Chapter 6: Parallel Processors from Client to Cloud
• Task-level (process-level) parallelism.
High throughput for independent jobs.
• Parallel processing program.
Single program run on multiple processors.
• Multicore microprocessors.
Chips with multiple processors (cores).
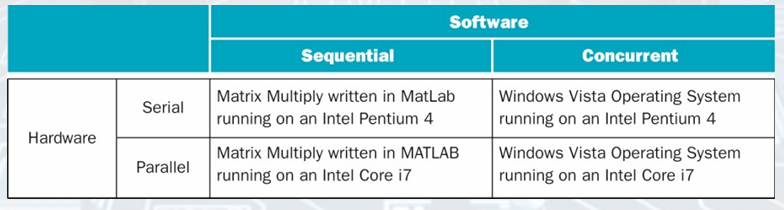
Hardward and Software
• Sequential/concurrent software can run on serial/parallel hardware.
Challenge: making effective use of parallel hardware.
Parallel Programming
Amdahl's Law
Sequential part can limit speedup

Sequential part need to be 0.1% of original time
Scaling Example

sum of 10 scalars: sequential data, 10x10 matrix sum: parallelizable
Time = (10(sequential) + 100(parallelizable)/processors) x t_add
Speedup = 110(single processor) / 20(multi processor) = 5.5 (55% of potential)? 10 processors/ 10, 10% of potential (100에 도달할 수 곱함)
Strong vs Weak Scaling
• Strong scaling: problem size fixed. As in example.
• Weak scaling: problem size proportional to number of processors.
10 processors, 10x10 matrix: Time = 20 x t_add
100 processors, 32 x 32 matrix: Time = (10 + 1000/100) x t_add = 20 x t_add
Constant performance in this example; performance가 20 나오도록 processor에 따라 problem size 바꿈
Instruction and Data Streams

• SPMD: Single Program Multiple Data.
A parallel program on a MIMD computer.
Conditional code for different processors.
Vector Processors
• Highly pipelined function units.
• Stream data from/to vector registers to units.
Data collected from memory into registers.
Results stored from registers to memory.
• Example: Vector extension to RISC-V.
• Significantly reduces instruction-fetch bandwidth.
Vector vs Scalar
• Vector architectures and compilers:
Simplify data-parallel programming.
Explicit statement of absence of loop-carried dependences. Reduced checking in hardware.
Regular access patterns benefit from interleaved and burst memory.
Avoid control hazards by avoiding loops.
• More general than ad-hoc media extensions (such as MMX, SSE).
Better match with compiler technology.
SIMD
• Operate elementwise on vectors of data.
E.g., MMX and SSE instructions in x86. Multiple data elements in 128-bit wide registers.
• All processors execute the same instruction at the same time.
Each with different data address, etc.
• Simplifies synchronization.
• Reduced instruction control hardware.
• Works best for highly data-parallel applications.
= exectue same instruction at the same time, with different data
Vector vs Multimedia Extension
variable vector width/ a fixed width
support stride access/ no
combination of pipelined and arrayed functional units/
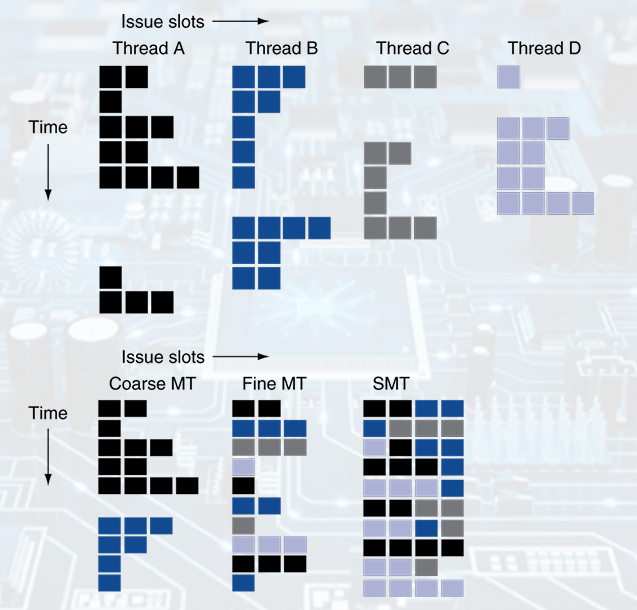
Multithreading
• Performing multiple threads of execution in parallel.
Replicate registers, PC, etc.
Fast switching between threads.
- Fine-grain multithreading:
Switch threads after each cycle.
Interleave instruction execution.
If one thread stalls, others are executed. - Coarse-grain multithreading:
Only switch on long stall (e.g., L2-cache miss).
Simplifies hardware, but doesn’t hide short stalls (e.g., data hazards). - Simultaneous Multithreading (SMT): In multiple-issue dynamically scheduled processor.
Schedule instructions from multiple threads.
Instructions from independent threads execute when function units are available.
Within threads, dependencies handled by scheduling and register renaming.
Shared Memory
SMP: shared memory multiprocessor.
• Hardware provides single physical address space for all processors.
• Synchronize shared variables using locks.
• Memory access time: UMA (uniform) vs. NUMA (nonuniform).

GPU
• 3D graphics processing:
Originally high-end computers (e.g., SGI).
Moore’s Law à lower cost, higher density.
3D graphics cards for PCs and game consoles.
• Graphics Processing Units:
Processors oriented to 3D graphics tasks.
Vertex/pixel processing, shading, texture mapping, rasterization.
- Perspective Projection vs. Orthographic Projection
- Graphics Rendering: rendered from wireframe (3d model)
- Graphics Pepeline
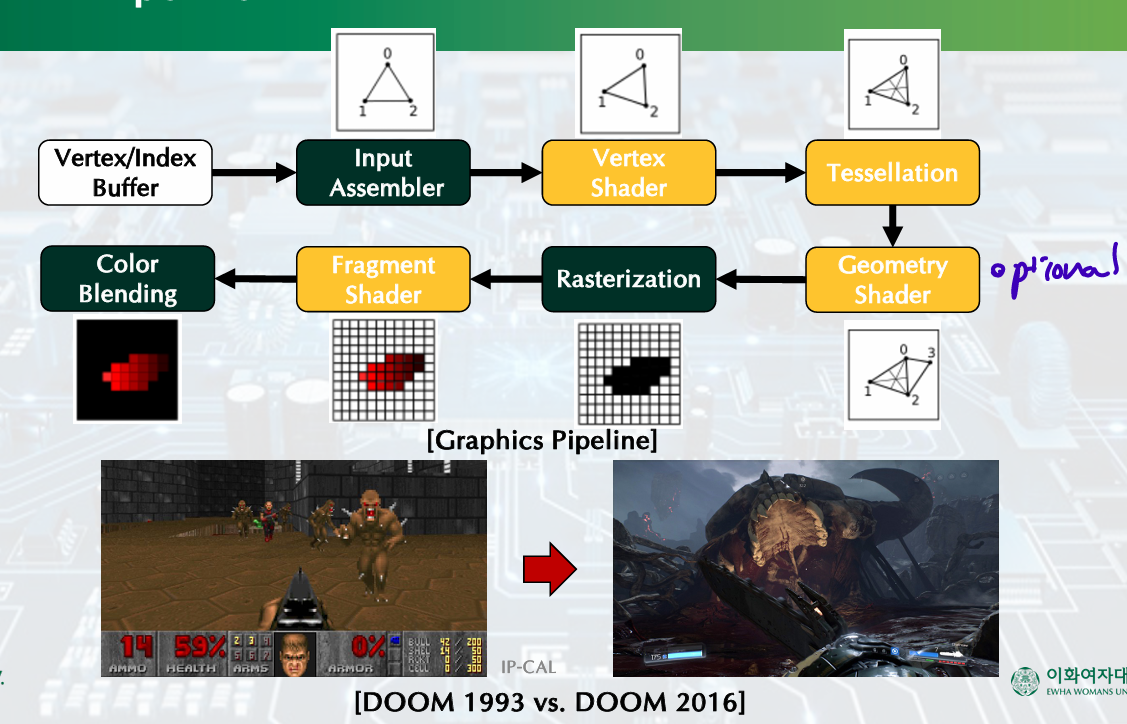
- History of Graphics Processing Units (GPUs)
fixed function- programmable stages - Improving Image Quality(ray tracing, general purpose application) - Graphics in the System
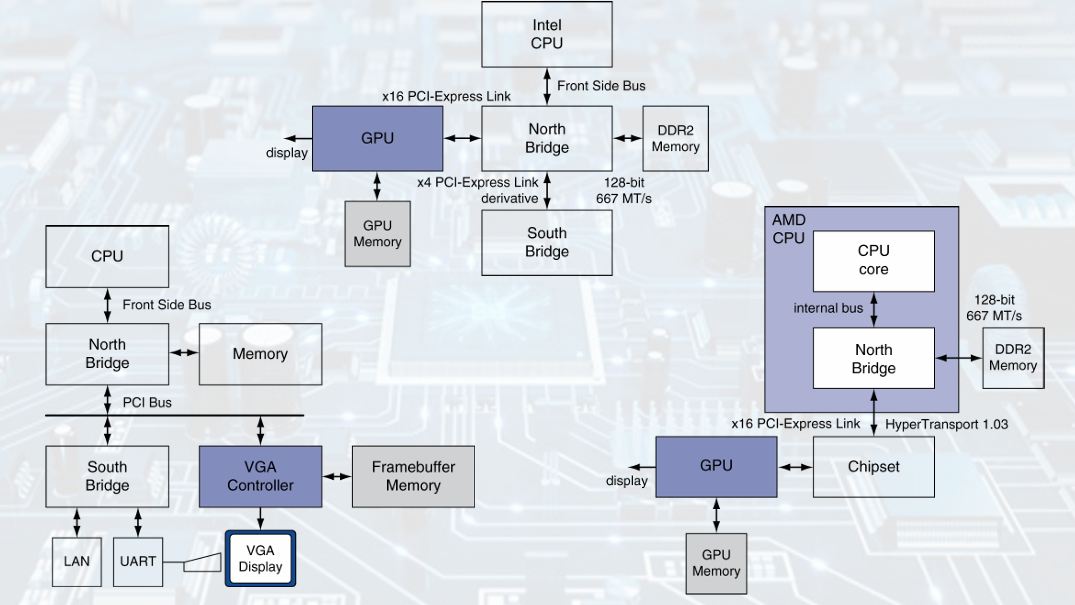
GPU Architectures
• Processing is highly data-parallel.
GPUs are highly multithreaded.
Use thread switching to hide memory latency. Less reliance on multi-level caches.
Graphics memory is wide and high-bandwidth.
• Trend toward general purpose GPUs.
Heterogeneous CPU/GPU systems.
CPU for sequential code, GPU for parallel code.
• Programming languages/APIs.
DirectX, OpenGL.
C for Graphics (Cg), High Level Shader Language (HLSL).
Compute Unified Device Architecture (CUDA).
Example: NVIDIA Tesla

• SIMD Processor: 16 SIMD lanes.
• SIMD instruction:
Operates on 32 element wide threads.
Dynamically scheduled on 16-wide processor over 2 cycles.
• 32K x 32-bit registers spread across lanes.
64 registers per thread context.
Classifying GPUs
Don’t fit nicely into SIMD/MIMD model.
• Conditional execution in a thread allows an illusion of MIMD.
But with performance degradation.
Need to write general-purpose code with care.

- GPU Memory Structures
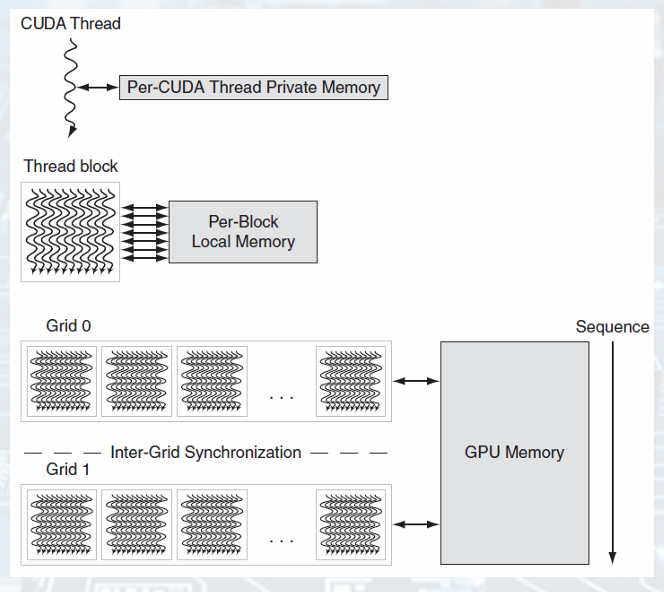
- Putting GPUs into Perspective

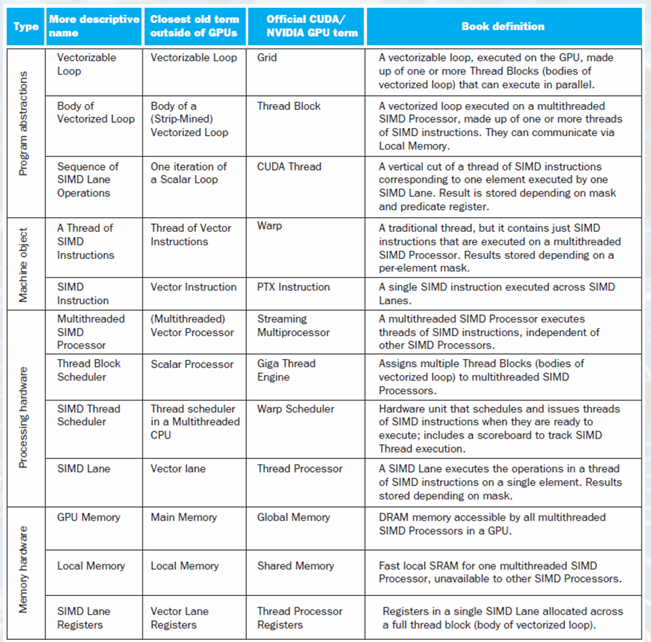
- GPU Terms