
📒 자료구조
📕 배열
1. 정적 배열 (array)
1) 개념
- 선언할 때 보통 크기를 설정해서 연산 진행
- 연속된 메모리 공간에 위치한 같은 타입의 요소들의 모음
- 숫자 인덱스 기반으로 랜덤 접근 가능하며 중복 허용
- 동적 배열(vector)과 달리 메서드X
- int a[3] : 배열의 크기를 정해서 선언
- int a[] = {1, 2, 3, 4} : 크기를 정하지 않고 선언, 요소 할당하면 자동적으로 rvalue의 크기로 할당됨

#include <bits/stdc++.h>
using namespace std;
int a[3] = {1, 2, 3};
int a2[] = {1, 2, 3, 4};
int a3[10];
int main(){
for(int i = 0; i < 3; i++) cout << a[i] << " ";
cout <<'\n';
for(int i : a) cout << i << " ";
for(int i = 0; i < 4; i++) cout << a2[i] << " ";
cout <<'\n';
for(int i : a2) cout << i << " ";
for(int i = 0; i < 10; i++) a3[i] = i;
cout <<'\n';
for(int i : a3) cout << i << " ";
return 0;
}
/*
1 2 3 (a)
1 2 3 1 2 3 4 (a + a2)
1 2 3 4 (a2)
0 1 2 3 4 5 6 7 8 9 (a3)2. 동적 배열 (vector)
1) 개념
- 동적으로 요소를 할당할 수 있음
- 컴파일 시점에 사용해야 할 요소들의 개수를 모를 경우 사용
- 연속된 메모리 공간에 위치한 같은 타입의 요소들의 모음
- 숫자 인덱스를 기반으로 랜덤접근이 가능하며 중복 허용
- vertor<int/string/...> 변수명;
- 시간복잡도
- 참조 : O(1)
- 탐색 : O(n)
- 맨 끝에 삽입/삭제 : O(1)
- 맨 끝 제외 삽입/삭제 : O(n)
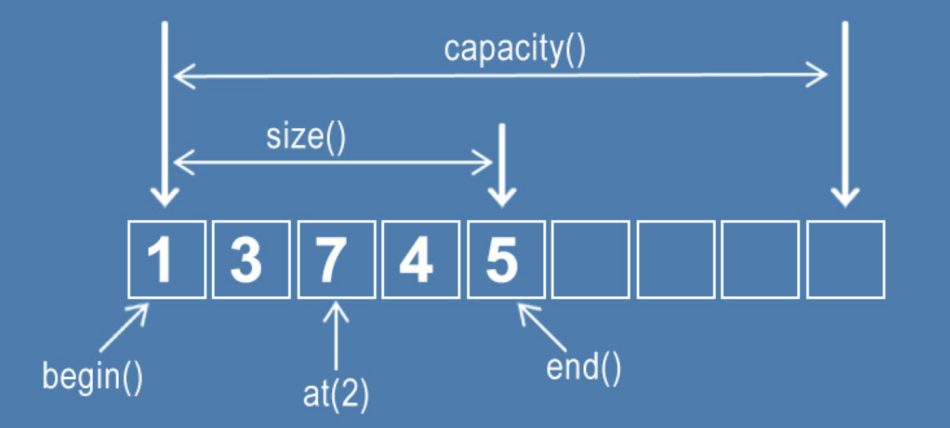
#include <bits/stdc++.h>
using namespace std;
vector<int> v;
int main(){
for(int i = 1; i <= 10; i++)v.push_back(i);
for(int a : v) cout << a << " ";
cout << "\n";
for(int i = 0; i < v.size(); i++){
cout << &v[i] << '\n';
}
v.pop_back();
for(int a : v) cout << a << " ";
cout << "\n";
v.erase(v.begin(), v.begin() + 3);
for(int a : v) cout << a << " ";
cout << "\n";
auto a = find(v.begin(), v.end(), 100);
if(a == v.end()) cout << "not found" << "\n";
fill(v.begin(), v.end(), 10);
for(int a : v) cout << a << " ";
cout << "\n";
v.clear();
cout << "아무것도 없을까?\n";
for(int a : v) cout << a << " ";
cout << "\n";
return 0;
}
/*
/tmp/k7wTAJUMUe.o
1 2 3 4 5 6 7 8 9 10
0x55d296744f20
0x55d296744f24
0x55d296744f28
0x55d296744f2c
0x55d296744f30
0x55d296744f34
0x55d296744f38
0x55d296744f3c
0x55d296744f40
0x55d296744f44
1 2 3 4 5 6 7 8 9
4 5 6 7 8 9
not found
10 10 10 10 10 10
아무것도 없을까?
*/2) 메서드
- push_back() : vector의 뒤에서부터 요소를 더함, 같은 기능의 emplace_back()도 있음
- pop_back() : vector의 맨 뒤의 요소를 지움
- erace(from, to) : 요소의 위치에 해당하는 구간 삭제
iterator erace (const_iterator position); iterator erace (const_iterator first, const_iterator last); - find(fron, to, value) : from~to 구간에서 value 찾기 (O(n)의 시간복잡도)
- clear() : vector의 모든 요소를 지움
- fill(from, to, value) : vector내의 from~to 구간에 value로 값을 채움 (초기화)
📖 참고 📖 범위 기반 for 루프
- for (range_declaration : range_expression)
loop_statement- 🗒️ 예시 : for(int a : v)
- vector 내에 있는 요소들을 탐색
- vector 뿐만 아니라 Array, 연결리스트, 맵, 셋을 탐색할 때도 사용
- for(int i = 0; i < v.size(); i++) int a = v[i]; 와 동일
3) vector의 정적할당
- 크기를 정해놓거나 해당 크기에 대해 어떠한 값으로 초기화 해놓고 시작 가능
#include <bits/stdc++.h>
using namespace std;
vector<int> v(5, 100);
int main(){
for(int a : v) cout << a << " ";
cout << "\n";
return 0;
}
/*
100 100 100 100 100
*/📕 연결리스트
1. 개념
- 노드로 감싸진 요소를 인접한 메모리 위치가 아닌 독립적으로 저장
- 각 노드는 next, prev라는 포인터로 서로 연결된 선형적인 자료구조

- 시간복잡도
- 참조 : O(n)
- 탐색 : O(n)
- 삽입/삭제 : O(1)
📖 참고 📖 노드
- data, next로 이루어진 구조체
- 어떠한 값을 담는 Data, 노드와 노들르 잇는 Next 포인터로 이루어짐
class Node { public: int data; Node* next; Node(){ data = 0; next = NULL; } Node(int data){ this->data = data; this->next = NULL; } };
2. 종류
1) 싱글 연결 리스트 (Singly Linked List)
- next 포인터만 존재
- 한 방향으로만 데이터가 연결

2) 이중 연결 리스트 (Doubly Linked List)
- prev, next 2개의 포인터로 양방향으로 데이터 연결

3) 원형 연결 리스트 (Circular Linked List)
- 마지막 노드와 첫 번째 노드가 연결되워 원을 형성
- 싱글 연결리스트 또는 이중 연결리스트로 이루어진 2가지 타입의 원형 연결리스트 존재
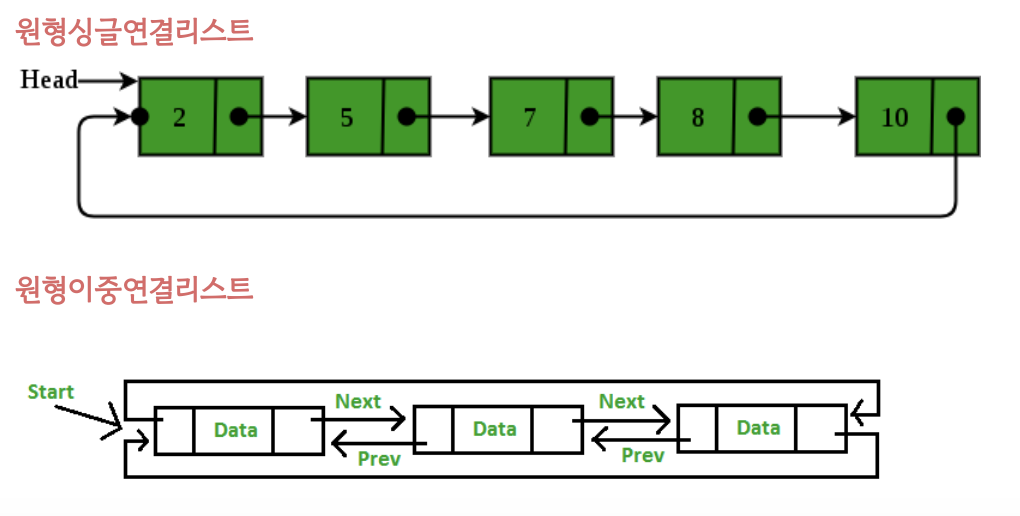
#include <bits/stdc++.h>
using namespace std;
list<int> a;
void print(list <int> a){
for(auto it : a) cout << it << " ";
cout << '\n';
}
int main(){
for(int i = 1; i <= 3; i++)a.push_back(i);
for(int i = 1; i <= 3; i++)a.push_front(i);
auto it = a.begin(); it++;
a.insert(it, 1000);
print(a);
it = a.begin(); it++;
a.erase(it);
print(a);
a.pop_front();
a.pop_back();
print(a);
cout << a.front() << " : " << a.back() << '\n';
a.clear();
return 0;
}
/*
3 1000 2 1 1 2 3
3 2 1 1 2 3
2 1 1 2
2 : 2
*/3. 메서드
- push_front(value) : 리스트 앞에서부터 value 삽입
- push_pack(value) : 리스트 뒤에서부터 value 삽입
- insert(idx, value) : 요소를 몇번째에 삽입
iterator insert(const_iterator positon, const value_type&val);- erase(idx) : 리스트의 idx번째 요소 삭제
iterator erase(const_iterator positon);- pop_front() : 첫번째 요소 삭제
- pop_back() : 마지막 요소 삭제
- front() : 첫번째 요소 참조
- back() : 마지막 요소 참조
- clear() : 모든 요소 삭제
4. 랜덤 접근과 순차 접근
1) 랜덤 접근 (직접 접근)
- 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능
- vector, array와 같은 배열은 랜덤 접근 가능
- n번째 요소에 접근할 때 O(1) 걸림
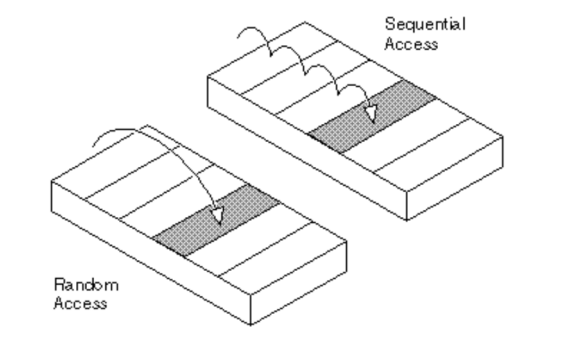
- n번째 요소에 접근할 때 O(1) 걸림
2) 순차 접근
- 데이터를 저장된 순서대로 검색해야 하는 기능
- 연결리스트, 스택, 큐는 순차적 접근만 가능
- n번째 요소에 접근할 때 O(n) 걸림
📕 스택
1. 개념
- 가장 마지막으로 들어간 데이터가 가장 첫 번째로 나오는 LIFO(Last In First Out)
- 🗒️ 예시 : 재귀적인 함수, 알고리즘에 사용
- 웹 브라우저 방문 기록 등에 사용
- 시간복잡도
- n번째 참조 : O(n)
- 가장 앞부분 참조 : O(1)
- 탐색 : O(n)
- 삽입/삭제(n번째 제외) : O(1)
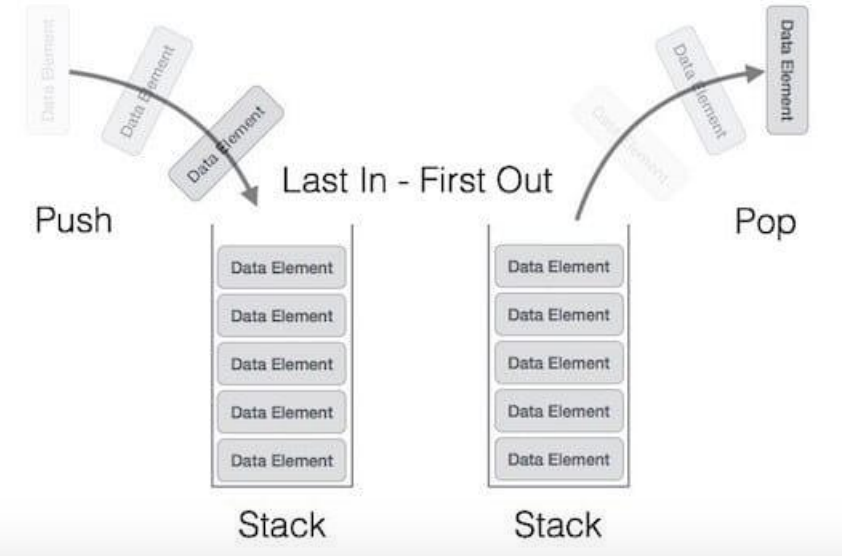
#include<bits/stdc++.h>
using namespace std;
stack<string> stk;
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
stk.push("엄");
stk.push("준");
stk.push("식");
stk.push("화");
stk.push("이");
stk.push("팅");
while(stk.size()){
cout << stk.top() << "\n";
stk.pop();
}
}
/*
팅
이
화
식
준
엄
*/2. 메서드
- push(value) : 해당 value를 스택에 추가
- pop() : 가장 마지막에 추가한 요소 지우기
- top() : 가장 마지막에 있는 요소 참조
- size() : 스택의 크기
📕 큐
1. 개념
- 먼저 집어넣은 데이터가 먼저 나오는 FIFO(First In First Out)
- 🗒️ 예시 : CPU 작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 배열, 너비우선 탐색, 캐시 등에 사용
- 시간복잡도
- n번째 참조 : O(n)
- 가장 앞부분 참조 : O(1)
- 탐색 : O(n)
- 삽입/삭제(n번째 제외) : O(1)
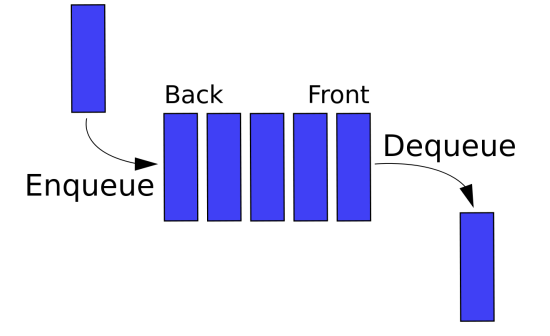
#include <bits/stdc++.h>
using namespace std;
queue<int> q;
int main(){
for(int i = 1; i <= 10; i++)q.push(i);
while(q.size()){
cout << q.front() << ' ';
q.pop();
}
return 0;
}
/*
1 2 3 4 5 6 7 8 9 10
*/2. 메서드
- push(value) : value를 큐에 추가
- pop() : 가장 앞에 있는 요소 제거
- size() : 큐의 크기
- front() : 가장 앞에 있는 요소 참조
📕 그래프
1. 개념 (Graph, Vertex, Edge, Weight)
1) 정점과 간선
-
그래프
- 정점과 간선들로 이루어진 집합
-
정점 (vertex)
- 노드, 그래프를 형성하는 기본 단위
- 분할할 수 없는 개체이자 점으로 표현되는 위치
-
간선 (edge)
- 정점을 잇는 선
- 관계, 경로
2) indegree와 outdegree
- 정점으로 나가는 간선을 해당 정점의 outdegree
- 정점으로 들어오는 간선을 해당 정점의 indegree
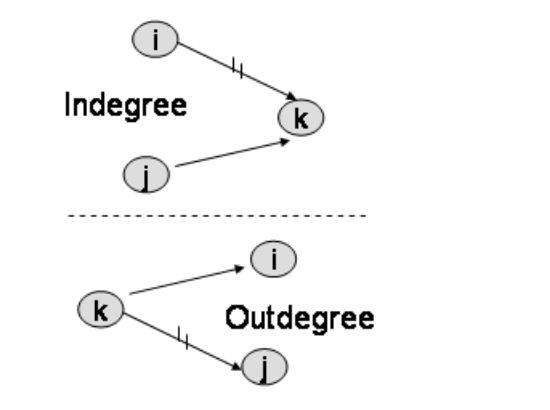
3) 가중치
- 정점과 정점사이에 드는 비용
- 🗒️ 예시 : 1번노드와 2번노드까지 가는 비용이 한칸이라면, 1번노드에서 2번노드까지의 가중치는 한칸
📕 트리
1. 트리
1) 개념
- 자식노드와 부모노드로 이루어진 계층적인 구조
- 무방향 그래프
- 사이클이 없는 자료구조
2) 특징
- 부모, 자식 계층 구조를 가짐
- 같은 경로 상에서 어떤 노드보다 위에 있으면 부모, 아래에 있으면 자식 노드
- V - 1 = E (간선 수 - 1 = 노드 수)
- 임의의 두 노드 사이의 경로는 유일하게 존재
- 트리 내의 어떤 노드와 다른 노드까지의 경로는 반드시 1개만 존재
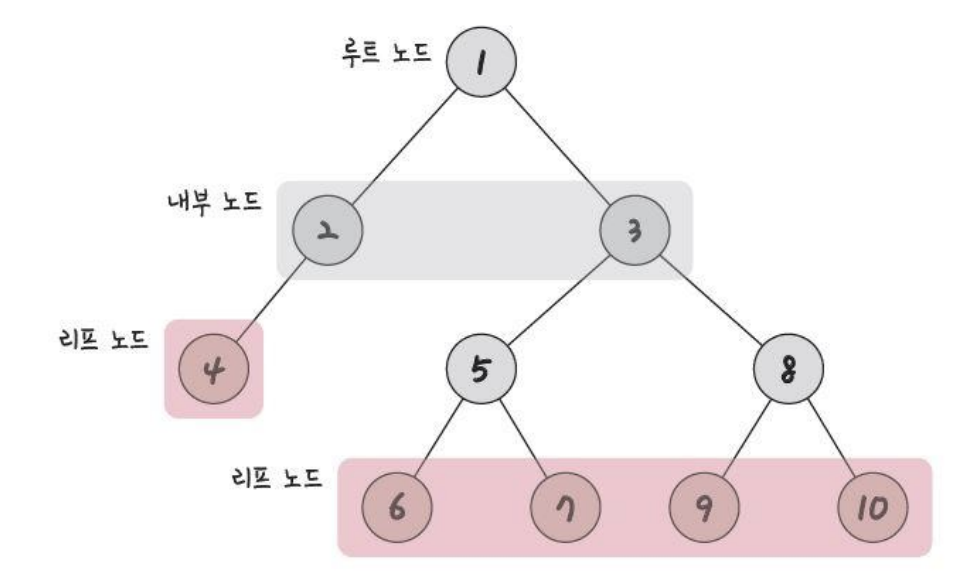
3) 노드 종류
- 루트 노드
- 가장 위에 있는 노드
- 트리를 탐색할 때 루트 노드를 중심으로 탐색하면 문제가 쉽게 풀림
- 내부 노드
- 루트 노드와 리프 노드 사이에 있는 노드
- 리프 노드
- 자식 노드가 없는 노드
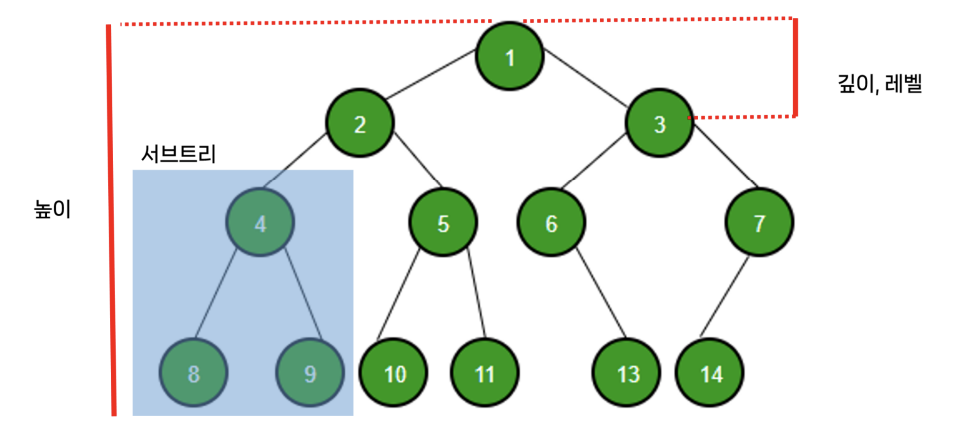
4) 트리의 높이와 레벨
- 깊이
- 루트 노드에서 특정 노드까지 최단거리로 갔을 때의 거리
- 트리에서 깊이는 각각의 노드마다 다름
- 높이
- 루트 노드부터 리프 노드까지의 거리 중 가장 긴 거리
- 레벨
- 깊이와 동일한 의미
- 서브 트리
- 트리 내의 하위 집합
- 트리 내에 있는 부분집합
5) 숲 (forest)
- 트리로 이루어진 집합
2. 이진트리
1) 개념
- 각각의 노드의 자식노드 수가 2개 이하로 구성되어 있는 트리
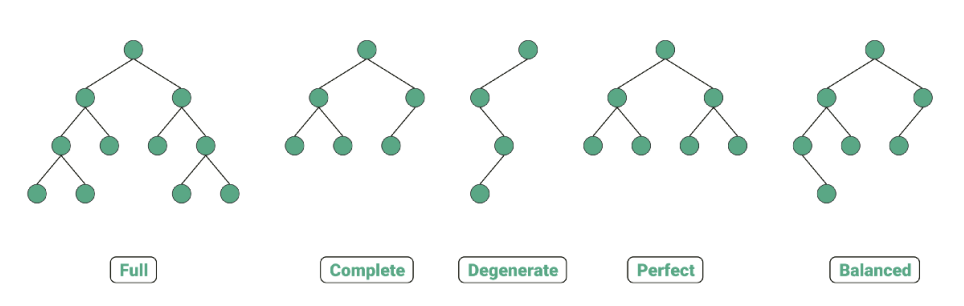
2) 종류
- 정이진 트리 (full binary tree)
- 자식 노드가 0 또는 2개인 이진 트리
- 완전 이진 트리 (complete binary tree)
- 왼쪽에서부터 채워져 있는 이진 트리
- 마지막 레벨을 제외하고는 모든 레벨이 완전히 채워져 있고, 마지막 레벨의 경우 왼쪽부터 채워져 있음
- 변질 이진 트리 (degenerate binary tree)
- 자식 노드가 하나밖에 없는 이진 트리
- 포화 이진 트리 (perfect binary tree)
- 모든 노드가 꽉 차 있는 이진 트리
- 균형 이진 트리 (balanced binary tree)
- 모든 노드의 왼쪽 하위 트리와 오른쪽 하위 트리의 차이가 1이하인 트리
- map, set을 구성하는 레드블랙트리는 균형이진트리의 종류
3. 이진탐색트리 (BST, Binary Search Tree)
1) 개념
- 노드의 오른쪽 하위 트리에는 노드의 값보다 큰 값이 있는 노드만 포함
- 왼쪽 하위트리에는 노드의 값보다 작은 값이 들어있는 트리
- 시간복잡도
- 탐색/삽입/삭제/수정 : O(logN)
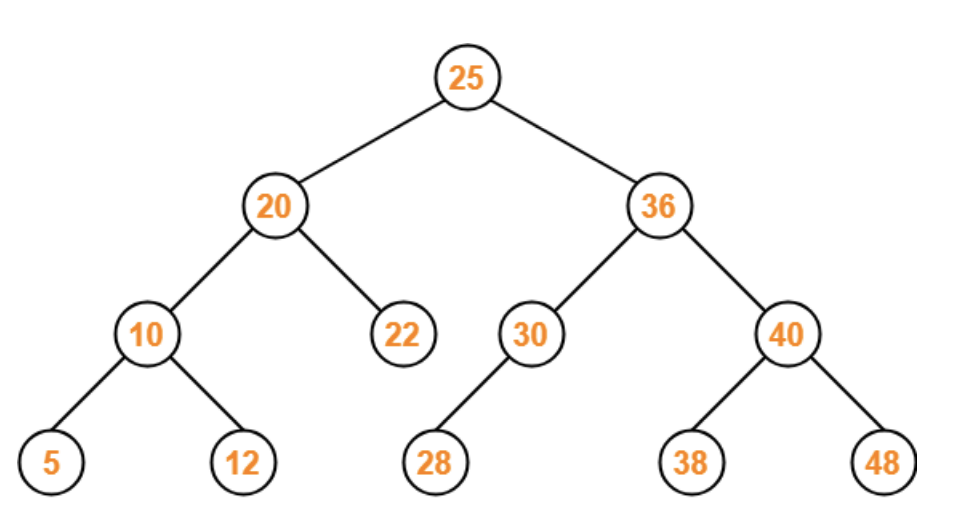
2) 특징
- 검색하기에 용이
- 전체 탐색X
- 삽입 순서에 영향을 받음
- 삽입 순서가 어떻든 트리의 노드를 회전시키는 방법을 통해 균형잡하게 만든 이진탐색트리
- AVL트리, 레드블랙트리
🗒️ 트래프와 그래프의 차이
그래프는 트리보다 더 포괄적인 개념입니다. 즉, 트리는 그래프라고 부를 수 있으나 모든 그래프를 트리라고 부를 순 없습니다.
그래프는 각 요소를 나타내는 노드와 노드 사이의 관계를 나타내는 엣지로 나타낼 수 있습니다.
트리는 그래프와 동일하나, 사이클이 없는 그래프를 의미하며 계층 구조를 나타낼 때 용이합니다.
🗒️ 이진 트리의 전위/중위/후위 순회
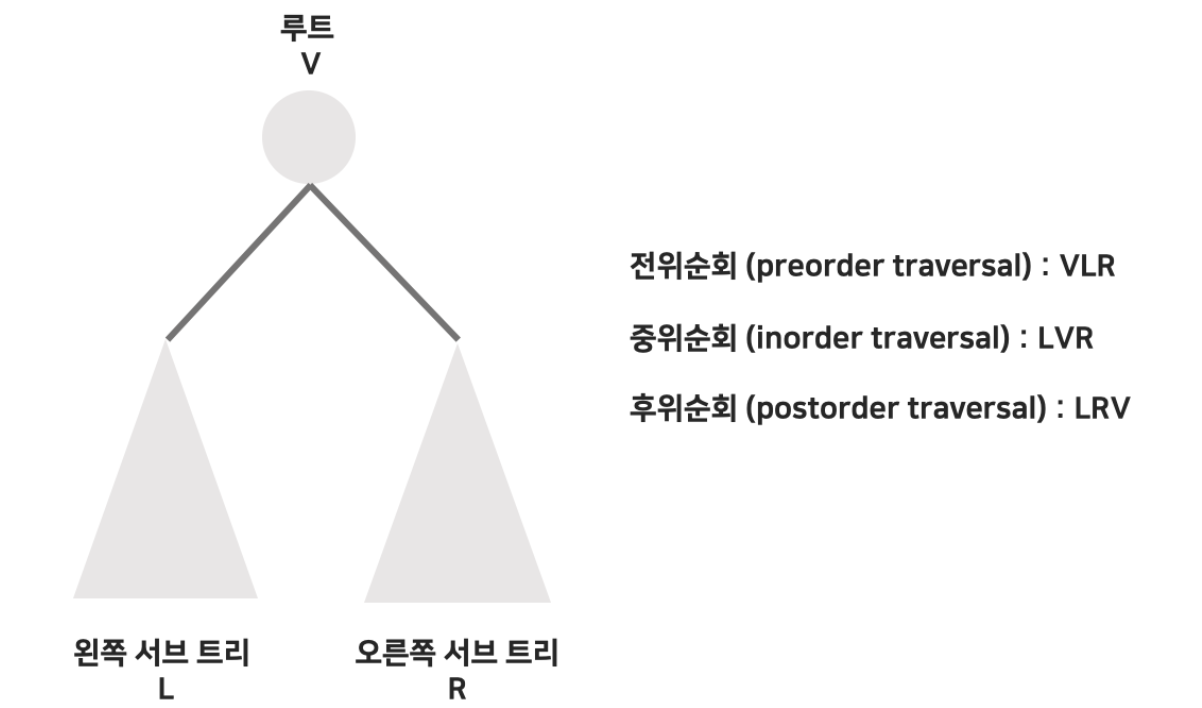
루트를 방문하는 작업을 V
왼쪽 서브 트리 방문을 L
오른쪽 서브트리 방문을 R
루트를 서브 트리에 앞서서 먼저 방문하면 전위 순회
루트를 왼쪽과 오른쪽 서브 트리 중간에 방문하면 중위 순회
루트를 서브 트리 방문 후에 방문하면 후위 순회
🗒️ BST (Binary Search Tree)
-
개념
- 데이터의 빠른 검색을 위해 만들어진 트리 자료구조
-
조건
- 이진 트리 (자식을 최대 2개까지 가질 수 있는 트리)
- 루트노드에 대해서 왼쪽 자식은 루트 노드보다 더 작은 값을, 오른쪽 자식은 루트 노드보다 더 큰 값을 저장
- 루트노드의 왼쪽 서브트리, 오른쪽 서브트리에 대해 위의 조건을 만족
-
시간 복잡도
- 탐색에 유리한 자료구조로, 특정 값에 대해 탐색하는 시간 복잡도가 트리의 높이에 의존 -> O(logN)의 시간복잡도
- 이진탐색트리의 왼쪽 서브 트리와 오른쪽 서브 트리의 균형이 맞지 않고 한 쪽으로만 치우쳐진 경우에는 트리의 높이 자체가 N이 됨 -> Worst Case의 경우 O(N)의 시간복잡도
-
성능 개선하는 방법
- BST의 양쪽 높이의 균형을 맞추는 것이 성능을 개선하는 방식
- 개량된 BST 트리로써, AVL 트리, Red-Black 트리
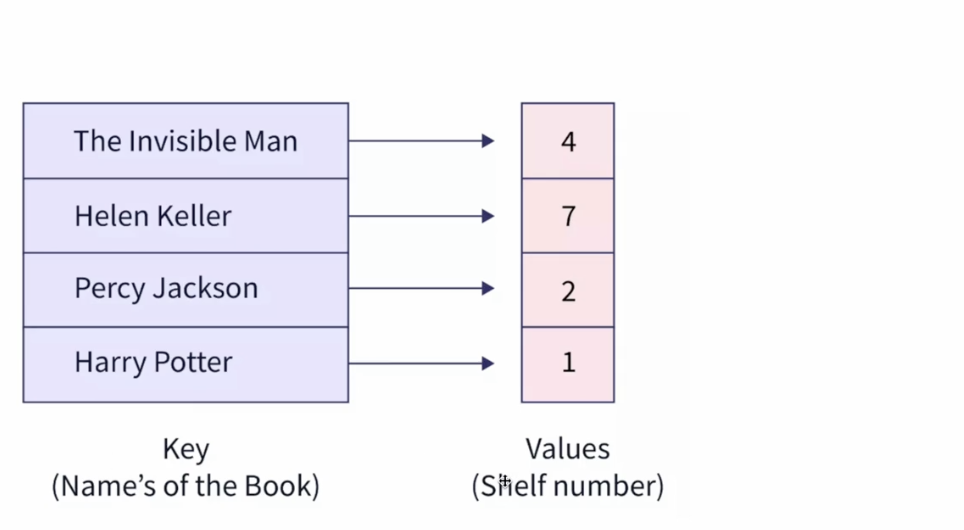
📕 맵
1. 개념
- 고유한 키를 기반으로 키-값(key-value) 쌍으로 이루어져 있고, 정렬됨 (삽입할 때마다 자동 정렬)
- 균형 잡힙 이진탐색트리는 레드
- 고유한 키를 가져 하나의 키에 중복된 값X
- []로 해당 키를 직접 참조할 수 있음
- 맵의 키와 값은 string이나 int 뿐만 아니라 다양한 값 가능
- 자동으로 오름차순 정렬되기 때문에 넣은 순서대로 map을 탐색하는 것이 아닌 아스키코드 순으로 정렬된 값을 기반으로 탐색
- 시간복잡도
- 참조 : O(logN)
- 탐색 : O(logN)
- 삽입/삭제 : O(logN)
#include <bits/stdc++.h>
using namespace std;
map<string, int> mp;
string a[] = {"주홍철", "양영주", "박종선"};
int main(){
for(int i = 0; i < 3; i++){
mp.insert({a[i], i + 1});
}
cout << mp["주홍철"] << '\n';
cout << mp.size() << '\n';
mp.erase("주홍철");
auto it = mp.find("kundol");
if(it == mp.end()){
cout << "맵에서 해당요소는 없습니다.\n";
}
// 이렇게도 삽입할 수 있습니다.
mp["kundol"] = 100;
for(auto it : mp){
cout << (it).first << " : " << (it).second << '\n';
}
mp.clear();
cout << "map의 사이즈는 : " << mp.size() << "입니다.\n";
return 0;
}
/*
1
3
맵에서 해당요소는 없습니다.
kundol : 100
박종선 : 3
양영주 : 2
map의 사이즈는 : 0입니다.
*/2. 메서드
- insert({key : value})
- map에다 {key, value}를 집어 넣음
- [key] = value
- 대괄호를 통해 key에 해당하는 value를 할당
- [key]
- key를 기반으로 map에 있는 요소 참조
- map에 해당 키에 맞는 요소가 없다면 0 또는 빈문자열로 초기화가 되어 할당됨
- int는 0, string/char는 빈문자열로 할당
- 할당하고 싶지 않아도 대괄호[]로 참조할 경우 자동 할당됨
- size()
- map에 있는 요소들의 개수 반환
- erase(key)
- 해당 키에 맞는 요소 지움
- find(key)
- map에서 해당 key를 가진 요소를 찾아 이터레이터를 반환
- 못찾을 경우 mp.end() 이터레이터 반환
- for(auto it : mp) : 범위기반 for루프로 map에 있는 요소들 순회
- map을 순회할 때는 key는 first, value는 second로 참조 가능
- for(auto it = mp.begin(); it != mp.end(); it++)
- map은 이터레이터로 순회 가능
- mp.clear()
- map에 있는 요소들 다 제거
📕 셋
1. 개념
- 고유한 요소만을 저장하는 자료구조
- 중복 허용X
- map처럼 {key, value} 넣지 않아도 되고, 중복된 값 자동 제거, 자동 정렬
- 메서드는 맵과 동일
- 시간 복잡도
- 참조 : O(logN)
- 탐색 : O(logN)
- 삽입/삭제 : O(logN)
#include <bits/stdc++.h>
using namespace std;
int main(){
set<int> st2;
st2.insert(2);
st2.insert(1);
st2.insert(2);
for(auto it : st2){
cout << it << '\n';
}
return 0;
}
/*
1
2
*/📕 해시테이블
1. 개념
- 큰 범위를 가진 각양각색의 데이터들을 해싱을 통해 한정된 범위의 정수값을 가진 해시로 만들고, 해시라는 키에 대응하여 원본 데이터들을 매핑시켜놓은 테이블
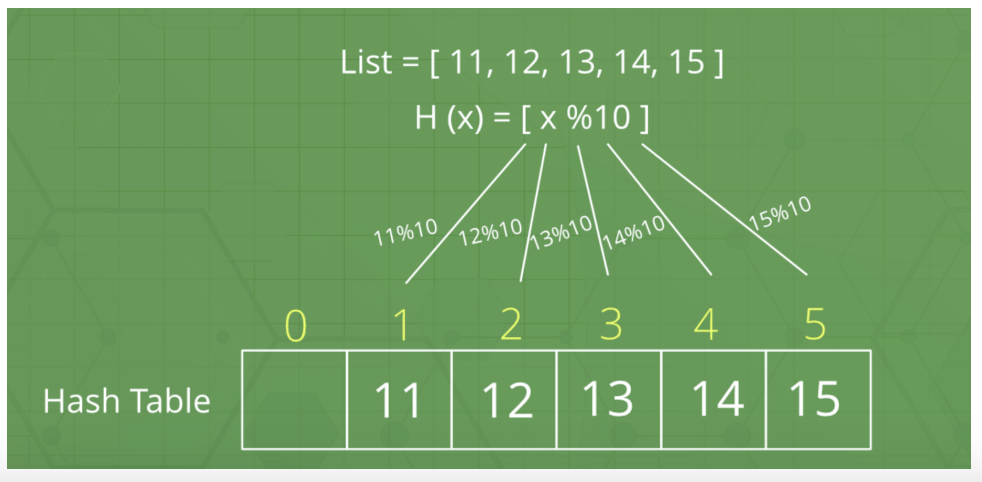
2. 해시, 해싱, 해시함수
- 해시
- 다양한 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한 값
- 해싱
- 임의의 데이터를 해시로 바꿔주는 일
- 해시함수가 담당
- 해시 함수
- 임의의 데이터를 입력으로 받아 일정한 길이의 데이터로 바꿔주는 함수
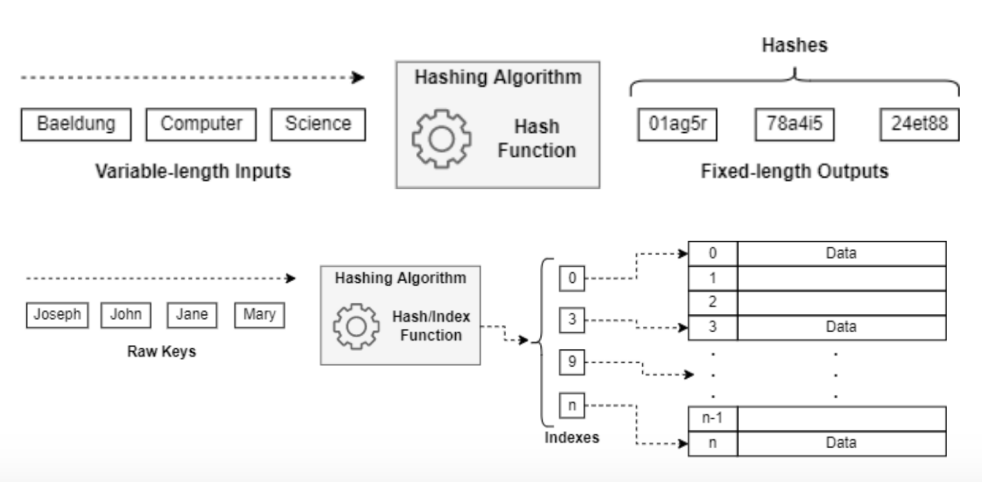
- 임의의 데이터를 입력으로 받아 일정한 길이의 데이터로 바꿔주는 함수
- 해시 함수 실습
- %연산자를 통해 유한한 값의 키 생성
let a = [1, 2, 42, 4, 12, 14, 17, 13, 37] const hashf = num => num % 20 a = a.map(e => hashf(e)) console.log(a) /* [ 1, 2, 2, 4, 12, 14, 17, 13, 17 ] */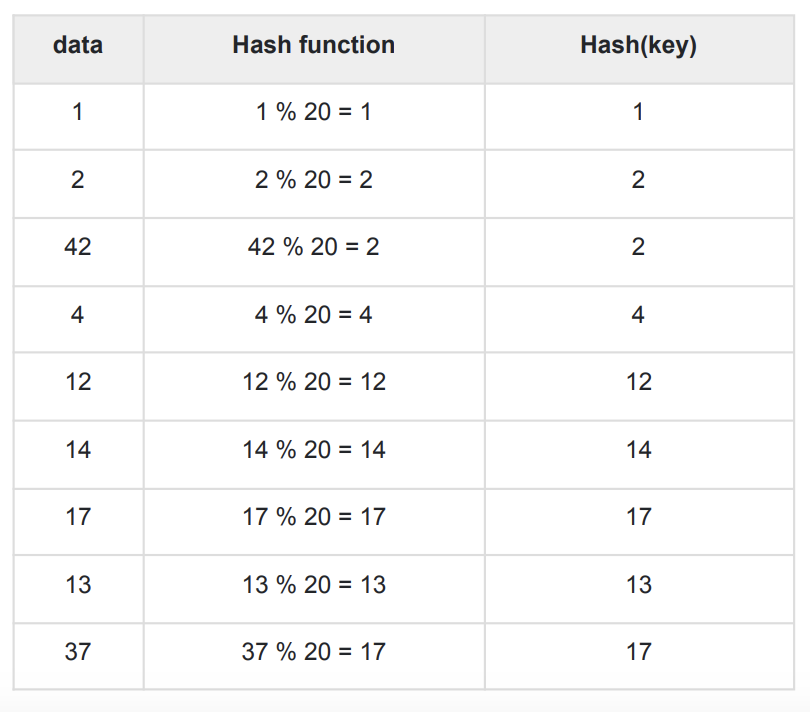
- 숫자가 아닌 문자열 기반으로 정수값의 해시생성 (객체, 문자열+숫자 값 가능)
let a = ["dopa", "paka", "ralo"] const hashf = (str, size) => { let hash = 3; for(let i = 0; i < str.length; i++){ hash *= str.charCodeAt(i) hash %= size } return hash } a = a.map(e => hashf(e, 20)) console.log(a) console.log('a'.charCodeAt(0)) // [ 0, 8, 12 ]- 데이터베이스에 개인정보를 암호화해서 저장할 때 사용
- MD5 : 레인보우 테이블을 통한 취약점으로 사용X
- bcrypt : 현재 데이터베이스에서 값을 암호화해서 저장할 때 많이 사용
3. 구현
- unorder_map을 통해 구현
#include <bits/stdc++.h>
using namespace std;
int hashF(string str){
int ret = str.size();
for(char a : str){
ret += (int)a;
}
return ret % 10;
}
int main(){
// 만약 내부적으로 구현이 되어있지 않다면 이런식으로 정수타입의 해시키를 만들어서
// 해시테이블을 구현해야 합니다.
unordered_map<int, string> umap;
umap[hashF("paka")] = "paka";
umap[hashF("kundol")] = "kundol";
//unordered_map은 해시테이블로 구현이 되어있기 때문에 내부적으로 string 값을
받아도 int타입의 해시키를 만들고
//이를 기반으로 테이블로 만들어버립니다.
unordered_map<string, string> umap2;
umap2["paka"] = "paka";
umap2["kundol"] = "kundol";
for(auto element : umap){
cout << element.first << " :: " << element.second << '\n';
}
for(auto element : umap2){
cout << element.first << " :: " << element.second << '\n';
}
cout << umap[7] << "\n";
cout << umap2["kundol"] << "\n";
return 0;
}
/*
9 :: kundol
7 :: paka
kundol :: kundol
paka :: paka
paka
kundol
*/📕 힙
1. 개념
- 여러 개의 값 중에서 가장 크거나 작은 값을 빠르게 찾기 위해 만든 완전 이진 트리
- 최소힙
- 가장 작은 요소가 루트 노드에 있음
- 부모 노드의 값은 자식 노드의 값보다 항상 작은 규칙을 지키는 힙
- 요소 중 가장 작은 값을 O(1) 만에 찾음
- 최대힙
- 가장 큰 요소가 루트 노드에 있음
- 부모 노드의 값은 자식노드의 값보다 항상 큰 규칙을 지키는 힙
- 요소 중 가장 큰 값을 O(1) 만에 찾음
- 이진 탐색 트리와 차이점
- 이진 탐색 트리 : 탐색을 쉽게하려고, 왼쪽이 작고 오른쪽이 큰 값으로 구성
- 힙 : 왼쪽 힙이 작고 오른쪽 힙이 클 필요
- 시간복잡도
- 참조(최대/최소값 참조) : O(1)
- 탐색 : O(n)
- 삽입/삭제 : O(logN)
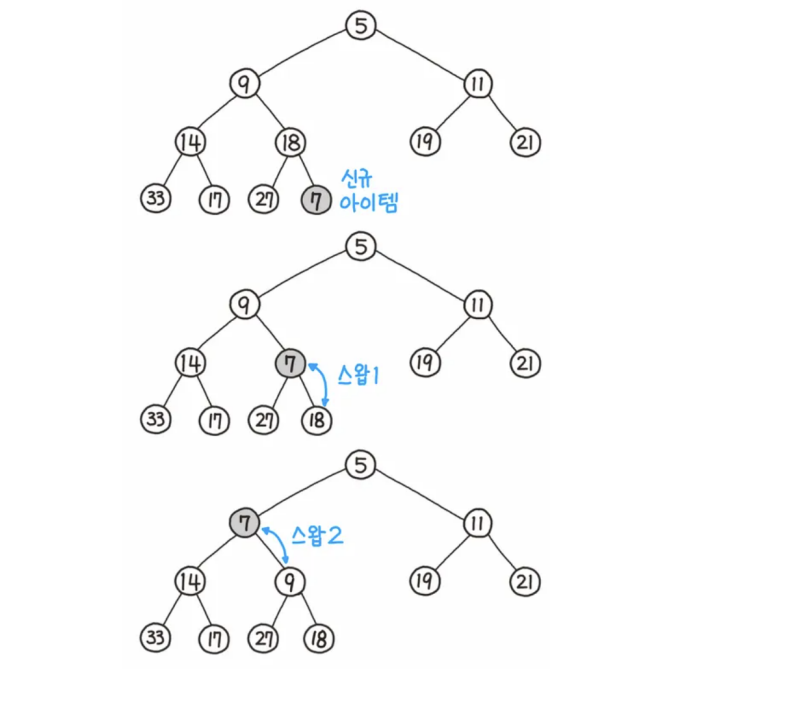
2. 힙의 데이터 삽입
1) 삽입 규칙
- 1️⃣ : 리프 노드에 삽입할 노드를 삽입
- 2️⃣ : 해당 노드와 부모노들르 서로 비교
- 3️⃣ : 규칙에 맞으면 그대로 두고, 그렇지 않으면 부모노드와 교환
- 4️⃣ : 규칙에 맞을 때까지 3번 과정 반복
2) 최소힙의 삽입 과정
3. 힙의 데이터 삭제
1) 삭제 규칙
-
루트 노드만을 제거할 수 있음
-
1️⃣ : 루트 노드를 제거함
-
2️⃣ : 루트 자리에 가장 마지막 노드 삽입
-
3️⃣ : 올라간 노드와 그의 자식노드와 비교
-
4️⃣ : 규칙을 만족하면 그대로 두고, 그렇지 않으면 자식노드와 교환함
2) 최소힙의 삭제 과정
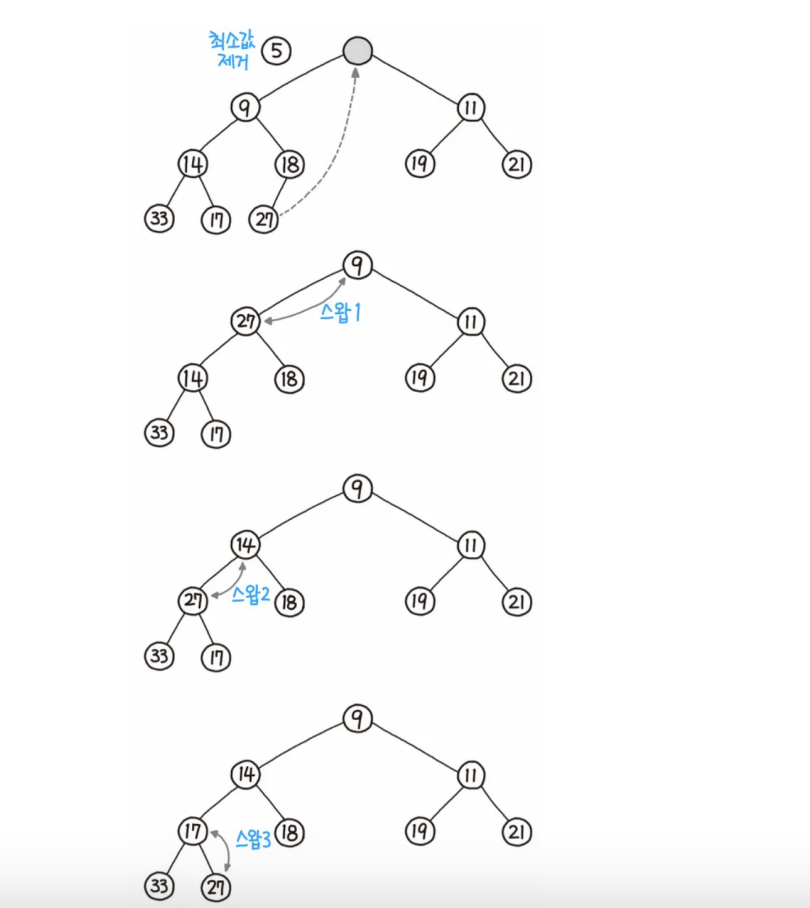
- 🗒️ 예시 :
📕
1.
📖 참고 📖
- ✏️

Notion으로 이동 (https://24tngus.notion.site/3a6883f0f47041fe8045ef330a147da3?v=973a0b5ec78a4462bac8010e3b4cd5c0&pvs=4)