오늘은 알고리즘에 대해서 공부해볼 것이다.
알고리즘은 #include <algorithm>이런식으로 사용할 수 있다.
find
int main()
{
vector<int> v;
for (int i = 0; i < 100; i++)
{
int n = rand() % 100;
v.push_back(n);
}
// Q) 특정 숫자가 있는지?
{
int number = 50;
vector<int>::iterator it;
for (it = v.begin(); it != v.end(); it++)
{
int value = *it;
if (value == number)
{
break;
}
}
}
}우리는 특정 숫자를 찾을 때 지금까지 저렇식으로 찾아왔었다.
물론 잘못된 코드는 아니지만 코드의 양도 많고 다 읽어야 이해할 수 있을 것이다.
그래서 표준에서 조금 더 권장하는 방법이 있다.
auto it = std::find(v.begin(), v.end(), number);
if (it == v.end())
{
cout << "못찾음" << endl;
}
else
{
cout << "찾음" << endl;
}이런식의 방법이다.
성능상으로는 똑같지만 함수 이름자체가 무엇을 하고 있는지 명확하게 알려주기 때문에 가독성이 높아진다.
잠깐!
네임스페이스
우리가 namespace std;를 써왔는데 무엇일까?
네임스페이스라는 키워드는 다른 사람들과 협업을 하거나 표준 라이브러리를 이용할 때 함수 이름이 겹쳐버리면 컴파일이 안되기 때문에 이름이 안겹치기 위해서 namespace(이름 공간)을 사용하여서 분리시키는 것이다.
그래서 우리가 std에 있는 것을 사용할 때 std::find()이런식으로 접근해서 사용하는 것이다.
find_if
find의 다른 사용방법도 알아보자
// Q2) 11로 나뉘는 숫자가 있는지?
int div = 11;
vector<int>::iterator it;
for (it = v.begin(); it != v.end(); it++)
{
int value = *it;
if (value % 11 = 0)
{
break;
}
}이러한 상황이 때 find_if를 사용할 수 있다.
인수는 begin, end가 들어가고 pradicate를 넣어줘야하는데 여기에는 함수 포인터나 함수 객체(함수자)가 들어갈 수 있다. 사실 람다식을 넣어주는 것이 좋지만 아직 배우지않았으니 함수자를 만들어서 넣어보자.
struct CanDivideBy11
{
bool operator()(int n_
{
return n % 11 == 0;
}
};
auto it = std::find_if(v.begin(), v.end(), CanDivideBy11());
if (it == v.end())
{
cout << "못찾음" << endl;
}
else
{
cout << "찾음" << endl;
}이런식으로 사용할 수 있다.
솔직히 이렇게 보면 위에 있는 코드가 더 좋아보이지만 람다식을 배우면 아래코드가 더 좋아보일 것이다.
count_if
조건을 넣고 그 조건에 맞는 개수를 찾는 함수이다.
// Q) 홀수인 숫자 개수는?
int count = 0;
for(auto it = v.begin(); it != v.end(); it++)
{
if(*it % 2 != 0)
count++;
}직접만들면 이런식이고
count_if를 사용해본다면
struct IsOdd
{
bool operator()(int n)
{
return n % 2 != 0;
}
};
int n = std::count_if(v.begin(), v.end(), IsOdd());이런식으로 사용할 수 있다.
이것과 비슷한 결의 함수들이 있는데 이것도 같이 설명하겠다.
// 모든 데이터가 홀수입니까?
bool b1 = std::all_of(v.begin(), v.end(), IsOdd());
// 홀수인 데이터가 하나라도 있습니까?
bool b2 = std::any_of(v.begin(), v.end(), IsOdd());
// 모든 데이터가 홀수가 아닙니까?
bool b3 = std::none_of(v.begin(), v.end(), IsOdd());이런식의 함수가 all_of, any_of, none_of 3가지가 더 있다.
이 정도는 만들어 사용할 수도 있지만 가독성 측면에서 더 보기 좋기때문에 기억을 해두는 것이 좋다.
for_each
모든 데이터를 순회를 할 때 사용함
//Q) 벡터에 있는 모든 숫자들에 3을 곱해주세요!
for(int i = 0, i < v.size(); i++)
{
v[i] *= 3;
}이런식으로 만들어서 사용이 가능하지만 for_each를 사용한다면
struct MutiplyBy3
{
void operator()(int& n)
{
n *= 3;
}
};
std::for_each(v.begin(), v.end(), MutiplyBy3());이런식으로 사용할 수 있다.
여기까지는 기본적인 함수들이다.
지금까지 다룬 함수들은 쉬웠지만 이 함수는 진짜 조심해야한다.
remove, remove_if
사람들이 이 함수들을 잘못 사용하는 경향이 있고 C++에서 좀 잘못만들어져 있기도 하다.
우리가 홀수인 데이터를 일괄 삭제하는 코드를 만든다고 하였을 때
vector<int> v = { 1, 4, 3, 5, 8, 2 };
for (auto it = v.begin(); it != v.end(); it++)
{
if (*it % 2 != 0)
v.erase(it);
}우리가 만들어 사용하면 이런식으로 사용하겠지만 여기서 치명적인 오류가 있다..
저번에 설명을 하였는데
저런식으로 코드를 짜버린다면 크래시가 나거나 넘어가버리기 때문에
vector<int> v = { 1, 4, 3, 5, 8, 2 };
for (auto it = v.begin(); it != v.end();)
{
if (*it % 2 != 0)
it = v.erase(it); // iterator로 위치를 받아주고
else
it++; //it++을 여기서 해준다.
}이런식으로 코드를 짜줘야 한다.
여기서도 실수를 할 수 있는데 remove는 더 실수를 할 가능성이 높다.
struct IsOdd
{
bool operaotr()(int n)
{
return n % 2 != 0;
}
};
std::remove_if(v.begin(), v.end(), IsOdd());이런식으로 사용할 수 있을 것인데
우리가 1, 4, 3, 5, 8, 2를 넣어줬는데 실행시키면 뭐가 남을까?
우리는 홀수를 삭제 하기로 하였기때문에 예상하기로는 4,8,2 이렇게 남았을 것이라고 생각할 것이다.
하지만 실제로 실행을 해보면 4 8 2 5 8 2가 들어가있다?!!??
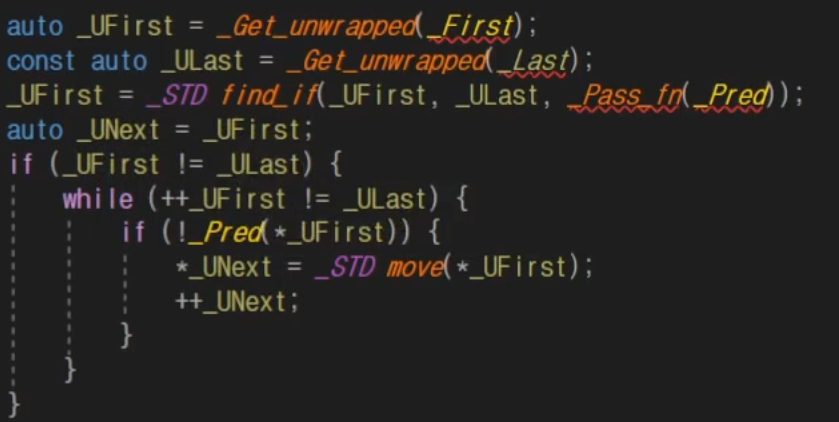
일단 컨닝을 하면서 알아보겠다.
이게 UNext가 커서이고 Ufirst가 앞으로 이동하면서 거르는 역활을 한다.
그래서 삭제를 하지않고 남겨야 하는것을 앞으로 구출을 하는 것인데
그것을 별도에 벡터에서 하는 것이아닌 똑같은 벡터를 대상으로 한다.
1 홀수니까 넘김 -> 4 맨 앞으로 -> 8남겨야 됨 앞으로 -> 2남겨야 됨 앞으로
482 근데 별도의 벡터가 아니기에 덮어쓰여버린다.
그래서 반반 섞여 있던 것이다.
이 뜻은 '나는 맨 앞으로 정리를 해줬기 때문에 뒤에 있는 것들은 너가 정리해!'이런 것이다.
그래서 iterator로 반환값을 받으면 5의 위치를 반환시켜 주기 때문에
struct IsOdd
{
bool operaotr()(int n)
{
return n % 2 != 0;
}
};
std::remove_if(v.begin(), v.end(), IsOdd());
v.erase(it, v.end()); // 뒷부분 지우기이렇게 해줘야 한다..
그래서 remove랑 erase를 세트로 생각해야한다.
마무리
그래서 오늘은 많이 사용되는 표준 라이브러리에 함수들을 알아보았는데
여기서 흠이 살짝있었다 predicate를 설정할 때 매번 struct를 만들어서 함수자를 만들어 줬어야 하는데
다음시간에 람다식을 공부해서 편하게 만드는 법을 알아볼 것이다!
- 수정 사항 -
STL가 정리된 블로그
나중에 복습할 때 볼 만할 것 같음
