proba, multi_class= 'ovr')
return f'ACC {A:.4f} {B:.4f} F1 {C:.4f} AUC {D:.4f}'get_scores() 함수는 암기하고 가세요!
A와 B의 값이 비슷하면서 AUC 값이 높은 모델을 골라 학습하면 됩니다.
A > B이면 과대적합, A < B이면 과소적합입니다.
시험에서는 스코어가 0.6을 넘으면 점수가 나오는 것 같더라고요.
참고로 다중 분류가 아닌 그냥 분류에서는 get_scores()를 아래와 같이 수정하면 됩니다.
y_pred = model.predict(x_test)
C = f1_score(y_test, y_pred)
D = roc_auc_score(y_test, y_pred)# [2] 연속형, 범주형 확인
# XY = pd.concat([X, Y])
# print(XY.head())
# XY.info()
# print(XY.nunique())
# object: Gender, Ever_Married, Graduated, Profession, Spending_Score, Var_1
# 연속: Age, Profession, Work_Experience, Family_Size
# 범주: Gender, Ever_Married, Graduated, Spending_Score, Var_1연속형과 범주형을 확인하기 위해 info()를 찍어봅니다.
print() 때문에 출력 크기 초과나 시간 초과가 될 수 있으니 모두 주석 처리해주세요.
# [3] X, X_submission 합치기
dfX = pd.concat([X, X_submission]) # (8819, 10)
# print(dfX.shape)범주형을 처리하기 위해 인코딩해줘야 합니다.
X와 X_submission을 합쳐서 같이 인코딩해주면 편합니다.
# [4] LabelEncoding, OneHotEncoding
label = ['Gender', 'Ever_Married', 'Graduated', 'Spending_Score']
for i in label:
dfX[i] = dfX[i].astype('category').cat.codes
dfX = pd.get_dummies(dfX)
# print(dfX.head())범주형 중에서 범주가 2개인 경우에는 LabelEncoding, 3개 이상이면 OneHotEncoding 해주었습니다.
범주의 개수는 XY.nunique()를 통해 확인할 수 있습니다.
# [5] X, X_submission 분리
dfX = dfX.drop(columns=['ID'])
XF = dfX.iloc[:6665, :]
XF_submission = dfX.iloc[6665:, :]
YF = Y['Segmentation']
# print(X.shape, Y.shape, X_submission.shape) # (6665, 24) (6665, 2) (2154, 24)
# [6] 학습, 평가 데이터 분리
temp = train_test_split(XF, YF, test_size=0.2, random_state=1234, stratify=YF)
x_train, x_test, y_train, y_test = temp
# print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (5332, 24) (1333, 24) (5332,) (1333,)회귀에서는 stratify=YF 부분만 삭제해줍니다.
# [7] 모델 평가 및 선택
# model1 = LogisticRegression(max_iter=1000).fit(x_train, y_train)
# print(get_scores(model1, *temp))
# ACC 0.5257 0.5229 F1 0.5072 AUC 0.7683
# model2 = KNeighborsClassifier(18).fit(x_train, y_train)
# print(get_scores(model2, *temp))
# ACC 0.5497 0.4711 F1 0.4597 AUC 0.7302
# model3 = DecisionTreeClassifier(max_depth=5, random_state=1).fit(x_train, y_train)
# print(get_scores(model3, *temp))
# ACC 0.5366 0.5214 F1 0.5063 AUC 0.7729
model4 = RandomForestClassifier(500, max_depth=4, random_state=1).fit(x_train, y_train)
# print(get_scores(model4, *temp))
# ACC 0.5383 0.5206 F1 0.4960 AUC 0.7724
# model5 = LGBMClassifier(n_estimators=50, max_depth=3, random_state=1, force_col_wise=True).fit(x_train, y_train)
# print(get_scores(model5, *temp))
# ACC 0.5713 0.5356 F1 0.5243 AUC 0.7841ACC 2개의 값이 비슷하면서 AUC 값이 높은 모델을 골라 학습하면 됩니다.
RandomForestClassifier를 선택했습니다.
앙상블 모델이 대체로 스코어가 괜찮게 나온다고 하더라고요.
사용하지 않을 모델은 모두 주석 처리해줍니다.
# [7] to_csv
submission = pd.DataFrame()
submission['Segmentation'] = model4.predict(XF_submission)
submission.to_csv('result.csv', index=False)문제에서 요구하는 컬럼명이랑 타입으로 만들어졌는지 확인하고 csv 파일로 만들면 됩니다.
index=False는 필수!
근데 시험에서 조꼼 당황했던 일이 있었습니다 ㅠㅠ
만든 result.csv 파일을 확인해봤는데 *****e 형태로 나오는 겁니다 ..
그걸 여차저차 10진수로 바꿨어요 ..
정수로 나와야할 것 같은데 결과에 소수점이 있는 겁니다 ..
에라 모르겠다 그냥 제출했는데 40점 맞아서 다행이네요 🥲회귀
# [0] import
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_log_error as msle
from sklearn.metrics import mean_absolute_percentage_error as mape# [1] score 함수 작성
def get_scores(model, x_train, x_test, y_train, y_test):
A = model.score(x_train, y_train)
B = model.score(x_test, y_test)
y_pred = model.predict(x_test)
y_pred = np.where(y_pred >= 0, y_pred, -y_pred) # 음수가 아닌 값으로 변경
C = msle(y_test, y_pred) ** 0.5
D = mape(y_test, y_pred)
return f'R2 {A:.4f} {B:.4f} RMSLE {C:.4f} MAPE {D:.4f}'나머지 과정은 똑같습니다.
A와 B의 값이 비슷하면서 MAPE 값이 낮은 모델을 골라 학습하면 됩니다.
작업 3유형
솔직히 간단한 문제 나올 줄 알고 공부를 별로 안 했습니다.
정규성 검증이나 카이제곱 검정 부분 공부하고 갔는데 무슨.. 오류율? 같은 게 나와서 포기 ㅠㅠ
한 문제는 풀고 나머지는 0.0으로 찍었어요.
3. 결과
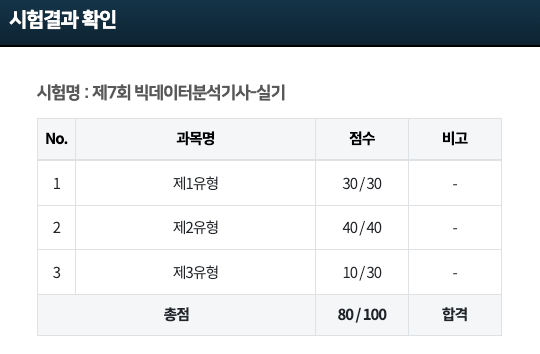
행복합니다 ㅎㅎ
정보처리기사에 이어 빅데이터분석기사도 얻게 되었는데요.
취뽀도 열심히 해보겠습니당 👊
추천 사이트
