데이터베이스
기본적으로 하나의 서버, 하나의 스토리지를 가지고 있다.
샤딩, 클러스터링, 레플리케이션
공통점
- 데이터베이스를 여러개로 나눈다
Clustering
데이터베이스 서버가 죽으면?
-> 서버를 여러개로 만들자!
1. Clustering(Active-Active)
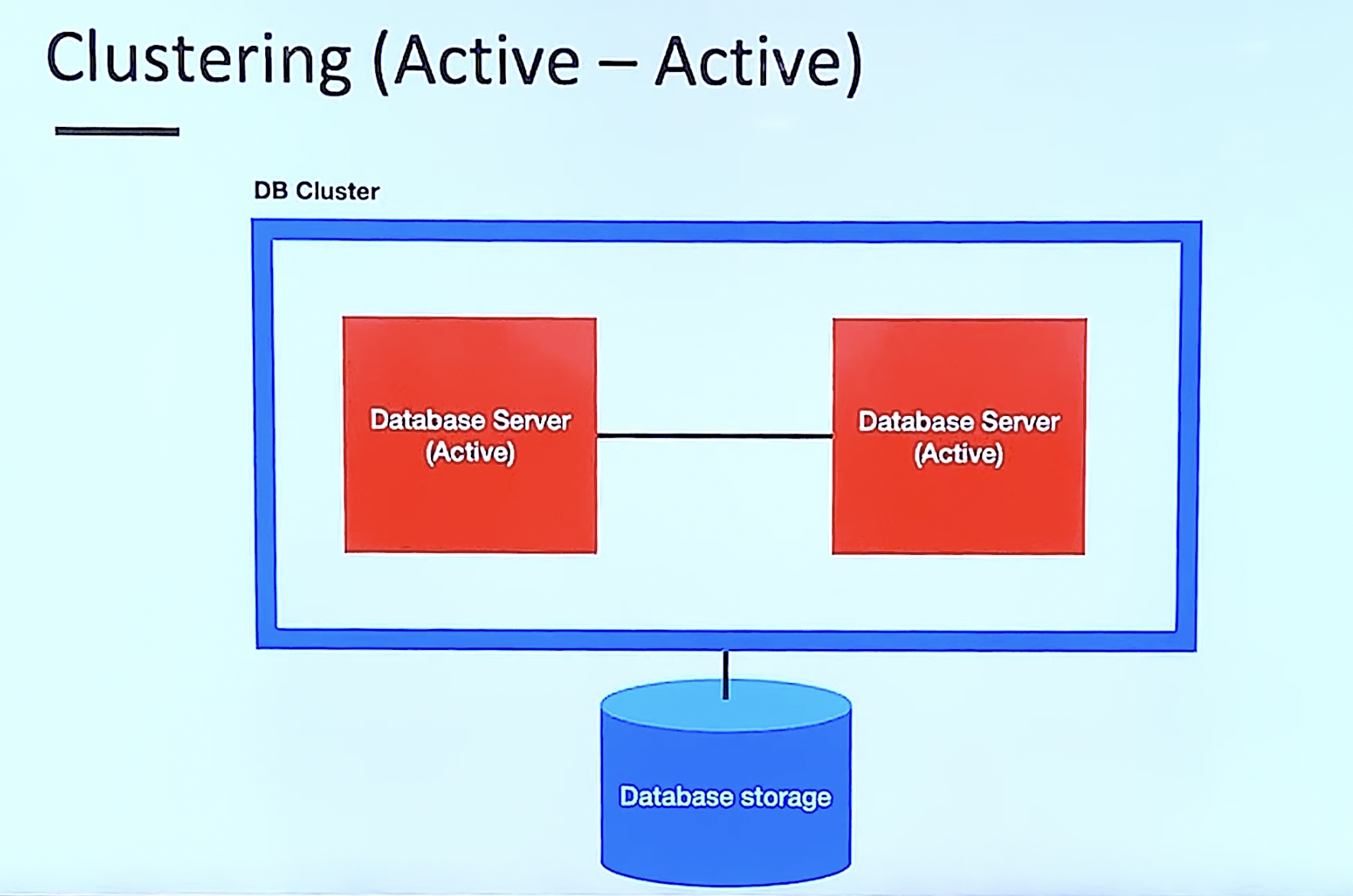
prod
- 여러 데이터베이스 서버를 동작 상태로 둔다
- 하나의 서버가 죽어도 다른 서버가 역할을 할 수 있기 떄문에 서버의 중단이 최소화됨
con
- 하나의 스토리지를 공유하고 있기 때문에 병목이 생길 수 있다.
- 비용이 비싸다
2. Clustering(Active-Standby)
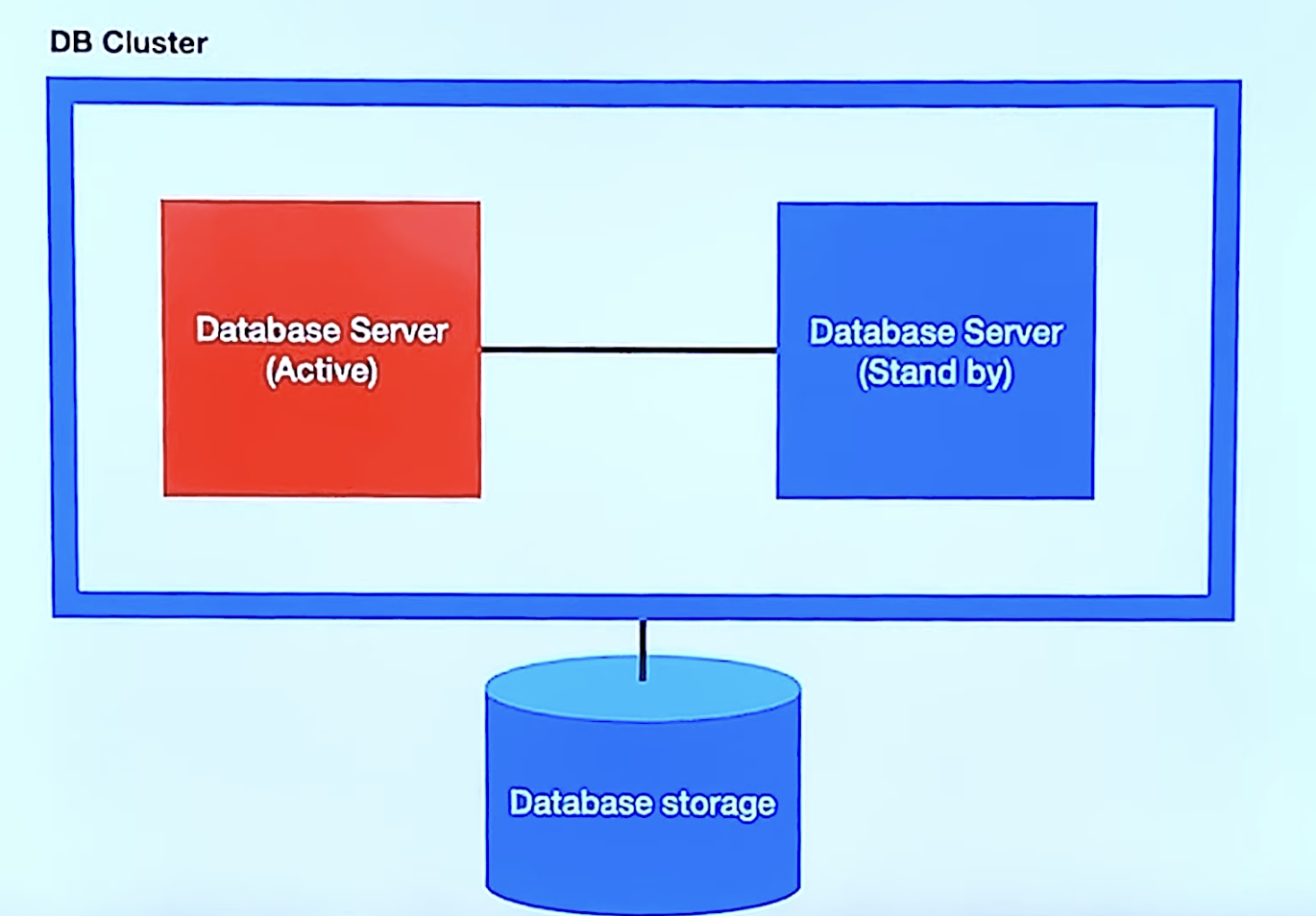
하나의 서버를 Active 상태로 두고 서버가 중지됐을 때 stand by 서버가 active 상태가 되어 대신하게 된다.
prod
- 비용이 저렴하다 (standby는 실제로 운용되지 않기 때문에)
con
- Active가 죽었을 때 전환 시 시간이 오래 걸린다
Replication
저장된 데이터가 손실되면 어떡하지?
-> 실제 데이터가 저장되는 저장소도 복제하자
replication
- 여러 개의 DB를 권한에 따라 수직적인 구조(Master-Slave)로 구축하는 방식
- 현재는 master-slave 단어를 안쓰는 추세인 만큼 source-replica 구조로 불리운다
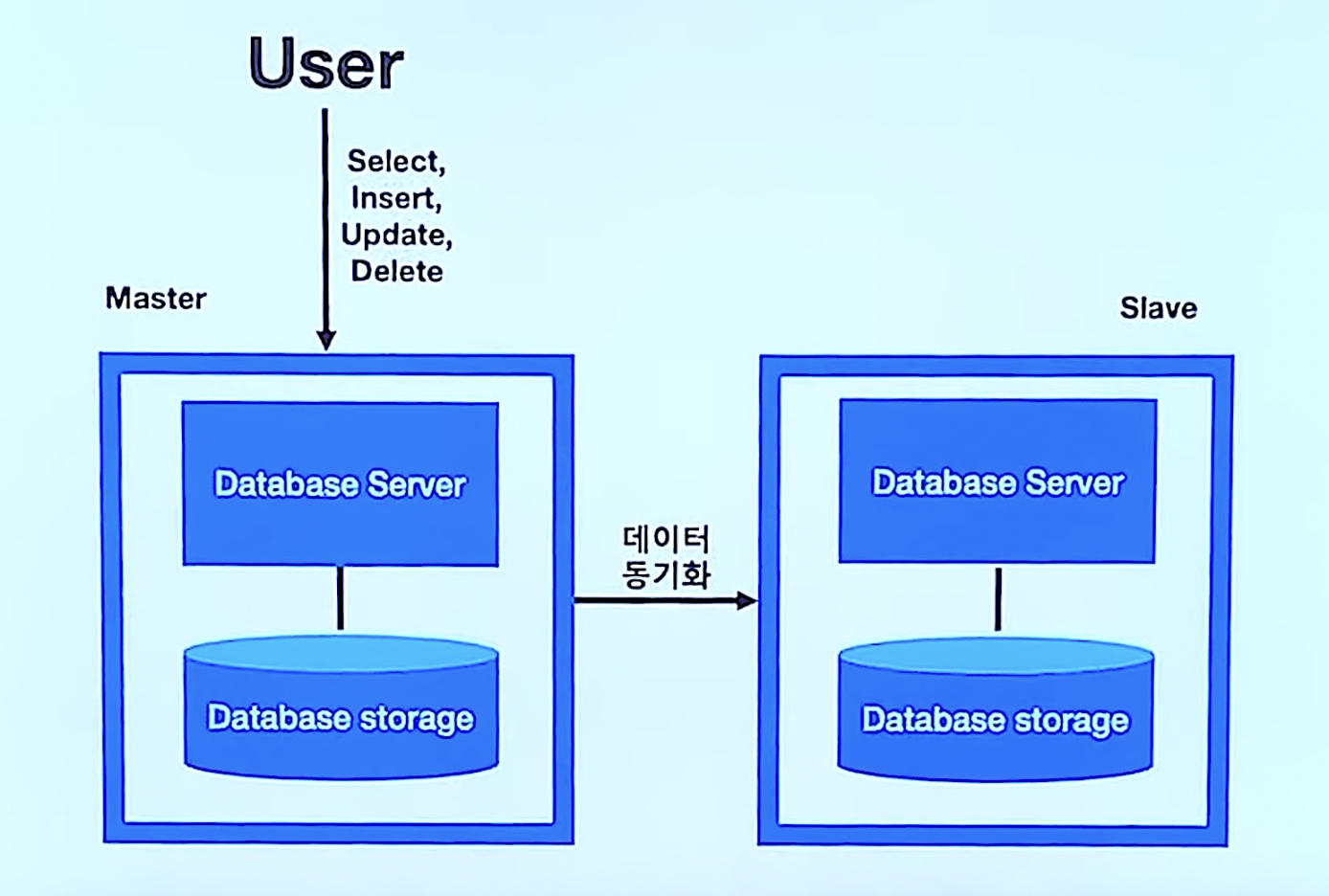
위 구성의 단점은 Slave의 DB 서버가 놀게 된다는 점
- Master DB(소스 DB)에는 Insert, Update, Delete
- Slave DB(Replica DB)에는 Select 를 하여 부하 분산
replication 구축 목적
- 스케일 아웃
- 갑자기 늘어나는 트래픽에 대해 부하를 줄이기 위해 서버를 늘리는 것
- 데이터 백업
- 백업 과정은 실제 실행중인 쿼리에 영향을 줄 수 있다.
- 따라서, 복제를 하여 레플리카 서버에서 데이터 백업을 진행
- 데이터 분석
- 데이터 분석의 경우, 대량의 데이터 조회, 복잡한 쿼리가 많을 수 있다.
- 소스 서버에서 데이터 분석을 할 경우, 실제 서비스에 문제가 생길 수 있다.
- 따라서 데이터 분석 전담 서버를 두는 것이 좋다.
- 데이터의 지리적 분산
- 데이터베이스 서버가 멀리 떨어져 있다면 빠른 응답을 받기 어렵다.
- 다양한 지역에 레플리카 서버를 두어 응답 속도를 높일 수 있다.
Sharding
데이터가 많아서 검색이 느린데 더 빠르게 할 수 있는 방법이 있을까?
-> 테이블을 나눠서 검색하자
sharding
- 테이블을 특정 기준으로 나눠서 저장 및 검색
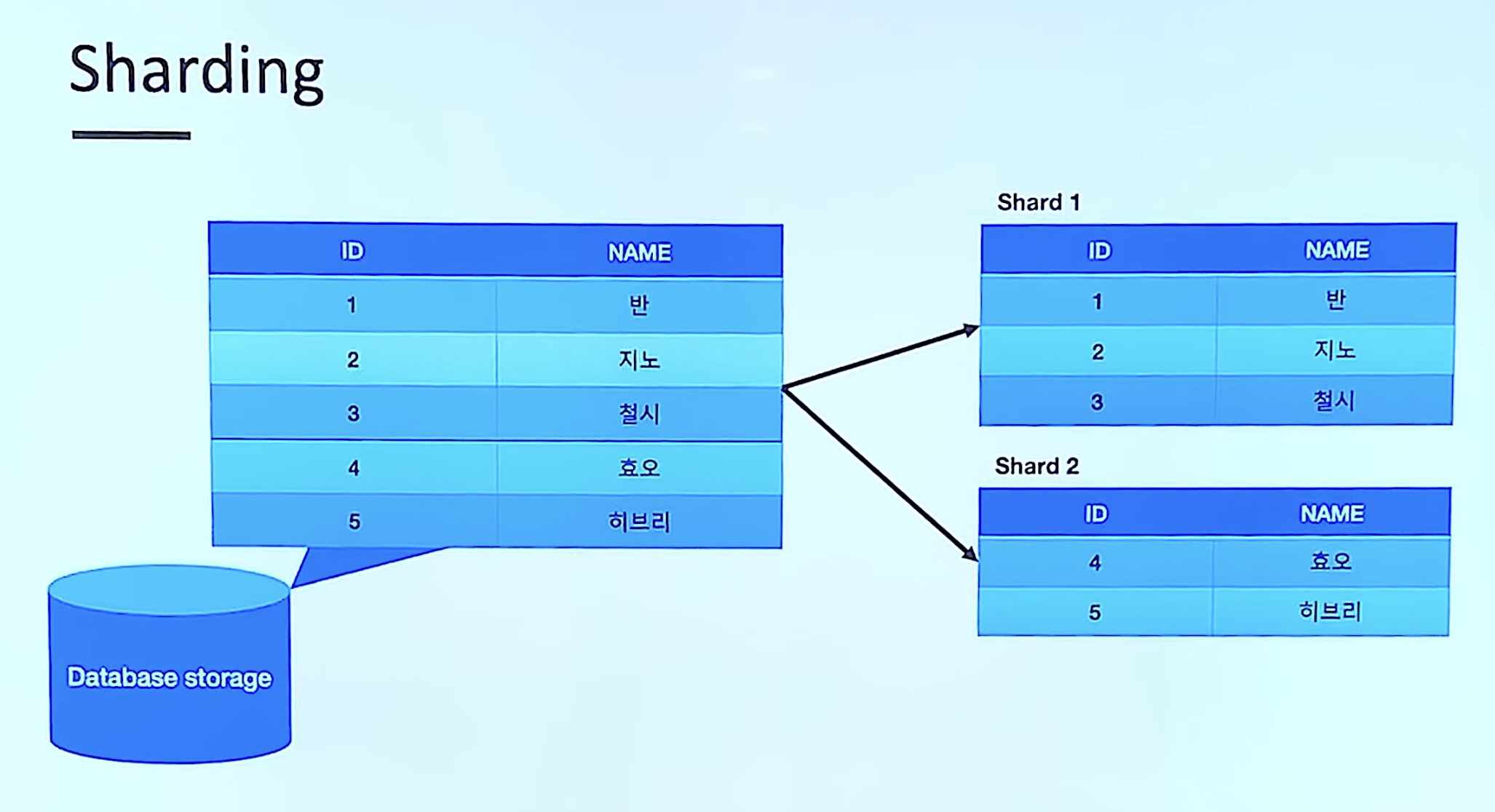
Sharding 시 주의할 점
Shard Key를 잘 선정해야 한다- 나눠진 shard 중 어떤 shard를 선택할지 결정하는 키
- Shard Key 결정방식에 따라 Sharding 방법이 나뉜다
Shard Key를 결정하는 방식
1. Hash Sharding
- 구현이 간단하다 (key-value)
- 확장성이 떨어진다
- 공간에 대한 효율을 고려하지 않는다
2. Dynamic Sharding
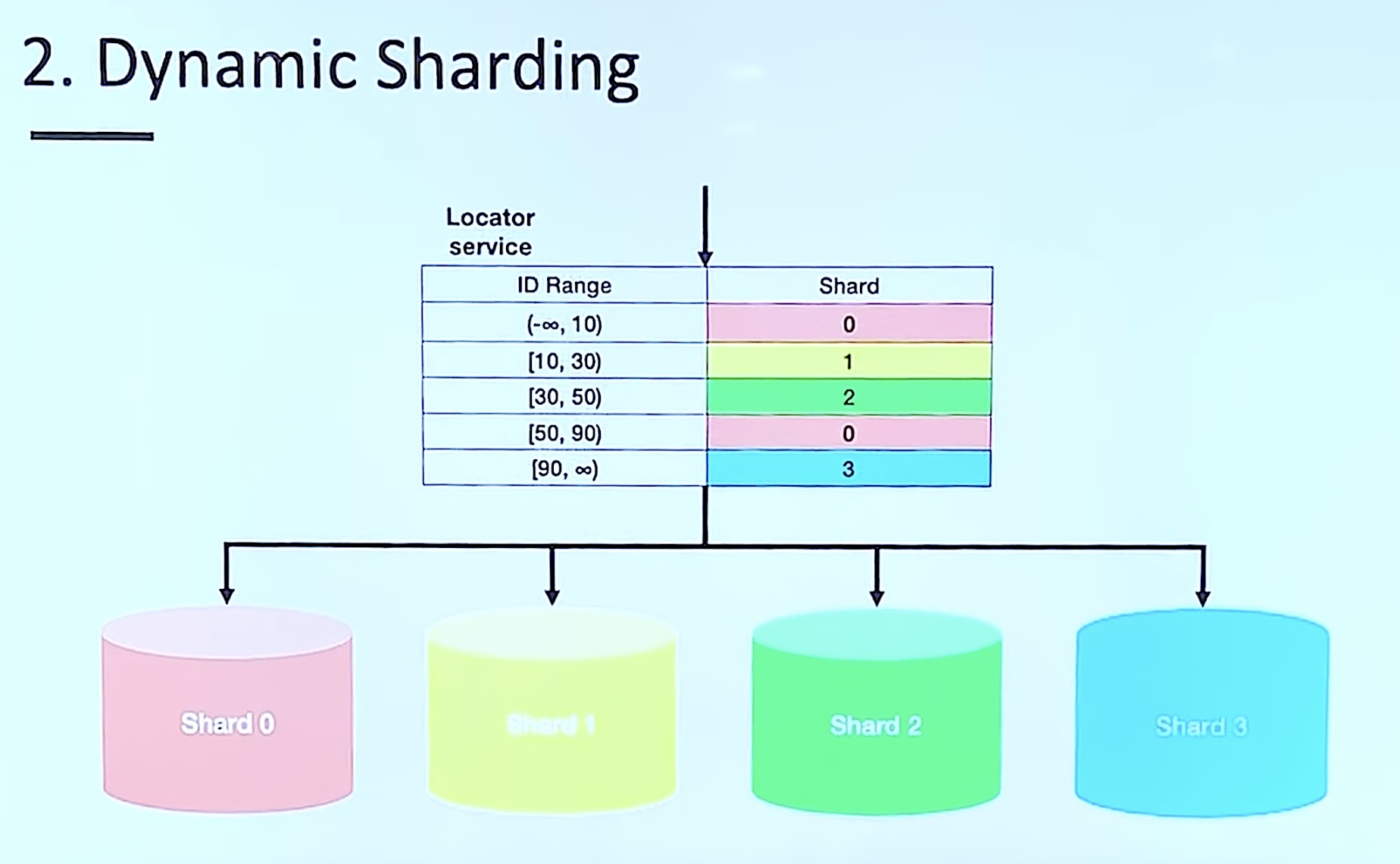
- 확장에 용이하다
- 데이터를 재배치시 Locator Service도 동기화 해야한다
- Locator에 의존적이다
3. Entity Group
- 1, 2번 방식과 같은 경우 key-value 형식이기 때문에 RDB보다 NoSQL에 좀 더 적합하다
- 관계가 있는 Entity끼리 같은 Shard 내에 공유하도록 만든 방식
prod
- 단일 Shard 내에서 쿼리가 효율적
- 단일 Shard 내에서 강한 응집도를 가진다
con
- 다른 Shard의 Entity와 연관되는 경우 비효율적
결론
데이터베이스를 나누는 것도 비용이기 떄문에 현재 상황에 맞는 기술을 사용하는 것이 중요하다
Reference

개발 경험 저장소