📒 웹 (스프링)
📕 Spring
✏️ Spring 프레임워크가 무엇인지 설명해주세요
✏️ IoC (Inversion of Control, 제어의 역전)이 무엇인지 설명해주세요
✏️ DI (Dependency Injection, 의존관계 주입)가 무엇인지 설명해주세요
✏️ Spring에서 IoC와 DI를 어떻게 지원해 주는지에 대해 설명해주세요
✏️ Bean 객체와 Bean 생명주기에 대해 설명해주세요
✏️ Annotation에 대해 설명해주세요
-
애노테이션 : 자바 소스 코드에 주석 처럼 추가하여 특별한 기능을 사용하는 메타데이터
- 애노테이션을 정의하고, 클래스에 배치한 후 코드가 실행되는 중 자바 reflection을 통해 추가 정보를 더해 기능 실시
-
🗒️ 예시 : @RequestHeader
- Request의 header 값을 가져올 수 있음
- 해당 Annotation을 쓴 메소드의 파라미터에 사용

📖 참고 📖 reflection
- 구체적인 Class Type을 알지 못해도, 해당 Class의 method, type, variable에 접근할 수 있도록 해주는 JAVA API
- 컴파일된 바이트 코드를 통해 Runtime에 특정 Class의 정보를 추출하도록 동적 바인딩 제공
📖 참고 📖 Spring 제공 Annotation
- 📌 @ComponentScan
- @Component, @Service, @Repository, @Controller, @Configuration이 붙은 클래스 Bean들을 찾아서 Context에 bean을 등록해주는 애노테이션
- 전부 다 @Component를 사용하지 않고 @Repository 등으로 분리해서 사용하는 이유는, 예를 들어 @Repository는 DAO에서 발생할 수 있는 unchecked exception들을 스프링의 DataAccessException으로 처리할 수 있기 때문이다.
- 또한 가독성에서도 해당 애노테이션을 갖는 클래스가 무엇을 하는지 단 번에 알 수 있다.
- 📌 @EnableAutoConfiguration
- autoConfiguration도 Configuration중 하나에 해당한다.
- spring.factories 내부에 여러 Configuration들이 있고 조건에 따라 Bean이 등록되게 되는데 메인 클래스 @SpringBootApplication을 실행하면 @EnableAutoConfiguration에 의해 spring.factories 안에 있는 수많은 자동 설정들이 조건에 따라 적용되어 수 많은 Bean들이 생성된다.
- 간단하게 정리하면, Application Context를 만들 때 자동으로 빈설정이 되도록 하는 기능이다.
- 📌 @Component
- 개발자가 직접 작성한 class를 Bean으로 등록하기 위한 애노테이션
- 📌 @Bean
- 개발자가 직접 제어가 불가능한 외부 라이브러리등을 bean으로 만들려할 때 사용되는 애노테이션
- 📌 @Configuration
- @Configuration을 클래스에 적용하고 @Bean을 해당 class의 메서드에 적용하면 @autowired로 Bean을 부를 수 있다.
- 📌 @Autowired
- 스프링이 Type에 따라 알아서 Bean을 주입해준다.
- Type을 먼저 확인한 후 못 찾으면 Name에 따라 주입한다.
- 강제로 주입하고자 하는 경우 @Qulifier을 같이 명시
- 📌 @Qualifier
- 같은 타입의 빈이 두 개 이상 존재하는 경우 스프링이 어떤 빈을 주입해야할 지 알 수 없어서 스프링 컨테이너를 초기화하는 과정에서 예외가 발생한다.
- @Qualifier는 @Autowired와 함께 사용하여 정확히 어떤 bean을 사용할지 지정하여 특정 의존 객체를 주입할 수 있다.
- 📌 @Resource
- @Autowired와 마찬가지로 Bean 객체를 주입해주는데 차이점은 Autowired는 타입으로, Resource는 이름으로 연결해준다.
- 애노테이션 사용으로 인해 특정 Framework에 종속적인 애플리케이션을 구성하지 않기 위해서 @Resource 사용을 권장한다.
- 📌 @Controller
- API와 view를 동시에 사용하는 경우에 사용
- 보통 view 화면 return을 목적으로 사용한다.
- 📌 @RestController
- view가 필요 없이 API만 지원하는 서비스에서 사용
- 📌 @SpringBootApplication
- @Configuration, @EnableAutoConfiguration, @ComponentScan 3가지를 하나로 합친 애노테이션
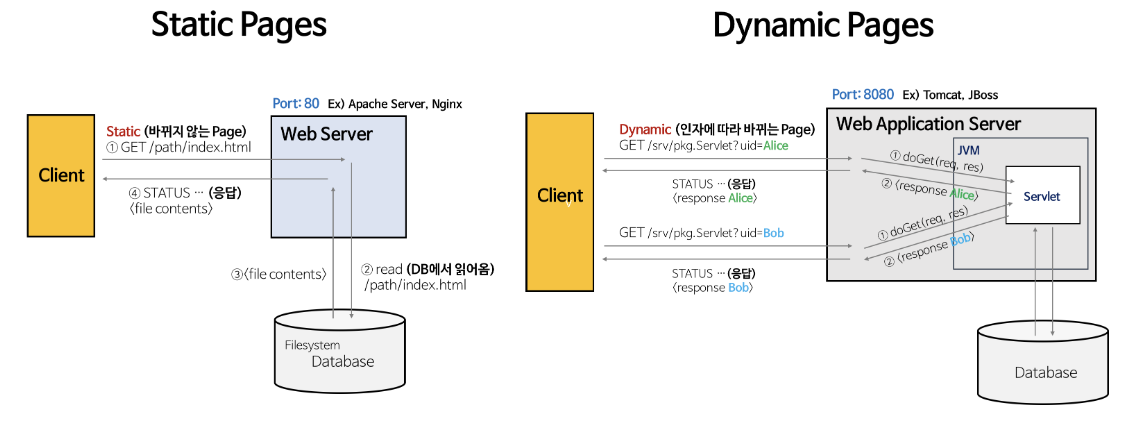
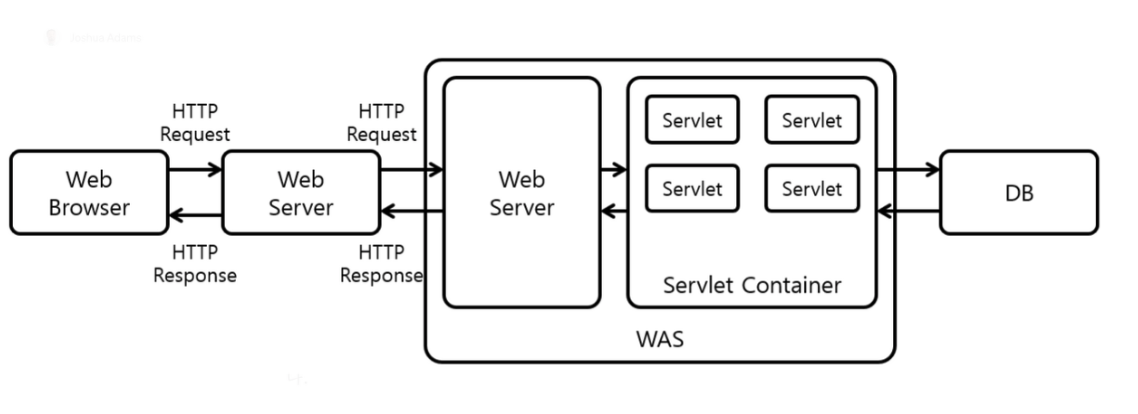
✏️ 웹 서버와 웹 애플리케이션 서버가 다른 점에 대해 설명해주세요
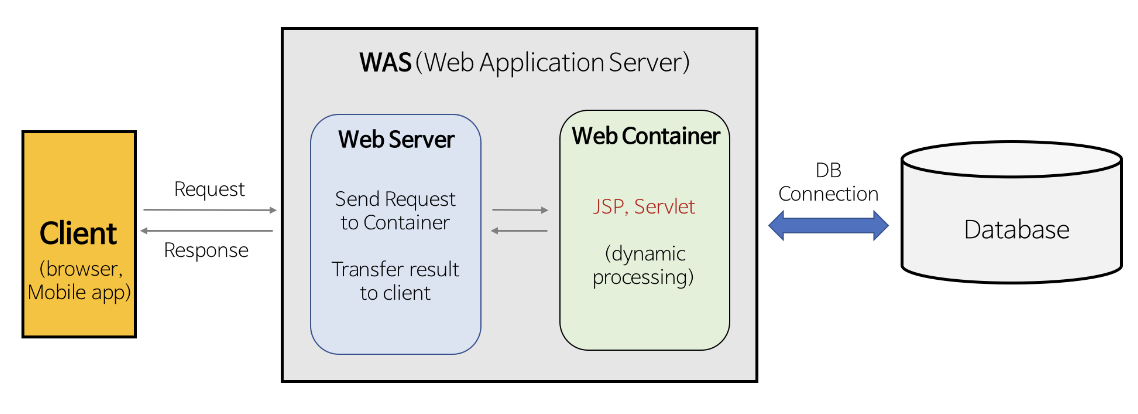
- 웹 서버 : 정적 리소스 파일을 제공하는 서버
- 웹 애플리케이션 서버 (WAS) : 웹 서버가 하는 일 + 애플리케이션 로직(DB 연결, 동작 수행, 데이터 제공)까지 제공하여 동적 처리를 제공하는 서버
✏️ 서블릿과 서블릿 컨테이너에 대해 설명해주세요
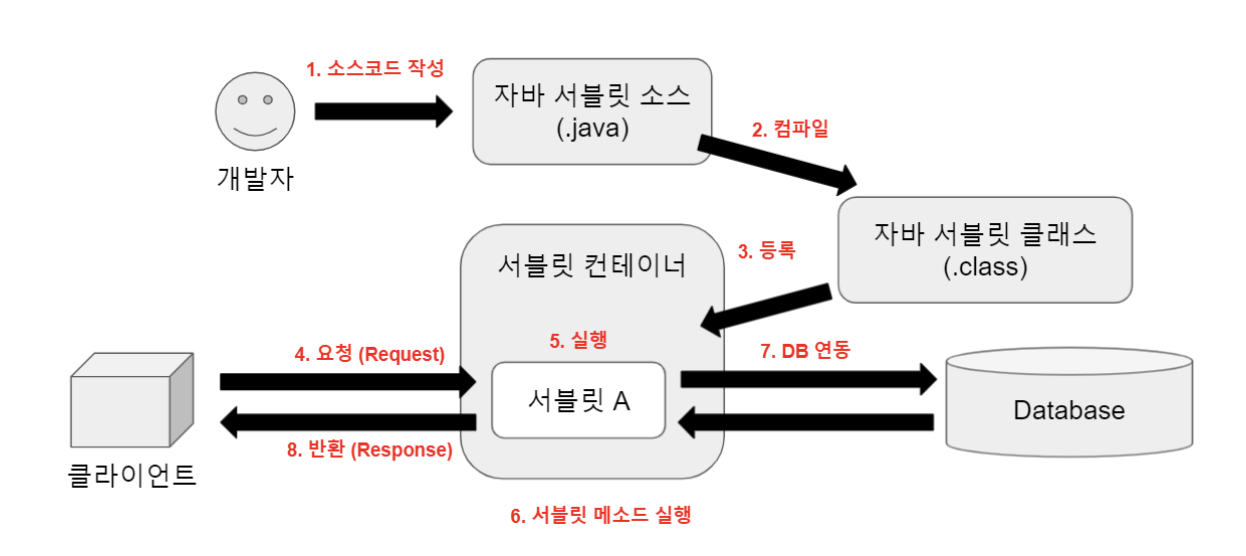
- 서블릿 : WAS 안에서 동적 처리에 사용되는 서버 프로그램 (개발자가 하던 HTTP 요청 메시지 파싱 등을 대신하여 개발자는 메인 로직에만 집중)
-
서블릿 컨테이너 : 웹서버와 통신을 지원하고, 서블릿의 생명주기와 멀티쓰레드 관리
-
🗒️ 예시 : 톰캣(Tomcat)
- 클라이언트의 요청(Request)을 받아주고 응답(Response)할 수 있게, 웹서버와 소켓으로 통신
- JSP(자바 서버 페이지)와 Servlet이 작동하는 환경을 제공
📖 참고 📖 Servlet Container 과정
- 1️⃣ : 요청 받으면 쓰레드 풀에서 쓰레드를 꺼내 할당하고, ServletRequest, ServletResponse 두 객체 생성
- 2️⃣ : 매핑할 서블릿 확인하고, Servlet Container에 없을 경우
init()메서드, 있을 경우service()메서드 호출- 3️⃣ : 응답 처리하면,
distroy()메서드 실행하여 ServletRequest, ServletResponse 객체 소멸 (가비지 컬렉션)
✏️ Spring MVC에 대해 설명해주세요
✏️
📒 데이터베이스
📕
✏️
📒 네트워크
📕
✏️
📒 운영체제
📕 OS
✏️ OS(운영체제)가 무엇인지 설명해주세요
- 하드웨어 자원을 관리하고, 응용 프로그램과 하드웨어 사이를 중재하는 인터페이스
✏️ 커널이 무엇인지 설명해주세요
- 운영체제는 메인 메모리에 적재되어야 하나, 크기가 너무 커서 전체를 메모리에 올리면 비효율적 (메모리 공간의 낭비)
- 항상 필요한 운영체제의 핵심 부분을 메모리에 적재하여 운영체제 사용
📕 메모리
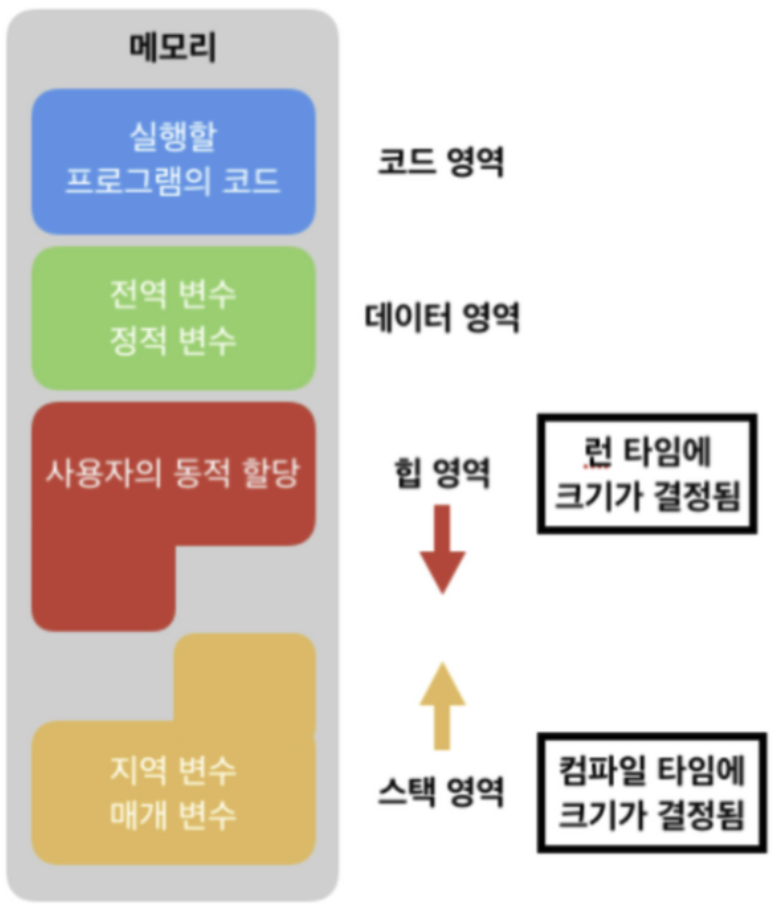
✏️ 메모리 구조를 영역에 따라 설명해주세요
-
1) 코드 영역 (Text)
- 실행할 프로그램 코드 저장되는 영역
- CPU는 해당 코드 영역에 저장된 명령어를 하나씩 가져가서 처리함
-
2) 데이터 영역
- 전역 변수와 정적 변수 저장
- 프로그램 시작하는 동시에 할당, 프로그램 종료되면 소멸
-
3) 힙 영역
- 메모리 공간이 동적으로 할당/해제
- 사용자가 직접 관리하고, new로 생성한 object가 많아질 수록 힙 영역 크기 늘어남
-
4) 스택 영역
- 함수 호출에 따른 지역 변수와 매개변수 저장
- 컴파일시 크기가 결정
- 함수의 호출과 함께 할당, 함수의 호출 종료되면 소멸
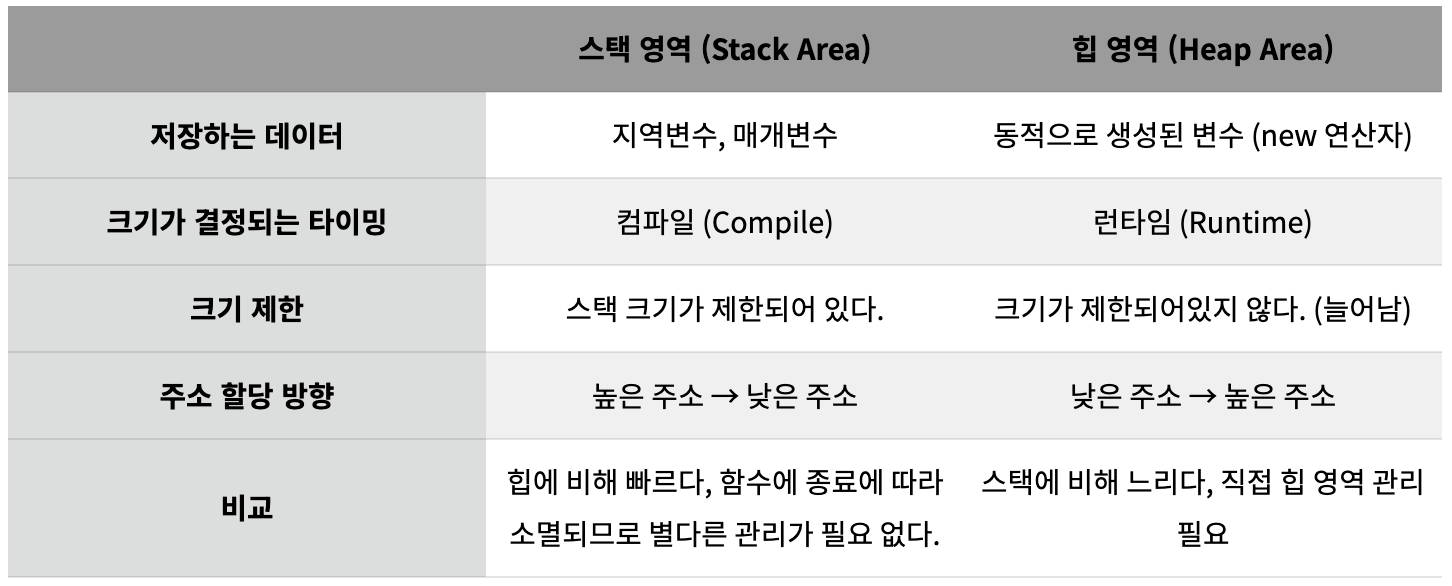
📖 참고 📖 heap과 stack 차이
- 스택은 높은 주소부터, 힙은 낮은 주소부터 채워짐
- 서로 영역 침범하느냐에 따라 stack overflow, heap overflow 발생
✏️ 메모리 종류에 대해 설명하고, 종류가 여러가지인 이유에 대해 설명해주세요
- 메모리 종류 : 레지스터 > 캐시 > 주기억장치 > 보조기억장치
- 종류가 많은 이유 : 용량과 접근 속도에 따른 차이
✏️ OS가 메모리 관리를 해야하는 이유와 관리를 위해 어떤 전략을 사용하는지 설명해주세요
-
각 프로세스는 독립된 메모리 공간을 가지고, 다른 프로세스의 메모리 공간에 접근할 수 없음
-
OS만이 운영체제 메모리 영역과 사용자 메모리 영역의 접근이 가능하여 적절한 관리가 필요함
-
메모리 관리 방식 : 가상 메모리를 이용한 Swapping, 페이징 및 세그멘테이션 전략, 고정길이 할당/가변길이 할당, 압축
✏️ 메모리 fit의 종류 4가지에 대해 설명해주세요
- First fit : 메모리의 처음부터 검사해서 크기가 충분한 첫번째 메모리에 할당
- Next fit : 마지막으로 참조한 메모리 공간에서부터 탐색을 시작해 공간을 찾음
- Best fit : 모든 메모리 공간을 검사해서 내부 단편화를 최소화하는 공간에 할당
- Worst fit : 남은 공간 중에 가장 큰 공간 할당
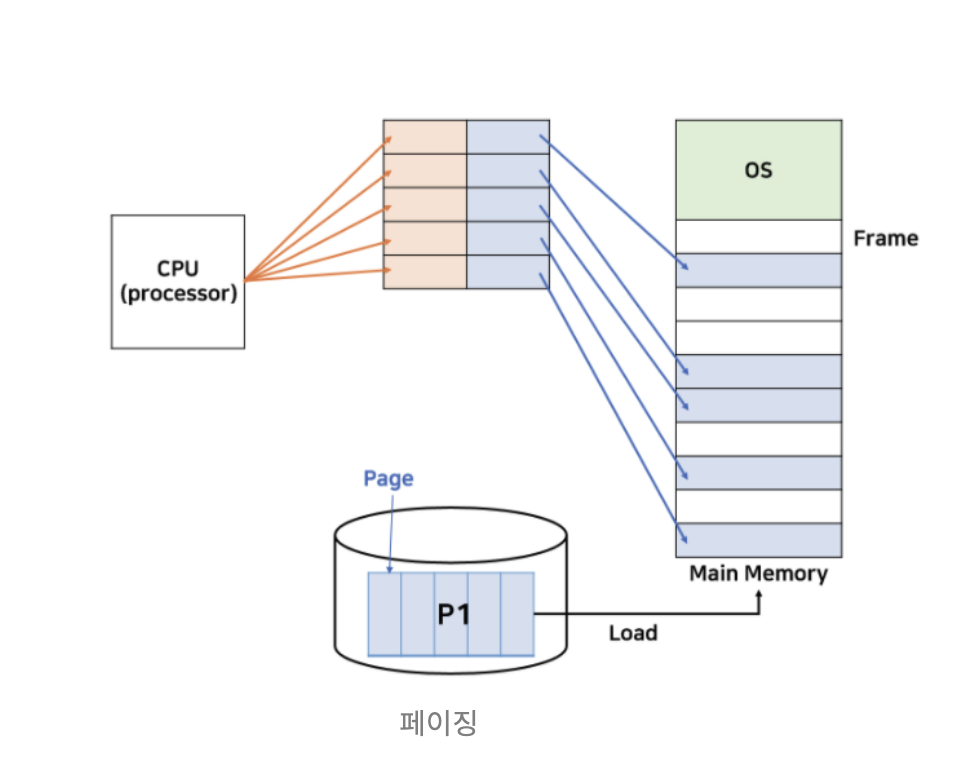
✏️ 페이징과 세그멘테이션에 대해 설명해주세요
-
Paging : 프로세스를 동일한 크기의 페이지로 분리, 메모리는 해당 페이지와 동일한 크기의 프레임으로 분리해서 메인 메모리에 불연속적으로 저장하는 방식 (내부 단편화 발생)
-
Segmentation : 프로세스를 가변적인 크기의 세그먼트로 분리, Code/Data/Stack/Heap으로 프레임을 분리해서 메인 메모리에 불연속적으로 저장하는 방식 (외부 단편화 발생)
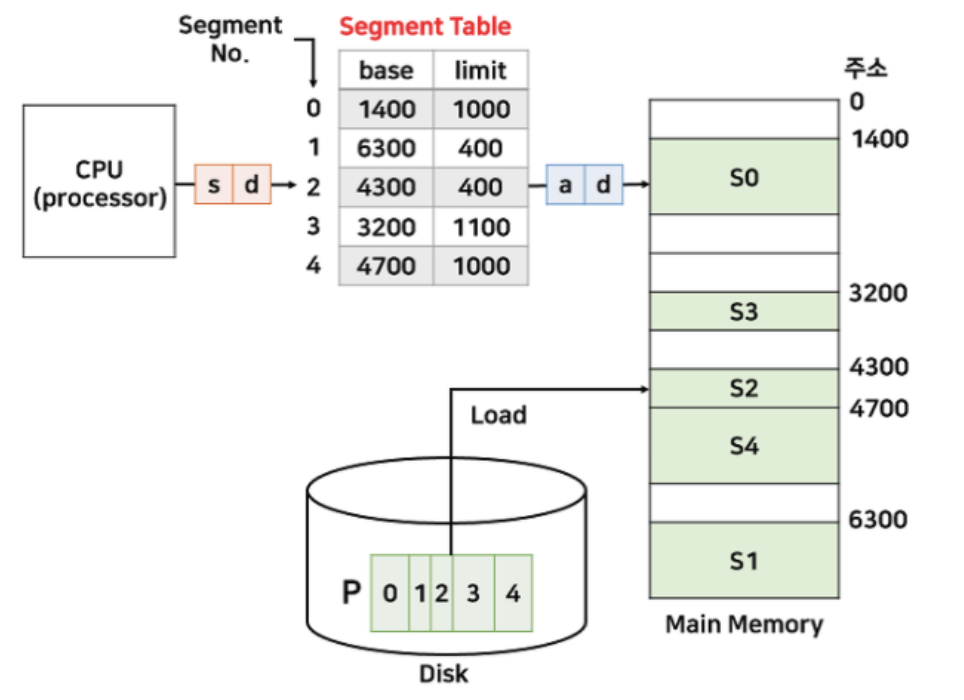
✏️ 내부단편화와 외부단편화가 무엇인지 설명해주세요
-
단편화 : 프로세스들이 차지하는 메모리에 사용하지 못할 만큼의 작은 공간
-
내부 단편화 : 고정길이 할당/페이지에서 나타남, 메모리를 고정 길이로 잘랐을 때 해당 고정 길이보다 작은 프로세스가 저장되어 생기는 여백
-
외부 단편화 : 가변길이 할당/세그멘테이션에서 나타남, 메모리에 적재할 수 있는 크기가 프로세스보다 작으면 적재할 수 없을 때의 여백
✏️ Demand Paging(요구 페이징)이 무엇인지 설명해주세요
- 프로그램 실행 시작 시에 프로그램 전체를 물리 메모리에 적재하는 대신, 초기에 필요한 것들만 적재하는 전략
✏️ 페이지 교체가 언제 발생하는지, 어떤 교체 알고리즘이 있는지 설명해주세요
-
Page Fault(프로세스 동작 중 필요한 페이지가 물리 메모리에 없는 상황)가 발생하면 원하는 페이지를 하드디스크의 Swapping을 통해 가져오는데, 물리 메모리가 가득찼을 경우 페이지 교체 발생
-
FIFO : 가장 오래된 페이지 교체
-
OPT (Optimal) : 가장 먼 미래 동안 사용되지 않을 페이지 교체 (불가능)
-
LFU (Least Frequently Use) : 가장 사용 빈도가 적은 페이지 고체
-
MFU (Most Frequently Use) : 가장 사용 빈도가 많은 펭지ㅣ 교체
-
LRU (Least Recently Use) : 가장 오랫동안 사용되지 않은 페이지 교체
-
NUR (Not Used Recently) : 가장 오랫동안 사용되지 않은 페이지 교체, 참조 비트와 변형 비트 사용하여 교체
-
Clock Algorithm : 각 페이지가 최근에 참조되었는지 reference bit 에 따라 페이지 교체 (오랫동안 참조되지 않은 페이지는 찾을 수 없고, 최근에 참조된 페이지는 피할 수 있음)
✏️ Thrashing(쓰레싱)에 대해 설명해주세요
-
페이지 부재율이 높은 상태
-
메모리에 프로세스가 너무 많아지면, Page Fault가 일어나 페이지 교체가 일어나며 CPU 사용률이 줄어들게 되는데, CPU는 더 많은 프로세스를 메모리에 올리게 되며 악순환 발생
-
해결 방법
- Working Set : 대부분 프로세스가 특정 페이지만 집중적으로 참조하는 특성을 이용하여 일정 시간동안 참조되는 페이지 개수를 파악하고, 그 페이지 수만큼 여분 프레임이 확보되면 그 때 페이지를 메모리에 올리는 알고리즘
- Page Fault Frequency : Page Fault 퍼센트의 상한과 하한을 두고, 상한을 넘으면 페이지에게 지급하는 프레임을 늘리고, 하한을 넘으면 지급 프레임 개수를 줄임
-
CPU 사용률과 메모리 적재량을 함께 체크하여 쓰레시 유무 파악
✏️ 메모리 고갈되면 일어나는 현상에 대해 설명해주세요
- 메모리가 고갈되면, 프로세스 실행을 위해 swapping이 활발
➡️ 프로세스가 집중적으로 사용하는 페이지들의 집합이 메모리에 한꺼번에 적재되지 못하여 page fault 많이 발생
➡️ CPU 이용률이 낮아지며, OS가 오히려 프로세스 추가하며 thrasing 현상 발생
➡️ 해소하지 못하면, Out of Memory 상태로 판단해 중요도가 낮은 프로세스 강제 종료
✏️ 캐시(cache)메모리를 왜 사용하는지, CPU 적중률을 높이기 위해 어떤 원리를 사용하는지 설명해주세요
-
cache memory 사용 목적 : 앞으로 사용될 것으로 예상되는 데이터를 미리 저장하여, CPU와 메모리 사이의 속도 차이 완화
-
CPU hit ratio 높이기 위한 원리 : 참조 지역성 원리 사용
- temporal locality (시간적 지역성) : CPU가 1번 참조한 데이터와 다시 참조할 가능성 높음
- spatial locality (공간적 지역성) : CPU가 참조한 데이터와 인접한 데이터가 참조할 가능성 높음
✏️ 메모리 할당 중, 연속(Contiguous) 할당 방식과 불연속(Non-contiguous) 할당 방식에 대해 설명해주세요
- 연속 할당 방식 : 프로세스가 분리되지 않고 메인 메모리에 적재하는 방식
- 고정 길이 할당 : 메모리를 고정된 길이로 분리 (내부 단편화 발생)
- 가변 길이 할당 : 메모리를 프로세스 길이에 맞게 분리 (외부 단편화 발생)
- 불연속 할당 방식 : 프로세스가 분리되어 메인 메모리에 적재하는 방식
- 페이징 : 프로세스를 동일한 크기의 페이지로 분리, 해당 페이지와 동일한 크기의 프레임으로 분리해서 메모리에 불연속적으로 저장 (내부 단편화 발생)
- 세그멘테이션 : 프로세스를 가변적인 크기의 세그먼트로 분리, Code/Data/Stack/Heap으로 분리해서 메모리에 불연속적으로 저장 (외부 단편화 발생)
✏️ RAID(Redundant Array of Independent Disks)가 무엇인지 종류에 대해 설명해주세요
-
RAID : 여러 개의 디스크를 하나의 디스크처럼 사용(대용량 단일 볼륨 사용 효과), 디스크 I/O 병렬화로 성능 향상(RAID 0, RAID 5, RAID 6), 데이터 복제로 안전성 향상(RAID 1)
-
종류
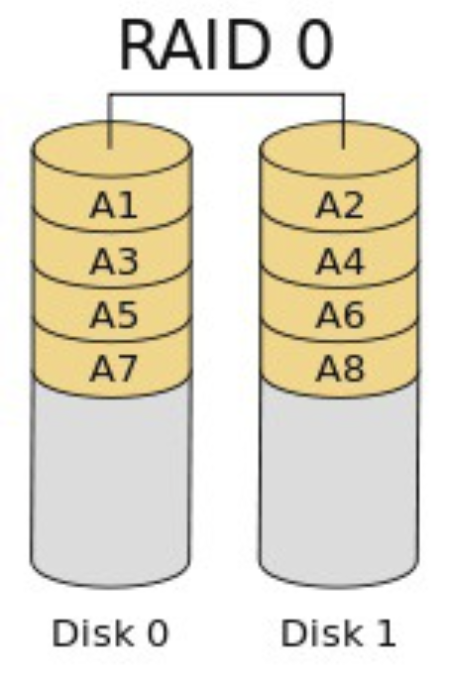
- RAID 0 : 스트라이핑, 모든 디스크에 데이터 분할 저장
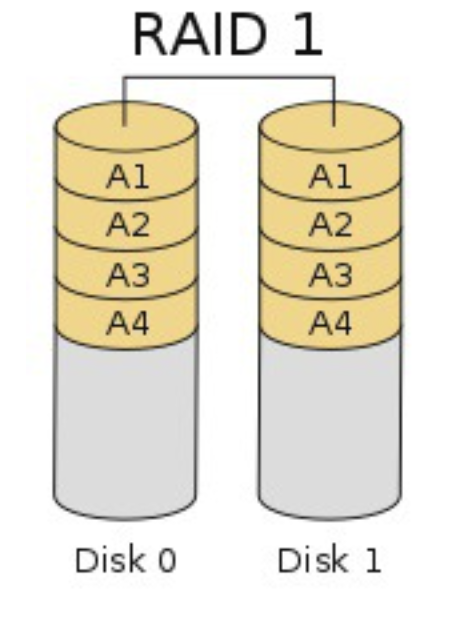
- RAID 1 : 미러링, 동일한 데이터를 N개로 복제하여 디스크에 저장
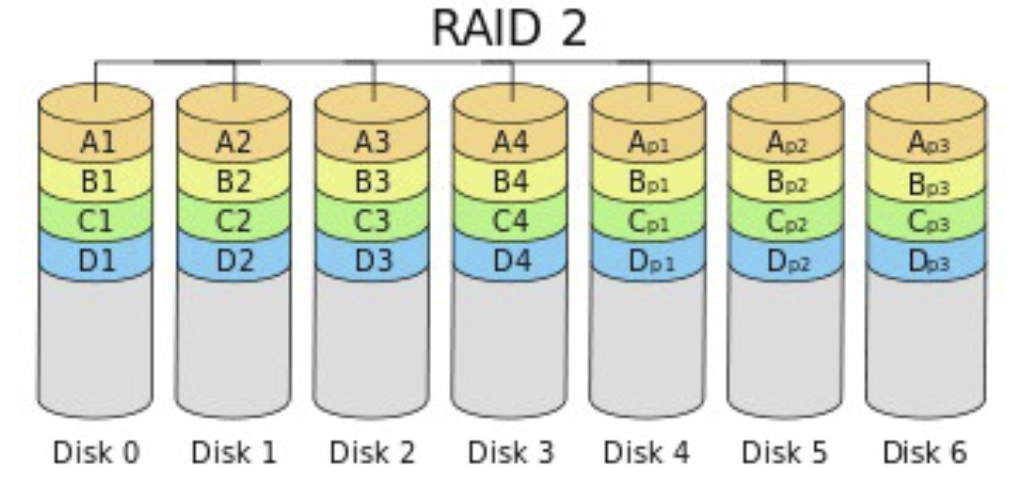
- RAID 2 : bit 단위로 스트라이핑, 오류 정정(error correction)으로 Hamming Code 사용
- 최근 디스크는 기본적으로 오류정정기능 가지고 있어 사용X
- 최소 3개 디스크로 구성 가능
- 1개 디스크 에러시 복구 가능
- RAID 3 : Byte 단위로 스트라이핑, 오류 정정을 위해 패리티 디스크 1개 사용
- byte라 너무 잘게 쪼개져 사용X
- 최소 3개 디스크로 구성 가능
- 1개 디스크 에러시 복구 가능
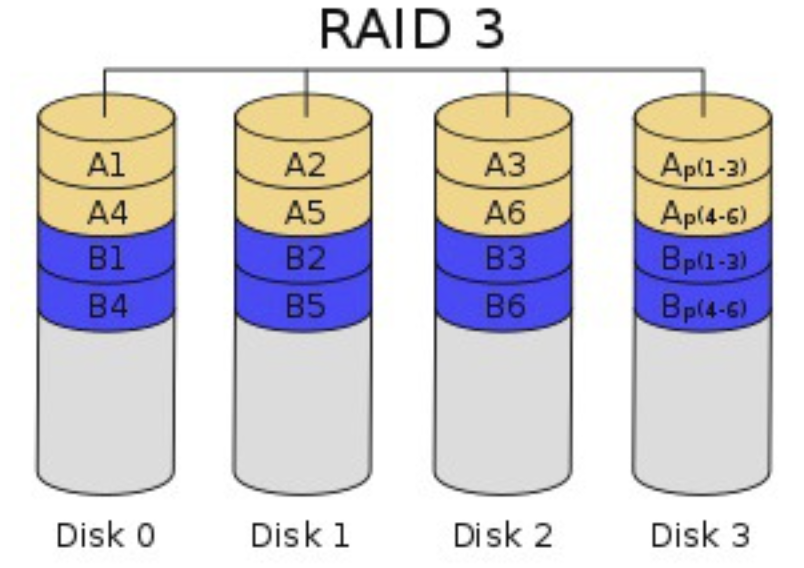
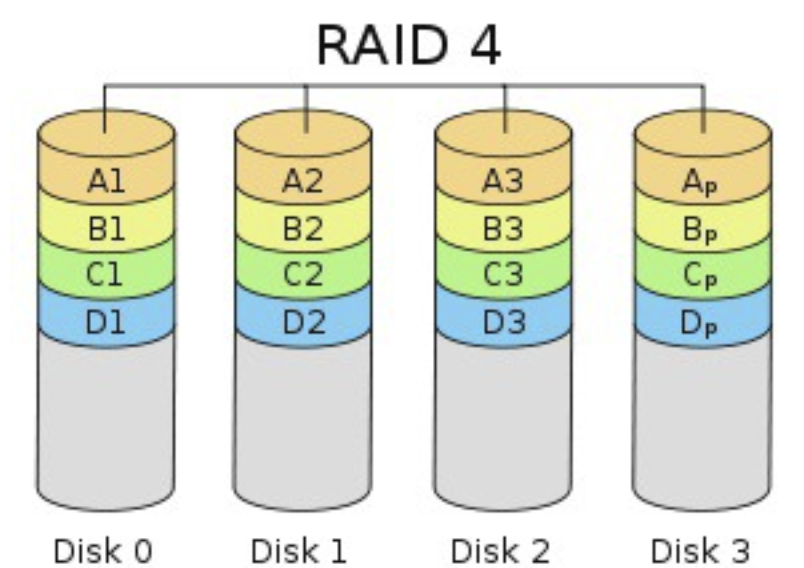
- RAID 4 : Block 단위로 스트라이핑, 오류 정정을 위해 패리티 디스크 1개 사용 (동일)
- 패리티 디스크 사용량이 높아 디스크 수명이 줄어들어 거의 사용X
- 최소 3개 디스크로 구성 가능
- 1개 디스크 에러시 복구 가능
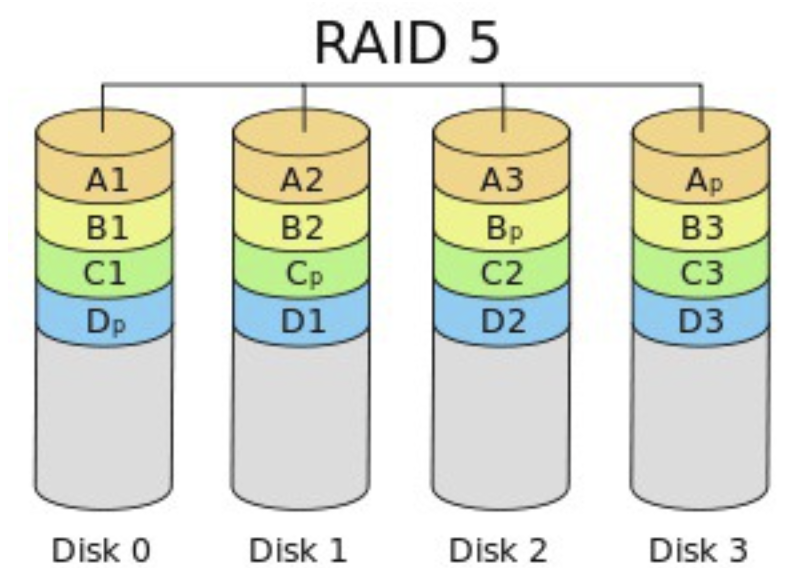
- RAID 5 : Block 단위로 스트라이핑, 오류 정정을 위해 패리티 디스크 1개 사용 (분할) (사용 빈도 높음)
- 최소 3개 디스크로 구성 가능
- 1개 디스크 에러시 복구 가능
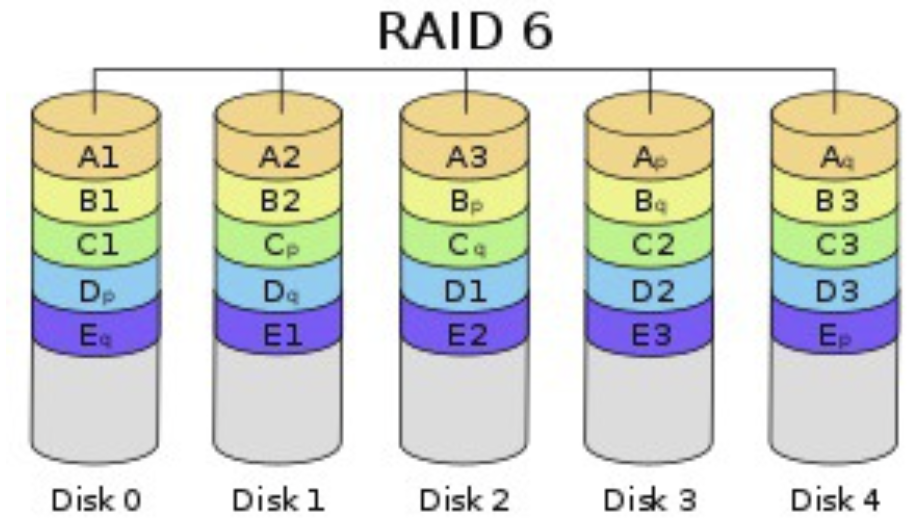
- RAID 6 : Block 단위로 스트라이핑, 오류 정정을 위해 패리티 디스크 2개 사용 (분할)
- 안정성 높아야 하는 서버 환경에서 주로 사용
- 최소 4개 디스크로 구성 가능
- 2개 디스크 에러시 복구 가능
- RAID 0 : 스트라이핑, 모든 디스크에 데이터 분할 저장
📖 참고 📖 스트라이핑 (striping)
- 연속된 데이터를 여러 개의 디스크에 RR(라운드 로빈) 방식으로 기록하는 기술
📖 참고 📖 미러링 (mirroring)
- 다른 디스크에 디이터를 중복 저장하는 기술로 디스크가 에러 발생했을 때 복구 가능
📕 프로세스 / 쓰레드
✏️ 프로세스와 쓰레드에 대해 설명하고, 차이점을 설명해주세요
-
Process : 메인 메모리에 적재되어 실행되는 프로그램
-
Thread : 한 프로세스 내의 실행 단위/실행 흐름을 의미
-
차이점 1️⃣
- 프로세스 : PCB, code, data, heap, stack 영역 가짐
- 쓰레드 : stack 영역, PC register 별도, 나머지는 해당 쓰레드를 포함한 프로세스 자원을 공유
-
차이점 2️⃣
- 프로세스
- 각 영역을 가져 동기화 작업 필요X
- context switching 비용⬆️
- 생성 시간⬆️
- 오류시 타 프로세스에 영향X
- 쓰레드
- 공유 자원에 접근시 동기화 작업 필요O
- context switching 비용⬇️
- 생성 시간⬇️
- 오류시 타 쓰레드에 영향O
- 프로세스
📖 참고 📖 크롬 브라우저는 한 탭에 오류가 생겨도, 다른 탭에 영향을 끼지 않습니다. 그렇다면 크롬은 프로세스인가요? 쓰레드인가요?
- 프로세스
- 크롬 탭이 쓰레드라면, 한 크롬탭에서 오류가 생기면 다른 크롬 탭에도 영향이 감
✏️ 멀티 프로세스와 멀티 쓰레드를 비교해주세요
-
Multi Process : 하나의 프로그램을 여러 개의 프로세스로 구성해 프로세스가 병렬적으로 작업 수행 (타 프로세스에 영향X, 많은 메모리 공간 차지)
-
Multi Thread : 하나의 프로세스를 여러 개의 쓰레드로 구성해 쓰레드가 자원을 공유하면서 작업 수행 (문맥 교환 빠르고, 적은 메모리 공간 차지, 동기화 필요)
📖 참고 📖 멀티 쓰레드를 많이 사용하는 이유
- 하나의 프로그램 안에서 여러 작업을 해결하는게 더 효율적이고, Context Switching시 Stack 영역만 초기화하여 빠름
- 프로세스 생성시 자원 할당하는 콜이 줄어들어 자원 효율적 관리 가능
📖 참고 📖 Python에서의 멀티 프로세스
- 파이썬은 GIL(Global Interpreter Lock) 정책 사용
- 하나의 프로세스 안에 모든 자원의 Lock을 global하게 관리하여 한 번에 하나의 쓰레드만 자원을 컨트롤해 사용
- I/O 동작이 많은 프로그램의 경우 : 멀티 쓰레드만으로 효과
- CPU 동작이 많은 경우 : 멀티 프로세스를 이용해서 병렬적으로 수행 가능
✏️ 컨텍스트 스위칭에 대해 설명하고, 왜 필요한지 설명해주세요
-
Context Switching (문맥 교환) : 현재 진행중인 프로세스의 상태를 PCB에 저장하고, 다음 진행할 프로세스의 상태 값을 읽어 레지스터에 적재하는 과정
-
필요 원인 : CPU Cycle 속도가 I/O 작업에 비해 매우 빨라, 문맥 교환을 통해 다른 프로세스로 전환하여 CPU 사용률⬆️
📖 참고 📖 Context Switching 과정
- 1) CPU가 다른 프로세스로 전환하면, 시스템은 프로세스 상태를 PCB에 저장
- 2) 대기열에서 다음 프로세스를 선택하고, 해당 프로세스의 PCB를 복원
- 3) PCB의 프로그램 카운터(레지스터)가 로드되어, 이전까지 작업한 곳의 지점으로 돌아가 선택한 프로세스의 작업을 이어서 함
✏️ 프로세스 제어 블록 (PCB)에 대해 자세히 설명해주세요
-
Process Control Block : 프로세스를 관리하기 위한 정보를 포함하는 OS 커널의 자료구조
-
과정 : OS는 프로세스의 생성과 동시에 고유한 PCB 생성 ➡️ 인터럽트 등 프로세스 전환이 발생하면, 진행하던 프로세스 관련 데이터를 PCB에 저장 ➡️ CPU 할당 받으면, PCB에서 내용 불러와 문맥 교환 후 다시 작업 수행
📖 참고 📖 PCB에 저장되는 정보
- 프로세스 식별자(PID) : 프로세스 식별번호
- 프로세스 상태 : new, ready, runnig, waiting, terminated 등 상태를 저장
- 프로그램 카운터 : 프로세스가 다음에 실행할 명령어의 주소
- CPU 레지스터
- CPU 스케쥴링 정보 : 프로세스의 우선순위, 스케줄 큐에 대한 포인터
- 메모리 관리 정보 : 페이지/세그먼트 테이블 등 정보
- 입출력 상태 정보 : 프로세스에 할당된 입출력 장치와 열린 파일 목록
- 어카운팅 정보 : 사용된 CPU 시간, 시간제한, 계정정보 등
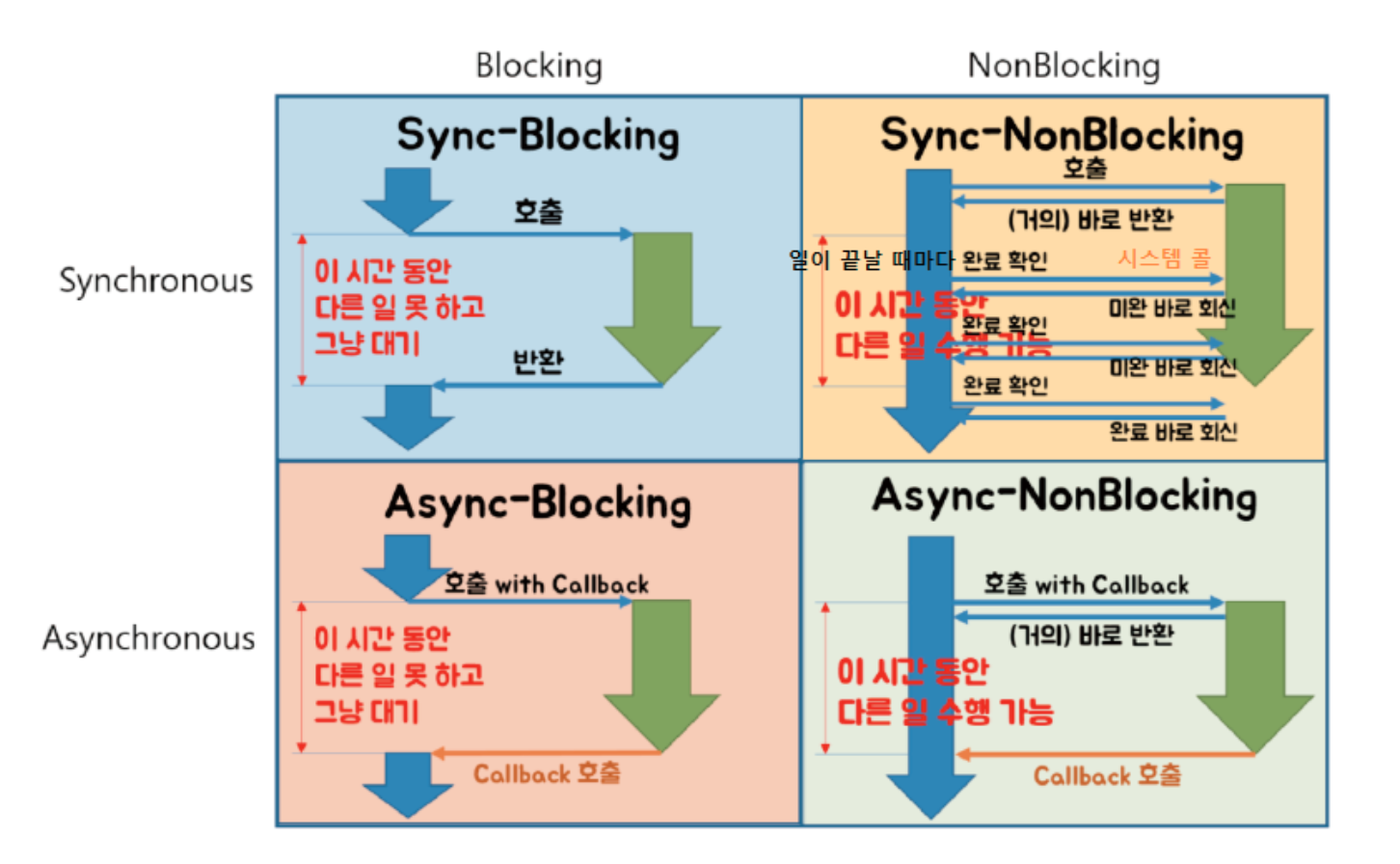
✏️ 동기와 비동기 차이에 대해 설명해주세요
-
Sync : 요청을 하면 반드시 결과가 주어져야 함
- 설계가 매우 간단하고 직관적
- 결과가 주어질 때까지 아무것도 못하고 대기해야 함
- A함수가 B함수를 호출할 때, B함수의 결과를 A가 처리함
-
Async : 요청과 결과가 동시에 일어나지 않음
- 대기 시간동안 다른 작업 가능해서, 자원을 효율적으로 사용 가능
- 동기보다 복잡한 방식
- A함수가 B함수를 호출할 때, B함수의 결과를 B가 처리하고 A에게 callback으로 알려줌
-
동기/비동기 : 호출된 함수의 종료를 호출한 함수가 처리하는지, 호출된 함수가 처리하는지
✏️ Blocking과 Non-Blocking에 대해 설명해주세요
-
Blocking : A함수가 B함수를 호출할 때, B함수가 자신의 작업 종료하기 전까지 A함수에게 제어권을 돌려주지 않는 것
- B 함수가 종료될 때까지 A 함수는 다른 일을 수행할 수 없음
-
Non-Blocking : A함수가 B함수를 호출할 때, B함수가 A함수에게 바로 제어권 돌려주는 것
- A함수는 제어권을 가지고 있으므로 다른 일 수행 가능함
-
blocking/non-blocking : 호출된 함수가 호출한 함수에게 제어권을 바로 주는지, 안주는지
✏️ 프로세스 종류에 대해 설명해주세요
-
자식 프로세스 : fork로 자식 프로세스를 만튼 상태 (부모의 데이터, 힙, 스택, PCB 복사)
-
데몬 프로세스 : 백그라운자에서 동작하면서 특정 서비스를 제공하는 프로세스
-
고아 프로세스 : 부모 프로세스가 먼저 종료되어 고립된 자식 프로세스
-
좀비 프로세스 : 자식 프로세스가 종료되었음에도 불구하고, 부모 프로세스로부터 작업 종료에 대한 승인을 받지 못한 프로세스
✏️ Race Condition과 Critical Section이 무엇이고, 경쟁상태를 막기 위해 어떤 방법을 사용하는지 설명해주세요
-
Race Condition (경쟁상태) : 2개 이상의 쓰레드가 공유자원에 대해 접근하려고 서로 경쟁하는 것
-
Crtical Section (임계 영역) : 공유자원이 존재하여 경쟁상태가 일어날 수 있는 영역
-
Mutual Exclusion (상호 배제) : 임계 영역에 대한 경쟁상태를 제거하기 위해서 1 공유자원에 1 쓰레드만 접근하도록 허락함
✏️ Deadlock(교착상태)와 그 해결방법에 대해 설명해주세요
-
Deadlock : 2개 이상의 프로세스나 쓰레드가 서로 자원을 기다리면서 무한히 대기하는 상태
-
발생 조건
- 상호 배제 (Mutual Exclusion) : 한 자원에 여러 프로세스가 동시에 접근할 수 없음
- 점유 대기 (Hold and Wait) : 하나의 자원을 소유한 상태에서 다른 자원을 기다림
- 비선점 (Non-preemption) : 프로세스가 어떤 자원의 사용을 끝낼 때까지 프로세스의 자원을 뺏을 수 없음
- 순환대기 (Circular Wait) : 각 프로세스가 순환적으로 다른 프로세스가 요구하는 자원을 가짐
-
해결 방법
- 예방 (Prevention) : 교착 상태 조건 중 1개를 제거하여 deadlock 발생 예방 (자원 낭비 심함)
- 회피 (Avoidance) : deadlock 발생 가능성을 인정하지만 적절하게 회피하는 방식 (은행원 알고리즘)
- 회복 (Recovery) : 시스템 자원 할당 상태를 가지고 deadlock 발생 여부 탐색, deadlock일 경우 회복
- 데드락 상태의 프로세스 모두 중단시키기
- 프로세스를 하나씩 중단 시킬 때마다 탐지 알고리즘으로 데드락 탐지하면서 회복시키기
- 자원 선점을 통해 해결하기 (교착 상태에 있는 프로세스가 점유한 자원을 선점하여 다른 프로세스에 할당)
📖 참고 📖 은행원 알고리즘
- 프로세스가 자원을 요구할 때 시스템은 자원을 할당한 후에도 안정 상태로 남아있는지 사전 검사 알고리즘
- 발생하지 않으면 자원을 할당하고, 발생하면 다른 프로세스가 자원을 해제할 때까지 대기
- 안전상태 : 시스템이 교착상태를 일으키지 않으면서 각 프로세스가 요구한 최대 요구량만큼 필요한 자원을 할당해 줄 수 있는 상태
- 장점 : 항상 안전 상태를 유지할 수 있음
- 단점 : 최대 자원 요구량을 미리 알아야하고, 항상 불안전 상태를 방지해야 하므로 자원 이용도가 낮음
✏️ '식사하는 철학자 문제'에서, Deadlock이 어떨 때 발생하고, 해결 방법을 설명해주세요

- 모든 철학자가 방에 입장한 후, 각자의 왼쪽 포크를 5명이 모두 드는 경우에 deadlock 발생
- 5명 모두 자신의 왼쪽 포크를 들고 있으므로
점유대기 - 남이 포크를 뺏어주지 않음
비선점 - 서로 오른쪽 포크를 놓기만을 기다림
환형대기 - 각 포크에 대해 한 사람만 들 수 있음
상호배제
- 5명 모두 자신의 왼쪽 포크를 들고 있으므로
- 문제를 해결하기 위해서 카운팅 세마포어 사용
- 방에 대한 입장 전원을 카운팅 세마포어로 설계해, 최대 4명만 들어온다면 방 안의 모든 사람들이 왼쪽 포크를 든다 하더라도 Deadlock 발생X
✏️ Mutex(뮤텍스)와 Semaphore(세마포어)에 대해 설명해주세요
-
Mutex : 오직 1개의 프로세스(스레드)만 접근 가능하고, 반드시 락을 획득한 프로세스는 락을 해제해야 함
-
Semaphore : 세마포어 변수만큼의 프로세스(스레드)가 접근 가능하고, 현재 수행중인 프로세스가 아닌 다른 프로세스가 세마포어 해제 가능
-
뮤텍스와 세마포어를 사용해 임계영역에서 경쟁상태 제거 가능
-
이진 세마포어 = 뮤텍스, 그 외 세마포어를 카운팅 세마포어라고 부름
✏️ 동시성과 병렬성이 어떻게 다른지 설명해주세요
- 동시성 : 주기억장치에 여러 프로세스를 적재해서 Context Switching을 통해 동시에 실행되는 것처럼 보이게 하는 것 (멀티 프로그래밍에서 나온 개념)
➡️ 싱글 코어에서 멀티스레드를 동작시키기 위한 방식
- 병렬성 : 실제로 동시에 여러 프로세스를 병렬적으로 실행하는 방식 (멀티 프로세싱에서 나온 개념)
➡️ 병렬적으로 실행하기 위해서는 CPU가 멀티코어야함
✏️ 스풀링(spooling)과 버퍼링과 스풀링 차이에 대해서 설명해주세요
-
스풀링 : 나중에 처리하거나 인쇄하기 위해 데이터를 일시적으로 저장하는 시스템 (다른 응용프로그램이 동시에 출력을 프린터로 보내면 스풀링은 모든 작업을 작업 풀(디스크 파일)에 보관하고 프린터에 따라 대기열에 넣음)
-
공통점 : 버퍼링과 스풀링은 CPU의 처리속도와 입출력 장치의 속도 차이를 보완하기 위한 방법
-
차이점
- 버퍼링 : 주기억 장치를 버퍼로 사용, 한 레코드가 읽혀 CPU가 연산을 시작하면, 입출력 장치는 레코드를 미리 읽어서 버퍼에 저장하여 레코드를 기다림 없이 전달
➡️ (입력) CPU가 버퍼의 내용을 가져다 쓰고 입력장치가 버퍼에 내용을 기록
➡️ (출력) CPU가 연산된 결과를 버퍼에 저장하고, 출력장치는 버퍼의 내용을 꺼내서 출력 - 스풀링 : 디스크를 버퍼로 사용, 디스크의 파일을 미리 입력 장치로부터 읽어들이고, 출력 장치가 받을 때까지 일시적으로 저장 (작업 풀)
➡️ (입력 스풀링) 데이터베이스 파일 입력에 적용, 입력 장치에서 정보를 가져오고 작업 스케줄링을 준비하며 작업 큐에 항목을 배치함
➡️ (출력 스풀링) 작업 출력을 프린터/디스켓 장치로 송신하는 대신 디스크 기억장치로 송신하여 속도나 가용성을 고려하지 않고 처리
- 버퍼링 : 주기억 장치를 버퍼로 사용, 한 레코드가 읽혀 CPU가 연산을 시작하면, 입출력 장치는 레코드를 미리 읽어서 버퍼에 저장하여 레코드를 기다림 없이 전달
📕 CPU
✏️ CPU Scheduling이 무엇인지 설명하고, CPU 스케줄링 종류에 대해 설명해주세요
-
CPU Scheduling : Ready Queue에 있는 프로세스 중 다음에 CPU에 할당할 프로세스를 선택하는 알고리즘
-
비선점
- FCFS (First Come First Served)
- 큐에 도착한 순서대로 실행
- 최악의 경우 오래 걸리는 문제가 가장 먼저 들어옴
- SJF (Shortest Job First)
- CPU 점유 시간이 가장 짧은 프로세스에 CPU를 먼저 할당하는 방식
- 기아 문제 발생
- HRRN (Highest Response Ratio Next)
- 준비 큐에서 기다리는 프로세스 중 응답 비율이 가장 큰 것을 먼저 처리하는 방식
- 서비스 받을 시간이 분모, 대기 시간이 분자에 있어 대기 시간이 큰 경우 우선순위가 높아짐
- FCFS (First Come First Served)
-
선점
- RR (Round Robin)
- 시간 할당량을 매 프로세스에 주고, 할당된 시간에 완료하지 못한 프로세스는 레디 큐의 맨 뒤에 배치하는 방식
- SRTF (Shortest Remaining Time First)
- CPU 점유 시간이 가장 짧은 프로세스에 CPU를 먼저 할당하는 방식
- SJF 방식에서 선점 방식만 다름
- 기아 문제 발생
- MFQ (Multilevel Feedback Queue)
- 각 단계마다 하나의 큐를 두고, 큐 시간 할당량 내에 처리하지 못하면 다음 큐로 보내는 방식
- 단계가 커질수록 시간 할당량이 커지는 형태
- RR (Round Robin)
✏️ CPU의 성능 척도에 무엇이 있는지 설명해주세요
- CPU Utilization (이용률) : CPU가 놀지 않고 일한 시간
- Throughput (처리량) : 단위 시간당 처리량, CPU가 얼마나 많은 일을 했는지
- Turnaround Time (소요시간, 반환시간) : CPU 사용 시간 + 기다린 시간
- Waitimg Time (대기시간) : 프로세스가 Ready Queue에서 기다린 전체 시간의 합
- Response Time (응답시간) : 프로세스가 Ready Queue에 들어가서 최초로 CPU 얻기까지 걸린 시간
✏️ 선점(preemption)과 비선점(non-preemption)이 무엇인지 설명해주세요
- 선점 방식
- 특정 프로세스가 실행 중이더라도 CPU 할당을 뺏어 다른 프로세스에 부여할 수 있는 방식
- System Call, Time Quantum, Interrupt 등에 의해 선점 발생
- 비선점 방식
- 특정 프로세스가 실행 중이면 끝나기 전까지 절대로 다른 프로세스에게 CPU를 뺏기지 않는 방식
✏️ Interrupt(인터럽트)에 대해 설명해주세요
- 프로그램을 실행하고 있는 도중에 입출력 요청/예외 상황을 처리할 경우 실행하던 프로그램을 멈추고 CPU가 해당 작업을 처리하도록 하는 것
✏️ System Call에 대해 설명해주세요
- 사용자나 응용 프로그램이 커널에서 제공하는 기능을 사용하기 위한 인터페이스
- 운영체제는 커널이 제공하는 서비스를 시스템 콜을 사용해야만 사용할 수 있도록 제한함으로써 컴퓨터 자원을 보호하면서 사용자나 응용 프로그램에게 서비스 제공할 수 있음
✏️ DMA (Direct Memory Access)에 대해 설명해주세요
- 다량의 데이터가 이동하면서 CPU에 많은 부하가 걸림
- CPU의 개입 없이 입출력장치와 메모리가 직접 접근하여 데이터를 전송하는 방법
📖 참고 📖 입출력 제어 방식 4가지
- 1️⃣ : 프로그램에 의한 I/O (CPU 개입⭕)
- 2️⃣ : 인터럽트에 의한 I/O (CPU 개입⭕)
- 3️⃣ : DMA에 의한 I/O (CPU 개입❌)
- 4️⃣ : 채널에 의한 I/O (CPU 개입❌)
📒 자바
📕
✏️
📒 자바스크립트
📕
✏️
- 🗒️ 예시 :
📖 참고 📖
- ✏️
➡️⬆️⬇️
