통계학 맛보기
이번 강에서는 통계학에 대하여 학습을 진행했다. 기계학습과 통계학이 공통적으로 추구하는 목표가 바로 통계적 모델링인데, 통계적 모델링이란 적절한 가정 위에서 확률분포를 추정하는 것이다. 따라서 머신러닝을 이해하기 위해서는 머신러닝과 공통의 목표를 추구하는 통계학에 대한 기초를 다지는 것은 필수이다. 이번 강의를 통해서 통계학에 대한 기초를 완벽히 다지기 위해 노력했다.
00. 공부 내용
- 모수에 대하여 공부
- 최대가능도추정법(Maximum Likelihood Estimation, MLE)에 대하여 공부
- 콜백-라이블러 발산(KL Divergence)에 대하여 공부
01. 모수
- 기계학습과 통계학은 공통적으로 적절한 가정 위에서 확률분포를 추정하는 것을 목표로 한다.
- 그런데 유한한 개수의 데이터만 관찰해서는 모집단의 분포(모수)를 정확하게 알아내는 것은 불가능하므로, 근사적으로 확률분포를 추정(표본을 바탕으로)할 수 밖에 없다. (따라서 우리가 만드는 예측모형의 목적은 데이터와 추정 방법의 불확실성을 고려하여 위험을 최소화 하는 것이라고 볼 수 있다.)
- 확률분포를 추정하는 방법은 크게 모수적(parametric) 방법론과 비모수적(nonparametric) 방법론으로 나뉘어진다.(기계학습의 많은 방법론은 비모수적 방법론에 속함)
- 모수적 방법론이란 데이터가 '특정 확률분포를 따른다고' 선험적으로(a priori) 가정한 후 그 분포를 결정하는 모수를 추정하는 방법이다.
- 비모수적 방법론이란 '특정 확률분포를 가정하지 않고' 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌는 방법이다.
- 대표적으로 우리가 알고 있는 모수 추정 방법론은 바로 표본평균과, 표본분산 공식을 활용하는 방법이다. 본 공식은 정규분포를 가정하기 때문에 모수적 방법론 중에 하나라고 볼 수 있다.

02. Maximum Likelihood Estimation
- MLE, 즉 최대가능도추정법은 이론적으로 가장 가능성이 높은 모수를 추정한는 방법 중 하나이다. (특정 확률분포를 가정하지 않아, 다양한 확률분포에 사용할 수 있는 방법임)

- MLE는 위 식과 같이 특정 파라미터 세타를 따르는 분포가 주어졌을 때 X를 관찰할 수 있는 최대 가능도를 추정하는 방법이다.
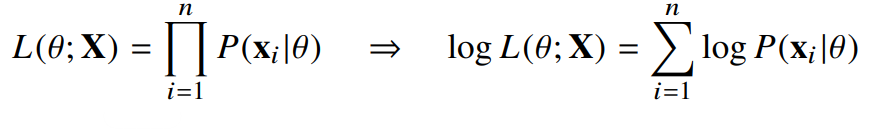
- 대부분의 MLE는 위와 같이 log를 취해 로그 가능도를 추정하는 방법으로 최적화가 이루어진다.
- 로그가능도를 사용하면 다음과 같은 장점을 얻을 수 있다.
- 만일 데이터의 숫자가 수억 단위가 된다면 곱셈인 가능도 식의 경우 그 값이 너무 커져 컴퓨터의 정확도로는 가능도를 계산하는 것이 어렵게 된다.
- 로그를 취하면 곱셉 연산이 덧셈으로 바뀌어 아무리 많은 데이터라도 컴퓨터로 가능도를 계산할 수 있게 된다.
- 로그 가능도를 사용하면 연산량이 O(n)으로 줄어드게 된다.
- 대게 손실함수의 걍우 경사하강법을 사용하기 때문에 negarive log-likelihood를 최적화 하게 된다.(argmax에 -를 붙여서 최저점이 곧 최고점을 갖게 되는 것)
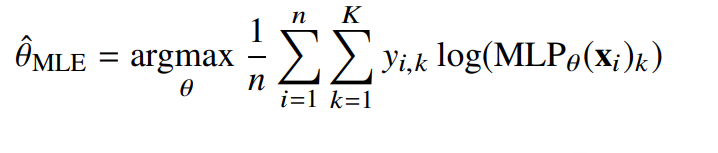
- 딥러닝에서는 위와 같은 log-likelihood 식을 활용하여 모델을 학습시킨다.
- 흔히 확률과 가능도를 비슷하게 생각하는 경우가 있는데, 확률과 가능도 엄연히 다르다고 할 수 있다. 확률이란 모집단을 바탕으로 특정 사건이 발생할 확률이기 때문에 값이 바뀌지 않는다고 볼 수 있다. 하지만 가능도는 특정 파라미터를 바탕으로 추정하는 것이기 때문에 데이터가 달라진다면 가능도 역시 달라질 수 있다. 따라서 간단하게 정리하면 확률은 모집단으로 추정된 변하지 않는 특정 사건이 발생할 가능성이고, 가능도는 표본으로 부터 추정된 변할 수 있는 특정 사건이 발생할 가능성이라고 볼 수 있다.
03. Kullback-Leibler Divergence
- KL Divergence은 두 개의 확률분포 P(X), Q(X)가 있을 때 두 확률분포 사이의 거리를 계산할 때 사용되는 함수이다.
- 기계학습에서 사용되는 손실함수들은 모델이 학습하는 확률분포와 데이터에서 관찰되는 확률분포의 거리를 통해 유도된다.

- KL Divergence가 각 확률변수에 따라서 위와 같이 정의될 때, KL Divergence는 아래와 같이 분해될 수 있다.

- 즉 위 식은, 분류문제에서 정답레이블 P, 모델 예측을 Q라 두면 MLE은 KL Divergence을 최소화하는 것과 동일하게 된다.
참고자료

Machine Learning Engineer at Konan Technology