
Outline
Formula E 레이스 결과를 크롤링
Ready
Official Site: https://www.fiaformulae.com
RESULTS 메뉴에서 시즌, 레이스 별로 결과를 확인할 수 있음.
모든 시즌과 레이스는 고유의 ID가 부여되어 있어, 이를 키로 사용해서 크롤링 해야 함.
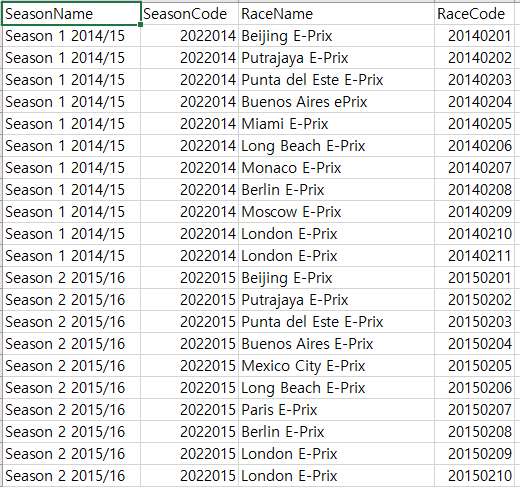
Code
시즌과 레이스 ID로 각 레이스마다 URL을 조립하여 크롤링 함수 호출.
for item in race_list.itertuples():
race_url = "https://www.fiaformulae.com/en/results/race-results/?championship=" + str(getattr(item, "SeasonCode")) + \
"&race=" + str(getattr(item, "RaceCode"))
s_name = getattr(item, "SeasonName")
r_name = getattr(item, "RaceName")
# main process
r_result = MakeRaceResult(race_url, s_name, r_name)
race_result = race_result.append(r_result)레이스 결과를 가져와서 보기 편하게 편집.
# Make race result
def MakeRaceResult (url_r, season_name, race_name):
# Get Source
source = urllib.request.urlopen(url_r)
# HTML to table
soup = bs.BeautifulSoup(source, "lxml")
table = soup.find_all("table")[0]
df = pd.read_html(str(table), flavor="bs4", header=[0])[0]
# Remove strange row
df_n = df.drop(df[(df.index % 2 == 1)].index)
# Remove unused column
df_l = df_n.drop(['MoreMore', 'Unnamed: 8', 'Unnamed: 9', 'Unnamed: 10', 'Unnamed: 11', 'Unnamed: 12'], axis=1)
# Reset index
df_l = df_l.reset_index(drop=True)
# Get Source again
source = urllib.request.urlopen(url_r)
# Read HTML again for Driver Name
soup = bs.BeautifulSoup(source, "lxml")
# Make table for driver's first name
tb_fname = soup.find_all("div", {"class":"driver__fname"})
df_fname = pd.DataFrame(tb_fname)
df_fname.rename(columns={0: 'DriverFirstName'}, inplace=True)
# Remove duplicated row
df_fname = df_fname.drop(df_fname[(df_fname.index % 2 == 1)].index)
df_fname = df_fname.reset_index(drop=True)
# Make table for driver's last name
tb_lname = soup.find_all("span", {"class":"full"})
df_lname = pd.DataFrame(tb_lname)
df_lname.rename(columns={0: 'DriverLastName'}, inplace=True)
# Remove duplicated row
df_lname = df_lname.drop(df_lname[(df_lname.index % 2 == 1)].index)
df_lname = df_lname.reset_index(drop=True)
# Make table for driver's number
tb_number = soup.find_all("div", {"class":"driver__number"})
df_number = pd.DataFrame(tb_number)
df_number.rename(columns={0: 'DriverNumber'}, inplace=True)
# Remove duplicated row
df_number = df_number.drop(df_number[(df_number.index % 2 == 1)].index)
df_number = df_number.reset_index(drop=True)
# Concat race result and name and number
df_result = pd.concat([df_l, df_number, df_fname, df_lname], axis=1)
# Changing column name
df_result.rename(columns={'PosPos':'Pos', 'TeamTeam':'Team', 'StartedStarted':'Started', 'BestBest':'Best', 'TimeTime':'Time'}, inplace=True)
# Removing Driver column
df_result = df_result.drop(['DriverDriver'], axis=1)
# Add season name
df_result['SeasonName'] = season_name
df_result['RaceName'] = race_name
# Changing column order
df_result = df_result[['SeasonName','RaceName','Pos','DriverNumber','DriverFirstName','DriverLastName','Team','Started','Best', 'Time','PtsPoints']]
return df_result순위, 선수, 팀, 랩타임, 획득 포인트 등을 얻을 수 있음.
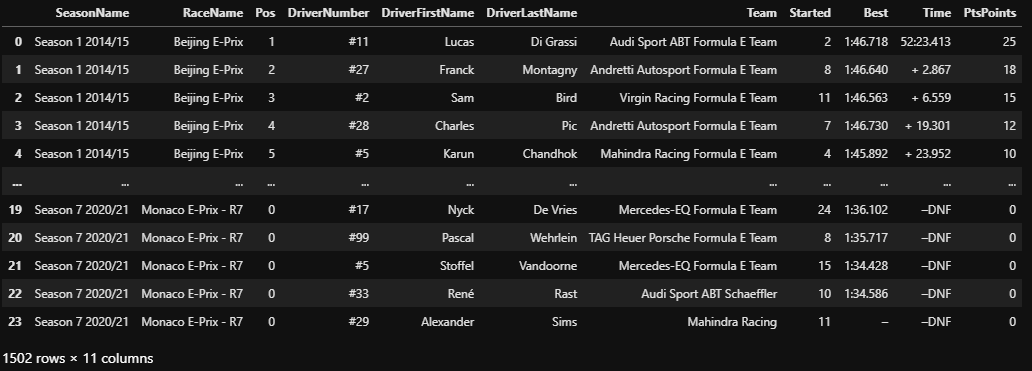
Link
Github: https://github.com/OreoJam/Crawling_FormulaE_Raceresults
Kaggle: https://www.kaggle.com/oreojam/formula-e-world-championship-race-results
Today I Failed.