인덱스란?
검색을 위해 임의의 규칙대로 부여된 임의의 대상을 가르키는 무언가
만약 인덱스가 없다면?
테이블 전체를 스캔해야하는 Full Table Scan
-> 대용량 테이블에 비효율적
인덱스를 메모리에 저장한다
인덱스의 구조
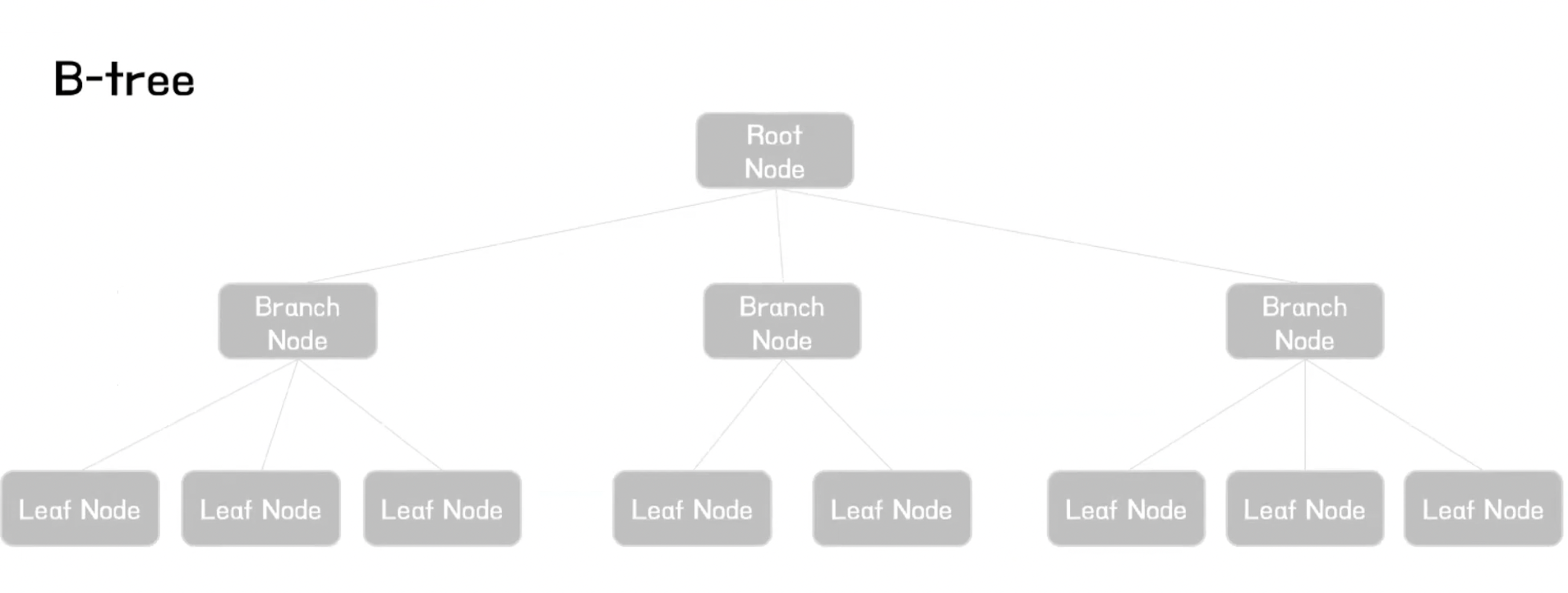
B-Tree
- 이진트리는 자식노드가 두개인 트리를 말하는데
- B-Tree의 경우 자식노드의 개수가 2개 이상인 트리를 말한다
수직적 탐색과 수평적 탐색
- 인덱스의 운행 방식은 수직적으로 조건을 만족하는 첫 번째 레코드를 찾아 들어간 후
- 리프노드에서 수평적 탐색을 통해 조건을 만족하는 레코드를 찾아가게 된다
Clustered vs Non-Clustered
- Cluster : 군집
- Clustered : 군집화
- Clustered Index : 군집화된 인덱스
1. Clustered Index
- clustered index의 경우에는 기본적으로 정렬이 되어 있어서 범위 검색에는 높은 성능을 보인다.
- 하지만 값이중간에 삽입된다거나(insert) 정렬하는 비용이 커지면 성능이 나빠진다
- Clustered는 Primary Key랑 매우 유사
2. Non-Clustered Index
- 간접 참조를 하고 있는 경우 (번지, 주소값)
- 순서와 상관 없다
- 해시 테이블 방식으로 검색이 매우 빠르다
Index의 효율 -> Cardinality
- 중복되는게 많아지면 카디널리티는 낮아진다
- 예) 성별
- 남자 50% 여자 50%
- 중복되는게 적어지면(유일한 값일 수록) 카디널리티는 높아진다
- 예) 주민등록번호
- 중복이 거의 없다
Query 튜닝
- MySQL의 경우 쿼리 실행 시 Explain 기능을 사용한다면 쿼리가 어떤식으로 실행할 계획인지 알 수 있다. 따라서 맞게 튜닝
- B-Tree
- Composite key

개발 경험 저장소