📒 SQL
📕 Oracle DB 설치
1. Windows
-
1) 오라클 소프트웨어 설치
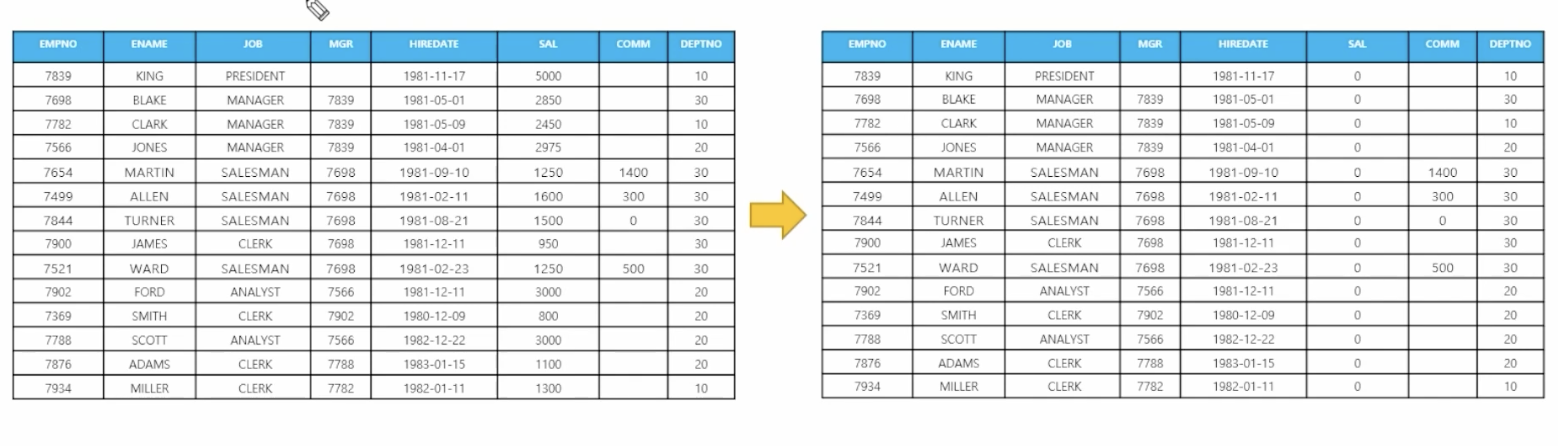
Database DownloadDatabase Express Edition- 설치파일의 위치에 한글 포함X
- 실행파일을 관리자 권한으로 실행
-
2) 21c Express Edition 접속
sqlplus " / as sysdba"

-
3) Oracle User 생성
- c## + 사용자 이름 으로 생성 (비밀번호 tiger)
create user c##scott identified by tiger;grant dba to c##scott;: 권한 부여connect c##scott/tiger: 접속

-
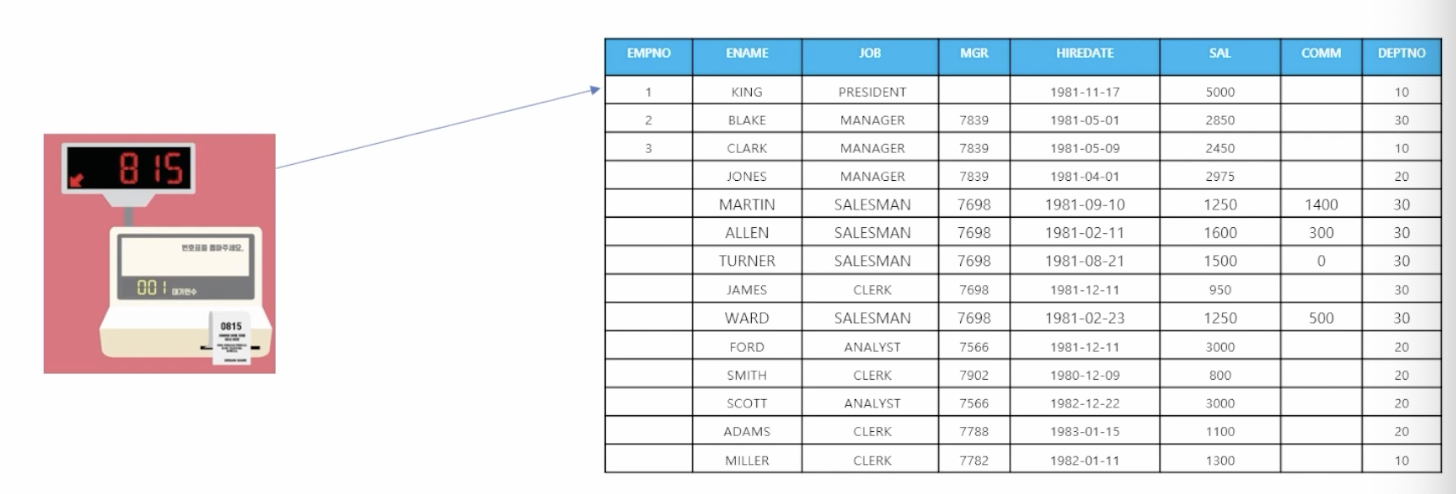
4) table 생성
- SQL 실습 스크립트 생성
alter session set nls_Date_format='RR/MM/DD';
drop table emp;
drop table dept;
CREATE TABLE DEPT
(DEPTNO number(10),
DNAME VARCHAR2(14),
LOC VARCHAR2(13) );
INSERT INTO DEPT VALUES (10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT VALUES (20, 'RESEARCH', 'DALLAS');
INSERT INTO DEPT VALUES (30, 'SALES', 'CHICAGO');
INSERT INTO DEPT VALUES (40, 'OPERATIONS', 'BOSTON');
CREATE TABLE EMP (
EMPNO NUMBER(4) NOT NULL,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4) ,
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2) );
INSERT INTO EMP VALUES (7839,'KING','PRESIDENT',NULL,'81-11-17',5000,NULL,10);
INSERT INTO EMP VALUES (7698,'BLAKE','MANAGER',7839,'81-05-01',2850,NULL,30);
INSERT INTO EMP VALUES (7782,'CLARK','MANAGER',7839,'81-05-09',2450,NULL,10);
INSERT INTO EMP VALUES (7566,'JONES','MANAGER',7839,'81-04-01',2975,NULL,20);
INSERT INTO EMP VALUES (7654,'MARTIN','SALESMAN',7698,'81-09-10',1250,1400,30);
INSERT INTO EMP VALUES (7499,'ALLEN','SALESMAN',7698,'81-02-11',1600,300,30);
INSERT INTO EMP VALUES (7844,'TURNER','SALESMAN',7698,'81-08-21',1500,0,30);
INSERT INTO EMP VALUES (7900,'JAMES','CLERK',7698,'81-12-11',950,NULL,30);
INSERT INTO EMP VALUES (7521,'WARD','SALESMAN',7698,'81-02-23',1250,500,30);
INSERT INTO EMP VALUES (7902,'FORD','ANALYST',7566,'81-12-11',3000,NULL,20);
INSERT INTO EMP VALUES (7369,'SMITH','CLERK',7902,'80-12-09',800,NULL,20);
INSERT INTO EMP VALUES (7788,'SCOTT','ANALYST',7566,'82-12-22',3000,NULL,20);
INSERT INTO EMP VALUES (7876,'ADAMS','CLERK',7788,'83-01-15',1100,NULL,20);
INSERT INTO EMP VALUES (7934,'MILLER','CLERK',7782,'82-01-11',1300,NULL,10);
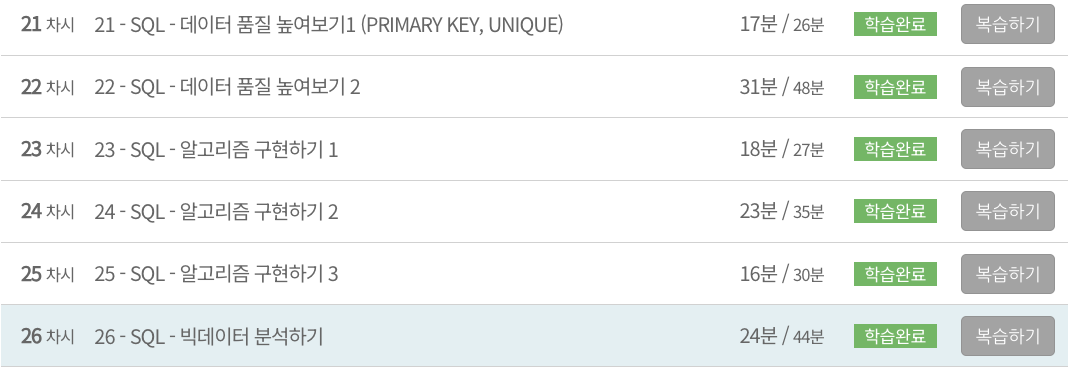
commit;select * from dept;: table 확인
- 5) SQL Developer 설치
lsnrctl status: 오라클 listener 상태 확인 (port : 1521, 서비스 : xe 확인)
2. Mac
-
1) colima 설치
- 무거운 Docker Desktop을 대신해 간단한 CLI 환경에서 도커 컨테이너를 실행할 수 있는 오픈 소스 소프트웨어
- colima 설치 :
brew install colima
-
2) docker 설치
- 도커 데스크탑을 설치하거나, 도커 엔진만 설치 가능
- 도커 데스크탑 설치
- colima와 Docker Desktop을 동시에 실행 가능
- 하지만, 둘다 실행시 docker 명령은 colima가 docker desktop으로 설정되어 있던 default docker context 가져가 버림
- Docker context가 다르면 이미지 공유도 안됨 (Docker context 변경시 자유롭게 왔다갔다 가능)
- 도커 엔진 설치 :
brew install docker- 도커 엔진을 구동할 수 있는 도커 머신 역할을 Docker Desktop 혹은 Colima가 수행
-
3) colima 실행
- colima를 x86_64 환경으로 띄워줌 :
colima start --memory 4 --arch x86_64- Doker Desktop 환경에서 oci-oracle-xe 이미지로 컨테이너를 띄웠을 때 아키텍처가 달라 문제 발생 (colima가 해결)
docker ps: 컨테이너 리스트를 반환 (현재 가동중인 컨테이너만 출력)
- colima를 x86_64 환경으로 띄워줌 :
-
4) 오라클 서버
- 오라클 서버 띄우기 :
docker run --restart unless-stopped --name oracle -e ORACLE_PASSWORD=pass -p 1521:1521 -d gvenzl/oracle-xe
docker logs -f (컨테이너명): 로그 확인
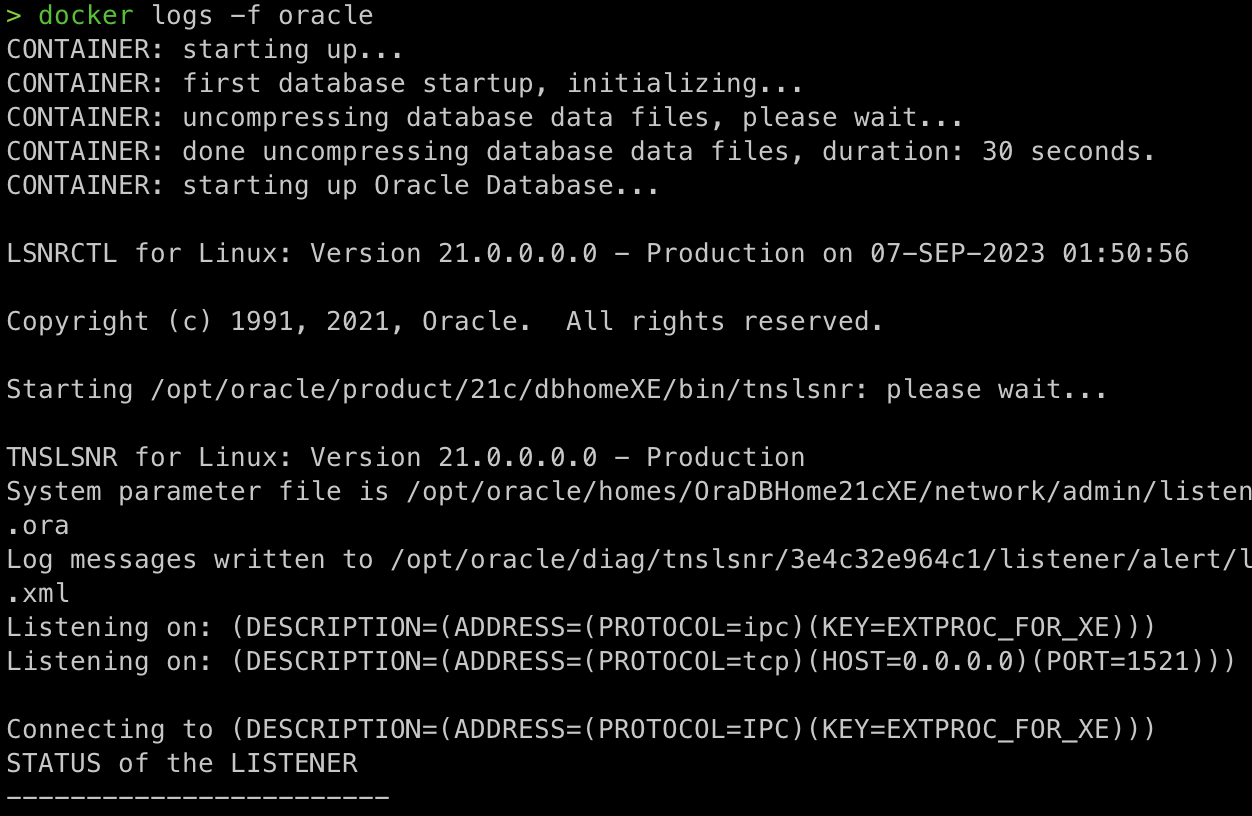

- 오라클 서버 띄우기 :
-
SQLDeveloper아이콘 ➡️ 응용 프로그램으로 이동
-
6) DB 연결
- SQL Developer ➡️
새 접속 - 사용자 이름 : system
- 비밀번호 : pass
- 호스트 이름 : localhost
- 포트 : 1521
- SID : xe
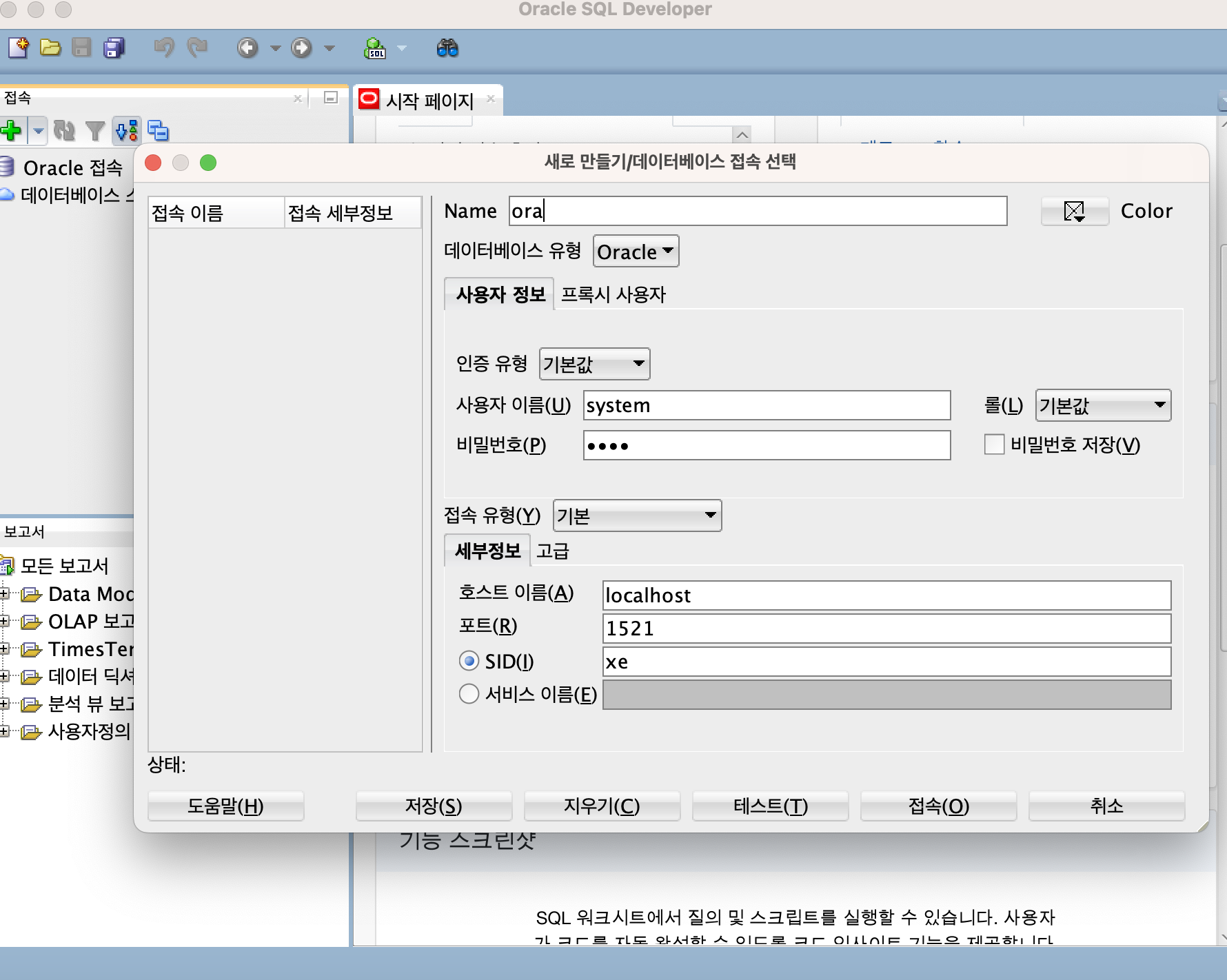
- SQL Developer ➡️
-
7) SCOTT 계정 생성
- sqlplus 접속 :
docker exec -it oracle sqlplus- username : system
- password : pass
- user 생성하고 필요한 권한 부여
CREATE USER scott identified by tiger; GRANT CONNECT, resource, dba to scott;- user 생성 확인
select username from dba_users where username = 'SCOTT';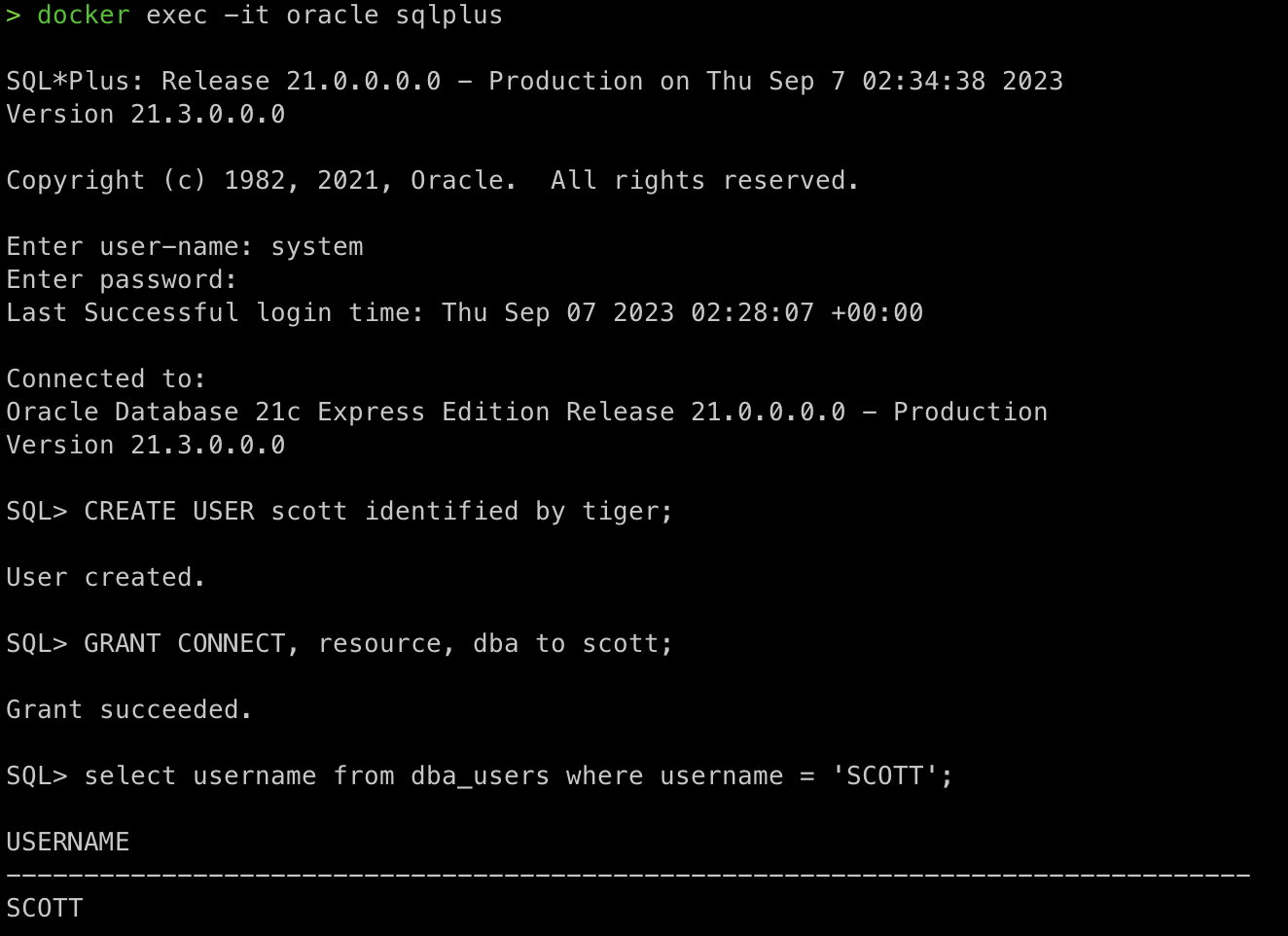
- sqlplus 접속 :
-
8) SCOTT 접속
ctrl + d: 접속 끊기- 다시 sqlplus 재접속
- username : scott
- password : tiger
📖 참고 📖 재시작후 데이터가 사라지는 경우
- (기존 명령어) 새로운 컨테이너 생성 :
docker run -e ORACLE_PASSWORD=pass -p 1521:1521 -d gvenzl/oracle-xe- 종료된 컨테이너 목록 확인 :
docker ps -a
- 컨테이너 실행 :
docker start 컨테이너 이름/컨테이너 ID➡️docker start oracle- 컨테이너 이름 설정해서 띄우기 : `docker run --restart unless-stopped --name oracle -e ORACLE_PASSWORD=pass -p 1521:1521 -d gvenzl/oracle-xe
📕 SQL 문법
1. SELECT절, WHERE절
- 1) 테이블에서 특정 열(COLUMN) 선택
- select 컬럼명
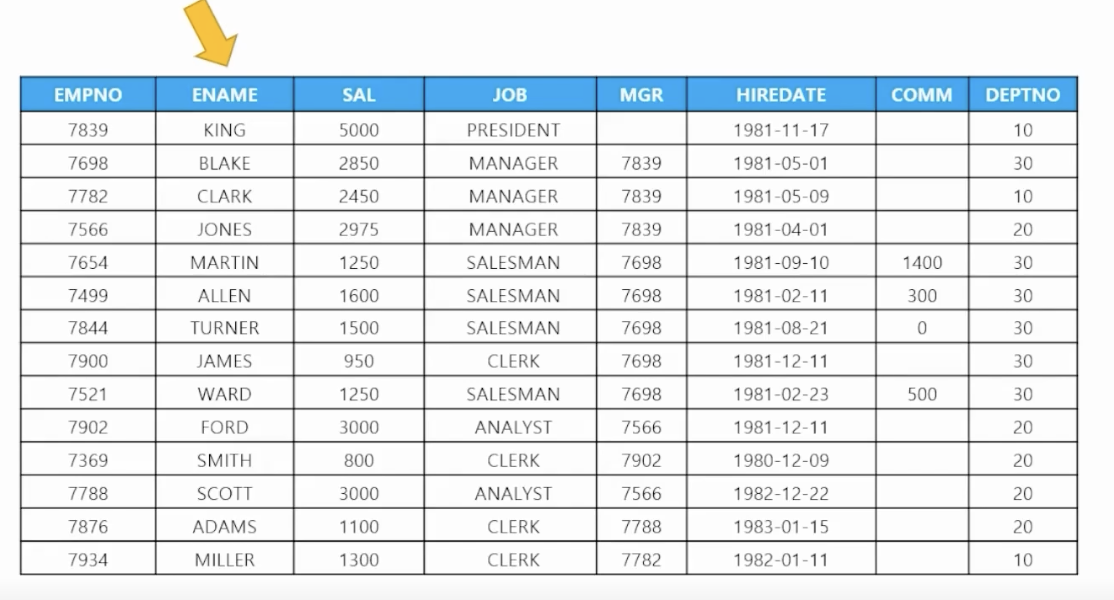
from 테이블명 - 🗒️ 예시 : 사원 테이블
- EMPNO : 사원 번호
- ENAME : 사원 이름
- SAL : 월급
- JOB : 직업
- MGR : 관리자 번호
- HIREDATE : 입사일
- COMM : 커미션
- DEPTNO : 부서 번호
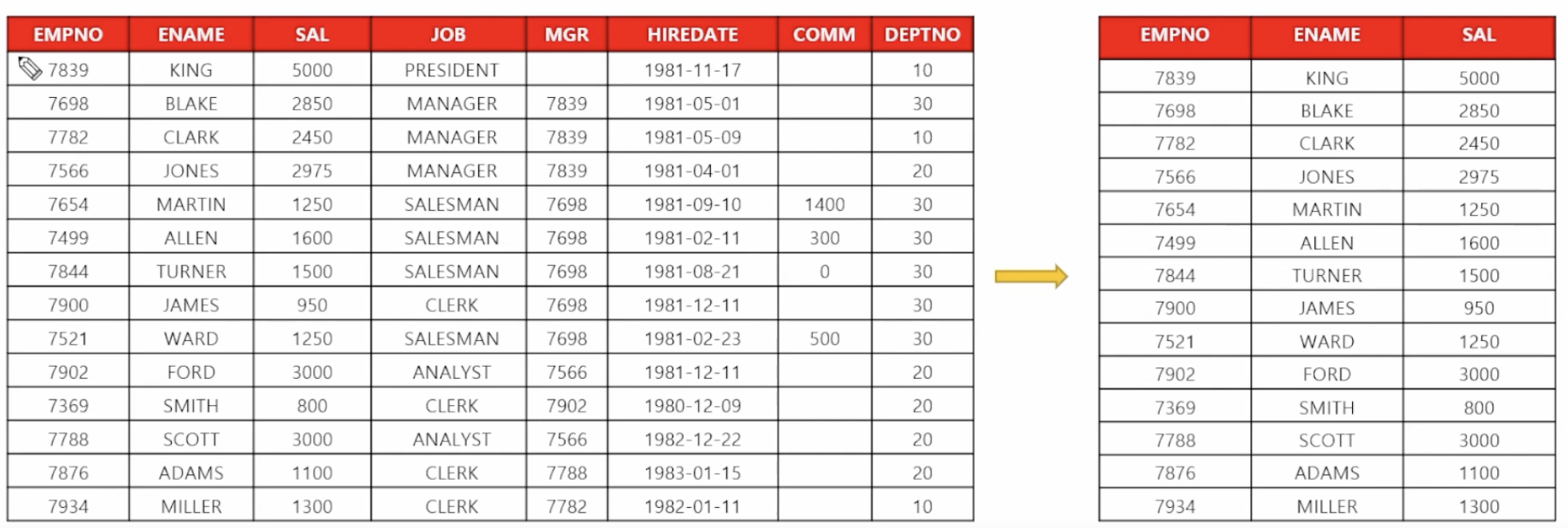
- select 컬럼명
//스크립트 데이터 추가
alter session set nls_Date_format='RR/MM/DD';
drop table emp;
drop table dept;
CREATE TABLE DEPT
(DEPTNO number(10),
DNAME VARCHAR2(14),
LOC VARCHAR2(13) );
INSERT INTO DEPT VALUES (10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT VALUES (20, 'RESEARCH', 'DALLAS');
INSERT INTO DEPT VALUES (30, 'SALES', 'CHICAGO');
INSERT INTO DEPT VALUES (40, 'OPERATIONS', 'BOSTON');
CREATE TABLE EMP (
EMPNO NUMBER(4) NOT NULL,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4) ,
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2) );
INSERT INTO EMP VALUES (7839,'KING','PRESIDENT',NULL,'81-11-17',5000,NULL,10);
INSERT INTO EMP VALUES (7698,'BLAKE','MANAGER',7839,'81-05-01',2850,NULL,30);
INSERT INTO EMP VALUES (7782,'CLARK','MANAGER',7839,'81-05-09',2450,NULL,10);
INSERT INTO EMP VALUES (7566,'JONES','MANAGER',7839,'81-04-01',2975,NULL,20);
INSERT INTO EMP VALUES (7654,'MARTIN','SALESMAN',7698,'81-09-10',1250,1400,30);
INSERT INTO EMP VALUES (7499,'ALLEN','SALESMAN',7698,'81-02-11',1600,300,30);
INSERT INTO EMP VALUES (7844,'TURNER','SALESMAN',7698,'81-08-21',1500,0,30);
INSERT INTO EMP VALUES (7900,'JAMES','CLERK',7698,'81-12-11',950,NULL,30);
INSERT INTO EMP VALUES (7521,'WARD','SALESMAN',7698,'81-02-23',1250,500,30);
INSERT INTO EMP VALUES (7902,'FORD','ANALYST',7566,'81-12-11',3000,NULL,20);
INSERT INTO EMP VALUES (7369,'SMITH','CLERK',7902,'80-12-09',800,NULL,20);
INSERT INTO EMP VALUES (7788,'SCOTT','ANALYST',7566,'82-12-22',3000,NULL,20);
INSERT INTO EMP VALUES (7876,'ADAMS','CLERK',7788,'83-01-15',1100,NULL,20);
INSERT INTO EMP VALUES (7934,'MILLER','CLERK',7782,'82-01-11',1300,NULL,10);
commit;-
📋 문제 1) 사원 테이블에서 사원 번호와 이름과 월급을 출력하세요
select empno, ename, sal from emp; -
📋 문제 2) 사원 테이블에서 사원 이름과 직업과 부서번호를 출력하세요
select ename, job, depno from emp; -
📋 문제 3) 사원 테이블의 모든 열과 데이터를 출력하세요
select * from emp; -
📋 문제 4) 부서테이블의 모든 열과 데이터를 출력하세요
select * from dept; -
2) 컬럼 별칭을 사용하여 출력되는 컬럼명 변경
- select 컬럼명
as 별칭
from 테이블명as (alias): 컬럼명을 변경할 때 쓰는 예약어 문법- select절에서 작성한 alias는 order by절을 제외한 다른 절에서는 사용 불가
"" (더블 쿼테이션 마크): 표기하고 싶은 문자열 그대로를 나타내기 위해 사용 (공백, _(언더바), 대소문자 필수)
- 🗒️ 예상 결과
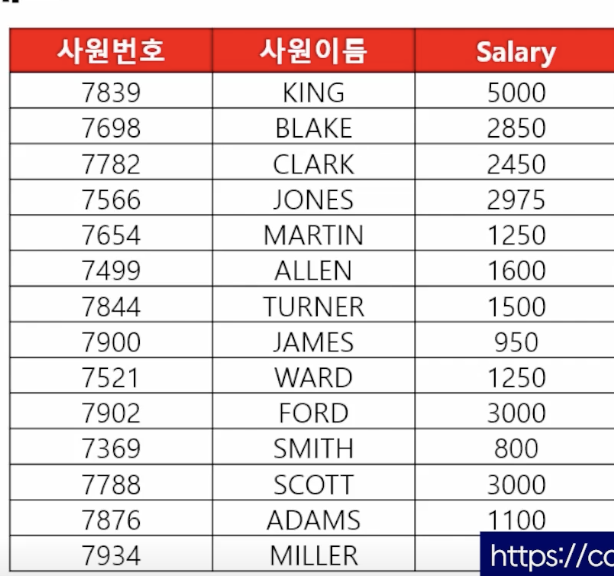
- 📋 문제 1) 사원 테이블의 사원번호와 이름과 월급을 출력하는데 컬럼명이 (사원번호, 사원이름, Salary)로 출력되게 하세요
select empno as 사원번호, ename as 사원이름, sal as "Salary" from emp; - 📋 문제 2) 이름과 직업을 출력하는데 컬럼명이 한글로 이름, 직업으로 출력되도록 하세요
select ename as 이름, job as 직업 from emp;
- select 컬럼명
-
3) 연결 연산자 사용 (||)
- select
컬럼 || 컬럼
from 테이블명|| (수직바)'' (싱글 쿼테이션 마크): 더블과 싱글을 혼용할 경우 더블 안에 싱글 사용
- 🗒️ 예상 결과
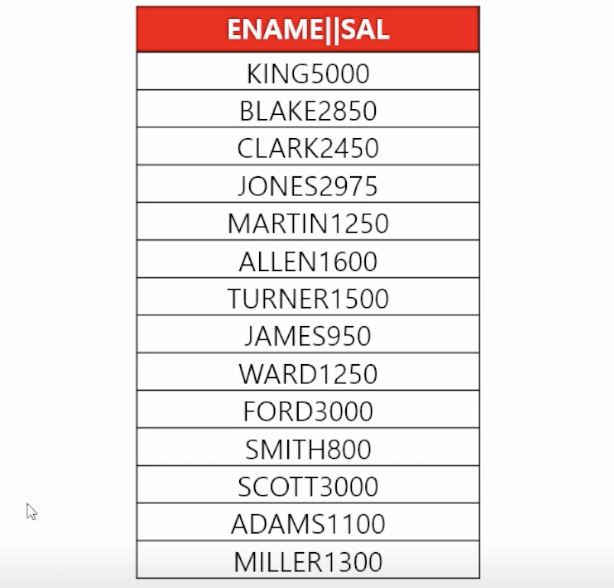
- 📋 문제 1) 사원 테이블에서 이름과 월급을 서로 붙여서 출력해보세요
select ename || sal from emp; - 📋 문제 2) 사원 테이블에서 이름과 직업을 서로 붙여서 'KING의 직업은 PRESIDENT 입니다' 문장으로 출력되게 하시오
select ename || '의 직업은 ' || job || ' 입니다' from emp;
- select
-
4) 중복된 데이터 제거해서 출력 (DISTINCT)
- select
distinct컬럼명
from 테이블명 - 🗒️ 예상 결과

- 📋 문제 1) 직업을 출력하는데 중복행을 제거해서 출력하세요
select distinct job from emp; - 📋 문제 2) 부서번호를 출력하는데 중복행을 제거해서 출력하세요
select distinct deptno from emp;
- select
-
5) 데이터를 정렬해서 출력하기 (ORDER BY)
- select 컬럼명
from 테이블명
order by 컬럼명 ASC- ASC (ascending) : 오름차순 (작은것 ➡️ 큰것)
- DESC (descending) : 내림차순 (큰것 ➡️ 작은것)
- 🗒️ 예상 결과
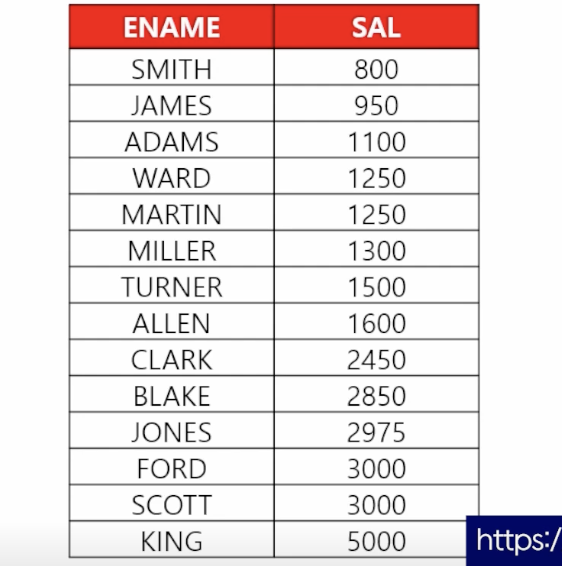
- 📋 문제 1) 이름과 월급을 출력하는데 월급이 낮은 사원부터 높은 사원 순으로 출력하세요
select ename, sal from emp order by sal asc; - 📋 문제 2) 이름과 입사일을 출력하는데 최근에 입사한 사원부터 출력하세요
select ename, hiredata from emp order by hiredata desc;
- select 컬럼명
-
6) WHERE절
- select 컬럼명
from 테이블명
where 조건- where 절 : 조건을 작성하여 해당 조건에 맞는 데이터만 출력
- 문자/날짜는 ''(싱글 쿼테이션 마크) 필요 (숫자는 필요x)
- 🗒️ 예상 결과

- 📋 문제 1) 월급이 3000인 사람들의 사원 이름, 월급, 직업을 출력하세요
select ename, sal, job from emp where sal = 3000; - 📋 문제 2) 사원번호가 7788번인 사원의 사원번호와 사원이름과 월급을 출력하세요
select empno, ename, sal from emp where ename = 7788; - 🗒️ 예상 결과
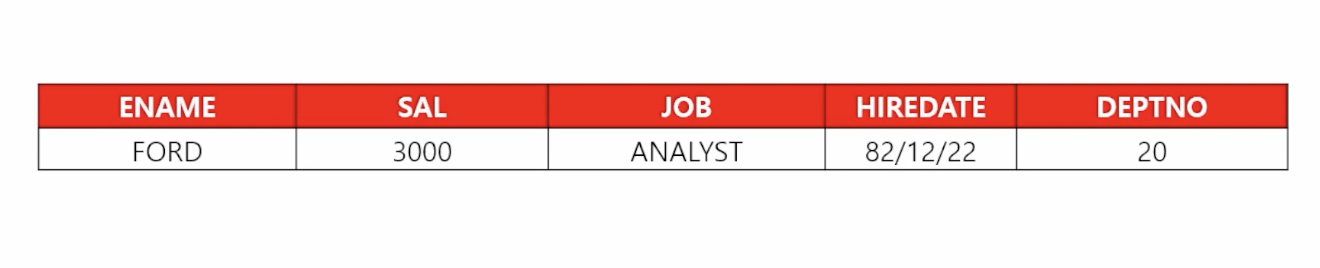
- 📋 문제 3) 이름이 SCOTT인 사원의 이름, 월급, 직업, 입사일, 부서번호를 출력하세요
select ename, sal, job, hiredata, deptno from emp where ename = 'SCOTT'; - 📋 문제 4) 직업이 SALESMAN인 사원들의 이름과 직업과 입사일을 출력하세요
select ename, job, hiredata from emp where job = 'SALESMAN'; - 📋 문제 5) 81/11/17에 입사한 사원의 이름과 입사일을 출력하세요
select ename, hiredate from emp where hiredate = '81/11/17';
- select 컬럼명
-
7) 산술 연산자 (+, -, *, /)
- 🗒️ 예상 결과
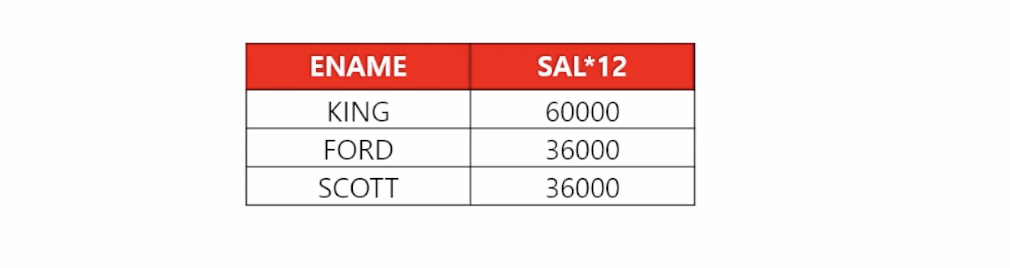
- 📋 문제 1) 연봉이 36000 이상인 사원들의 이름과 연봉을 출력하세요 (연봉은 월급의 12배로 출력)
select ename, sal * 12 as 연봉 from emp where sal * 12 >= 36000; - 📋 문제 2) 직업이 ANALYST인 사원들의 이름과 연봉을 출력하세요
select ename, sal * 12 as 연봉 from emp where job = 'ANALYST';
- 🗒️ 예상 결과
-
8) 비교 연산자 (<, <=, >, >=, =, !=, <>, ^=)
- (not) between .. and
- (not) like
- % (wild card) : %의 위치에 따라 어떤 문자열이든 개수에 관계없이 출력
- _ (under bar) : _의 위치에 따라 어떤 문자열이 1개 출력
- (not) in
- is (not) null
- null값과 비교연산자는 연산 불가능 (컬럼명 = null로는 찾을 수 없음)
- null : 데이터가 없는 상태, 알 수 없는 값
- 🗒️ 예상 결과
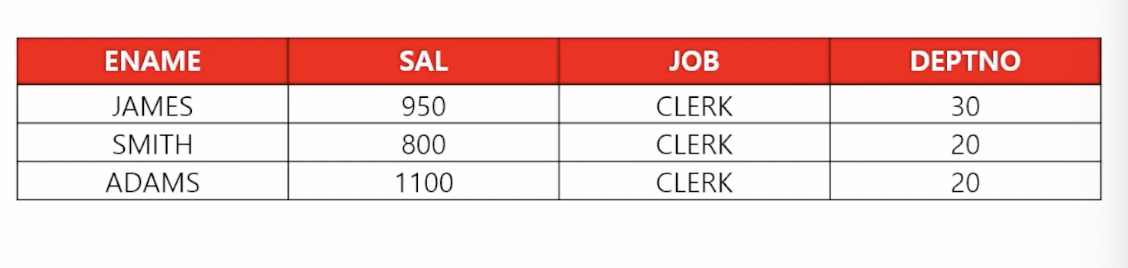
- 📋 문제 1) 월급이 1200 이하인 사원들의 이름, 월급, 직업, 부서번호를 출력하세요
select ename, sal, job, deptno from emp where sal <= 1200; - 📋 문제 2) 직업이 SALESMAN이 아닌 사원들의 이름과 직업을 출력하세요
select ename, job from emp where job != 'SALESMAN'; - 📋 문제 3) 월급이 1000에서 3000 사이인 사원들의 이름과 월급을 출력하세요
select ename, sal from emp where sal between 1000 and 3000; // where sal >= 1000 and sal <= 3000; - 📋 문제 4) 월급이 1000에서 3000 사이가 아닌 사원들의 이름과 월급을 출력하세요
select ename, sal from emp where sal not between 1000 and 3000; // where sal < 1000 or sal > 3000; - 📋 문제 5) 1981년 11월 01 부터 1982년 05월 30일 사이에 입사한 사원들의 이름과 입사일을 출력하세요
select ename, hiredate from emp where hiredate between '81/11/01' and '82/05/30'; - 📋 문제 6) 이름의 첫글자가 S로 시작하는 사원들의 이름을 출력하세요
select ename from emp where ename like 'S%'; - 📋 문제 7) 이름의 끝글자가 T로 끝나는 사원들의 이름을 출력하세요
select ename from emp where ename like '%T'; - 📋 문제 8) 이름의 두번째 철자가 M인 사원들의 이름을 출력하세요
select ename from emp where ename like '_M_%; - 📋 문제 9) 커미션이 null인 사원들의 이름과 커미션을 출력하세요
select ename, comm from emp where comm is null; - 📋 문제 10) 커미션이 null이 아닌 사원들의 이름과 커미션을 출력하세요
select ename, comm from emp where comm is not null; - 📋 문제 11) 직업이 SALESMAN, ANALYST, MANAGER인 사원들의 이름과 월급과 직업을 출력하세요
select ename, sal, job from emp where job in ('SALESMAN, ANALYST, MANAGER'); - 📋 문제 12) 직업이 SALESMAN, ANALYST, MANAGER가 아닌 사원들의 이름과 월급과 직업을 출력하세요
select ename, sal, job from emp where job not in ('SALESMAN, ANALYST, MANAGER');
-
9) 논리 연산자 (AND, OR, NOT)
- 🗒️ 예상 결과
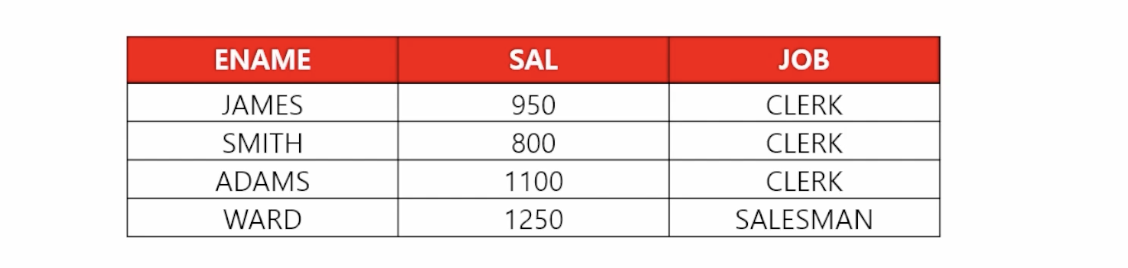
- 📋 문제 1) 직업이 SALESMAN이고, 월급이 1200 이상인 사원들의 이름과 월급과 직업을 출력하세요
select ename, sal, job from emp where job = 'SALESMAN' and sal >= 1200; - 📋 문제 2) 부서번호가 30번이고, 커미션이 100 이상인 사원들의 이름과 월급과 커미션을 출력하세요
select ename, sal, comm from emp where deptno = 30 and comm >= 100;
- 🗒️ 예상 결과
📖 참고 📖
- ✏️ * (asterisk) : 모든 정보 가리킴
- ✏️ 대소문자
- sql은 대소문자 구분X
- 데이터는 대소문자 구분O (정확히 일치 해야함)
- ✏️ 순서
- 쿼리 실행 순서 : from ➡️ where ➡️ select
- 코딩 순서 : select ➡️ from ➡️ where
2. 함수

- 1) 문자 함수
-
문자 변환
- upper(컬럼명/"문자열") : 대문자 변환
- lower(컬럼명/"문자열") : 소문자 변환
- initcap(컬럼명/"문자열") : 첫번째 문자만 대문자, 그 외 소문자 변환
-
문자에서 특정 철자 추출
- substr(컬럼명/"문자열", 시작 철자 위치, 잘라낼 문자의 개수)
-
문자열 길이 출력
- length(컬럼명)
-
문자에서 특정 철자의 위치 출력하기
- instr (컬럼명/"문자열", "검색할 문자열")
-
특정 절차를 다른 절차로 변경
- replace (컬럼명/"문자열", "기존 문자열", "변경 문자열")
-
특정 철자를 N개 만큼 채우기
- lpad(컬럼명, 출력 길이, "채워넣을 문자열")
- rpad(컬럼명, 출력 길이, "채워넣을 문자열")
-
특정 절차 잘라내기
- ltrim(컬럼명/"문자열", "잘라낼 문자열")
- rtrim(컬럼명/"문자열", "잘라낼 문자열")
- trim("잘라낼 문자열" from 컬럼명/"문자열")
- 잘라낼 문자열 입력하지 않을 경우, 기본값으로 공백 제거
-
문자열 연결
- concat(문자열, 문자열)
-
🗒️ 예상 결과
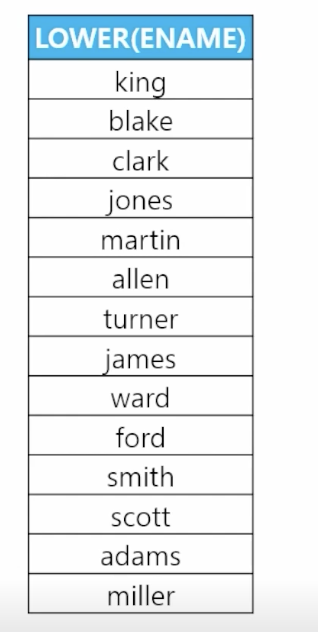
-
📋 문제 1) 사원 테이블에서 이름을 출력하는데 모두 소문자로 출력하세요
select lower(ename) from emp; -
📋 문제 2) 이름이 scott인 사원의 이름과 월급을 출력하는데 이름을 소문자로 검색해도 결과가 출력되게 하세요
select ename, sal from emp; where lower(ename) = 'scott'; -
📋 문제 3) SMITH라는 단어에서 MI만 추출해서 출력하세요
select substr('SMITH', 2, 2) from dual; // 단어 1개만 처리할 때 -
📋 문제 4) 사원 테이블에서 이름을 출력하는데 이름의 첫글자만 출력하고 첫글자를 소문자로 출력하세요
select lower(substr(ename, 1, 1)) from emp; -
📋 문제 5) 이름을 출력하고 이름의 철자의 길이를 출력하세요
select ename, length(ename) from emp; -
📋 문제 6) 이름의 철자의 길이가 5개 이상인 사원들의 이름과 이름의 철자의 길이를 출력하세요
select ename, length(ename) from emp where length(ename) >= 5; -
📋 문제 7) SMITH이라는 단어에서 알파벳 M이 몇번째 자리에 있는지 출력하세요
select instr('SMITH', 'M') from dual; -
📋 문제 8) 이름에 철자 S가 포함된 사원들의 이름을 출력하세요
select ename from emp where instr(ename, 'S') > 0; -
📋 문제 9) 이름과 월급을 출력하는데 월급의 숫자 0을 *로 출력하세요
select ename, replace(sal, 0, '*'); from emp; -
📋 문제 10) 이름과 월급을 출력하는데 숫자 0번부터 3번까지는 *로 출력하세요
select ename, regexp_replace(sal, '[0-3]', '*') from emp; -
🗒️ 예상 결과
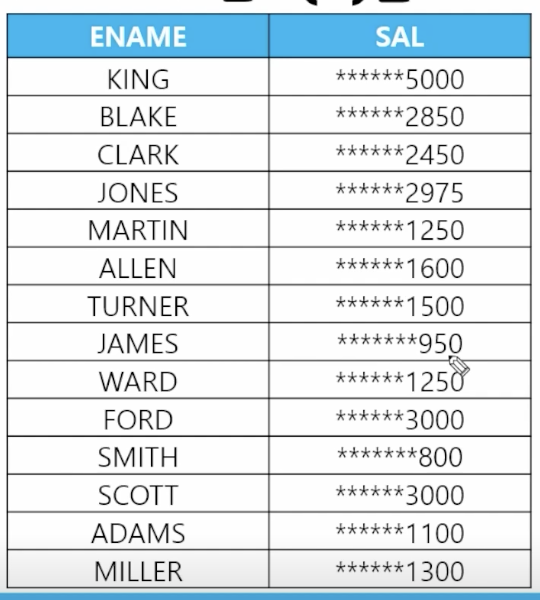
-
📋 문제 11) 이름과 월급을 출력하는데 월급 컬럼의 자릿수를 10자리로 하고, 월급을 출력하고 남은 나머지 자리 왼쪽에 별표(*)를 채워서 출력해보세요
select ename, lpad(sal, 10, '*') frome emp; -
📋 문제 12) 이름과 월급을 출력하는데 월급 컬럼의 자릿수를 10자리로 하고, 월급을 출력하고 남은 나머지 자리 오른쪽에 별표(*)를 채워서 출력해보세요
select ename, rpad(sal, 10, '*') from emp; -
📋 문제 13) smith 영어단어에서 앞에 s를 잘라내서 출력하고 뒤에 h를 잘라서 출력하고 양쪽 s를 잘라서 출력하세요
select 'smith', ltrim('smith', 's'), rtrim('simth', 'h'), trim('s' from 'smith') from dual; -
📋 문제 14) 다음의 데이터를 사원 테이블에 입력하고 이름이 JACK인 사원의 이름과 월급을 출력하세요
insert into emp(empno, ename, sal) values(3821, 'JACK ', 3000); commit; select ename, sal from emp where rtrim(ename) = 'JACK';
-
📖 참고 📖
- ✏️ from dual
- 가상의 테이블 환경을 구성하여 질의문의 결과 확인
- 함수로 실행되는 하나의 결과값을 보기위한 가상의 테이블
- ✏️ regexp_ (regular expression)
- 정규식 표현
- regexp_ 뒤에 사용할 함수명을 입력 후 원하는 값 출력
- SQL의 기본 함수보다 넓은 범위로 함수를 적용할 때 사용
- ✏️ insert 문
- insert into 테이블명(컬럼명1, 컬럼명2, ...) values(데이터1, 데이터2, ...)
- DML 문장으로 테이블에 데이터를 추가할 때 사용하는 명령문
- ✏️ commit 명령어 : 테이블에 변경이 생겼을 경우 해당 작업을 확정짓는 명령어
- 2) 숫자 함수
- round(데이터, 자릿수) : 반올림해서 출력
- 자릿수는 소수 부분이 양의 정수, 정수 부분이 음의 정수로 되어있음 (소수점 기준)
- 자릿수를 입력하지 않으면 기본값으로 정수부분까지만 출력
- trunc(데이터, 자릿수) : 숫자 버리고 출력
- 자릿수는 잘라낸 뒤 남겨놓을 자리 값 작성
- mod : 나눗셈한 나머지 값 출력
- 🗒️ 예상 결과

- 📋 문제 1) 876.567 숫자를 출력하는데 소수점 두번째 자리인 6에서 반올림해서 출력하세요
select round(876.567, 1) from dual; - 📋 문제 2) 사원 테이블에서 이름과 월급의 12%을 출력하는데 소수점 이하는 출력되지 않도록 반올림하세요
select ename, round(sal * 0.12) from emp; - 📋 문제 3) 876.567 숫자를 출력하는데 소수점 두번째 자리인 6과 그 이후의 숫자들을 모두 버리고 출력하세요
select trunc('76.567, 1); from dual; - 📋 문제 4) 사원 테이블에서 이름과 월급의 12%을 출력하는데 소수점 이하는 출력되지 말고 버리세요
select ename, trunc(sal * 0.12) from emp; - 📋 문제 5) 숫자 10을 3으로 나눈 나머지 값을 출력하세요
select mod(10, 3) from dual; - 📋 문제 6) 사원번호가 홀수인 사원들의 사원번호와 이름을 출력하세요
select empno, ename from emp where mod(empno, 2) = 1;
- round(데이터, 자릿수) : 반올림해서 출력
- 3) 날짜 함수
- months_between(최신 날짜, 옛날 날짜) : 날짜간 개월 수 출력
- add_months(기준 날짜, 구하고 싶은 기간) : 개월 수 더한 날짜 출력
- next_day(기준 날짜, 구하고 싶은 요일) : 특정 날짜 뒤에 오는 요일 날짜 출력
- last_day(기준 날짜) : 특정 날짜가 있는 달의 마지막 날짜 출력
- 🗒️ 예상 결과
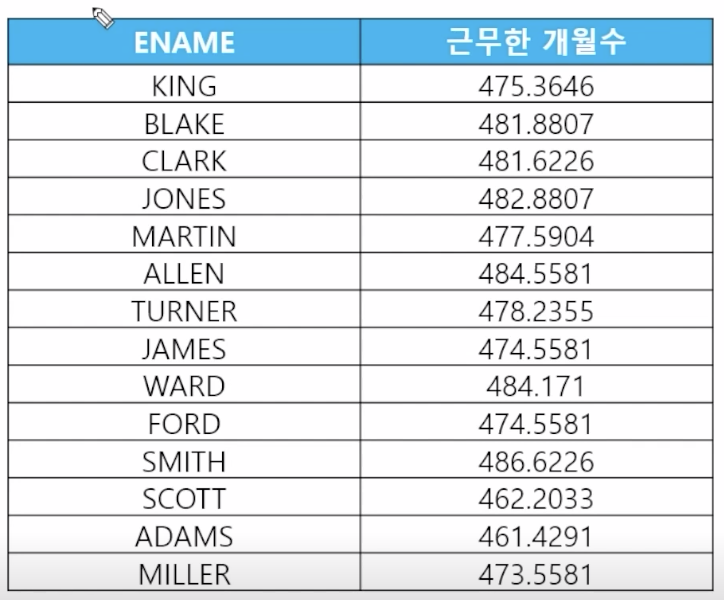
- 📋 문제 1) 이름을 출력하고 입사한 날짜부터 오늘까지 총 몇 달을 근무했는지 출력해보세요
select ename, months_between(sysdate, hiredate) from emp; - 📋 문제 2) 내가 태어난 날부터 오늘까지 총 몇달인지 출력하세요
select round(months_between(sysdate, '1997/04/24')) from dual; - 📋 문제 3) 2019년 5월 1일부터 100달 뒤의 날짜는 어떻게 되는지 출력
select add_months('2019/05/01', 100) from dual; - 📋 문제 4) 오늘부터 100달 뒤의 날짜가 어떻게 되는지 출력하세요
select add_months(sysdate, 100) from dual; - 📋 문제 5) 2021년 5월 5일로 부터 바로 돌아오는 월요일의 날짜가 어떻게 되는지 출력해보세요
select next_day('2021/05/05', '월요일') from dual; - 📋 문제 6) 오늘부터 앞으로 돌아올 금요일의 날짜가 어떻게 되는지 출력하세요
select next_day(sysdate, '금요일') from dual; - 📋 문제 7) 2021년 5월 5일 해당 달의 마지막 날짜를 출력하세요
select last_day('2021/05/05') from dual; - 📋 문제 8) 오늘부터 요번 달 말일까지 총 몇일 남았는지 출력하세요
select last_day(sysdate) from dual;
📖 참고 📖
- ✏️ sysdate
- 오늘 날짜 출력
select sysdate from dual;- ✏️ delete from 테이블명 where 조건
- DML문으로 테이블에 조건에 맞는 행 삭제
delete from emp where trim(ename) = 'JACK'; commit;
- 4) 변환 함수
- to_char(날짜/숫자 컬럼명, '날짜/숫자 포맷') : 문자형으로 데이터 유형 변환
- 날짜형 -> 문자형
- 날짜 포맷 : (년도) RRRR, YYYY, RR, YY, (달) MON, MM, (일) DD, (요일) DAY, DY
- 숫자형 -> 문자형
- 숫자 포맷 : '999,999' (천단위 표시)
- to_number(문자 컬럼명) : 문자를 숫자형으로 데이터 유형 변환
- to_date('날짜', '날짜의 형식') : 날짜형으로 데이터 유형 변환하기
- 🗒️ 예상 결과

- 📋 문제 1) 이름이 SCOTT인 사원의 입사한 요일과 월급을 출력하는데 월급을 출력할 때에 다음과 같이 천단위를 표시해서 출력하세요
select ename, to_char(hiredate, 'day'), to_chat(sal, '999,999') from emp where ename='SCOTT'; - 📋 문제 2) 수요일에 입사한 사원들의 이름과 입사일과 입사한 요일을 출력하세요
select ename, hiredate , to_char(hiredate, 'day') from emp; where to_char(hiredate, 'day') = '수요일'; - 📋 문제 3) 내가 태어날 생일의 요일을 출력하세요
select to_char(to_date('1997/04/24', 'YYYY/MM/DD'), 'day') from dual; - 📋 문제 4) 81년 11월 17일에 입사한 사원의 이름과 입사일을 출력하세요
select ename, hiredate from emp where hiredate = '81/11/17'; // where hiredate = to_date('81/11/17', 'RR/MM/DD'); - 📋 문제 5) 1981년도에 입사한 사원들의 이름과 입사일을 출력하는데 최근에 입사한 사원부터 출력하세요
select ename, hiredate from emp where hiredate between to_date('1981/01/01', 'RRRR/MM/DD') and to_date('1981/12/31', 'RRRR/MM/DD') + 1; oreder by hiredate desc;
- to_char(날짜/숫자 컬럼명, '날짜/숫자 포맷') : 문자형으로 데이터 유형 변환
📖 참고 📖
- ✏️ 현재 세션의 날짜 형식 확인
select * from nls_session_parameters;
- ✏️ 현재 세션의 날짜 형식 변경
alter session set nsl_date_format='DD/MM/RR';
- ✏️ 암시적 형 변환
- Oracle DB에서 조건절의 데이터를 확인 후 자동으로 형 변환 시행
- 쿼리문 실행 될까? ➡️ 실행O
select ename, sal from emp where sal = '3000'; // 숫자 != 문자, 숫자가 문자보다 우선순위 높아서 문자를 숫자로 변경- ✏️ Query 실행 계획
- explain plan for ~ from table(dbms_xplan.display)
- 질의문이 실행되는 순서와 정보 출력
explain plan for select ename, sal from emp where sal = '3000'; select * from table(dbms_xplan.display);
- 쿼리문 실행 될까? ➡️ 실행O
select ename, sal from emp where sal like '30%; // 숫자 != 문자, %가 있어서 문자 변경 못하니 숫자를 문자로 변경
- 5) 일반 함수
-
nvl(컬럼명, 변경값)
- NULL 값 대신 다른 값으로 치환하여 출력 (Null VaLue 함수)
- 데이터에 NULL 값 존재하는 경우 : 연산자를 이용한 결과를 출력할 때 null 값으로 출력
- 기존 데이터와 치환할 데이터 형이 다른 경우 : 기존의 데이터 형이 변경될 데이터의 형태를 인식하지 못하여 에러 발생
-
decode(컬럼명, 조건1, 변경값1,, 조건2, 변경값2, ..., 나머지 값)
- IF문을 SQL로 구현하기
- = (eqal 비교만 가능)
-
case when 컬럼명 조건1 then 변경값1 when 컬럼명 조건2 then 변경값2 ... else 나머지값 end
- IF문을 SQL로 구현하기
- = 및 >, < (부등호 비교 가능_
-
🗒️ 예상 결과
-
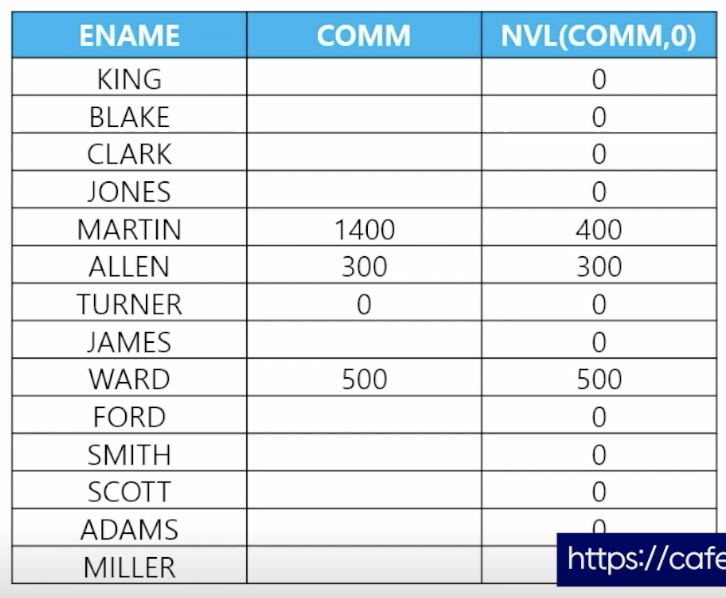
📋 문제 1) 이름과 월급과 커미션을 출력하는데 커미션이 null인 사원들은 값을 0으로 출력하세요
select ename, sal, nvl(comm, 0) from emp; -
📋 문제 2) 이름과 커미션을 출력하는데 커미션이 null인 사원들은 no comm 이라는 글씨로 출력하세요
select ename, nvl(comm, 'no comm') // 에러 발생 from emp; select ename, nvl(to_char(comm), 'no comm') // 문자열로 수정 -
📋 문제 3) 이름, 부서번호, 보너스를 출력하는데 보너스가 부서번호가 10번이면 300, 부서번호가 20번이면 400, 나머지 부서번호는 0을 출력하세요
select ename, deptno, decode(deptno, 10, 300, 20, 40, 0) as 보너스 from emp; -
📋 문제 4) 이름, 직업, 보너스를 출력하는데 작업이 SALESMAN이면 6000을 출력하고 직업이 ANALYST면 3000을 출력하고 직업이 MANAGER면 2000을 출력하고 나머지 직업은 0을 출력되게 하시오
select ename, job, decode(job, 'SALESMAN', 6000, 'ANALYST', 3000, 'MANAGER', 2000, 0) as 보너스 from emp; -
📋 문제 5) 직업이 SALESMAN, ANALYST인 사원들의 이름, 직업, 월급, 보너스를 출력하는데 월급이 3000이상이면 보너스를 500을 출력하고 월급이 2000 이상이면 보너스를 300을 출력하고 월급이 1000 이상이면 보너스를 200을 출력하고 나머지를 0을 출력하세요
select ename, job, sal, case when sal >= 3000 then 500 when sal >= 2000 then 300 when sal >= 1000 then 200 else 0 end as 보너스 from emp where job in ('SALESMAN', 'ANALYST'); -
📋 문제 6) 이름, 월급, 보너스를 출력하는데 월급이 3000 이상이면 보너스를 9000을 출력하고 월급이 2000 이상이면 (2000 이상이면서 3000 보다 작으면) 8000을 출력하고 나머지 (2000보다 작은 사원들)는 0을 출력하시오
select ename, sal, case when sal >= 3000 then 9000 when sal >= 2000 then 8000 else 0 end as 보너스 from emp;
-
📖 참고 📖 조건절 + group by 컬럼명
- 단일 함수 + 다중 함수 출력
- 그룹함수 연산 통해 1개의 값/그룹별로 출력하려면, 결과가 나오기 위해서는 그룹으로 묶기
- group by + where절 사용X (having절 사용)
- 그룹함수는 NULL 값을 무시함
-
6) 최대값 (max 컬럼명)
- 🗒️ 예상 결과

- 📋 문제 1) 사원 테이블에서 최대 월급을 출력하세요
select max(sal) from emp; - 📋 문제 2) 직업이 SALESMAN인 사원들 중에서의 최대 월급을 출력하세요
select max(sal) from emp where job = 'SALESMAN'; - 📋 문제 3) 직업이 SALESMAN인 사원들 중에서의 최대 월급을 출력하는데 아래와 같이 직업도 같이 출력하시오
select max(sal), job from emp where job = 'SALESMAN' group by job;
- 🗒️ 예상 결과
-
7) 최소값 (min)
- 🗒️ 예상 결과

- 📋 문제 1) 직업이 SALESMAN인 사원들 중에서 최소 월급을 출력하세요
select min(sal) from emp where job = 'SALESMAN'; - 📋 문제 2) 부서번호가 20번인 사원들 중에서 최소월급을 출력하세요
select min(sal) from emp where depto = 20; - 📋 문제 3) 부서번호와 부서번호별 최소월급을 출력하세요
select deptno, min(sal) from emp group by deptno;
- 🗒️ 예상 결과
-
8) 평균값 (avg)
-
🗒️ 예상 결과

-
📋 문제 1) 사원 테이블에서 평균 월급을 출력하세요
select avg(sal) from emp; -
📋 문제 2) 직업과 직업별 평균월급을 출력하는데 직업별 평균월급이 높은 것부터 출력하세요
select job, round(avg(sal)) from emp group by job order by 2 desc; // 2는 컬럼 번호 // alias 사용 select job, round(avg(sal)) as 평균 from emp group by job order by 퍙균 desc; -
📋 문제 3) 부서번호, 부서번호별 평균월급을 출력하는데 부서번호별 평균월급을 출력할 때에 천 단위 표시를 하시오
select deptno, to_char(round(avg(sal)), '999,999') from emp group by deptno;
-
-
9) 합계 (sum)
-
🗒️ 예상 결과
-
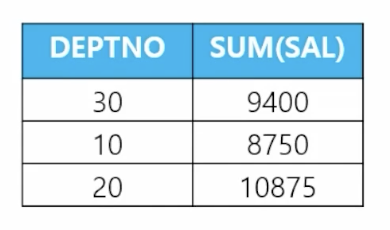
📋 문제 1) 부서번호, 부서번호별 토탈 월급을 출력하세요
sel deptno, sum(sal) from emp group by deptno; -
📋 문제 2) 1981년도에 입사한 사원들의 월급을 토탈값을 출력하세요
select sum(sal) from emp where to_char(hiredate, 'YYYY') = 1981; -
📋 문제 3) 직업과 직업별 토탈월급을 출력하는데 직업별 토탈월급이 6000 이상인 것만 출력하세요
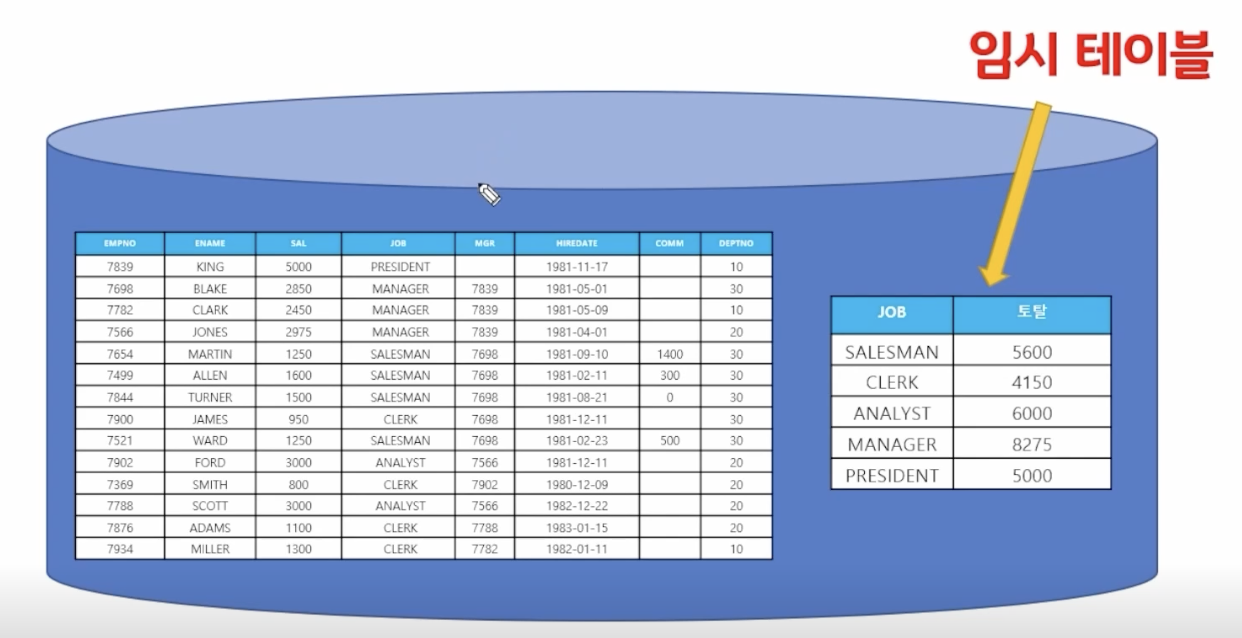
select job, sum(sal) from emp where sum(sal) >= 6000 // 오류 group by job; select job, sum(sal) from emp group by job having sum(sal) >= 6000;
-
-
10) 카운트값 (count)
-
🗒️ 예상 결과

-
📋 문제 1) 사원 테이블의 전체 인원수가 어떻게 되는지 출력하세요
select count(*) from emp; -
📋 문제 2) 부서번호, 부서번호별 인원수를 출력하세요
select deptno, count(*) from emp group by deptno; -
📋 문제 3) 직업과 직업별 인원수를 출력하는데 직업이 SALESMAN은 제외하고 출력하고 직업별 인원수가 3명 이상인 것만 출력하세요
select job, count(*) from emp group by job having job != 'SALESMAN' and count(*) >= 3 // 맞긴 하지만 수정 필요 // 테이블 데이터를 가져온 다음 where 절로 필커링을 하면 having절로 조건을 주는 것보다 질의문을 효과적으로 구현 가능 select job, count(*) from emp where job != 'SALESMAN' having count(*) >= 3;
-
📖 참고 📖 질의문
- select 컬럼명
- from 테이블명
- where 검색조건
- group by 그룹할 컬럼명
- having 그룹 함수로 검색조건
- order by 정렬할 컬럼명
- 실행 순서
- from ➡️ where ➡️ group by (having) ➡️ select ➡️ order by
3. 데이터 분석 함수
-
1) 순위1 (RANK)
- rank() over (order by 컬럼명 desc)
- 🗒️ 예상 결과
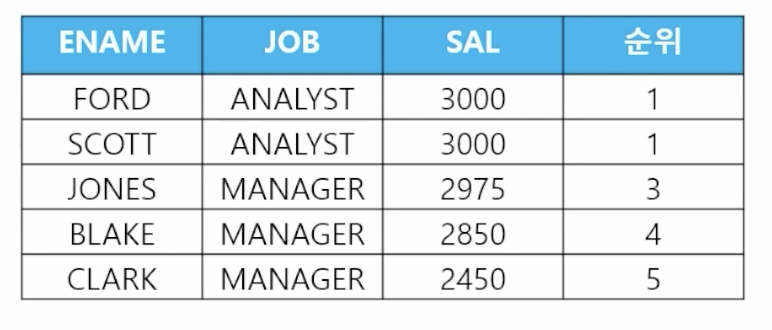
- 📋 문제 1) 직업이 ANALYST, MANAGER인 사람들의 이름, 직업, 월급과 월급에 대한 순위를 출력하세요
select ename, job, sal, rank() over (order by sal desc) 순위 from emp where job in ('ANALYST', 'MANAGER'); - 📋 문제 2) 부서번호가 20번인 사원들의 이름과 부서번호와 월급과 월급에 대한 순위를 출력하세요
select ename, deptno, sal, rank() over (order by sal desc) 순위 from emp where deptno = 20;
-
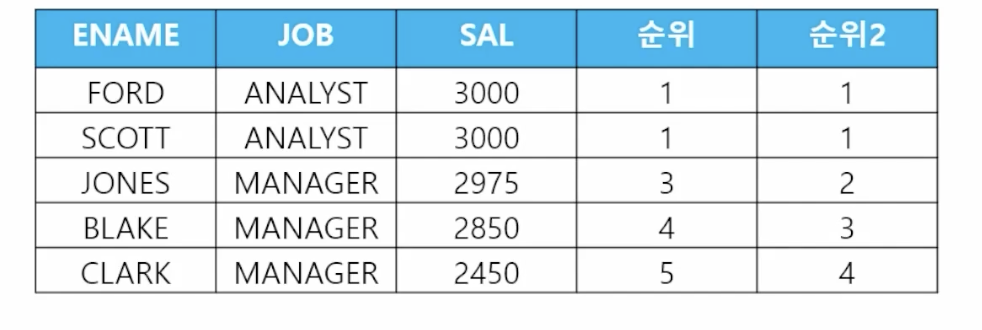
2) 순위2 (DENSE_RANK)
- dense_rank() over (partition by 나눌 기준 컬럼 oreder by 순위 적용할 컬럼)
- dense_rank(기준값) within group (order by 순위 적용할 컬럼)
- withing group 뒤에 rank를 적용한 컬럼에서 dense_rank(기준값)의 순위 출력
- 🗒️ 예상 결과
- 📋 문제 1) 직업이 ANALYST, MANAGER인 사람들의 이름과 직업과 월급과 순위를 출력하는데 그 옆에 순위가 동일한 사람이 여러명인 경우 바로 다음 순위가 출력되게 하시오
select ename, job, sal, dense_rank() over (order by sal desc) 순위 from emp where job in ('ANALYST', 'MANAGER'); - 📋 문제 2) 직업, 이름, 월급, 순위를 출력하는데 순위가 직업별로 각각 월급이 높은 사원순으로 순위를 부여하세요
select job, ename, sal, dense_rank() over (partition by job order by sal desc) 순위 from emp; - 📋 문제 3) 월급이 2975인 사원은 사원 테이블에서 월급의 순위가 몇위인가
select dense_rank(2975) within group (order by sal desc) 순위 from emp;
-
3) 등급 (NTILE)
- ntile(등급 나눌 수) over (order by 기준 컬럼 desc)
- 🗒️ 예상 결과
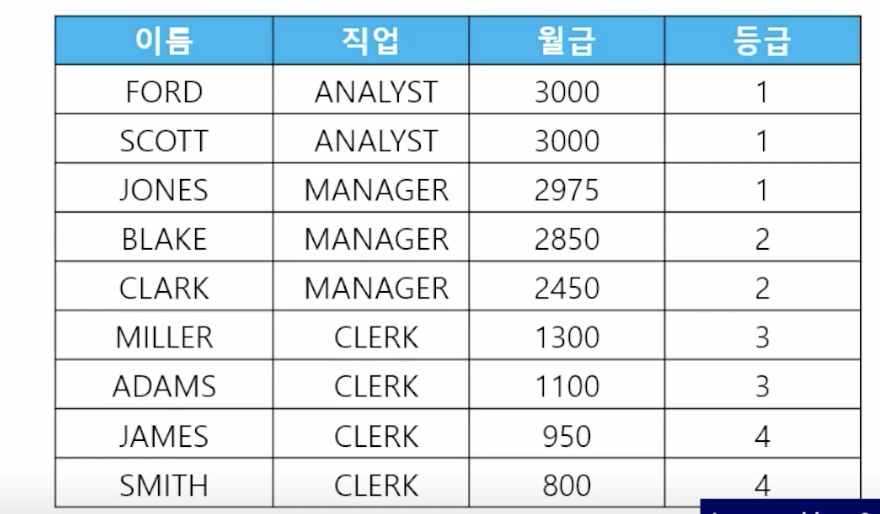
- 📋 문제 1) 직업이 ANALYST, MANAGER, CLERK인 사원들의 이름과 직업과 월급과 등급을 출력하는데 등급을 4등급으로 나눠서 출력하세요
select ename, sal, ntile(4) over (order by sal desc) 등급 from emp where job in ('ANALYST', 'MANAGER', 'CLERK'); - 📋 문제 2) 이름, 입사일, 사원순으로 등급을 나누는데 등급을 5등급으로 나눠서 출력하시오
select ename, hiredate, ntile(5) over (order by hiredate asc) 등급 from emp;
-
4) 순위의 비율 (cume_dist)
- cume_dist() over (partition by 나눌 기준 컬럼 order by 기준 컬럼 desc)
- 🗒️ 예상 결과
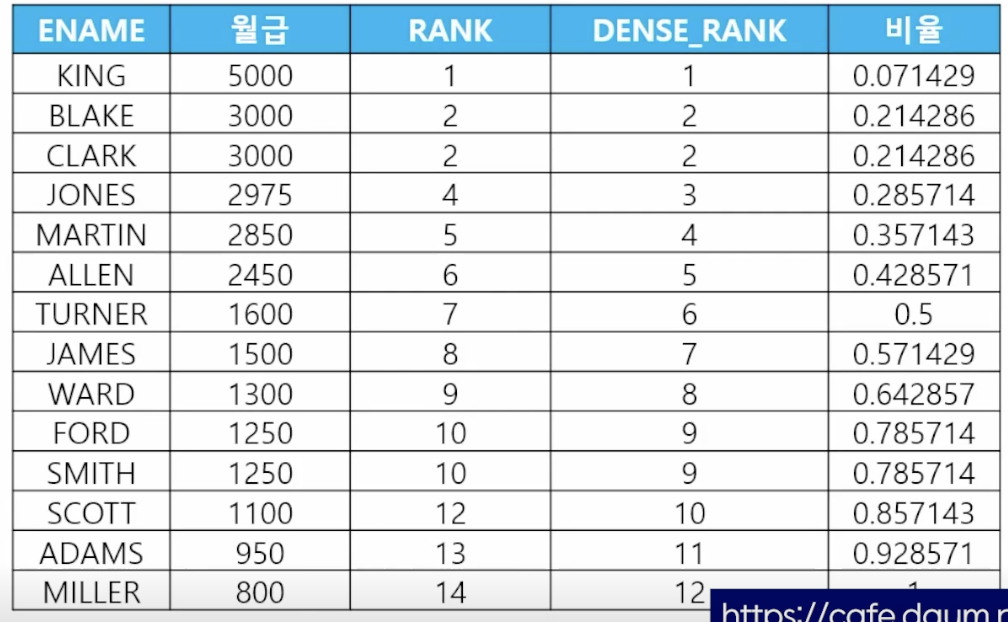
- 📋 문제 1) 이름과 월급과 순위와 자신의 월급의 순위에 대한 비율을 출력하세요
select ename, sal, dense_rank() over (order by sal desc) 순위, cume_dist() over (order by sal desc) 비율 from emp; - 📋 문제 2) 부서번호, 이름과 월급과 월급의 순위에 대한 비율을 출력하세요. 순위 비율이 부서번호별로 각각 출력되게 하시오
select deptno, ename, sal, cume_dist() over (partition by deptno order by sal desc) 비율 from emp;
-
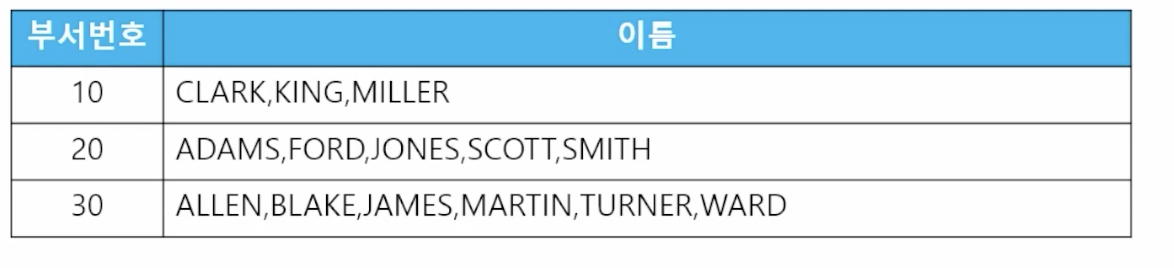
5) 데이터 가로 출력 (listagg)
-
listagg(컬럼명, "구분자") within group (order by 기준 컬럼)
-
🗒️ 예상 결과
-
📋 문제 1) 부서번호를 출력하고 해당 부서번호별로 속한 사원들의 이름을 가로로 출력하세요
select deptno, listagg(ename, ',') withing group (order by ename asc) as 이름 from emp; -
📋 문제 2) 직업, 직업별로 속한 사람들의 이름을 가로로 출력하는데 가로로 출력될 때에 월급이 높은 사원부터 출력되게 하시오
select job, listagg(ename, ',') within group(order by sal desc) as 이름 from emp group by job;
-
-
6) 바로 전 행과 다음 행 출력 (LAG, LEAD)
- lag(컬럼명, 행 번호) over(order by 기준 컬럼)
- lead(컬럼명, 행 번호) over(order by 기준 컬럼)
- 🗒️ 예상 결과
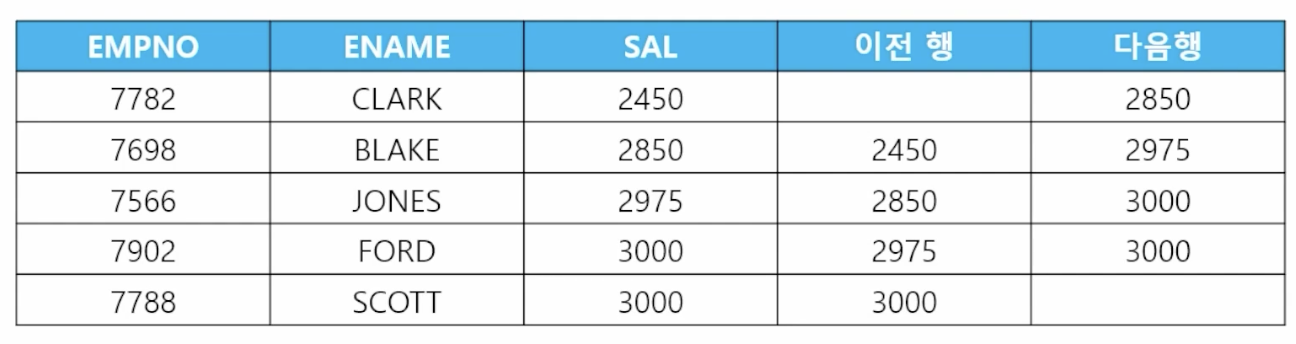
- 📋 문제 1) 직업이 ANALYST, MANAGER인 사원들의 사원번호와 이름과 월급을 출력하는데 다음과 같이 월급의 전행과 그 다음행이 출력되게 하세요
select ename, sal, lag(sal, 1) over(order by sal asc) 이전행, lead(sal, 1) over (order by sal asc) 다음행 from emp where job in ('ANALYST', 'MANAGER'); - 📋 문제 2) 이름, 입사일, 바로 전에 입사한 사원과의 간격일을 출력하세요
select ename, hiredate, hiredate - lag(hiredate, 1) over (order by hiredate asc) 간격일 from emp;
-
7) row를 column으로 출력하기1 (SUM + DECODE)
-
🗒️ 예상 결과
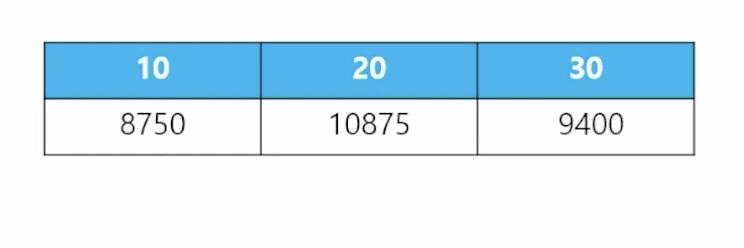
-
📋 문제 1) 부서번호와 부서번호별 토탈 월급을 출력하는데 다음과 같이 가로로 출력하세요
// 세로 출력 select deptno, sum(sal) from emp group by deptno; // 가로 출력 select sum(decode (deptno, 10, sal, null)) as "10", // 0대신 null 사용하기 sum(decode (deptno, 20, sal, null)) as "20", // 안쓸경우 null 입력됨 sum(decode (deptno, 30, sal, null)) as "30", from emp; -
📋 문제 2) 직업, 직업별 토탈 월급을 가로로 출력하세요
// 세로 출력 select job, sum(job) from emp group by job; // 가로 출력 select sum(decode (job, 'ANALYST', sal)) as "ANALYST", sum(decode (job, 'CLERK', sal)) as "CLERK", sum(decode (job, 'MANAGER', sal)) as "MANAGER", sum(decode (job, 'PRESIDENT', sal)) as "PRESIDENT", sum(decode (job, 'SALESMAN', sal)) as "SALESMAN" from emp;
-
-
8) row를 column으로 출력하기2 (PIVOT)
-
pivot(그룹함수 for 기준 컬럼 in (데이터1, 데이터2, ... ))
-
pivot문 다음 select절이 실행 (pivot문의 결과를 출력할 수 있도록 select절에 작성)
-
🗒️ 예상 결과
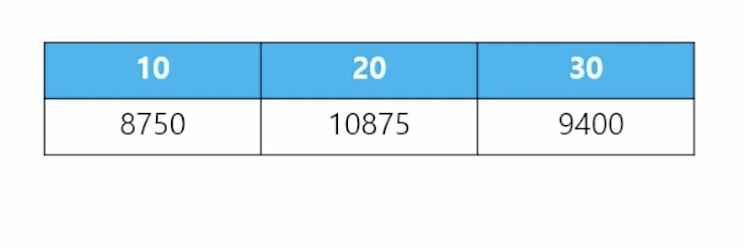
-
📋 문제 1) 부서번호와 부서번호별 토탈 월급을 출력하는데 다음과 같이 가로로 출력하세요
select * from (select dptno, sal, from emp); pivot (sum(sal) for deptno in (10, 20, 30)); -
📋 문제 2) 직업, 직업별 토탈월급을 pivot문을 이용하여 가로로 출력하세요
select * from (select job, sal from emp) pivot (sum(sal) for job in ('ANALYST', 'CLERK', 'MANAGER', 'SALESMAN', 'RRESIDENT')); // 컬럼명에 붙은 작음따옴표 지우는 방법 select * from (select job, sal from emp) pivot (sum(sal) for job in ('ANALYST' as "ANALYST", 'CLERK' as "CLERK", 'MANAGER' as "MANAGER", 'SALESMAN' as "SALESMAN", 'RRESIDENT' as "PRESIDENT"));
-
-
9) column을 row로 출력하기 (UNPIVOT)
-
unpivot(출력할 컬럼 이름 for 데이터가 출력될 컬럼 이름 in (데이터1, 데이터2, ...))
-
unpivot문 작성시 쿼테이션마크 작성X
-
unpivot문 in()안에 컬럼으로 구분된 이름들 모두 작성
-
🗒️ 예상 결과
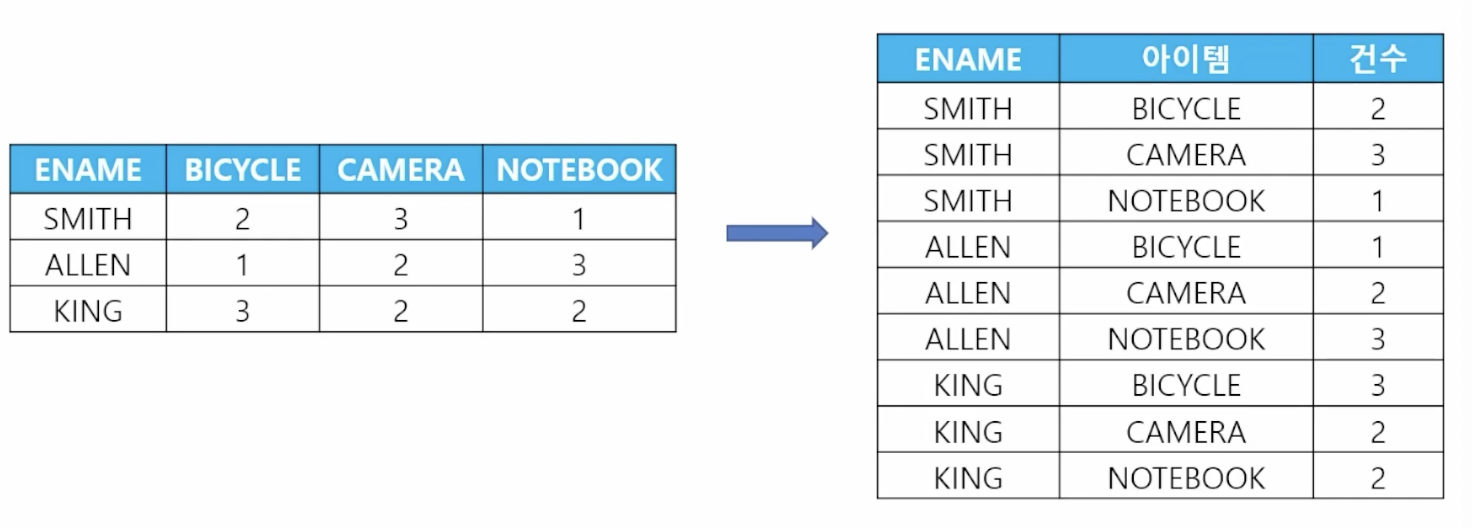
-
📋 문제 1) 예상 결과와 같이 컬럼이 데이터로 들어가게 하세요
// 정보 추가 drop table order2; create table order2 ( ename varchar2(10), bicycle number(10), camera number(10), notebook number(10)); insert into order2 values ('SMITH', 2, 3, 1); insert into order2 values ('ALEN', 1, 3, 2); insert into order2 values ('KING', 3, 2, 2); commit; // unpivot문 select * from order2 unpivot(건수 for 아이템 in (BICYCLE, CAMERA, NOTEBOOK)); -
📋 문제 2) 범죄원인 테이블을 생성하고 방화사건의 가장 큰 원인이 무엇인지 출력하세요
-
// 범죄원인 테이블 생성
create table crime_cause
(
crime_type varchar2(30),
생계형 number(10),
유흥 number(10),
도박 number(10),
허영심 number(10),
복수 number(10),
해고 number(10),
징벌 number(10),
가정불화 number(10),
호기심 number(10),
유혹 number(10),
사고 number(10),
불만 number(10),
부주의 number(10),
기타 number(10) );
insert into crime_cause values( '살인',1,6,0,2,5,0,0,51,0,0,147,15,2,118);
insert into crime_cause values( '살인미수',0,0,0,0,2,0,0,44,0,1,255,38,3,183);
insert into crime_cause values( '강도',631,439,24,9,7,53,1,15,16,37,642,27,16,805);
insert into crime_cause values( '강간강제추행',62,19,4,1,33,22,4,30,1026,974,5868,74,260,4614);
insert into crime_cause values( '방화',6,0,0,0,1,2,1,97,62,0,547,124,40,339);
insert into crime_cause values( '상해',26,6,2,4,6,42,18,1666,27,17,50503,1407,1035,22212);
insert into crime_cause values( '폭행',43,15,1,4,5,51,117,1724,45,24,55814,1840,1383,24953);
insert into crime_cause values( '체포감금',7,1,0,0,1,2,0,17,1,3,283,17,10,265);
insert into crime_cause values( '협박',14,3,0,0,0,10,11,115,16,16,1255,123,35,1047);
insert into crime_cause values( '약취유인',22,7,0,0,0,0,0,3,8,15,30,6,0,84);
insert into crime_cause values( '폭력행위등',711,1125,12,65,75,266,42,937,275,181,52784,1879,1319,29067);
insert into crime_cause values( '공갈',317,456,12,51,17,116,1,1,51,51,969,76,53,1769);
insert into crime_cause values( '손괴',20,4,0,1,3,17,8,346,61,11,15196,873,817,8068);
insert into crime_cause values( '직무유기',0,1,0,0,0,0,0,0,0,0,0,0,18,165);
insert into crime_cause values( '직권남용',1,0,0,0,0,0,0,0,0,0,1,0,12,68);
insert into crime_cause values( '증수뢰',25,1,1,2,5,1,0,0,0,10,4,0,21,422);
insert into crime_cause values( '통화',15,11,0,1,1,0,0,0,6,2,5,0,2,44);
insert into crime_cause values( '문서인장',454,33,8,10,37,165,0,16,684,159,489,28,728,6732);
insert into crime_cause values( '유가증권인지',23,1,0,0,2,3,0,0,0,0,3,0,11,153);
insert into crime_cause values( '사기',12518,2307,418,225,689,2520,17,47,292,664,3195,193,4075,60689);
insert into crime_cause values( '횡령',1370,174,58,34,86,341,3,10,358,264,1273,23,668,8697);
insert into crime_cause values( '배임',112,4,4,0,30,29,0,0,2,16,27,1,145,1969);
insert into crime_cause values( '성풍속범죄',754,29,1,6,12,100,2,114,1898,312,1051,60,1266,6712);
insert into crime_cause values( '도박범죄',1005,367,404,32,111,12969,4,8,590,391,2116,9,737,11167);
insert into crime_cause values( '특별경제범죄',5313,91,17,28,293,507,31,75,720,194,9002,1206,6816,33508);
insert into crime_cause values( '마약범죄',57,5,0,1,2,19,3,6,399,758,223,39,336,2195);
insert into crime_cause values( '보건범죄',2723,10,6,4,63,140,1,6,5,56,225,6,2160,10661);
insert into crime_cause values( '환경범죄',122,1,0,2,1,2,0,0,15,3,40,3,756,1574);
insert into crime_cause values( '교통범죄',258,12,3,4,2,76,3,174,1535,1767,33334,139,182010,165428);
insert into crime_cause values( '노동범죄',513,11,0,0,23,30,0,2,5,10,19,3,140,1251);
insert into crime_cause values( '안보범죄',6,0,0,0,0,0,1,0,4,0,4,23,0,56);
insert into crime_cause values( '선거범죄',27,0,0,3,1,0,2,1,7,15,70,43,128,948);
insert into crime_cause values( '병역범죄',214,0,0,0,2,7,3,35,2,6,205,50,3666,11959);
insert into crime_cause values( '기타',13872,512,35,55,552,2677,51,455,2537,1661,18745,1969,20957,87483);
commit;
// unpivot문
select *
from crime_cause;
unpivot (건수 for 범죄원인 in (생계형, 유흥, 도박, 허영심, 복수, 해고, 징벌, 가정불화, 호기심, 유혹, 사고, 불만, 부주의, 기타));
where crime_type = '방화';
order by 건수 desc;📖 참고 📖 in line view (from절 서브쿼리)
- 쿼리문이 가장 처음 실행되는 from절에 새로운 쿼리를 작성하는 방식
- 서브쿼리(sub-query) : 데이터를 불러올 때 1차적으로 선별하여 불러오기 위해 작성
📖 참고 📖 alias 사용
- select ➡️ order by 다음에 실행되므로 alias 적용된 이름 사용 가능
-
10) 누적 데이터 출력 (SUM OVER)
- sum(컬럼명) over (order by 기준 컬럼)
- 기준 컬럼 적지 않을 경우 총합 누적 결과로 나옴
- order by 기준 컬럼 rows between unbounded preceding and current row
- unbounded preceding : 첫번째 행
- current row : 현재 행
- rows between unbounded preceding and current row 생략 가능
- 🗒️ 예상 결과
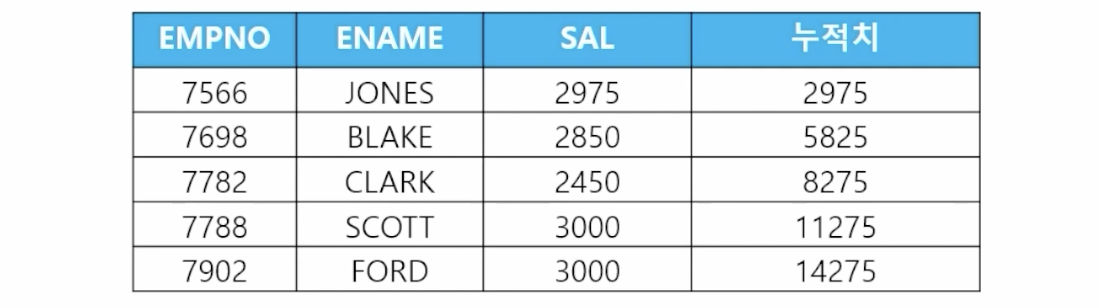
- 📋 문제 1) 직업이 ANALYST, MANAGER인 사원들의 사원번호, 사원이름, 월급, 월급에 대한 누적치를 출력하세요
select empno, ename, sal, sum(sal) over (order by empno) 누적치 // 사원번호 기준 누적 from emp where job in ('ANALYST', 'MANAGER'); - 📋 문제 2) 부서번호가 20번인 사원들의 사원이름, 월급, 월급에 대한 누적치가 출력되게 하세요
select ename, sal, sum(sal) over (order by empno asc) 누적치 from emp where empno = 20;
-
11) 비율 출력 (RATIO_TO_REPORT)
-
ratio_to_report(컬럼명) over()
-
🗒️ 예상 결과
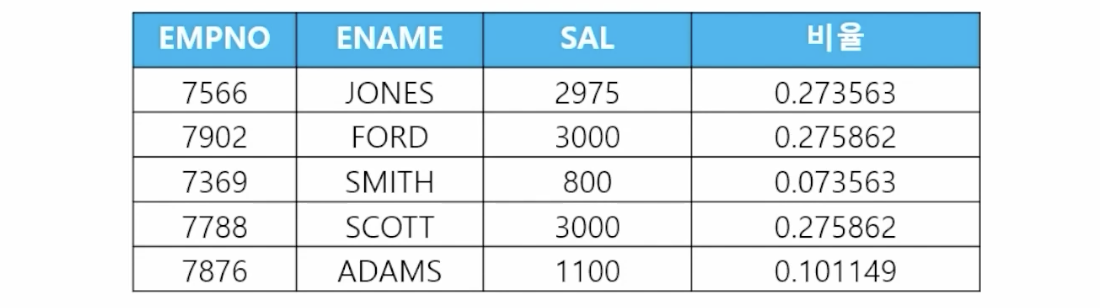
-
📋 문제 1) 부서번호가 20번인 사원들의 사원번호, 이름, 월급, 월급에 대한 비율을 출력하세요
select empno, ename, sal, round(ratio_to_report(sal) over(), 2) 비율 from emp where deptno = 20; -
📋 문제 2) 사원 테이블 전체에서 사원번호, 이름, 월급, 월급에 대한 비율을 출력하세요
select empno, ename, sal, round(ratio_to_report(sal) over (), 2) 비율 from emp; -
12) 집계 결과 하단에 출력 (ROLLUP)
- group by절에 rollup(기준 컬럼)
- row 하단에 전체 토탈을 출력해줌
- 🗒️ 예상 결과

-
📋 문제 1) 직업, 직업별 토탈 월급을 출력하는데 맨 아래에 다음과 같이 전체 토탈월급이 출력되게 하세요
select job, sum(sal) from emp group by rollup(job); // grouping sets로 구현 select job, sum(sal) from emp group by grouping sets((job), ()); -
📋 문제 2) 부서번호, 부서번호별 토탈월급을 출력하는데 맨 아래에 전체 토탈월급이 출력되게 하세요
select deptno, sum(deptno) from emp group by rollup(deptno); -
13) 집계 결과 상단에 출력 (CUBE)
- group by절에 cube(기준 컬럼)
- 🗒️ 예상 결과
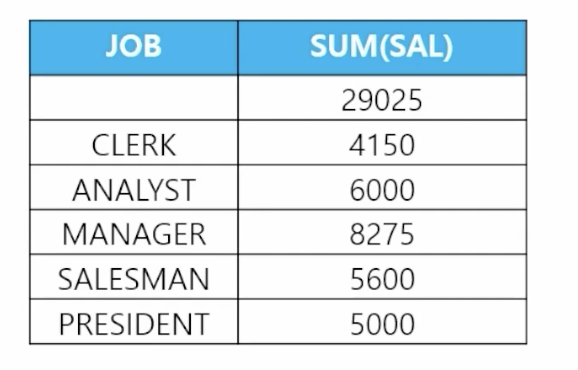
-
📋 문제 1) 직업, 직업별 토탈월급을 출력하는데 맨 위에 다음과 같이 전체 토탈월급이 출력되게 하세요
select job, sum(sal) from emp group by cube(job); -
📋 문제 2) 입사한 년도(4자리), 입사한 년도 별 토탈월급을 출력하는데 맨 위에 사원 테이블의 전체 토탈월급이 출력되게 하세요
select to_char(hiredate, 'YYYY'), sum(sal) from emp group by cube(to_char(hiredate, 'YYYY')); -
14) 2가지 집계 결과 출력 (GROUPING SETS)
- group by grouping sets(기준 컬럼1, 기준 컬럼2, ..., ())
- 마지막 () : 전체 합계 출력
- grouping sets안에서 괄호()의 역할은 기준 컬럼들이 동시에 묶인 결과를 출력할지 단일 겨로가를 출력할지 결정하는 역할
- 🗒️ 예상 결과
- 직업별 합계 + 전체 합계 + 부서별 합계 출력
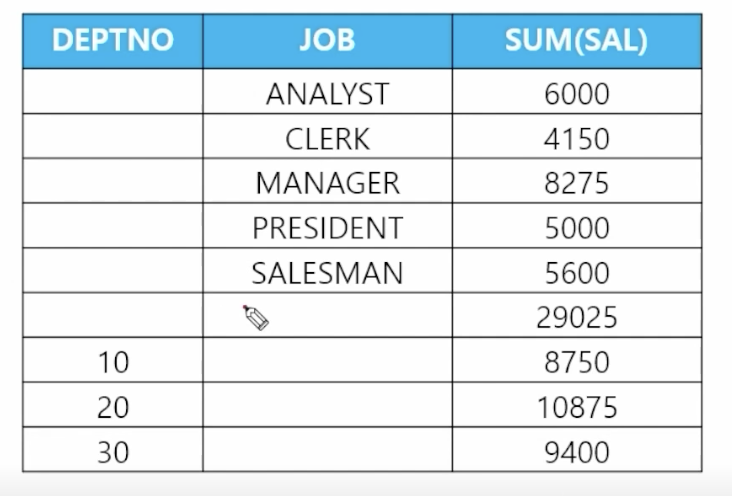
- 직업별 합계 + 전체 합계 + 부서별 합계 출력
- group by grouping sets(기준 컬럼1, 기준 컬럼2, ..., ())
-
📋 문제 1) 다음과 같이 직업별 토탈월급과 부서번호별 토탈월급과 전체 토탈월급을 같이 출력하세요
select deptno, job, sum(sal) from emp group by grouping sets(deptno, job, ()); // deptno + job별 토탈월급 select deptno, job, sum(sal) from emp group by grouping sets((deptno, job), ()); -
📋 문제 2) 입사한 년도(4자리), 입사한 년도(4자리)별 토탈월급과 직업, 직업별 토탈월급을 위아래로 같이 출력하세요
select to_char(hiredate, 'YYYY'), job, sum(sal) from emp group by grouping sets(to_char(hiredate, 'YYYY'), job); -
15) 출력 결과 넘버링 (ROW_NUMBER)
- row_number() over(order by 기준 컬럼)
- 출력된 행을 넘버링
- 🗒️ 예상 결과
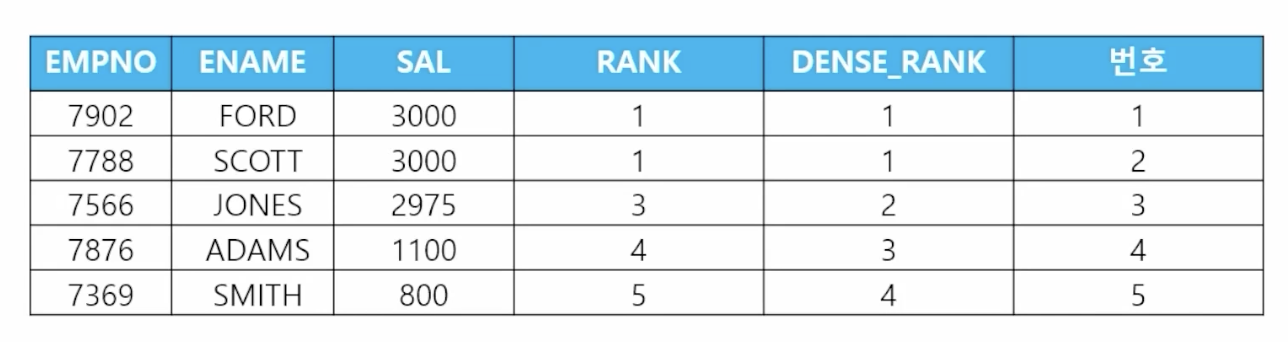
- 📋 문제 1) 부서번호가 20번인 사원들의 사원번호, 사원이름, 월급, 순위를 출력하는 결과 끝에 번호를 넘버링해서 출력하세요
select empno, ename, sal, rank() over (order by sal desc) as rank, dense_rank() over (order by sal desc) as dense_rank, row_number() over (order by sal desc) as 번호 from emp where deptno = 20; - 📋 문제 2) 월급이 1000에서 3000 사이인 사원들의 이름과 월급을 출력하는데 출력하는 결과 맨 끝에 번호를 넘버링해서 출력하세요
select ename, sal, row_number() over (order by empno) as 번호 // 이름이나 월급 순으로 정렬한다는 내용 없어서 사원번호순 정렬 from emp where sal between 1000 and 3000;
-
16) 출력 상단 행 제한 (ROWNUM)
- rownum은 쉐도우 컬럼(모든 테이블에 숨겨져존재) 사용
- 🗒️ 예상 결과
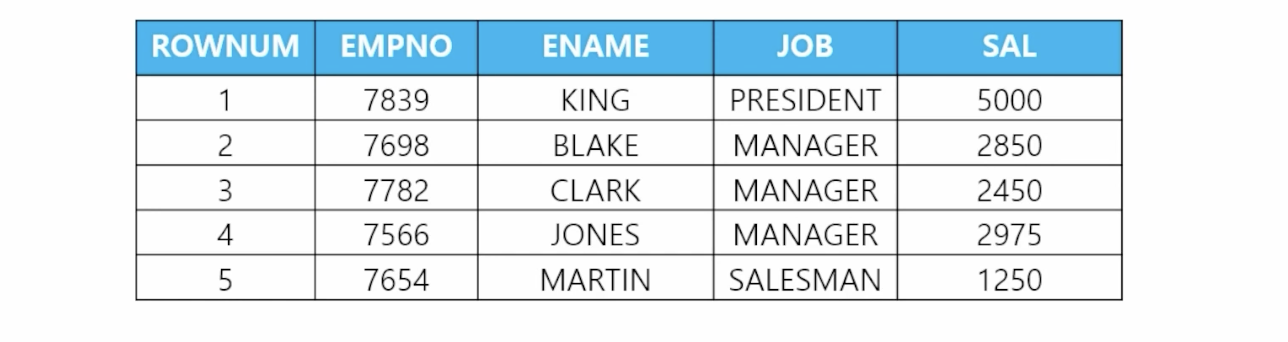
- 📋 문제 1) 사원 테이블에서 맨 위의 5개의 행만 아래와 같이 출력하세요
select rownum, empno, ename, job, sal from emp where rownum <= 5; - 📋 문제 2) 직업이 SALESMAN인 사원들의 이름과 월급과 직업을 출력하는데 맨 위의 행 2개만 출력하세요
select ename, sal, job from emp where job = 'SALESMAN' and rownum <= 2;
-
17) 출력되는 행 제한 (Simple TOP-n Queries)
- 🗒️ 예상 결과
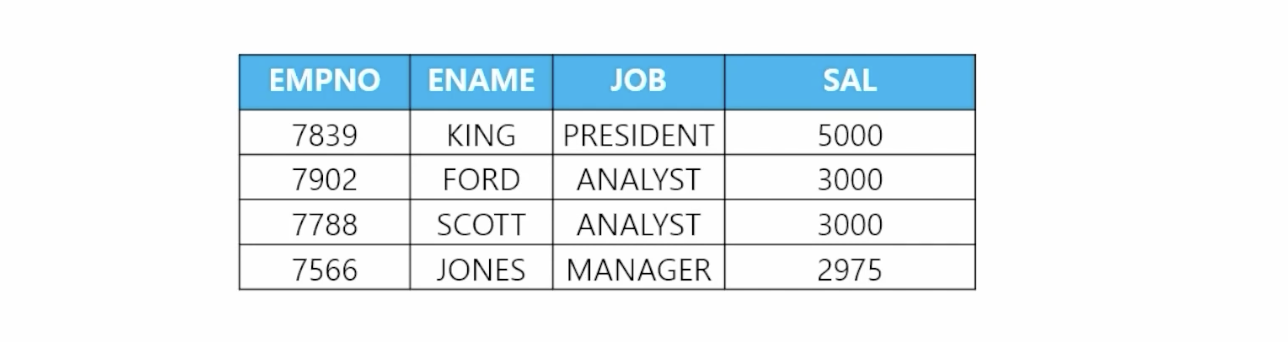
- 📋 문제 1) 월급이 높은 사원순으로 사원번호, 이름, 직업, 월급을 출력하는데 다음과 같이 맨 위의 4개의 행만 출력하세요
select empno, ename, job, sal from emp order by sal desc fetch first 4 rows only; - 📋 문제 2) 최근에 입사한 사원순으로 이름, 입사일과 월급을 출력하는데 맨 위의 5명만 출력하세요
select ename, hiredate, sal from emp order by hiredate desc fetch first 5 rows only;
- 🗒️ 예상 결과
📕 테이블 JOIN
1. oracle 조인 문법
-
1) 여러 테이블의 같은 데이터 조인 (EQUI JOIN)
- 테이블에서 서로 공통된 컬럼이 있는 경우
- 조인조건 : where문에 두 테이블의 같은 컬럼을 연결
- 🗒️ 예상 결과
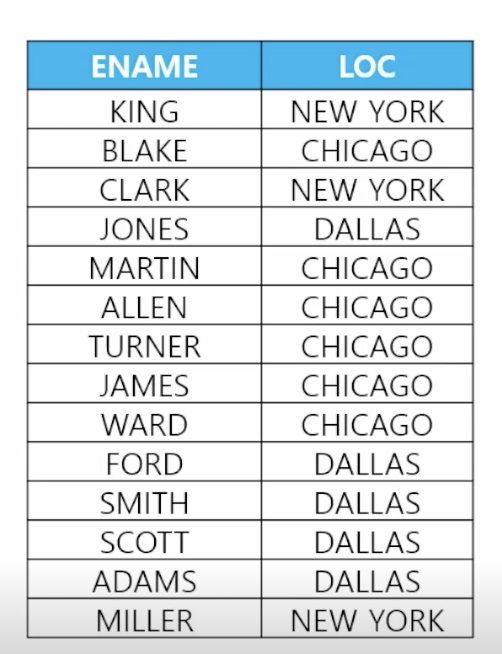
- 📋 문제 1) 사원 테이블과 부서 테이블을 조인해서 이름과 부서위치를 출력하세요
select e.ename, d.loc, e.deptno from emp e, dept d // table alias where e.deptno = d.deptno; - 📋 문제 2) 직업이 SALESMAN인 사원들의 이름과 직업과 부서위치를 출력하세요
select e.ename, e.job, d.loc from emp e, dept d where e.deptno = d.deptno and e.job = 'SALESMAN'; - 📋 문제 3) DALLAS에서 근무하는 사원들의 이름과 부서위치를 출력하세요
select e.ename, d.loc from emp e, dept d where e.deptno = d.deptno and d.loc = 'DALLAS';
-
2) 여러 테이블의 같지 않은 데이터 조인 (NON EQUI JOIN)
-
테이블에서 서로 공통된 컬럼이 없는 경우
-
조인조건 : where문에 두 테이블의 조건에 따라 컬럼을 연결
-
🗒️ 예상 결과
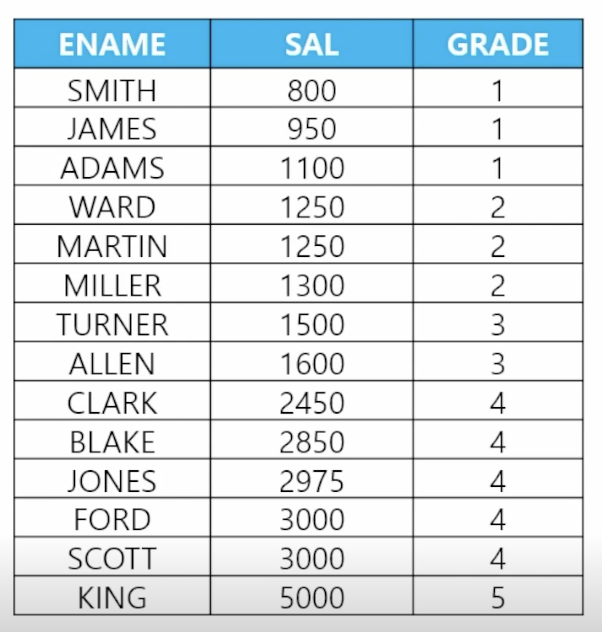
-
📋 문제 1) 사원 테이블과 급여 테이블과 조인하여 이름과 월급과 월급에 대한 등급을 출력하세요
// 데이터 추가 drop table salgrade; create table salgrade ( grade number(10), losal number(10), hisal number(10) ); insert into salgrade values(1,700,1200); insert into salgrade values(2,1201,1400); insert into salgrade values(3,1401,2000); insert into salgrade values(4,2001,3000); insert into salgrade values(5,3001,9999); commit; // NON EQUI JOIN select e.ename, e.sal, s.grade from emp e, s.salgrade s where e.sal between s.losal and s.hisal; // emp 테이블 월급은 salgrade 테이블의 losal과 hisal 사이에 존재 -
📋 문제 2) 급여등급이 4등급인 사원들의 이름과 월급을 출력하는데 월급이 높은 사원부터 출력하세요
select e.ename, e.sal from emp e, salgrade s where e.sal between s.losal and s.hisal and s.grade = 4 order by e.sal desc;
-
-
3) 여러 테이블의 없는 데이터 조인 (OUTER JOIN)
-
한 테이블에 존재하지만, 다른 테이블에 존재하지 않는 컬럼이 있는 경우
-
조인 조건 : where절에 없는 컬럼 (+) = 있는 컬럼
-
🗒️ 예상 결과
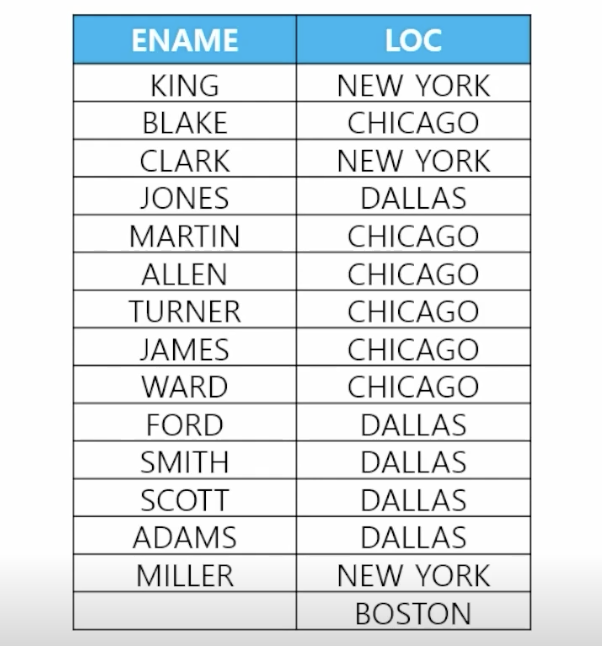
-
📋 문제 1) 이름과 부서위치를 출력하는데 다음과 같이 BOSTON도 출력되게 하세요
select e.name, d.loc from emp e, dept d where e.deptno = d.deptno; // 수정 필요 (emp 테이블에 40번 부서번호가 없어서 BOSTON 출력되지 않음) // OUTER JOIN select e.name, d.loc from emp e, dept d where e.deptno (+) = d.deptno; // dept 테이블에 없을 경우 e.deptno = d.deptno (+) -
📋 문제 2) 사원 테이블 전체에 이름과 부서위치를 출력하는데 JACK도 출력되게 하시오
// 데이터 추가 insert into emp(empno, ename, sal, deptno) values(7122, 'JACK', 3000, 70); commit; // OUTER JOIN select e.ename, d.loc from emp e, dept d where e.deptno = d.deptno (+);
-
-
4) 자기 자신 테이블의 데이터 조인 (SELF JOIN)
- 자기 자신의 테이블과도 조인 가능
- 🗒️ 예상 결과
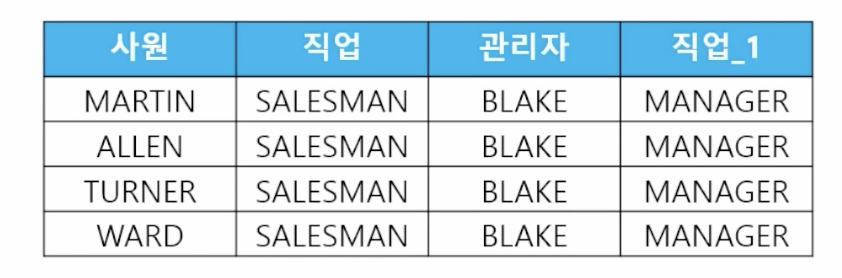
- 📋 문제 1) 사원이름과 직업을 출력하고 관리자 이름과 관리자의 직업을 출력하세요
// MGR (관리자의 사원번호) select 사원.ename as 사원, 사원.job as 직업, 관리자.ename as 관리자, 관리자.job as 직업 from emp 사원, emp 관리자 where 사원.mgr = 관리자.empno; - 📋 문제 2) 사원 이름과 월급을 출력하고 관리자의 이름과 관리자의 직업을 출력하고, 관리자인 사원들보다 더 많은 월급을 받는 사원들의 데이터만 출력하세요
select 사원.ename as 사원, 사원.sal as 사원월급, 관리자.ename as 관리자, 관리자.sal as 관리자월급 from emp 사원, emp 관리자 where 사원.mgr = 관리자.empno and 사원.sal >= 관리자.sal;
2. 1999 ANSI 조인 문법
-
1) 내부 조인 (ON절)
- where절 대신 on 사용 (조인조건과 검색조건 분리)
- 조인 조건 : on절에 두 테이블의 같은 컬럼을 연결
- 🗒️ 예상 결과
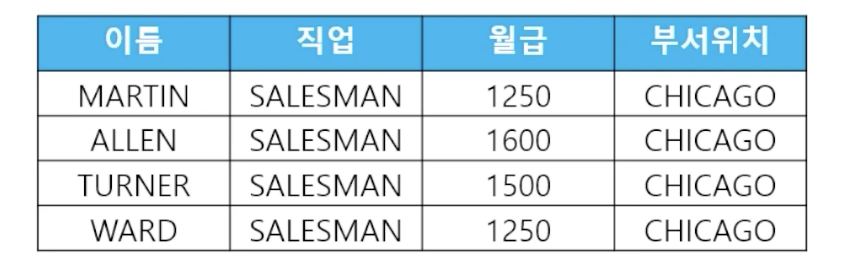
- 📋 문제 1) on절을 사용한 조인문법으로 직업이 SALESMAN인 사원들의 이름과 직업과 월급과 부서위치를 출력하세요
select e.ename, e.job, e.sal, d.loc from emp e join dept d on (e.deptno = d.deptno) // 조인조건 where e.job = 'SALESMAN'; // 검색조건 - 📋 문제 2) 월급이 1000에서 3000사이인 사원들의 이름과 월급과 부서위치를 on절을 사용한 조인문법으로 출력하세요
select e.ename, e.sal, d.loc from ename e join dept d on (e.deptno = d.deptno) // 조인조건 where e.sal between 1000 and 3000; // 검색조건
-
2) 내부 조인 (USING 절)
- on절과 동일한 기능
- 조인 조건 : using(동일 컬럼) (테이블 별칭 없이 사용)
- 🗒️ 예상 결과
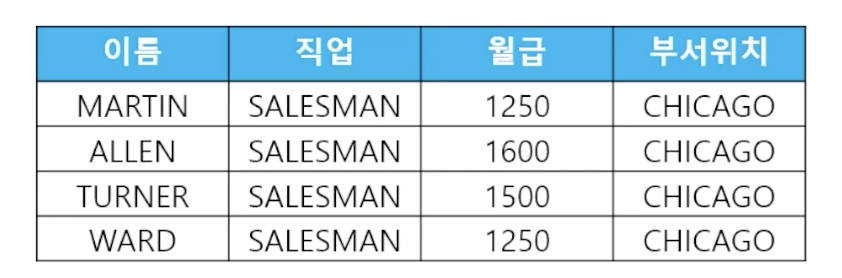
- 📋 문제 1) using 절을 사용한 조인문법으로 다음의 결과를 출력하세요
select e.ename, e.job, e.sal, d.loc from emp e join dept d using (deptno) // 테이블 별칭 사용X where e.job = 'SALESMAN'; - 📋 문제 2) using절을 사용한 조인문법으로 부서위치가 DALLAS인 사원들의 이름과 월급과 부서위치를 출력하세요
select e.name, e.sal, d.loc from emp e join dept d using (deptno) // 조인조건 where d.loc = 'DALLAS'; // 검색조건
-
3) 내부 조인 (NATURAL JOIN)
- on절, using절과 동일한 기능
- 조인 조건 필요X : from절에 natural join 사용
- 공통된 연결 컬럼은 별칭 사용X
- 🗒️ 예상 결과

- 📋 문제 1) natural.join을 이용해서 이름과 직업과 월급과 부서위치를 출력하세요
select e.ename as 이름, e.job as 직업, e.sal as 월급, d.loc as 부서위치 from emp e natural join dept d where e.job = 'SALESMAN'; - 📋 문제 2) 직업이 SALESMAN이고 부서번호가 30번인 사원들의 이름과 직업과 월급과 부서위치를 출력하세요
select e.ename, e.sal, d.loc from emp e natural join dept d where e.job = 'SALESMAN' and deptno = 30; // deptno에 별칭 붙이면 에러 발생
-
4) 외부 조인 (LEFT/RIGHT OUTER JOIN)
-
🗒️ 예상 결과
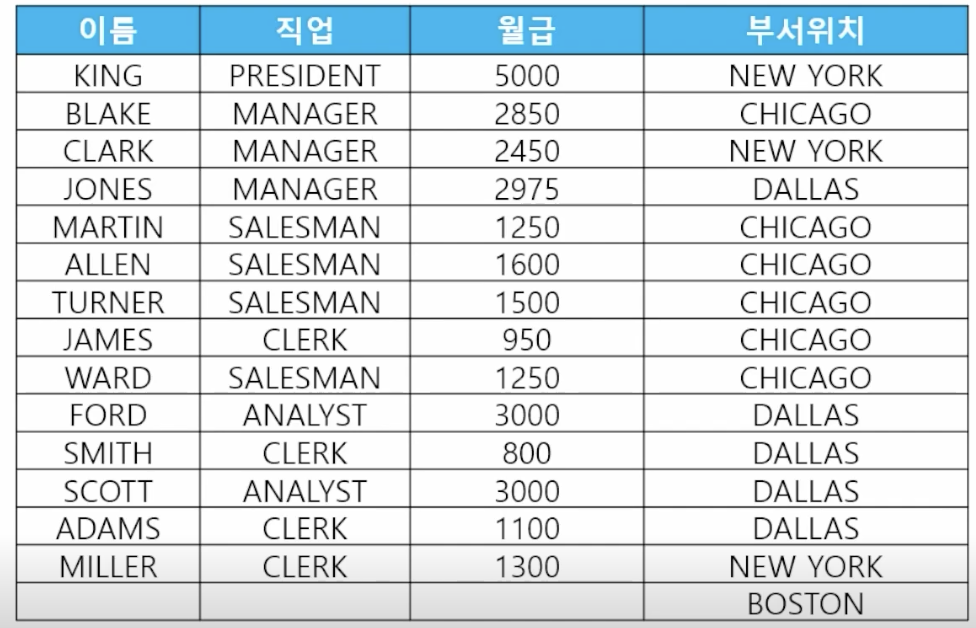
-
📋 문제 1) 1999 ansi 조인 문법의 outer join으로 사원 테이블과 부서 테이블을 조인해서 이름, 직업, 월급, 부서위치를 출력하세요
select e.ename, e.job, e.sal, d.loc from emp e right outer join dept d // from dept d left outer join emp e on (e.deptno = d.deptno); -
📋 문제 2) 다음의 데이터를 사원 테이블에 입력하고, 1999 ansi 조인 문법을 사용하여 이름과 직업, 월급과 부서위치를 출력하는데 사원 테이블에 JACK도 출력될 수 있도록 하세요
// 데이터 추가 INSERT INTO emp(empno, ename, sal, job, deptno) VALUES(8282, 'JACK', 3000, 'ANALYST', 50); commit; // left/right outer join select e.ename, e.job, e.sal, d.loc from emp e left outer join dept d on (e.deptno = d.deptno);
-
-
5) 외부 조인 (FULL OUTER JOIN)
- oracle 문법에는 없는 기능
- 🗒️ 예상 결과

- 📋 문제 1) 1999 ANSI 조인의 full outer 조인을 사용하여 JACK도 출력되고 부서위치의 BOSTON도 출력되게 하세요
select e.ename, e.job, e.sal, d.loc from emp e full outer join dept d on (e.deptno = d.deptno); - 📋 문제 2) 직업이 ANALYST이거나 부서위치가 BOSTON인 사원들의 이름과 직업과 월급과 부서위치를 출력하는데 FULL OUTER 조인을 사용하여 출력하세요
select e.ename, e.job, e.sal, d.loc from emp e full outer join dept d on (e.deptno = d.deptno) where e.job = 'ANALYST' or d.loc = 'BOSTON';
3. 집합 연산자
- 1) 데이터 위아래 연결 (UNION ALL)
-
조건에 맞는 컬럼의 총합 출력
-
데이터를 정렬X 출력
-
위의 컬럼과 아래 컬럼의 개수, 데이터 타입, 컬럼명 일치해야 함
-
🗒️ 예상 결과
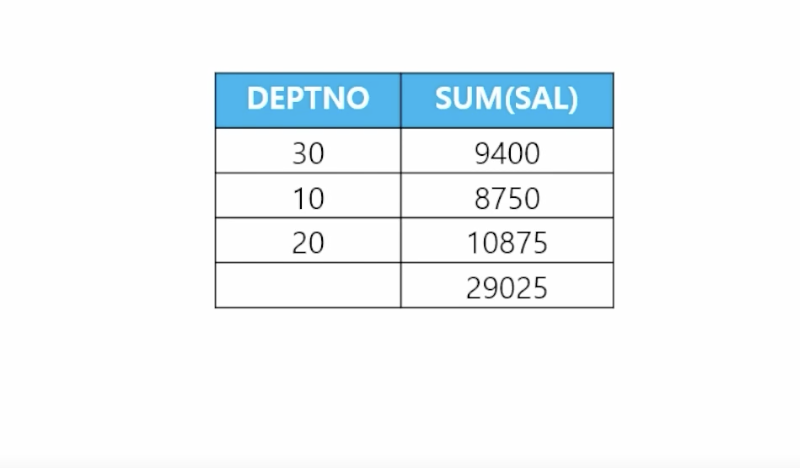
-
📋 문제 1) 부서번호와 부서번호별 토탈 월급을 출력하는데 다음과 같이 맨 아래에 전체 토탈 월급도 출력하세요
// 데이터 수정 delete from emp where deptno = 50; commit; // UNION ALL select deptno, sum(sal) from emp group by deptno union all select to_number(null) as deptno, sum(sal) // 위 컬럼 개수와 일치시킴 from emp order by detpno asc; // 컬럼명을 일치시켜서 order by 사용 가능 (order by는 항상 맨 하단에 위치) -
📋 문제 2) 직업과 직업별 토탈월급을 출력하는데 맨 아래에 전체 토탈월급도 출력하세요
select job, sum(sal) from emp group by job union all select to_char(null) as job, sum(sal) from emp;
-
- 2) 데이터 위아래로 연결 (UNION)
- 조건에 맞는 컬럼의 총합 출력
- 데이터를 정렬해서 출력
- 위의 컬럼과 아래 컬럼의 개수, 데이터 타입, 컬럼명 일치해야 함
- 🗒️ 예상 결과
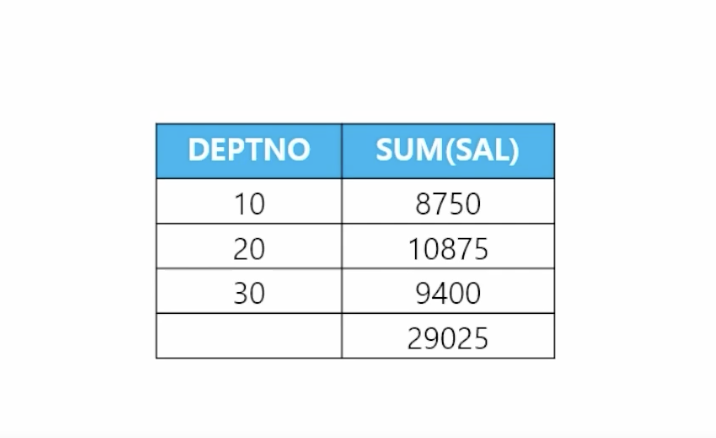
- 📋 문제 1) 부서번호와 부서번호별 토탈 월급을 출력하고 다음과 같이 맨 아래에 전체 토탈 월급도 출력하는데 부서번호가 오름차순으로 정렬되어서 출력되게 하세요
select deptno, sum(sal) from emp group by deptno union to_number(null) as deptno, sum(sal) from emp; - 📋 문제 2) 직업, 직업별 토탈월급을 출력하는데 직업이 abcd 순으로 정렬되어서 출력하고 맨 아래에 전체 토탈월급을 출력하세요
select job, sum(sal) from emp group by job union select to_char(null) as job, sum(sal) from emp; - 📋 문제 3) 입사한 년도, 입사한 년도별 토탈월급을 출력하는데 맨 아래에 전체 토탈월급이 출력되게 하세요 (입사한 년도는 정렬되어서 출력되게 하세요)
select to_char(hiredate, 'YYYY'), sum(sal) from emp group by to_char(hiredate, 'YYYY') union select to_char(null), sum(sal) from emp;
- 3) 데이터 교집합 (INTERSECT)
- 중복된 데이터 출력
- 맨 첫번째 컬럼 기준으로 정렬
- 📋 문제 1) A와 B의 교집합 출력

- 📋 문제 2) 사원 테이블과 부서 테이블간의 공통된 부서번호가 무엇인지 출력하시오
select deptno from emp intersect select deptno from dept;
- 4) 데이터 차집합 (MINUS)
- 📋 문제 1) A와 B의 차집합 출력

- 📋 문제 2) 부서 테이블에는 존재하는데 사원 테이블에는 존재하지 않는 부서번호를 출력하시오
select deptno from dept minus select deptno from emp;
- 📋 문제 1) A와 B의 차집합 출력
📕 서브쿼리
1. 서브쿼리 사용
-
1) 단일행 서브쿼리
-
서브 쿼리에서 메인쿼리로 하나의 값이 리턴되는 경우
- 서브 쿼리의 결과를 메인 쿼리에 넘겨주면 한번에 실행 가능
-
연산자 : =, !=, ^=, <>, >, <, >=, <=
-
🗒️ 예상 결과
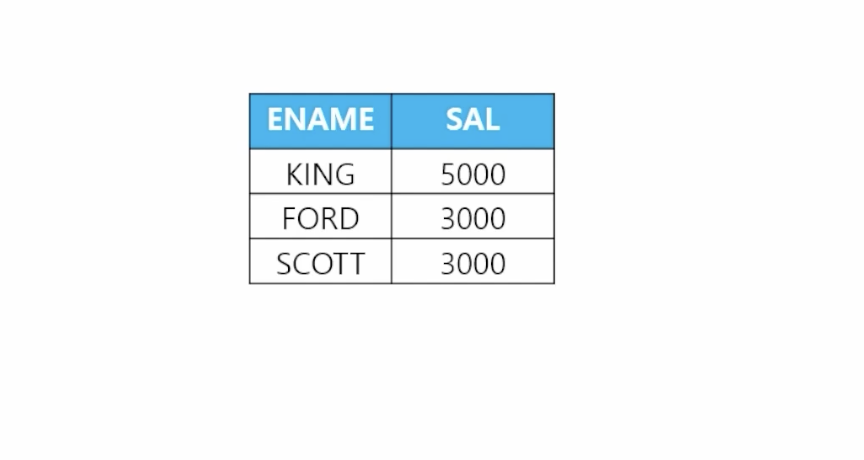
-
📋 문제 1) JONES보다 더 많은 월급을 받는 사원들의 이름과 월급을 출력하세요
// 1. JONES 월급 구하기 select sal from emp where ename = 'JONES'; // 2. main 쿼리안에 sub 쿼리 작성 select ename, sal from emp where sal > ( select sal // 서브쿼리 from emp where ename = 'JONES'); -
📋 문제 2) ALLEN보다 더 늦게 입사한 사원들의 이름과 월급을 출력하세요
select ename, sal from emp where hiredate > ( select hiredate from emp where ename = 'ALLEN');
-
-
2) 다중행 서브쿼리
- 서브쿼리에서 메인퉈리로 2개 이상의 값이 리턴되는는 경우
- 연산자 : in (=all), not in (!=all), >all, <all, >any, \<any
- not in 쓸 경우 : null 값이 들어오면 안됨 (결과도 null이 됨)
- 🗒️ 예상 결과
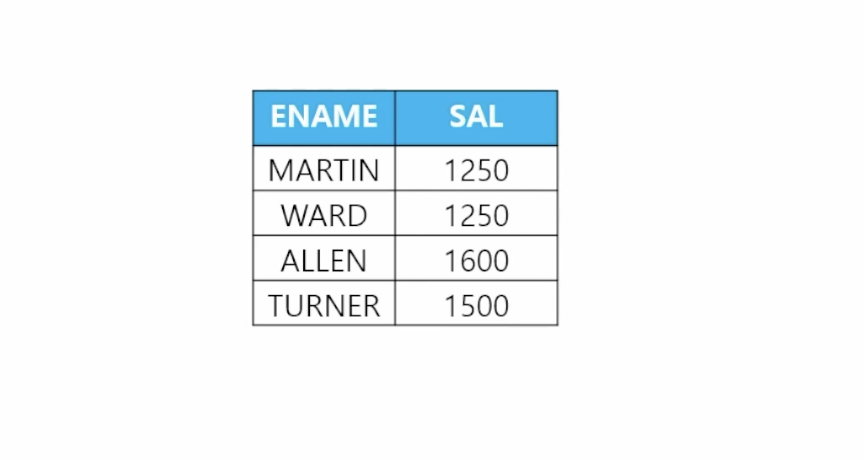
- 📋 문제 1) 직업이 SALESMAN인 사원들과 같은 월급을 받는 사원들의 이름과 월급을 출력하시오
select ename, sal from emp where sal = (select sal // 에러 발생 from emp // (단일행 하위 질의가 2개 이상 리턴 발생) where job = 'SALESMAN'); // 다중행 서브쿼리 select ename, sal from emp where sal in (select sal from emp where job = 'SALESMAN'); - 📋 문제 2) 부서번호가 20번인 사원들과 같은 직업을 갖는 사람들의 이름과 직업을 출력하시오
select ename, job from emp where job in (select job from emp where deptno = 20); - 📋 문제 3) 관리자 사원들의 이름을 출력하세요
select ename from emp where empno in (select mgr from emp); - 📋 문제 4) 관리자가 아닌 사원들의 이름을 출력하세요
select ename from emp where empno not in (select mgr // null 값이 있어서 데이터 하나도 출력 안됨 from emp); // null값 제거하도록 수정 select ename from emp where empno not in (select mgr // where절 없이 nvl(mgr, -1)도 가능 from emp where mgr is not null);
-
3) EXISTS와 NOT EXIST
- 🗒️ 예상 결과
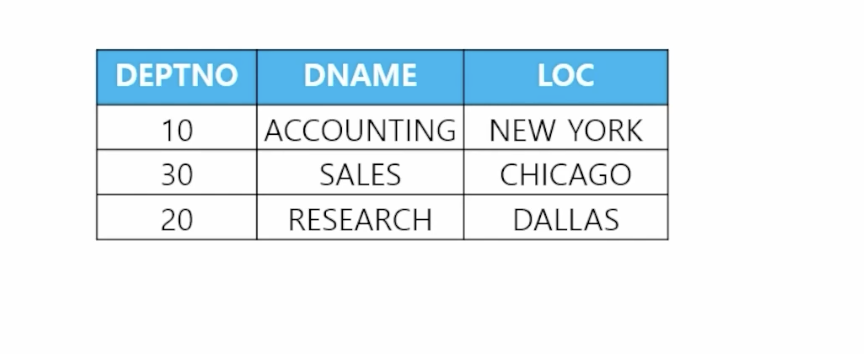
- 📋 문제 1) 부서 테이블에 있는 부서번호중에서 사원 테이블에 존재하는 부서번호에 대한 모든 컬럼을 출력하세요
select deptno, dname, loc from dept d where exists (select deptno from emp e where e.deptno = d.deptno); - 📋 문제 2) 부서 테이블에 있는 부서번호 중에서 사원 테이블에 존재하지 않는 부서번호에 대한 모든 컬럼을 출력하세요
select deptno from dept d where not exits (select deptno from emp e where e.deptno = d.deptno);
- 🗒️ 예상 결과
-
4) HAVING 절의 서브 쿼리
-
그룹 함수로 검색 조건 사용할 경우 HAVING 절에 작성
-
🗒️ 예상 결과
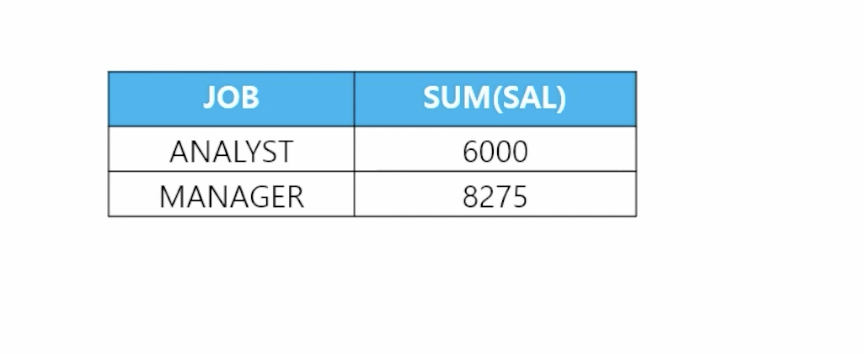
-
📋 문제 1) 직업과 직업별 토탈월급을 출력하는데 직업이 SALESMAN인 사원들의 토탈월급보다 더 큰 것만 출력되게 하세요
select job, sum(sal) from emp where sum (sal) > (select sum(sal) // 그룹 함수가 허가되지 않아서 에러 발생 from emp whiere job = 'SALESMAN') group by job; // HAVING절 select job, sum(sal) from emp group by job having sum(sal) > (select sum(sal) from emp whiere job = 'SALESMAN'); -
📋 문제 2) 부서번호, 부서번호별 인원수를 출력하는데 10번 부서번호의 인원수보다 더 큰 것만 출력하시오
select deptno, count(*) from emp group by deptno having count(*) > (select count(*) from emp where deptno = 10);
-
-
5) FROM절의 서브 쿼리
- 해당 조건을 from 절에 넣어 서브 쿼리로 사용
- where이 select 보다 먼저 실행하여 rank의 alias 사용 불가
- 분석함수는 Select절에만 가능해서 where절에 작성 불가
- 🗒️ 예상 결과
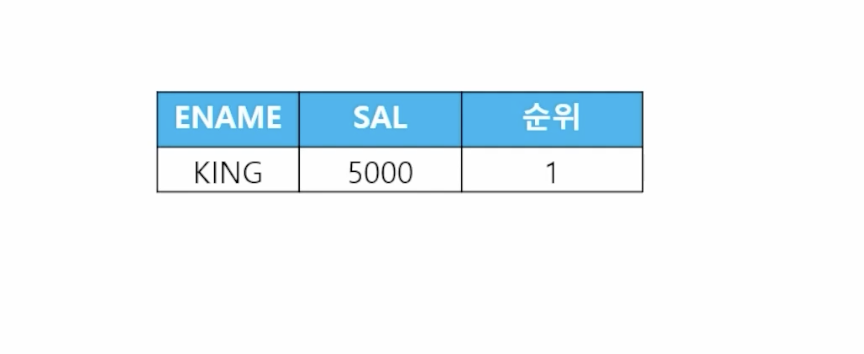
- 📋 문제 1) 사원 테이블에서 월급을 가장 많이 받는 사원의 이름과 월급과 월급의 순위를 출력하세요
select * from ( select ename, sal, rank() over (order by sal desc) 순위 from emp ) where 순위 = 1; - 📋 문제 2) 직업이 SALESMAN인 사원들 중에서 가장 먼저 입사한 사원의 이름과 입사일을 출력하세요
select * from (select ename, hiredate, rank() over (order by hiredate asc) as 입사 from emp where job = 'SALESMAN') where 입사 = 1;
- 해당 조건을 from 절에 넣어 서브 쿼리로 사용
-
6) SELECT절의 서브 쿼리
-
단일행 함수와 다중행 함수 동시에 사용X
-
🗒️ 예상 결과
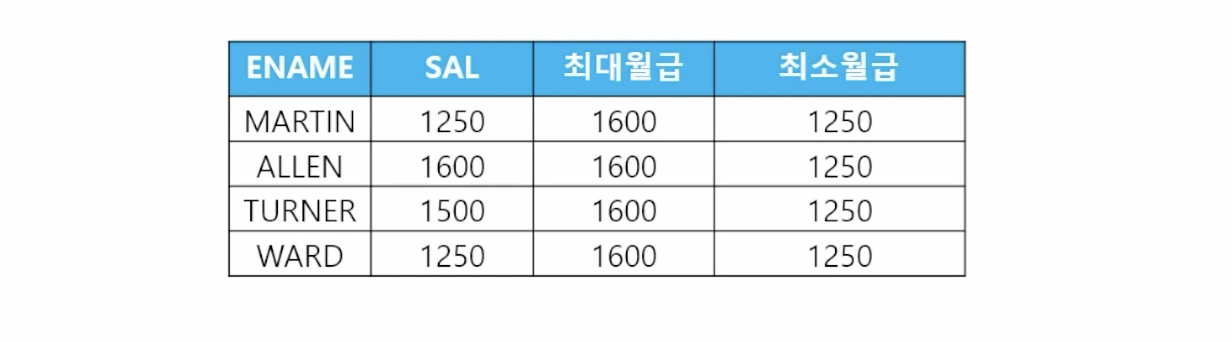
-
📋 문제 1) 직업이 SALESMAN인 사원들의 이름과 월급을 출력하면서 그 옆에 직업이 SALESMAN인 사원들의 최대월급과 최소월급을 출력하세요
select ename, sal, ( select max(sal) from emp where job = 'SALESMAN') as 최대월급, select min(sal) from emp where job = 'SALESMAN') as 최소월급 from emp where job = 'SALESMAN'; -
📋 문제 2) 부서번호가 20번인 사원들의 이름과 월급을 출력하고 그 옆에 20번 부서번호인 사원들의 평균월급이 출력되게 하시오
select ename, sal (select avg(sal) from emp where deptno = 20) from emp where deptno = 20;
-
📖 참고 📖 서브쿼리 사용
- select (서브쿼리)
- from (서브쿼리)
- where (서브쿼리)
- group by
- having (서브쿼리)
- order by (서브쿼리)
- 실행 순서 : from ➡️ where ➡️ group by ➡️ having ➡️ select ➡️ order by
📕 DML, DDL
📖 참고 📖 SQL 종류
- 1️⃣ : QUERY문
- select
- from
- where
- group by
- having
- order by
- 2️⃣ : DML문 (Data Manipulation Language)
- insert
- upadate
- delete
- merge
- 3️⃣ : DDL문
- 4️⃣ : DCL문
- 5️⃣ : TCL문
1. DML
-
1) 데이터 입력 (insert)
- insert into 테이블명(컬럼명)
values (삽입 값) - 문자('' 필요), 숫자 (필요X)
- 날짜 (to_date('RRRR/MM/DD' 필요)
- 🗒️ 예상 결과
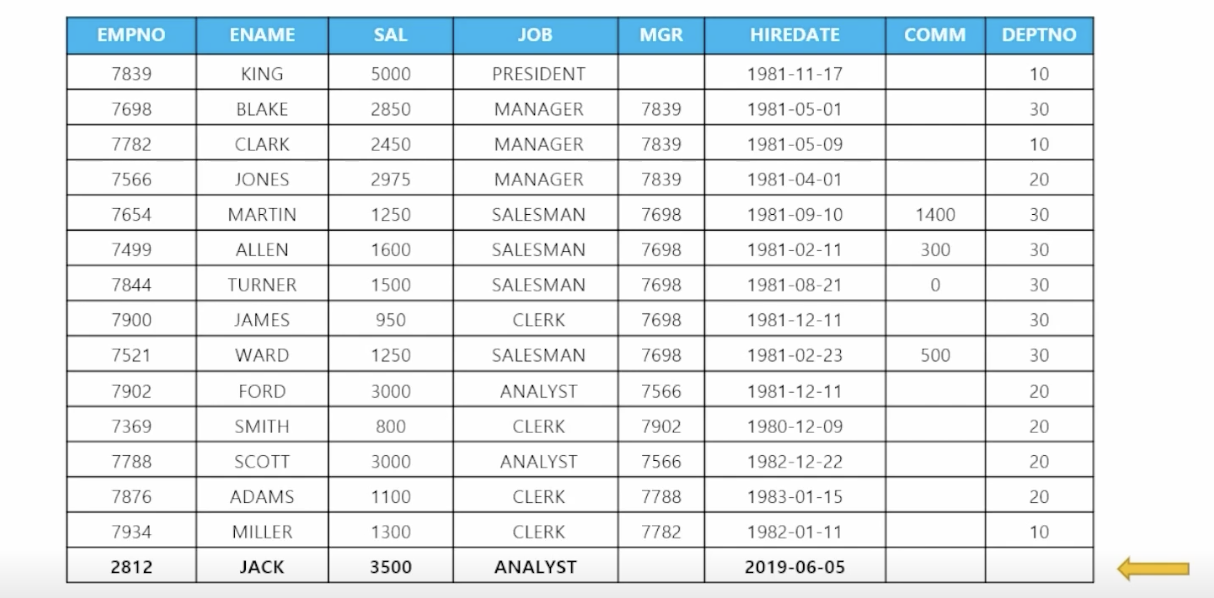
- 📋 문제 1) 다음과 같이 사원 테이블에 데이터를 입력하세요
insert into emp(empno, ename, sal, job, hiredate) // () 안 쓸 경우 전체 입력 values (2812, 'JACK', 3500, 'ANALYST', to_date('2019/06/05', 'RRRR/MM/DD')); - 📋 문제 2) 부서 테이블에 아래의 데이터를 입력하세요
- 부서번호 : 50
- 부서이름: RESEARCH
- 부서위치 : SEOUL
insert into dept(deptno, dname, loc) values (50, 'RESEARCH', 'SEOUL');
- insert into 테이블명(컬럼명)
-
2) 데이터 저장 및 취소 (COMMIT, ROLLBACK)
-
COMMIT : 데이터베이스에 영구히 저장
-
ROLLBACK : 작업 취소 (commit 상태로 되돌리기)
-
🗒️ 예상 결과
-
📋 문제 1) 데이터 입력 작업을 영구히 저장하거나 취소하세요
insert into emp(empno, ename, sal, deptno) values (9382, 'JACK', 3000, 10); rollback // 작업 취소 commit;
-
-
3) 데이터 수정 (UPDATE)
- update 테이블명
set 변경 컬럼 = 변경값
where 조건 컬럼 = 값 - 🗒️ 예상 결과
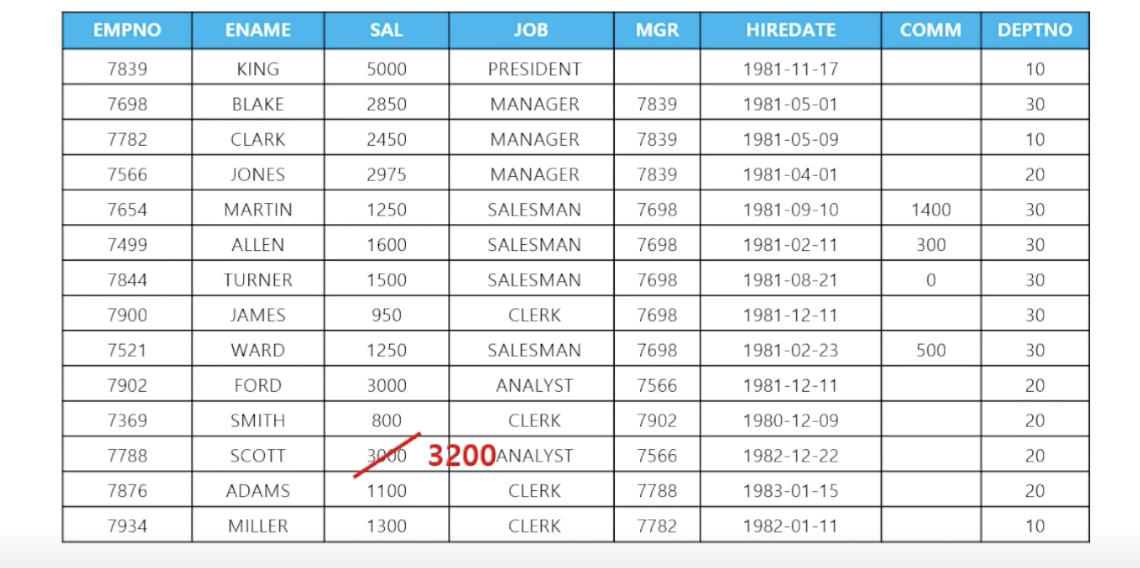
- 📋 문제 1)
update emp set sal = 3200 where ename = 'SCOTT'; - 📋 문제 2) 직업이 SALESMAN인 사원들의 커미션을 7000으로 수정하세요
update emp set comm = 7000 where job = 'SALESMAN';
- update 테이블명
-
4) 데이터 삭제 (DELETE, TRUNCATE, DROP)
-
delete
- 저장 공간 : 유지
- 저장 구조 : 유지
- delete from 테이블명
where 조건 컬럼 = 값
-
truncate
- 저장 공간 : 삭제
- 저장 구조 : 유지
- truncate table 테이블명 (rollback 불가)
-
drop
- 저장 공간 : 삭제
- 저장 구조 : 삭제
-
🗒️ 예상 결과
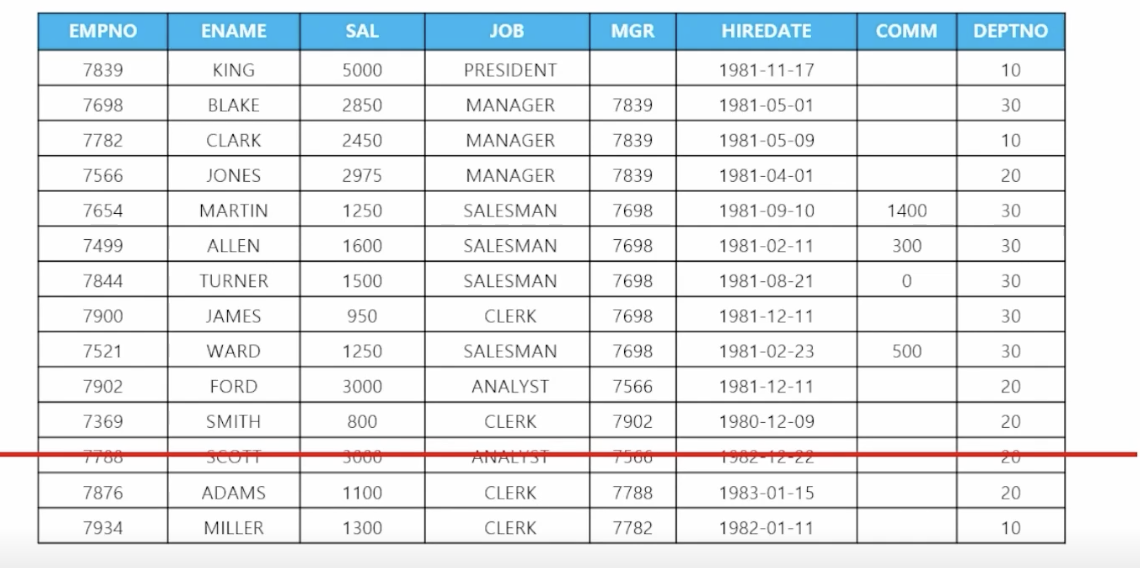
-
📋 문제 1) SCOTT의 데이터를 삭제하세요
delete from emp where ename = 'SCOTT'; -
📋 문제 2) 월급이 3000 이상인 사원들을 삭제하세요
delete from emp where sal >= 3000; -
📋 문제 3) 부서테이블을 지우는데 구조만 남기고 다 삭제하세요
truncate table emp;
-
-
5) 데이터 입력, 수정, 삭제 한번에 하기 (MERGE)
-
merge into 테이블명1
using 테이블명2
on (일치 조건)
when (not) matched then
select / update set / delete 컬럼명 -
merge문 작성시 alias 구분이 쉽게 되도록 작성 필요
- into절의 테이블 값 (or 서브쿼리)
- using절의 테이블 값 (or 서브쿼리)
-
🗒️ 예상 결과
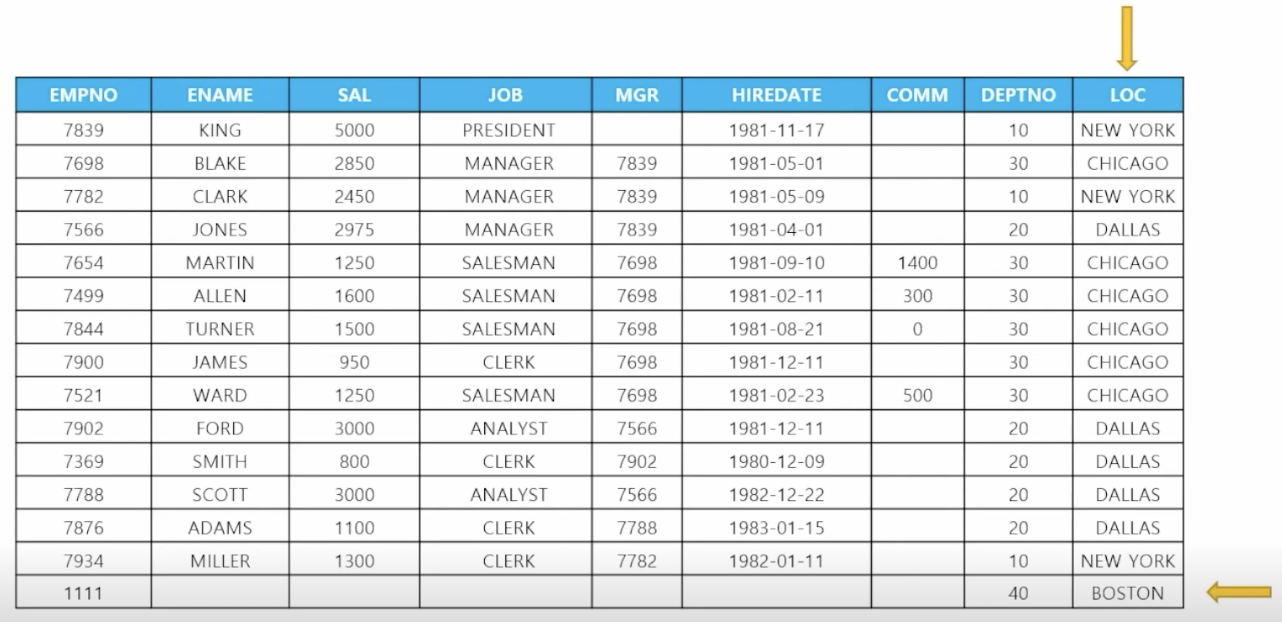
-
📋 문제 1) 사원 테이블에서 부서위치 컬럼을 생성하세요, 또한 동시에 부서 테이블만 있는 부서번호를 사원 테이블에 입력하세요
// 데이터 수정 alter table emp add loc varchar2(10); // MERGE merge into emp e using dept d //dept를 사용해서 emp를 merge함 on (e.deptno = d.deptno) when matched then update set e.loc = d.loc when not matched then insert (e.empno, e.deptno, e.loc) values (1111, d.deptno, d.loc); -
📋 문제 2) 사원 테이블에 부서명 컬럼을 추가하고 해당 사원의 부서명으로 값을 갱신하세요
// 부서명 칼럼 추가 alter table emp add dname varchar2(10); merge into emp e using dept d on (e.deptno = d.deptno) when matched then update set e.dname = d.dname;
-
-
6) 락 (LOCK)
-
같은 테이블을 같은 행에 update할 경우 먼저 수행한 쪽에서 lock을 잠김
- commit/rollback을 할 경우 lock 풀림
- 나중에 수행하지 못했던 부분은 lock 풀릴 경우 자동 수행됨
-
🗒️ 예상 결과
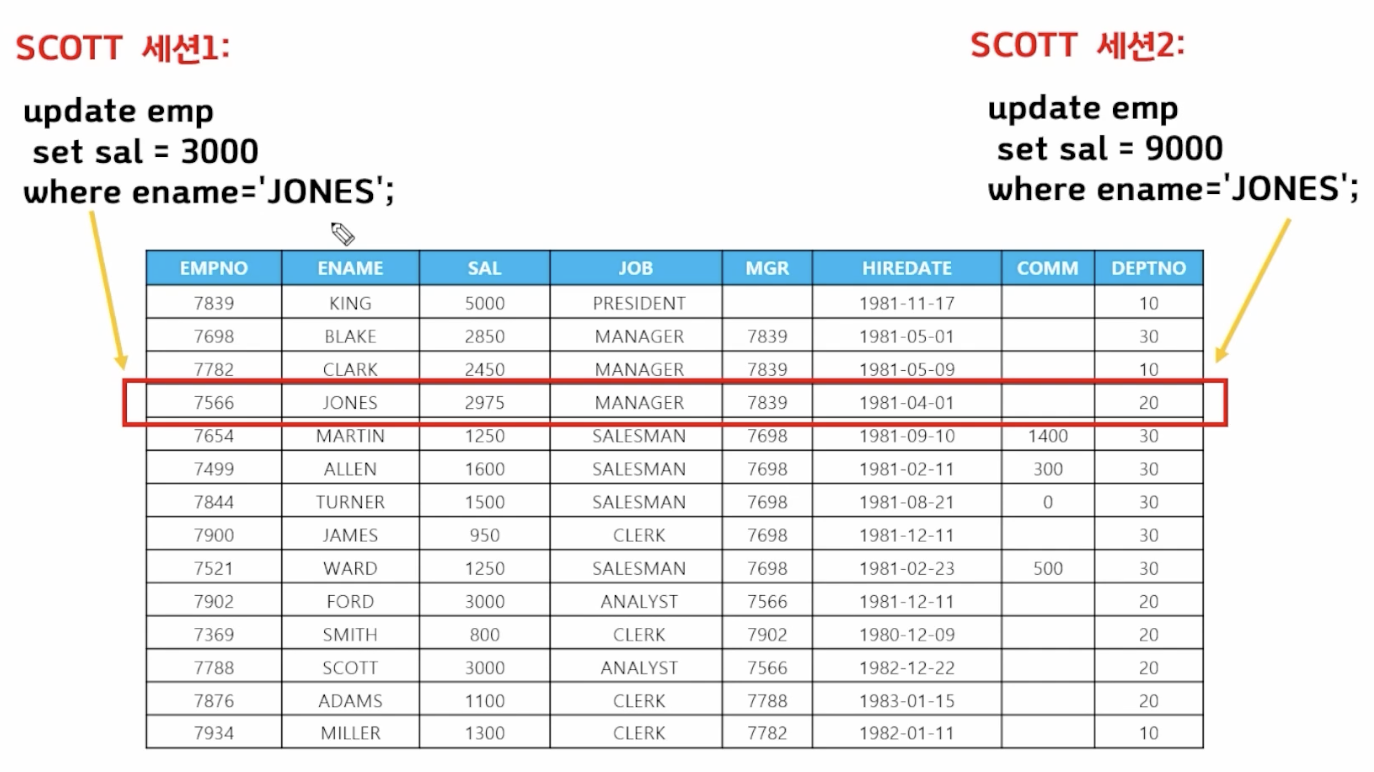
-
📋 문제 1)
// A update emp set sal = 9000 where ename = 'JONES'; // B update emp set sal = 0 where ename = 'JONES'; -
📋 문제 2) SCOTT으로 접속한 창을 2개를 열어놓은 상태에서 하나의 창에서 ALLEN의 월급을 2000으로 수정하고 커밋을 안한 상태에서 다른창에서 ALLEN의 부서번호를 10번으로 수정하면 수정이 될까? (안됨)
// A update emp set sal= 2000 where ename = 'ALLEN'; // B update emp set deptno = 20 where ename = 'ALLEN';
-
-
7) SELECT FOR UPDATE절
- 🗒️ 예상 결과
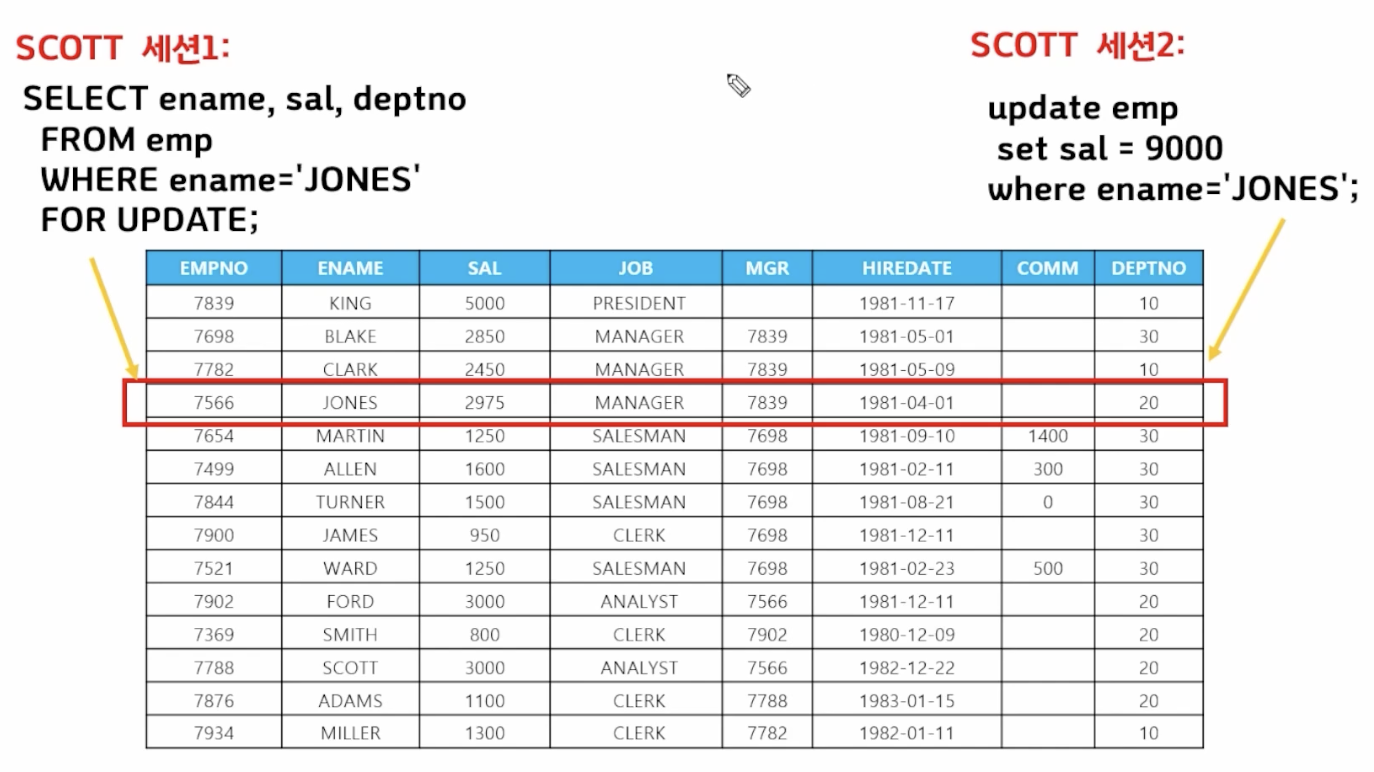
- 📋 문제 1)
select ename, sal, deptno from emp where ename = 'JONES' for update; // JONES행에 lock을 걸면서 update 수행 - 📋 문제 2) 부서번호가 10번, 20번인 이름과 직업과 부서번호를 조회하는 동안 그 누구도 부서번호 10번, 20번인 사원들의 데이터를 갱신하지 못하도록 하시오
select ename, job, deptno from emp where deptno in (10, 20) for update;
- 🗒️ 예상 결과
-
8) 서브쿼리를 사용하여 데이터 입력
- insert into 테이블명(컬럼명)
select 컬럼명
from 테이블명
where 조건 - 🗒️ 예상 결과

- 📋 문제 1) 사원 테이블과 같은 구조의 새로운 테이블을 생성하고 사원 테이블에서 부서번호가 10번인 사원들의 사원번호, 이름, 월급, 부서번호를 생성한 테이블에 입력하세요
// emp 테이블 '내용'과 동일하도록 emp2 생성 create table emp2 as select * from emp;
// emp 테이블 '구조'와 동일하도록 emp2 생성
create table emp2
as
select *
from emp
where 1 = 2; // 거짓insert into emp2 (empno, ename, sal, deptno) // value 대신 select 사용
select empno, ename, sal, deptno
from emp
where deptno = 10;- 📋 문제 2) 부서 테이블과 같은 구조의 테이블을 DEPT2라는 이름으로 생성하고 부서번호가 20번, 30번의 모든 컬럼의 데이터를 DEPT2에 입력하시오 (query 작성시 단계별로 진행해도 되고, 한 번에 subquery를 작성하여 데이터를 넣어도 되지만 테이블 구조 생성 후 데이터를 삽입하는 형태로 작성해보세요) ```sql create table dept2 as select * from dept where 1 = 2; insert into dept2 select * from dept where dept in (20, 30); - insert into 테이블명(컬럼명)
-
9) 서브쿼리 사용하여 데이터 수정
- 🗒️ 예상 결과
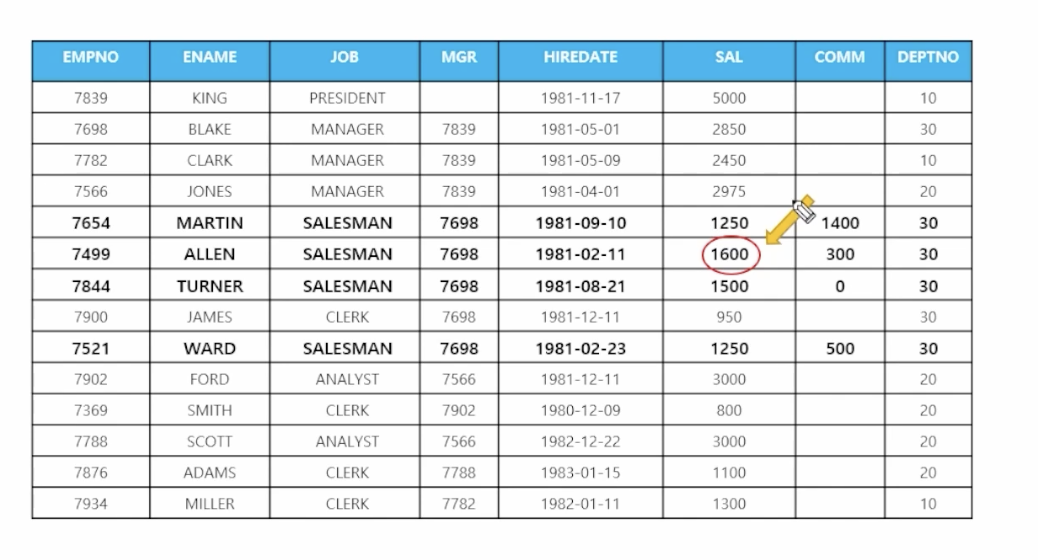
- 📋 문제 1) 직업이 SALESMAN인 사원들의 월급을 ALLEN의 월급으로 수정하세요
update emp set sal = (select sal from emp where ename = 'ALLEN') where job = 'SALESMAN'; - 📋 문제 2) 부서번호가 30번인 사원들의 직업을 MARTIN의 직업으로 변경하세요
update emp set job = (select job from emp where ename = 'MARTIN') where deptno = 30;
- 🗒️ 예상 결과
-
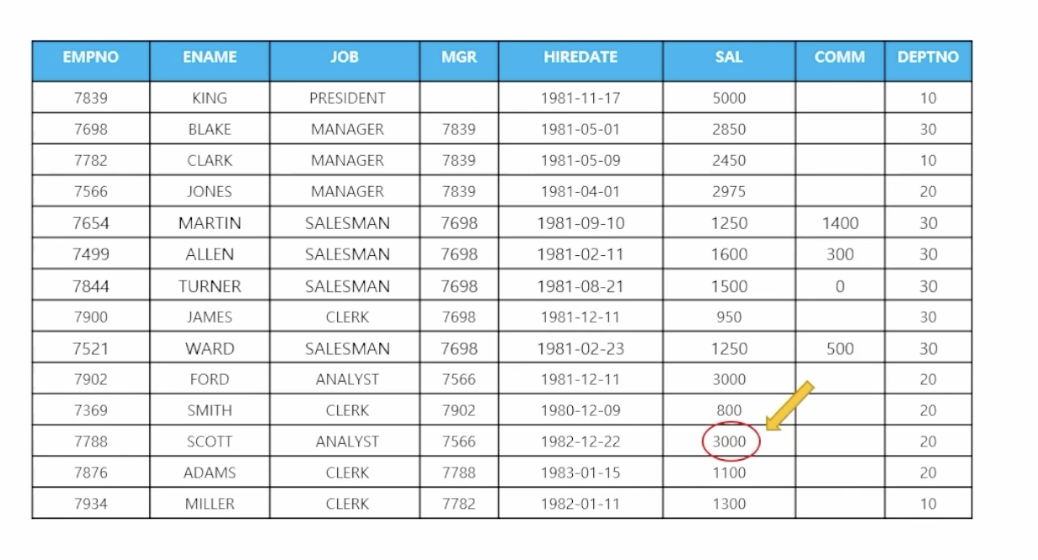
10) 서브쿼리 사용하여 데이터 삭제
-
🗒️ 예상 결과
-
📋 문제 1) SCOTT보다 더 많은 월급을 받는 사원들을 삭제하세요
delete from emp where sal > (select sal from emp where ename = 'SCOTT'); -
📋 문제 2) ALLEN보다 늦게 입사한 사원들의 모든 행을 지우세요
delete from emp where hiredate > (select hiredate from emp where ename = 'ALLEN');
-
-
11) 서브쿼리를 사용하여 데이터 합치기
-
🗒️ 예상 결과
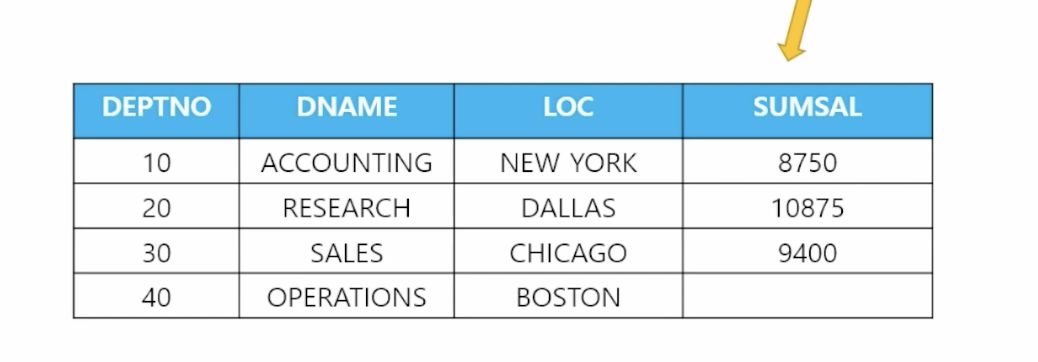
-
📋 문제 1) 다음과 같이 부서테이블에 부서번호별 토탈월급 데이터가 입력되게하세요
// 테이블에 컬럼 추가 alter table dept add sumal number(10); // sum(sal) 구하기 select deptno, sum(sal) from emp group by deptno; // 정답 (merge + using + 서브쿼리) merge into dept d using (select deptno, sum(sal) as sumsal // 실제로 존재하지 않아 서브쿼리 이용 from emp group by deptno) v on (d.deptno = v.deptno) when matched then update set d.sumsal = v.sumsal; -
📋 문제 2) 부서 테이블에 cnt라는 컬럼을 추가하고 해당 부서번호의 인원수로 값을 갱신하시오
alter table dept add cnt number(10); merge into dept d using (select deptno, count(*) as cnt from ename group by deptno) v on (d.deptno = v.deptno) when matched then update set d.cnt = v.cnt;
-
2. 계층형 질의문
- 1) 서열 주고 데이터 출력 (level)
-
start with 컬럼명=값
connect by prior 조건 컬럼 -
🗒️ 예상 결과
-
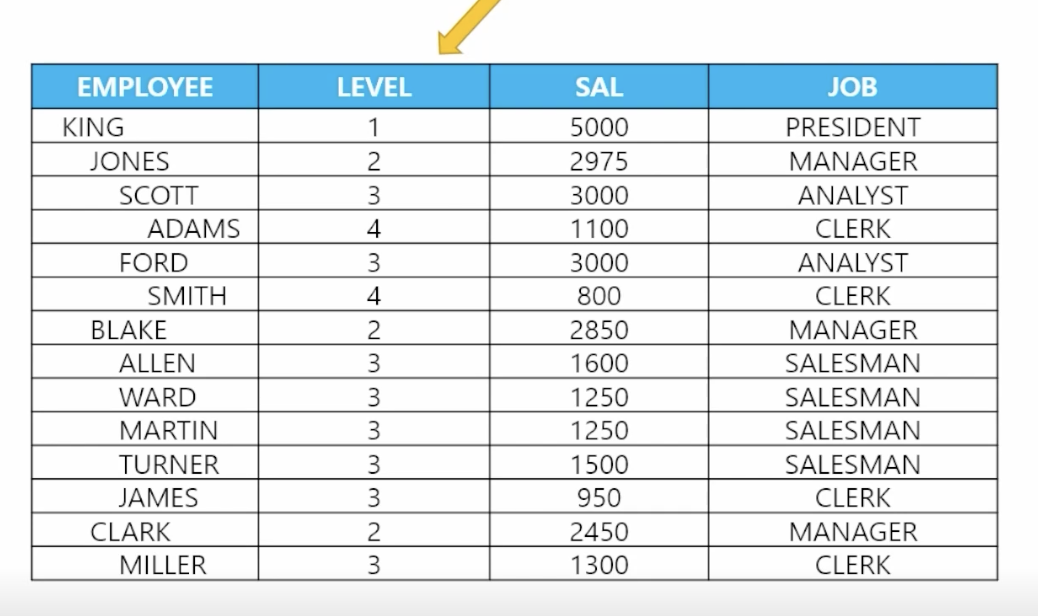
📋 문제 1) 다음과 같이 사원 테이블의 서열(level)을 출력하세요
select ename, level, sal, job from emp start with ename = 'KING' // 시작 데이터 (서열 1위부터 시작) connect by prior empno = mgr; // level 높은 순대로 공백 채우기 select rpad(' ', level * 3) || ename, sal, job from emp start with ename = 'KING' connect by prior empno = mgr; -
📋 문제 2) 서열이 2위인사원들의 이름과 서열과 직업을 출력하세요
select ename, level, job from emp where level = 2 start with ename = 'KING' connect by prior empno = mgr; -
🗒️ 예상 결과
-
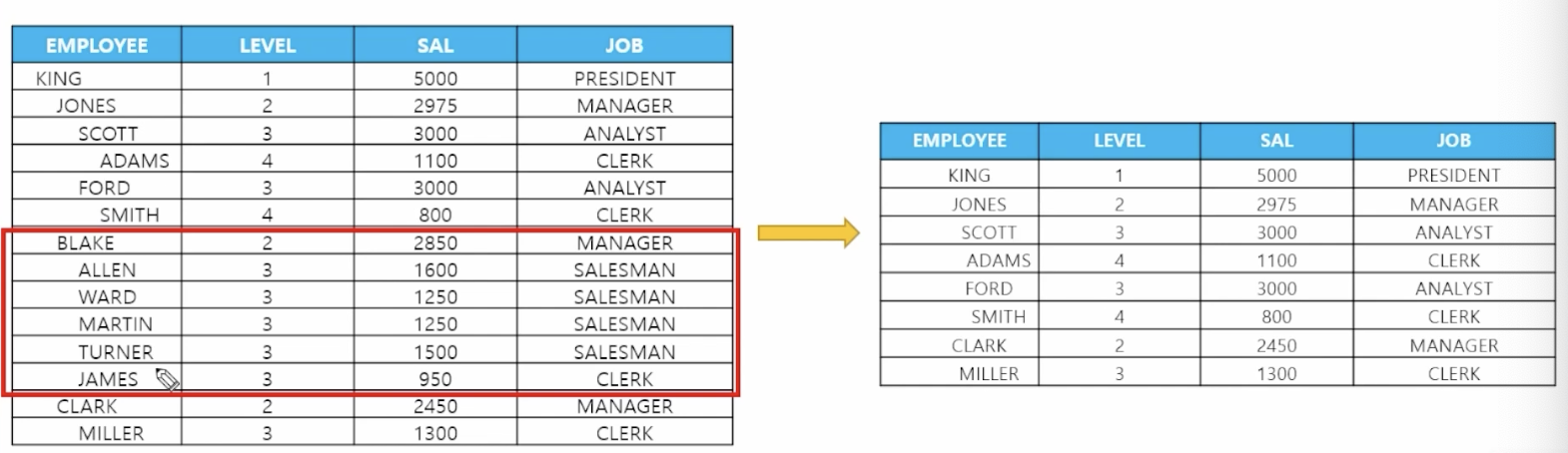
📋 문제 3) 서열 순서를 유지한 상태에서 BLAKE와 BLAKE의 팀원들이 출력되지 않게 하시오
select ename, level, sal, job from emp start with enmae = 'KING' connect by prior empno = mgr and ename != 'BLAKE'; -
📋 문제 4) 사원 테이블에서 서열 순서대로 이름과 서열과 월급과 직업을 출력하는데 SCOTT과 SCOTT의 팀원과 FORD와 FORD의 팀원들이 출력되지 않게 하세요
select ename, level, sal, job from emp start with ename = 'KING' connect by prior empno = mgr and ename not in ('SCOTT', 'FORD'); -
🗒️ 예상 결과
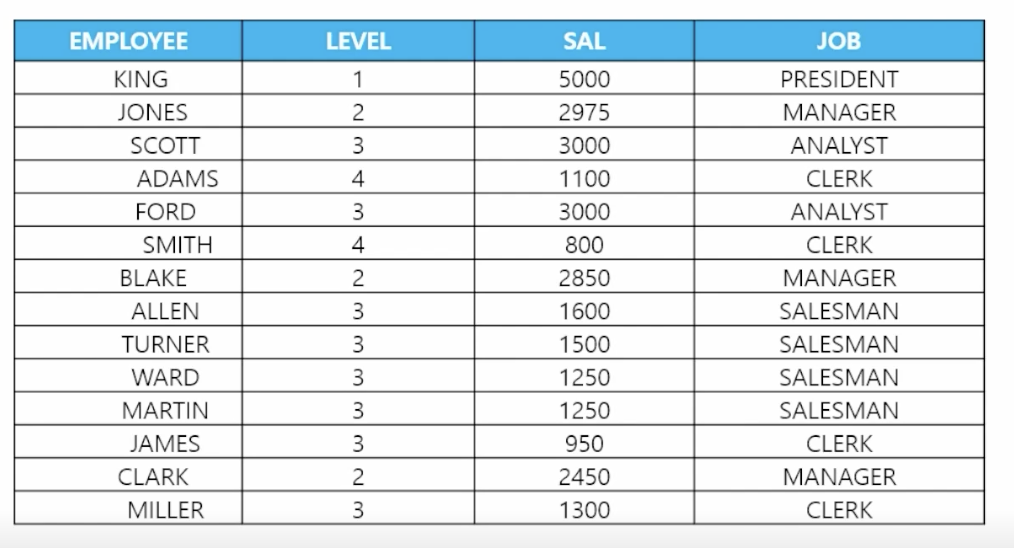
-
📋 문제 5) 서열 순서를 유지한 상태에서 월급이 높은 순서대로 출력하세요
select rpad(' ', level * 3) || ename as employee, level, sal, job from emp start with ename = 'KING' connect by prior empno = mgr order by sal desc; // 서열 순서 깨지고 정렬됨 (수정 필요) select rpad(' ', level * 3) || ename as employee, level, sal, job from emp start with ename = 'KING' connect by prior empno = mgr order siblings by sal desc; // 서열 유지 -
📋 문제 6) BLAKE와 BLAKE의 팀원들만 출력하는데 서열을 유지한 상태에서 월급이 낮은 사원부터 출력하세요
select rpad(' ', level * 3) || ename as employee, level, sal, job from emp start with ename = 'BLAKE' connect by prior empno = mgr order siblings by sal asc; -
🗒️ 예상 결과
-
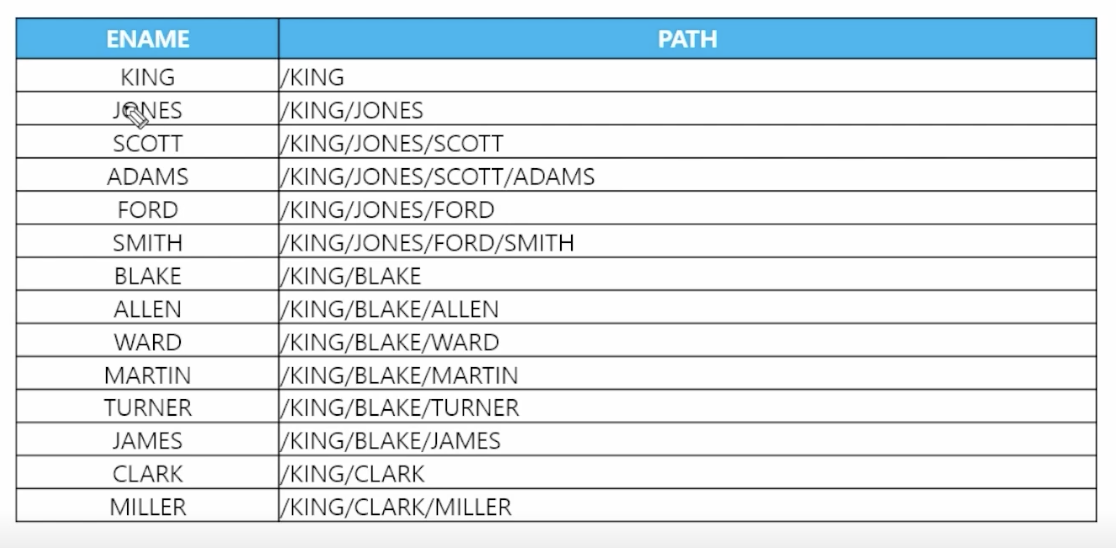
📋 문제 7) 다음과 같이 자기의 서열순서가 어떻게 되는지 출력하세요
select ename, sys_connect_by_path(ename, '/') as path from emp start with ename = 'KING' connect by prior empno = mgr; -
📋 문제 8) 다음과 같이 월급도 출력되게 하세요
select ename || '(' || sal || ')', sys_connect_by_path(ename || '(' || sal || ')', '/') as path from emp start with ename = 'KING' connect by prior empno = mgr;
-
3. DDL
- 1) 일반 테이블 생성 (CREATE TABLE)
- create table 테이블명
(컬럼명 자료형(크기), ...) - 🗒️ 예상 결과
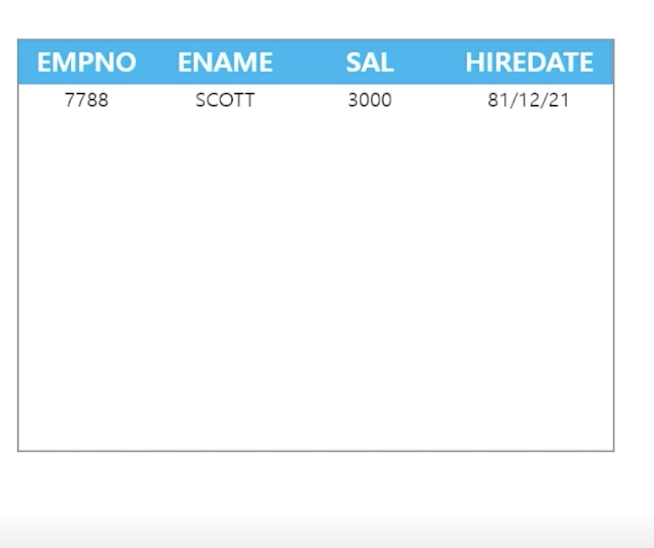
- 📋 문제 1) 오라클에 데이터를 저장할 테이블을 다음과 같이 생성하시오
// 테이블 생성 create table emp93 (empno number(10), // number 숫자형 데이터 타입 ename varchar2(10), // varchar2 문자형 데이터 타입 sal number(10, 2), // 숫자 10자리 허용하는데 2자리는 소수점 자리로 허용 hiredate date); // date 날짜형 데이터 타입 // 데이터 입력 insert into emp93 (empno, ename, sal, hiredate) values (7788, 'SCOTT', 3000, to_date('81/12/21', 'RR/MM/DD')); - 📋 문제 2) 다음의 테이블을 생성하세요
- 테이블명 : emp50
- 컬럼명 : empno, ename, sal, job, deptno
create table emp50 (empno number(10), ename varchar2(10), sal number(10, 2), job varchar2(20), deptno number(10)); // 데이터 입력 insert into emp50 values (2912, 'SCOTT', 3000, 'SALESMAB', 20);
- create table 테이블명
- 2) 임시 테이블 생성 (CREATE TEMPORARY TABLE)
-
on commit delete rows : 커밋하면 데이터 지움
-
on commit preserve rows : 세션을 종료하면 데이터 지움
-
🗒️ 예상 결과
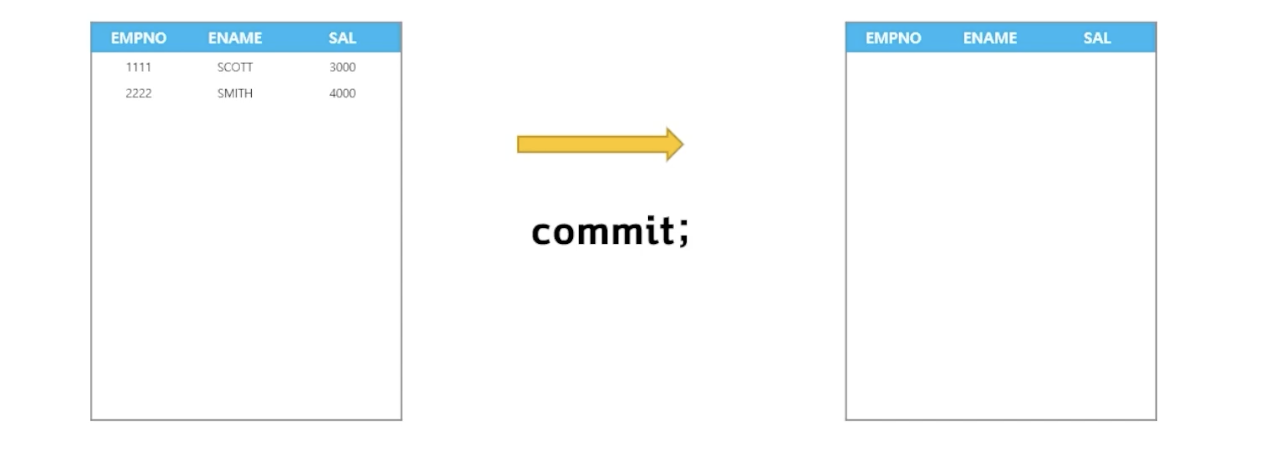
-
📋 문제 1) 다음과 같이 테이블을 만들고 데이터를 저장하는데 commit을 하면 데이터가 사라지게 만드세요
create global temporary table emp37 (empno number(10), ename varchar2(10), sal number(10) ) on commit delete rows; insert into emp37 values (1111, 'SCOTT', 3000); insert into emp37 values (2222, 'SMITH', 4000); commit; -
📋 문제 2) 세션을 종료하면 데이터가 사라지는 임시테이블을 다음과 같이 생성하세요
- 테이블명 : emp94
- 컬럼명 : empno, ename, sal
create global temporary table emp94 (empno number(10), ename varchar2(10), sal number(10)) on commit preserve rows; insert into emp94 values (1111, 'SCOTT', 3000); insert into emp94 values (2222, 'SMITH', 4000); commit;
-
📕 VIEW, INDEX
1. VIEW
- 1) 복잡한 쿼리 단순하게 하기
- create view 뷰 명
as
select절 - 바라보는 용도이지, 데이터 저장X (view update하면 table도 변경)
- 그룹 함수를 사용하여 뷰 생성시 별칭 필요
- 목적
- 보안 용도로 제한적 보기 역할
- 복잡한 쿼리문 간단하게 검색
- 🗒️ 예상 결과
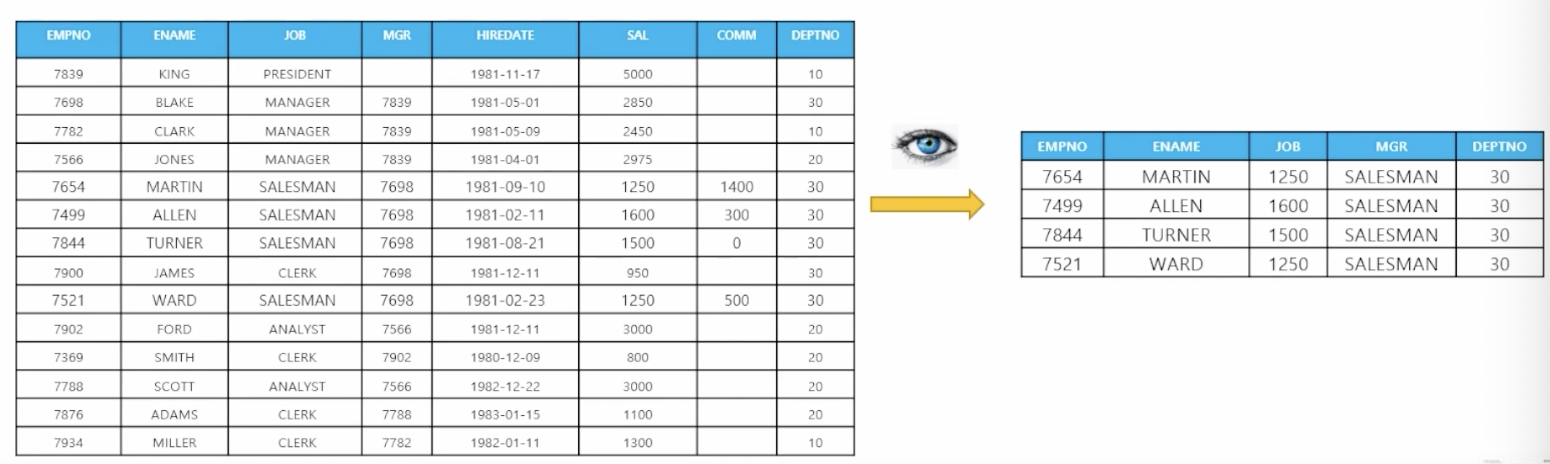
- 📋 문제 1) 사원 테이블에서 직업이 SALESMAN인 사원들의 사원번호, 사원이름, 직업, 관리자번호, 부서번호만 바라볼 수 있는 VIEW를 만드세요
create view emp_view as select empno, ename, job, mgr, deptno from emp where job = 'SALESMAN';
set sal = 0
where name = 'MARTIN';- 📋 문제 2) 사원 테이블에서 부서번호가 20번인 사원들의 사원번호와 사원이름, 직업, 월급을 볼 수 있는 뷰를 생성하세요 ```sql create view emp_view as select empno, ename, job, sal from emp where empno = 20;- 🗒️ 예상 결과
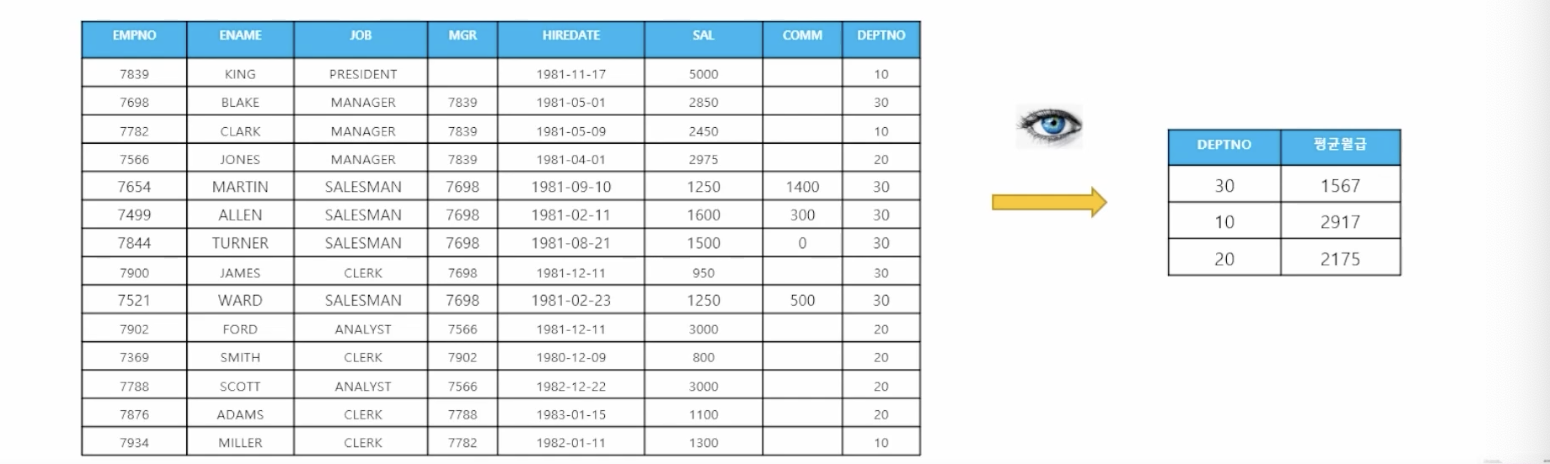
- 📋 문제 3) 사원 테이블에서 부서번호와 부서번호별 평균 월급만 바라볼 수 있는 VIEW를 만드세요
create view emp_view as select deptno, round(avg(sal)) as avgsal // 컬럼 별칭 필수! from emp group by deptno; - 📋 문제 4) 직업, 직업별 토탈월급을 출력하는 view를 emp_view96으로 생성하세요
create view emp_view96 as select job, sum(sal) as 토탈월급 from emp group by job;
- create view 뷰 명
- 2) 데이터 검색 속도 높이기 (INDEX)
-
🗒️ 예상 결과

-
📋 문제 1) 월급이 3000인 사원의 이름과 월급을 인덱스를 통해서 빠르게 검색하세요
select ename, sal, rowid from emp where sal = 3000; -
📋 문제 2) 사원 테이블의 직업에 인덱스를 생성하세요
create index emp_job on emp(job); select ename, job from emp where job = 'PRESIDENT';
-
📖 참고 📖
- ✏️ dbms_xplan.display (sql 실행 계획 확인)
- explain plan for
select문
select * from table(dbms_xplan.display);- ✏️ row id
- 행의 주소
- file 번호 + 블럭 번호 + row 번호
- 3) 중복되지 않는 번호 만들기 (SEQUENCE)
-
create sequence 시퀀스 명
-
시퀀스 명.nextval : 다음 번호 지정
-
🗒️ 예상 결과
-
📋 문제 1) 사원 번호에 번호를 입력할 때 데이터가 중복되지 않고 순서대로 입력되게 하세요
create sequence seq1; select seq1.nextval from dual; // 옵션 추가 create sequence seq2 start with 1 // 1부터 시작 maxvalue 100 // 100까지 increment by 1; // 1씩 증가 create table emp500 (empno number(10), ename varchar2(10)); insert into emp500 value (seq2.nextval, 'scott'); // scott이 emp500에 삽입될 때 순차적으로 번호 -
📋 문제 2) dept 테이블에 부서번호를 50번부터 입력하고 10씩 증가하는 시퀀스를 생성하시오 (시퀀스 이름은 dept_seq1)
create sequence dept_seq1 start with 50 increment by 10; insert into dept(deptno, dname, loc_ values(dept_seq1.nextval, 'transfer', 'seoul');
-
📕 FLASHBACK
1. 실수로 지운 데이터 복구
- 1) FLASHBACK QUERY
-
delete from emp; commit;한 상태
-
commit 후 rollback이 안될 경우
-
15분 안에만 복구 가능 (기본값 900초지만 회사마다 다름)
-
select *
from emp
as of timestamp(systimestamp - interval '5' minute); -
🗒️ 예상 결과
-
📋 문제 1) 사원 테이블을 지우기 전인 5분전의 사원 테이블의 상태를 검색하세요
delete from emp; // 사원 테이블 삭제 select * from emp as of timestamp(systimestamp - interval '5' minute); // 현재 날짜의 시간 보여줌 -
📋 문제 2) 사원 테이블의 월급을 모두 0으로 변경하고 commit한 후에 사원 테이블을 1분전 상태로 되돌리시오
update emp set sal = 0; commit; select * // 현재 상태 확인 from emp as of timestamp(systimestamp - interval '1' minute); // 해당 값으로 갱신하기 merge into emp e using (select empno, sal from emp as of timestamp(systimestamp - interval '1' minute) ) s on (e.empno = s.empno) when matched then update set e.sal = s.sal;
-
📖 참고 📖
- ✏️ systimestamp
- 현재 날짜의 시간 보여줌
- ✏️ show parameter undo
- undo_retention의 값 900 확인

- 2) FLASHBACK TABLE
-
delete from emp; commit;한 상태
-
alter table 테이블명 enable row movement;
flashback table 테이블명 to timestamp(systimestamp - interval '5' minute); -
15분(900초 안에서만 복구 가능)
-
🗒️ 예상 결과
-
📋 문제 1) 사원 테이블을 지우기 전인 5분 전의 상태로 되돌리세요
delete from emp; // 사원 테이블 모두 삭제 commit; alter table emp enable row movement; // emp 테이블을 복구 가능한 상태로 변경 flashback table emp to timestamp(systimestamp - interval '5' minute); -
📋 문제 2) 사원 테이블의 월급을 전부 0으로 변경하고 commit한 다음에 사원 테이블의월급을 전부 0으로 변경하기 전 상황으로 복구하시오
update emp set sal = 0; commit; alter table emp enable row movement; flashback table emp to timestamp(systimestamp - interval '5' minute);
-
- 3) FLASHBACK DROP
-
flashback table 테이블명 to before drop;
-
휴지통 비우기(purge recyclebin;)만 하지 않으면 복구 가능
-
drop table emp;한 상태 // drop하면 휴지통으로 들어감
-
🗒️ 예상 결과
-
📋 문제 1) drop한 테이블을 지우기 전인 상태로 되돌리세요
drop table emp; select * from emp; // 구조도 날라가서, 오류 발생 select * from user_recyclebin // drop된 휴지통 정보 확인 order by droptime desc; flashback table emp to before drop; -
📋 문제 2) dept 테이블을 drop하고 다시 복구하세요
drop table dept; flashback table dept to before drop;
-
- 4) FLASHBACK VERSION QUERY
-
테이블의 과거부터 현재까지의 변경된 히스토리 확인
-
versions between timestamp to_timestamp('23/09/10 04:37:10', 'RRRR-MM-DD HH24:MI:SS') and maxvalue
-
commit이 진행되어야 version 업데이트 가능
-
version_starttime의 초기값은 null로 되어있으므로 (order by) nulls first 작성하면 순서대로 확인하기 용이함
-
to_timestamp같은 특정 시점을 시작 지점으로 설정 가능 (between timestamp 구문에서 종료시점도 설정 가능)
-
🗒️ 예상 결과
-
📋 문제 1) 사원 테이블이 그동안 어떻게 변경되어왔는지 확인하세요
select ename, sal, deptno, versions_starttime, versions_endtime, versions_operation from emp versions between timestamp to_timestamp('23/09/10 04:37:10', 'RRRR-MM-DD HH24:MI:SS') AND MAXVALUE // max값은 현재 시간 where ename = 'KING' order by versions_starttime nulls first; -
📋 문제 2) 부서 테이블의 부서위치를 전부 seoul로 변경하고 dept 테이블이 그동안 어떻게 변경되어왔는지 확인하세요
update dept set loc = 'SEOUL'; commit; select * from dept; select deptno, dname, loc, versions_starttime, versions_endtime, versions_operation from dept versions between timestamp to_timestamp('23/09/10 04:37:10', 'RRRR-MM-DD HH24:MI:SS') and maxvalue order by versions_starttime nulls first;
-
- 5) FLASHBACK TRANSACTION QUERY
-
🗒️ 예상 결과
-
📋 문제 1) 실수로 데이터 지워서 다시 복구할 수 있는 스크립트를 구할 수 있다면?
select ename, sal from emp where ename = 'KING'; update emp set sal = 8000 where ename = 'KING'; commit; update emp set deptno = 20 where ename = 'KING'; select versions_startscn, versions_endscn, versions_operation, sal, deptno from emp versions between scn minvalue and maxvalue where ename = 'KING';
-
📖 참고 📖
- ✏️ sqlplus "/as sysdba"
- 최고 권한자로 접속
- ✏️ show user
- 접속자 확인
- 최고 권한자일 경우 : sys
- ✏️ shutdown immediate
- 데이터베이스 정상 종료
- ✏️ startup mount
- 데이터베이스 구조 바꾸기 위해서 mount로 올림
- ✏️ alter database archivelog
- 데이터베이스를 achivelog 모드로 변경
- 데이터베이스 장애가 났을 때 언제든 복구 가능한 모드
- ✏️ alter database add supplemental log data;
- oracle 에디션 중 expree 에디션(xe) 사용할 경우 에러 발생
- enterprise 에디션에서 실행 가능
- ✏️ connect / as sysdba ➡️ alter database open; ➡️ connect scott/tiger
- ✏️ alter user scott
account unlock;- ✏️ alter user scott
identified by tiger;- ✏️ grant dba to scott;
- ✏️ connect scott/tiger
📕 데이터 품질 높이기
1. 데이터 품질 높이기
-
데이터 제약 : 데이터에 엉뚱한 데이터가 들어가지 않게 막음
-
제약 생성 방법
- 1️⃣ : 테이블 생성할 때 제약을 걸면서 생성
- 2️⃣ : 만들어진 테이블에 제약을 거는 방법
-
1) PRIMARY KEY 제약
-
alter table 테이블명
add constraint 제약명 primarykey(컬럼명); -
중복된 데이터 + null 값 입력 제한
-
🗒️ 예상 결과
-
📋 문제 1) 사원 번호에 중복된 데이터와 null값을 입력안되게 하려면?
// 테이블 생성시 제약 create table dept2 (deptno number(10) constraint dept2_deptno_pk primary key, dname varchar2(10), loc varchar2(10)); insert into dept2 values (10, 'aaa', 'bbb'); insert into dept2 values (10, 'ccc', 'ddd'); // 에러 (중복된 값 안됨) insert into dept2 values(null, 'eee', 'fff); // 에러 (null 값 안됨) // 제약 삭제 alter table dept2 drop constraint dept2_deptno_pk; // 이미 생성된 테이블에 제약 alter table dept add constraint dept_deptno_pk primary key(deptno); // 제약 확인 select table_name, contraint_name from user_contraints where table_name = 'DEPT'; insert into dept(deptno, loc) vales (10, 'aaa'); // 에러 (무결성 제약조건 (dept_deptno_pk에 위배) -
📋 문제 2) 사원 테이블의 empno에 primary key를 생성하시오
alter table emp add constraint emp_empno_pk primary key(empno);
-
-
2) UNIQUE 제약
- alter table 테이블명
add constraint 제약명 unique(컬럼명); - 중복된 데이터 입력 제한
- 🗒️ 예상 결과
- 📋 문제 1) 사원번호에 중복된 데이터가 입력 안되게 하려면?
// 테이블 생성하면서 dname에 unique 제한 create table dept3 (deptno number(10), dname varchar2(14) constraint dept3_dname_un unique, loc varchar2(10)); // 제약 확인 select a.constraint_name, a.constraint_types, b.column_name from user_constraint s, user_cons_columns b where a.table_name = 'DEPT3' // 대문자 필요 and a.constraint_name = b.constraint_name; insert into dept3 values (10, 'ACCOUNTING', 'NEW YORK'); // 만들어진 테이블에 제약 create table dept4 (deptno number(10), dname varchar2(14), loc varchar2(10)); alter table dept4 add constraint dept4_dname_un unique(dname); insert into dept3 values (10, 'ACCOUNTING', 'NEW YORK'); - 📋 문제 2) 사원번호, 사원이름, 월급, 직업을 담는 테이블을 아래와 같이 생성하는데 사원번호 컬럼에 중복된 데이터가 입력되지 않도록 제약을 걸어서 생성하세요
- 테이블명 : emp100
- 컬럼명 : empno, ename, sal, job
create table emp100 (empno number(10) constraint emp100_empno_un unique. ename varchar2(10), sal number(10), job varchar2(10)); - 📋 문제 3) 사원 테이블(emp)의 사원번호에 중복된 데이터가 있는지 검색헤보세요
select empno, count(*) from emp group by empno having count(*) >= 2; - 📋 문제 4) 사원 테이블(emp)의 사원번호에 중복된 데이터가 입력되지 못하도록 제약을 거세요
alter table emp add contraint emp_empno_un unique(empno);
- alter table 테이블명
-
3) NOT NULL 제약
- alter table 테이블명
modify 컬럼명 constraint 제약명 not null; - null 값이 들어오지 못하게 제약
- 🗒️ 예상 결과
- 📋 문제 1) 사원 이름에 null 입력 안되게 하려면?
// 생성시 create table dept5 (deptno number(10), dname varchar2(14), loc varchar2(10) constraint dept5_loc_nn not null); // 수정시 create table dept6 (deptno number(10), dname varchar2(14), loc varchar2(10))); alter table dept6 modify loc constraint dept6_loc_nn not null; // add가 아닌 modify - 📋 문제 2) 사원 테이블에 사원이름에 NULL값이 몇건 존재하는지 검색하세요
select count(*) from emp where ename is null; - 📋 문제 3) 사원 테이블에 사원이름에 not null 제약을 거세요
alter table emp modify ename constraint emp_ename_nn not null; - 📋 문제 4) 부서 테이블에 부서번호에 not null 제약을 거세요
alter table dept modify depno constraint dept_depno_nn not null;
- alter table 테이블명
-
4) CHECK 제약
-
alter table 테이블명
add constraint 제약명(컬럼명 조건); -
특정 컬럼에 조건에 해당하는 데이터만 수정/입력되도록 함
-
🗒️ 예상 결과
-
📋 문제 1) 월급 컬럼에 9000보다 큰 월급은 입력되지 못하게 하려면?
// 생성시 create table emp6 (empno number(10), ename varchar2(20), sal number(10) constraint emp6_sal_ck check (sal between 0 and 9000)); update emp6 // 에러 (조건에 맞지 않는 데이터 입력) set sal = 9000 where ename = 'CLARK'; // 제약 삭제 alter table emp6 drop constraint emp6_sal_ck; // 수정시 alter table emp add constraint emp_sal_ck(sal between 0 and 9000); -
📋 문제 2) 사원 테이블의 부서번호에 부서번호가 10번, 20번 30번만 입력, 수정되도록 체크 제약을 거세요
alter table emp add constraint emp_deptno_ck(deptno in (10, 20, 30)); -
📋 문제 3) 부서 테이블의 부서위치에 NEW YORK, DALLAS, CHICAGO, BOSTON만 입력, 수정되도록 체크제약을 거세요
alter table dept add constraint dept_loc_ck(loc in ('NEW YORK', 'DALLAS', 'CHICAGO', 'BOSTON')); -
📋 문제 4) 사원 테이블에 이메일 컬럼을 다음과 같이 추가하고 이메일에 @가 있어야지만 데이터가 입력 또는 수정되도록 체크 제약을 거세요
alter table emp add email varchar2(50); alter table emp add constraint emp_email_ck(email like '%@%');
-
-
5) FOREIGN KEY 제약
-
alter table 테이블명
add constraint 제약명 foreign key(외래키 컬럼명) references 테이블명(기본키 컬럼명)); -
🗒️ 예상 결과
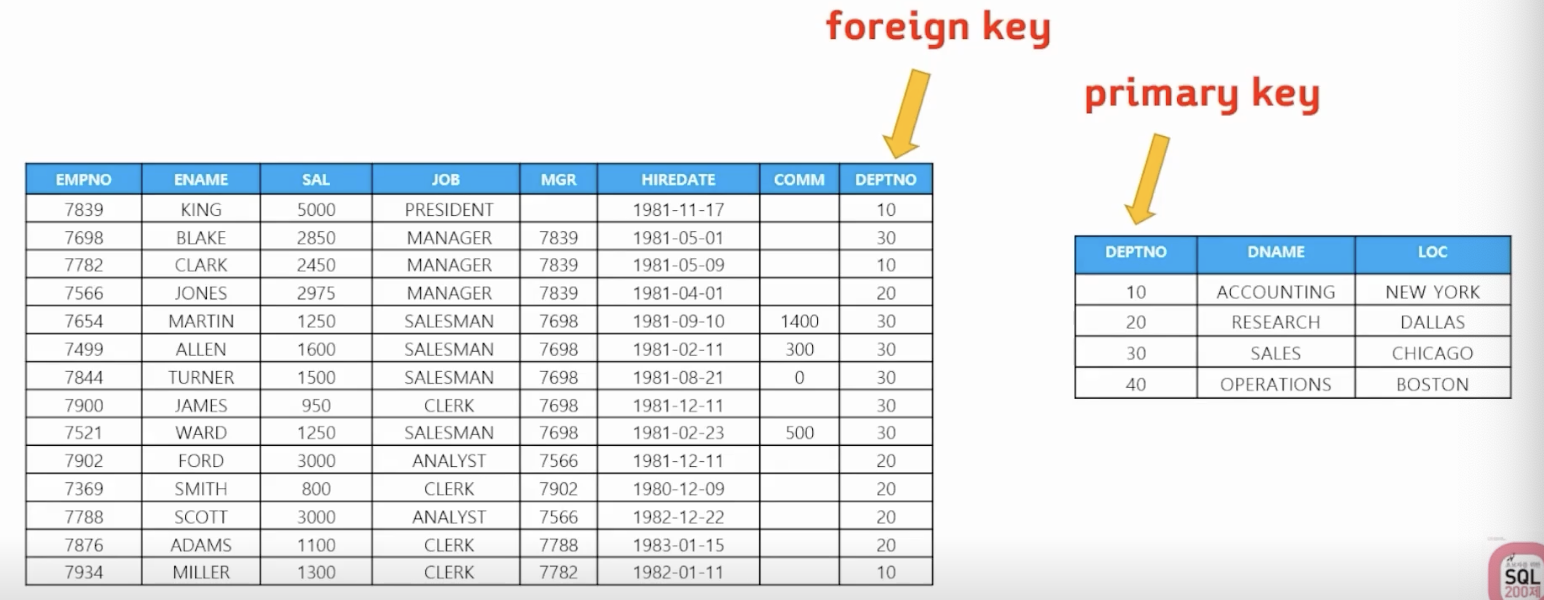
-
📋 문제 1) 부서 테이블에 있는 부서번호만 사원 테이블에 입력되게 하려면?
create table dept7 ( deptno number(10) constraint dept7_deptno_pk primary key, dname varchar2(14), loc varchar2(10)); create table emp7 (empno number(10), ename varchar2(20), sal number(10), deptno number(10) constraint emp7_empno_fk references dept7(deptno)); // 제약 확인 select a.constraint_name, a.constraint_type, b.column_name from user_constraints a, user_cons_columns b where a.table_name in ('DEPT7', 'EMP7') and a.constraint_name = b.constraint_name; insert into emp7 values (1111, 'JACK', 3000, 80); // 에러 (emp7 테이블에 80(기본키) 없어서 제약조건 위배) // 제약 삭제 alter table dept7 drop constraint dept_deptno_pk; // 참고되어 있는 모든 테이블 삭제해야 제약조건 삭제 가능 alter table dept7 drop constraint dept_deptno_pk cascade; // 참조된 테이블도 함께 삭제 -
📋 문제 2) 사원 테이블에 empno에 primary key를 거시오
alter table empno add constraint emp_empno_pk primarykey(empno); -
📋 문제 3) 사원 테이블에 관리자 번호(mgr)에 foreign key 제약을 걸고 사원 테이블에 사원번호에 있는 컬럼을 참조하게 하며 관리자 번호가 사원 테이블에 있는 사원번호에 해당하는 사원들만 관리자 번호로 입력 또는 수정될 수 있도록 하시오
alter table emp add constraint emp_empno_fk foreign key(mgr) reference emp(empno);
-
-
6) WITH ~ AS 절
-
with with절의 테이블명 as with절의 출력결과
-
🗒️ 예상 결과
-
📋 문제 1) 시간이 오래 걸리는 무거운 커리문이 하나의 쿼리문에서 반복 사용된다면?
select job, sum(sal) as 토탈 // 해당 쿼리문의 수행시간이 20분이라면 from emp group by job; select job, sum(sal) as 토탈 // 해당 쿼리문의 수행시간은 40분 from emp group by job; having sum(sal) > (select avg(sum(sal)) from emp group by job); // with절 with job_sumsal as (select job, sum(sal) as 토탈) from emp group by job) select job, 토탈 from job_sumsal where 토탈 > (select avg(토탈) from job_sumsal); -
📋 문제 2) 부서번호별 토탈월급을 출력하는데 부서번호별 토탈월급들의 평균값보다 더 큰 것만 출력되게 하세요
with dept_sumsal as (select deptno, sum(sal) as sumsal from emp group by deptno) select deptno, sumsal from dept_sumsal where sumsal > (select avg(sumsal) from dept_sumsal); -
📋 문제 3) 부서위치, 부서위치별 토탈월급을 출력하는데 부서위치별 토탈월급의 평균값보다 더 큰 것만 출력하세요
with dept_sumsal as (select d.loc, sum(e.sal) as sumsal from dept d join emp e where e.deptno = d.deptno group by loc) select loc, sumsal from dept_sumsal where sumsal > (select avg(sumsal) from dept_sumsal);
-
-
7) SUBQUERY FACTORING
- 🗒️ 예상 결과

- 📋 문제 1) 위 SQL은 실행 될까요?
- 결과 : 에러 나면서 실행X (별칭 가지고 올 수 없음)
// from절 서브쿼리에서 with절 2개로 수정 with job_sumsal as (select job, sum(sal) 토탈 from emp group by job), deptno_sumsal as (select deptno, sum(sal) 토탈 from emp group by deptno having sum(sal) > (select avg(토탈) + 3000 from job_sumsal) ) select deptno, 토탈 from deptno_sumsal; - 📋 문제 2) 입사한 년도와 입사한 년도별 토탈월급을 출력하는데 부서번호별 토탈월급들의 평균값보다 더 큰 것만 출력하세요
with deptno_sumsal as (select deptno, sum(sal) 토탈 from emp group by deptno), hire_sumsal as (select to_char(hiredate, 'RRRR') hire_year, sum(sal) 토탈) from emp group by to_char(hiredate, 'RRRR') having sum(sal) > (select avg(토탈) from deptno_sumsal) ) select hire_year, 토탈 from hire_sumsal;
- 🗒️ 예상 결과
📕 알고리즘 구현
1. 구구단 2단 출력
-
1) 계층형 질의문 이용
-
🗒️ 예상 결과
-
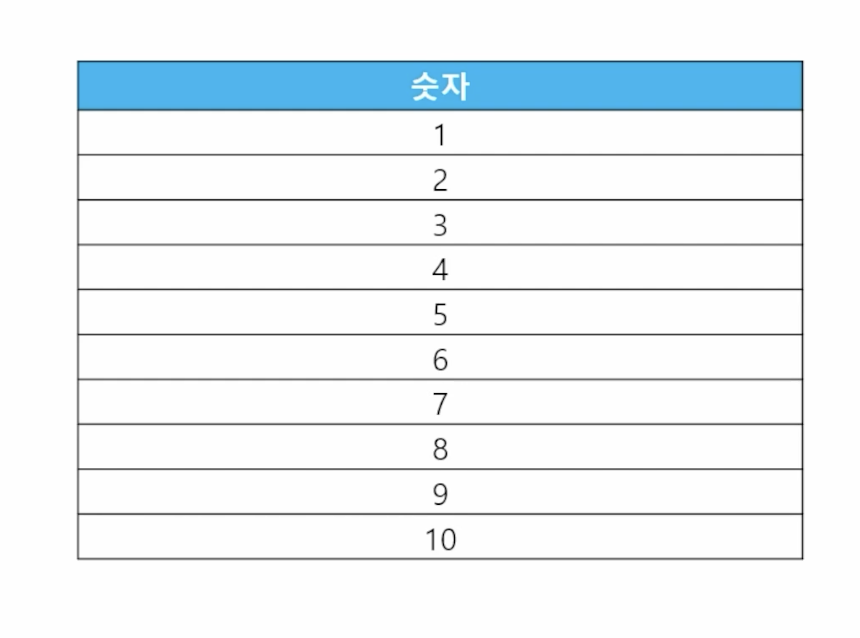
📋 문제 1) SQL로 숫자 1번부터 10번까지 출력할 수 있을까?
// 1 ~ 10까지 반복하는 쿼리 select level as num from dual connect by level <= 10; // connect by절 포함되어 있어 계층형 질의문 // 정답 with loop_table as (select level as num from dual connect by level <= 9) select '2' || 'x' || num || '=' || 2 * num as "2단" from loop_table; -
📋 문제 2) 1부터 100까지의 합은 얼마인가?
select sum(level) from dual connect by level <= 100; -
📋 문제 3) 1부터 100까지 숫자 55를 뺀 수의 합은 얼마인가?
select sum(level) from dual where level != 55 connect by level <= 100; -
📋 문제 4) 1부터 100까지 짝수 수의 합은 얼마인가?
select sum(level) from dual where mod(level, 2) = 0 connect by level <= 100;
-
-
2) 두 테이블 조인하는 계층형 질의문
-
🗒️ 예상 결과
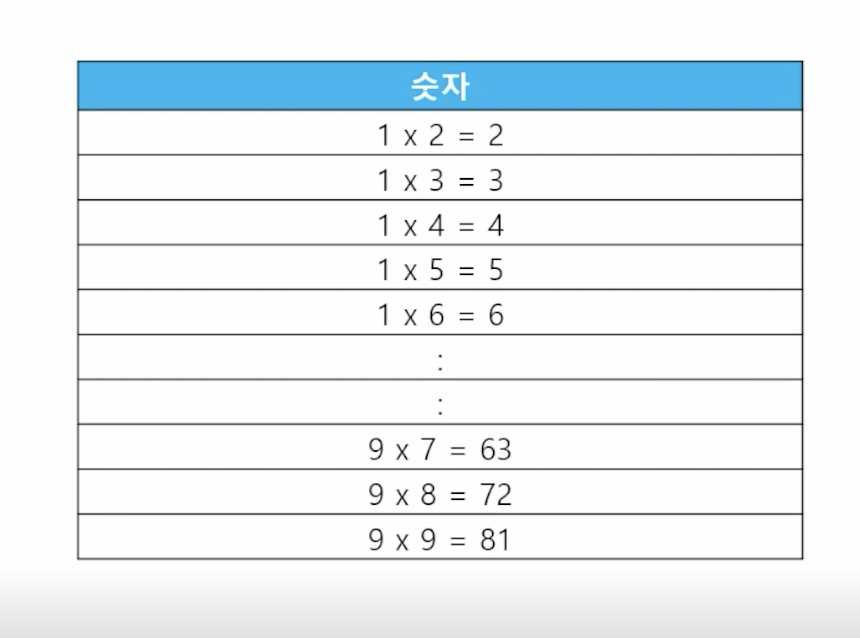
-
📋 문제 1) 구구단 전체를 SQL로 출력할 수 있을까? (구구단 1 ~ 9단 출력)
// 1 ~ 9까지 출력 select level as num from dual connect by level <= 9; // 2 ~ 9까지 출력 select level + 1 as num from dual connect by level <= 8; // 정답 with loop_table as (select level as num from dual connect by level <= 9), gugu_table as (select level + 1 as gugu from dual connect by level <= 8) select to_char(a.num) || 'x' || to_char(b.gugu) || '=' || to_char(a.num * b.gugu) as 구구단 from loop_table a, gugu_table b; -
📋 문제 2) 위의 결과에서 2단과 5단, 7단만 출력하세요
with loop_table as (select level as num from dual connect by level <= 9), gugu_table as (select level as gugu from dual connect by level <= 9) select to_char(a.num) || 'x' || to_char(b.gugu) || '=' || to_char(a.num * b.gugu) as 구구단 from loop_table a, gugu_table b where a.num in (2, 5, 7); -
📋 문제 3) 구구단 전체에서 짝수단만 출력하세요
with loop_table as (select level as num from dual connect by level <= 9), gugu_table as (select level as gugu from dual connect by level <= 9) select to_char(a.num) || 'x' || to_char(b.gugu) || '=' || to_char(a.num * b.gugu) as 구구단 from loop_table a, gugu_table b where a.num in (2, 4, 6, 8);
-
-
3) lpad 함수로 직각 삼각형 채우기
- lpad('출력값' , 전체 자리수, '자리수 나머지값')
- 오른쪽부터 출력값 채워둠
- 🗒️ 예상 결과

- 📋 문제 1) 직각 삼각형을 SQL로 출력할 수 있을까?
with loop_table as (select level as num from dual connect by level <= 8) select lpad('★', num, '★') as star from loop_table; - 📋 문제 2) 다음과 같이 삼각형을 뒤집어서 출력하세요
with loop_table as (select 9 - level as num from dual connect by level <= 8) select lpad('★', num, '★') as star from loop_table; - 🗒️ 예상 결과

- 📋 문제 3) 다음과 같이 결과를 출력하세요
with loop_table as (select level as num from dual connect by level <= 8) select lpad('★', num, '★') as star from loop_table union all select lpad('★', 9 - num, '★') as star from loop_table;
- lpad('출력값' , 전체 자리수, '자리수 나머지값')
- 4) lpad 함수로 삼각형 채우기
-
🗒️ 예상 결과

-
📋 문제 1) 삼각형을 SQL로 출력할 수 있을까?
// 역 직각삼각형 select lpad(' ', 10 - level, ' ') from dual connect by level <= 8 // 직각삼각형 select lpad('★', level, '★') from dual connect by level <= 8; // 정답 with loop_table as (select level as num from dual connect by level <= 8) select lpad(' ', 10-num, ' ') || lpad ('★', num, '★') as "Triangle" from loop_table; -
📋 문제 2) 역삼각형을 출력하세요
with loop_table as (select level as num from dual connect by level <= 8) select lpad(' ', num, ' ') || lpad ('★', 9-num, '★') as "Triangle" from loop_table;
-
- 5) lpad 함수로 마름모 채우기
-
🗒️ 예상 결과

-
📋 문제 1) 마름모를 SQL로 출력할 수 있을까?
select lpad(' ', 5-level, ' ') || rpad('★', level, '★') as star from dual connect by level < 6 union all select lpad(' ', level, ' ') || rpad('★', 5-level, '★') as star from dual connect by level < 6; // 마름모 크기 변경 // 치환변수 사용 undefine p_num accept p_num promot '숫자 입력 : ' select lpad(' ', (&p_num)-level, ' ') || rpad('★', level, '★') as star from dual connect by level < &p_num + 1 union all select lpad(' ', level, ' ') || rpad('★', (&p_num)-level, '★') as star from dual connect by level < &p_num; -
📋 문제 2) 모래시계 모양을 출력하세요
select lpad(' ', level, ' ') || rpad('★', 9-level, '★') as star from dual connect by level < 10 union all select lpad(' ', 9-level, ' ') || rpad('★', level, '★') as star from dual connect by level < 10
-
- 6) lpad 함수로 사각형 채우기
-
🗒️ 예상 결과

-
📋 문제 1) 사각형을 SQL로 출력할 수 있을까?
undefine p_n1 undefine p_n2 accept p_n1 prompt '가로숫자를 입력하세요'; accept p_n2 promot '세로숫자를 입력하세요'; with loop_table as (select level as num from dual connect by level <= &p_n2) select lpad('★', &p_n1, '★') as star from loop_table; -
📋 문제 2) 숫자를 한번만 물어보게 하고 정사각형이 출력되게 하세요
undefine p_n accept p_n prompt '숫자를 입력하세요'; with loop_table as (select level as num from dual connect by level <= &p_n) select lpad('★', &p_n, '★') as star from loop_table;
-
- 7) 계층형 질의함수로 출력
-
🗒️ 예상 결과
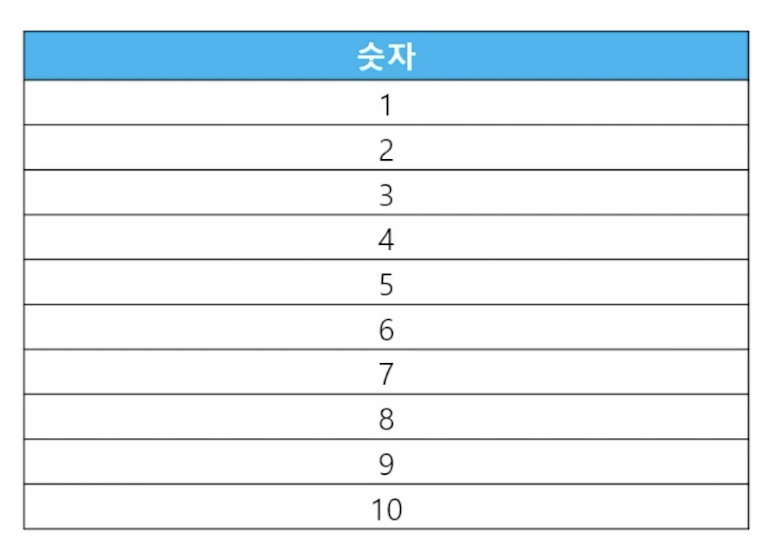
-
📋 문제 1) 1부터 10까지 숫자의 합
select sum(level) from dual connect by level <= 10; // 치환변수 사용 undefine p_n accept p_n prompt '숫자를 입력하세요'; select sum(level) as 합계 from dual connect by level <= &p_n; -
📋 문제 2) 1부터 100까지의 숫자 중에서 짝수 숫자들의 합은 무엇입니까?
select sum(level) from dual where mod(level,2) = 0 connect by level <= 100; -
📋 문제 3) 1부터 100까지의 숫자 중에서 홀수 숫자들의 합은 무엇입니까?
select sum(level) from dual where mod(level,2) = 1 connect by level <= 100; -
📋 문제 4) 1부터 10까지의 곱은 얼마인가?
// 자연상수 e의 10승 select exp(10) from dual; // 로그함수 밑수가 e고, 진수가 10 select ln(10) from dual; // 지수 * 로그로 진수를 곱셈으로 이용 select round(exp(sum(ln(level)))) from dual connect by level <= 10; -
📋 문제 5) 1부터 100까지의 짝수 숫자들의 곱은 무엇입니까?
select round(exp(sum(ln(level)))) from dual where mod(level, 2) = 0 connect by level <= 100;
-
- 8) listagg 함수로 가로 출력
- 🗒️ 예상 결과

- 📋 문제 1) 1부터 10까지 짝수만 가로로 출력하세요
select listagg(level, ',') from dual where mod(level, 2) = 0 connect by level <= 10; - 📋 문제 2) 1부터 10까지 홀수만 가로로 출력하세요
select listagg(level, ',') from dual where mod(level, 2) = 1 connect by level <= 10;
- 🗒️ 예상 결과
- 9) with절 조인해 사용
-
🗒️ 예상 결과
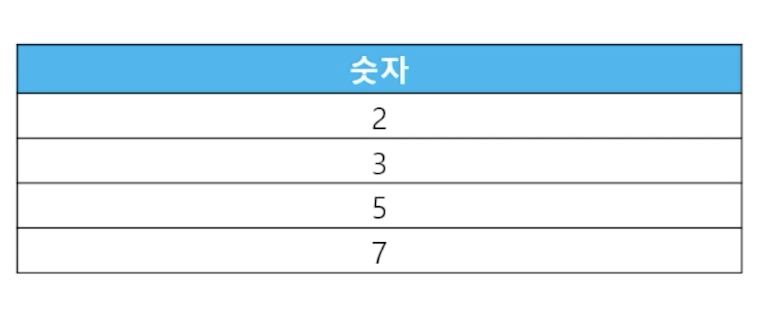
-
📋 문제 1) 1부터 10까지 소수만 출력하세요
- 소수 : 1과 자기자신 외의 약수를 가지지 않는 1보다 큰 자연수
with loop_table as (select level as sum from dual connect by level <= 10) select l1.num as 소수 from loop_table l1, loop_table l2 where mod(l1.num, l2.num) = 0 group by l1.num having count(l1.num) = 2; -
📋 문제 2) 1부터 10까지의 소수들의 합은?
select sum(소수) from ( with loop_table as (select level as sum from dual connect by level <= 10) select l1.num as 소수 from loop_table l1, loop_table l2 where mod(l1.num, l2.num) = 0 group by l1.num having count(l1.num) = 2 ); -
📋 문제 3) 1부터 10까지의 소수들의 곱은?
select round(exp(sum(ln(소수)))) from ( with loop_table as (select level as sum from dual connect by level <= 10) select l1.num as 소수 from loop_table l1, loop_table l2 where mod(l1.num, l2.num) = 0 group by l1.num having count(l1.num) = 2 ); -
📋 문제 4) 16과 24의 최대 공약수는?
// 16과 24 출력 select 16 as num1, 24 as num2 from dual; // 16과 24 각각을 1부터 24까지 나눈 값 출력 with num_d as (select 16 as num1, 24 as num2 from dual) select level, mod(num1, level), mod(num2, level) from num_d connect by level <= num2; // 정답 with num_d as (select 16 as num1, 24 as num2 from dual) select max(level) from num_d where mod(num1, level) = 0 and mod(num2, level) = 0 connect by level <= num2; -
📋 문제 5) 16, 24, 48의 최대 공약수는?
with num_d as (select 16 as num1, 24 as num2, 48 as num3 from dual) select max(level) from num_d where mod(num1, level) = 0 and mod(num2, level) = 0 and mod(num3, level) = 0 connect by level <= num3; -
📋 문제 6) 16과 24의 최소 공배수는?
with num_d as (select 16 as num1, 24 as num2 from dual) select (num1/max(level)) * (num2/max(level)) * max(level) from num_d where mod(num1, level) = 0 and mod (num2, level) = 0 connect by level <= num2;
-
- 10) case when 사용하여 여부 판단
-
🗒️ 예상 결과
-
📋 문제 1) 피타고라스의 정리로 직각 삼각형 여부를 확인하기
select case when 2=2 then '맞습니다' else '아닙니다' end from dual; accept num1 prompt '밑변의 길이 입력' accept num2 prompt '높이 입력' accept num3 prompt '빗변의 길이 입력' select case when (power(&num1, 2) + power(&num2, 2)) = power(&num3, 2) then '직각 삼각형이 맞습니다' else '직각 삼각형이 아닙니다' end as '피타고라스의 정리' from dual; -
📋 문제 2) 빗변 2개와 밑변을 각각 물어보게 하고 정삼각형이 맞는지에 대한 여부를 출력하세요
accept num1 prompt '왼쪽 빗변의 길이 입력' accept num2 prompt '오른쪽 빗변의 길이 입력' accept num3 prompt '밑변 길이 입력' select case when (&num1 = &num2 and &num2 = &num3) then '직각 삼각형이 맞습니다' else '직각 삼각형이 아닙니다' end as '피타고라스의 정리' from dual; -
📋 문제 3) 몬테카를로 알고리즘으로 원주율을 알아내세요
- 반지름 반지름 3.14 = 원의 넓이
- 원주율 = 부채꼴의 점의 개수 / 정사각형의 점의 개수 * 4
select sum(case when (power(num1, 2) + power(num2, 2)) <= 1 then 1 else 0 end) / 100000 * 4 as "원주율" from ( select dbms_random.value(0, 1) as num1, dbms_random.value(0, 1) as num2 from dual connect by level < 100000); // 3.14992 출력 -
📋 문제 4) 몬테카를로 알고리즘으로 자연상수 e의 값을 SQL로 알아내세요

with loop_table as (select level as n from dual connect by level <= 1000000 ) select result from ( select n, power((1 + 1/n), n), as result from loop_table) ) where n = 1000000;
-
📕 빅데이터 분석
1. 공공 데이터 포털 이용
- 1) 방법
- 데이터 임포트 ➡️ 찾아보기 (엑셀/txt) ➡️ 다운받은 데이터 불러오기
- 형식 : csv
2. 데이터 분석
- 1) select절 사용
- 📋 문제 1) 우리나라 남자들이 가장 많이 걸리는 암은 무엇일까?
select * from cancer where 성 != '남녀전체' and 발생연도 = '1999' and 발생자수 is not null and 암종 != '모든암' and 성 = '남자' order by 발생자수 desc fetch first 4 rows only; // 4개만 출력됨
- 📋 문제 1) 우리나라 남자들이 가장 많이 걸리는 암은 무엇일까?
- 2) regexp_substr 사용
-
📋 문제 1) 스티븐 잡스 연설문에서 가장 많이 나오는 단어는?
drop table speech; create table speech (speech_text varchar2(1000)); select word, count(*) from ( select regexp_substr(lower(speech_text), '[^ ]+', 1, a) word // [^ ]+ : 공백이 아닌 것을 여러개 검색 from speech, (select level a from dual connect by level <= 52) // 한줄이 52개 단어가 안남어간다고 가정 (문장을 어절별로 분리) ) where word is not null group by word order by count(*) desc; -
📋 문제 2) 스티븐 잡스 연설문에는 긍정단어가 많이 나올까 부정단어가 많이 나올까?
drop table positive; drop table negative; drop table speech; create table positive (p_text varchar2(2000)); create table negative (n_text varchar2(2000)); alter table speech rename column 열1 to sppech_text; // 어절별로 나눠 view 생성 create or replace view speech_view as select regexp_substr(lower(speech_text), '[^ ]+', 1, a) word from speech, (select level a from dual connect by level <= 52); // 소문자로 바꾸어 비교 select count(word) as 긍정단어 from speech_view where lower(word) in (select lower(p_text) from positive); select count(word) as 부정단어 from speech_view where lower(word) in (select lower(p_text) from negative);
-
- 3) unpivot 사용
-
📋 문제 1) 절도가 가장 많이 발생하는 요일은 언제인가요?
drop table crime_day_unpivot; create table crime_day_unpivot as select * from crime_day unpivot(cnt for day_cnt in (sun_cnt, mon_cnt, tue_cnt, wed_cnt, thu_cnt, fri_cnt, sat_cnt)); select * from ( select day_cnt, cnt, rank() over (order by cnt desc) rnk from crime_day_unpivot when trim(crime_type) = '절도' // trim으로 공백 제거 } where rnk = 1;
-
- 4)
-
📋 문제 1) 우리나라에서 대학 등록금이 가장 비싼 학교는?
drop table university_fee; create table university_fee (division varchar2(20), type varchar2(20), university varchar2(60), loc varchar2(40), admission_cnt number(20), admission_fee number(20, 2), tuituion_fee number(20, 2)); select * from ( select university, tuition fee, rank() over (order by tuition_fee desc nulls last 순위 from univesity_fee; ) where 순위 = 1;
-
📖 참고 📖
- ✏️ SQLD 카페
