Level1 P-Stage 이미지 분류 대회 회고
드디어 Level1 P-Stage 이미지 분류 대회가 끝났다. 대회 기간 동안 계속 모델을 돌리느라 너무 바빠서 글을 작성하지 못했지만, 이제는 대회도 끝났고 대회를 진행하면서 많은 아쉬움이 남아 대회에 대한 회고글을 작성하려고 한다. 글은 프로젝트 요약, 대회를 진행하면서 배운 내용 순으로 정리해볼 예정이다.
1. 프로젝트 소개

-
본 프로젝트는 위 그림 처럼 한 사람의 이미지가 주어졌을 때 해당 사람의 마스크 착용 여부(올바른 착용, 잘못된 착용, 미착용), 나이(청년층, 중년층, 노년층), 성별(남, 여)을 예측하는 최적의 모델을 만드는 것이다.
-
본 프로젝트는 총 18개의 클래스를 제대로 맞추는 것이 목표이며, 18개의 클래스는 세부적으로 3개의 클래스로 이루어진 마스크 착용 여부, 2개의 클래스로 이루어진 성별, 3개의 클래스로 이루어진 나이의 조합으로 구성된다.
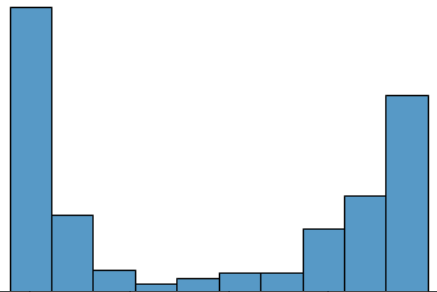
- 본 대회에 주어진 데이터의 분포를 보면 대부분의 클래스가 모두 불균형했으며, 위 그림은 본 프로젝트에서 제일 중요한 클래스인 나이의 분포이다. 그림을 통해 알 수 있듯이 주어진 데이터의 나이 분포는 매우 불균형하다는 것을 알 수 있다. 실제로 사람의 눈으로도 해당 사람의 나이를 구분하기 어려울 정도였으며, 나이를 제대로 맞추는 것이 이번 대회의 핵심이라고 할 수 있었다.
2. 프로젝트 수행 절차
- 클래스 불균형 문제에 대한 실험
- sklearn의 StratifiedKFold를 활용하여 모든 데이터의 클래스가 균일 하도록 K-fold Set을 설정함
- Model 학습시 StratifiedSampler을 사용하여 Batch 단위에 모든 데이터의 클래스가 균일하도록 설정함
- 클래스의 분포에 대한 영향력을 줄이기 위해서 OverSampling, DownSampling 등을 실험함
- 클래스의 분포를 고려하여 Model을 학습시키기 위해서 Weighted Cross Entropy Loss, Focal Loss 등을 실험함
- 대회 평가 메트릭에 대한 실험
- F1-Score의 경우 전체 클래스를 균일하게 맞추는 것이 더 좋다고 판단하여 Label Smoothing, Focal Loss, F1 Loss 등을 실험함
- 특징이 다른 여러 Model을 Ensemble하여 전체 클래스를 균일하게 맞출 수 있도록 실험함
- 데이터의 변형 및 증강 기법에 대한 실험
- 얼굴을 조금 더 잘 인식할 수 있도록 이미지에 얼굴 부분만을 남기고 나머지 부분은 자르는 FaceCrop을 실험함
- 옷의 색깔, 피부색 등 색상에 대한 영향력을 제거히기 의해서 이미지에 색상을 모두 회색으로 바꾸는 GrayScale을 실험함
- 주름 등 나이에 대한 영향력을 주는 요인을 조금 더 잘 파악할 수 있도록 이미지의 해상도를 높이는 Contrast Limited Adaptive Histogram Equalization(CLAHE)을 실험함
- 새로운 이미지에 대한 데이터를 생성하기 위해서 3명의 사람에 대한 이미지의 평균 값을 이용하여 이미지를 생성하는 MixUp 기법에 대하여 실험함
- 이외에도 ColorJitter, GaussianBlur, RandomRotation, RandomHorizontalFlip 등 다양한 이미지 변형 기법을 실험함
- 다양한 모델 알고리즘에 대한 실험
- CNN 기반에 모델의 성능 평가를 진행함(RegNet, ResNet, EfficientNet 등)
- Transformer 기반에 모델의 성능 평가를 진행함(Vision Transformer 등)
- Multi Sample Dropout을 활용한 모델의 성능 평가를 진행함
- 모델 학습에 대한 실험
- 대회 초반
- 모델의 Learning Rate를 0.01, 0.001 등 크게 잡아 학습 시킴
- 모델의 loss 값이 빠르게 0에 수렴하고, 추후에 오버슛팅이 발생된다는 것을 확인함
- 이를 통해서 현재 데이터의 목적 함수는 매우 non-convex 하다는 것과, 현재 주어진 이미지의 경우 모델이 학습하기에 매우 복잡하지 않은 구조라는 것을 알게됨
- 즉 모델이 빠르게 Local Minimum에 수렴하여 괴적합이 되는 문제가 발생함.
- 따라서 Learning Rate와 Batch Size를 작게 설정히여 모델을 학습함
- 대회 후반
- 모델 학습 시 train loss는 계속 감소하지만, val loss는 계속하여 증가한다는 문제점을 발견함
- 이에 모델의 optimizer를 Adam이 아닌 AdamW, RAdam 등으로 변경함
- optimizer의 변경을 통해서 모델의 학습 속도와 과적합을 줄여, train loss와 val loss 사이의 차이를 줄임
- 대회 초반
- Mask / Gender / Age 분류에 대한 실험
- 모델이 Mask와 Gender에 대한 분류는 잘 하고 있지만, 모델 예측에 대부분의 오류가 Age에서 발생한다는 것을 확인함
- Mask, Gender, Age 각각 분류하는 모델을 만들어 Ensemble 하는 방식을 실험을 진행
- 전체 클래스를 모두 분류 후, 추후에 Age를 다시 분류하는 모델에 대한 실험을 진행
- Mask 착용 여부, Gender로 분리된 데이터로 Age 모델을 학습 시킨 후 Mask 착용 여부, Gender를 예측 후에 Age를 분류하는 모델에 대한 실험을 진행
- 모델 성능 향상을 위한 실험
- Test Time Augmentation(TTA)를 활용하여 서로 다른 데이터 변형에 따른 결과를 앙상블함
- Stochastic Weight Averaging(SWA)를 활용하여 모델의 Weight를 동적이게 하여 모델의 표현력을 높일 수 있도록 함
- Pseudo Labeling 기법을 활용하여 모델의 결정 경계를 조금더 확실히 하고, 학습 데이터의 양을 늘릴 수 있도록 함
3. 프로젝트 수행 결과
- Age와 Gender를 같이 고려하고 Train과 Val Data에 서로 다른 사람이 존재하도록 데이터를 분리하여 모델의 일반화 성능을 높임
- 데이터 변형 기법 중 GrayScale을 사용하는 것이 노년층 분류에 있어서 가장 좋은 성능을 보임
- Loss는 Label Smoothing을 사용하였고, 본 Loss를 통해서 전체 클래스를 골고루 예측하는 모델을 얻음
- Learning Rate는 9e-05, Batch Size는 64로 설정하여 모델의 학습 속도를 조절하여, 조금 더 주어진 데이터를 학습할 수 있도록 함
- optimizer로 AdamW를 사용하여 train loss와 val loss 사이의 격차를 줄여, 모델의 일반화 성능을 높임
- 모델 자체 성능 평가 결과, RegNet 계열의 모델이 최고의 성능을 보였고, 속도와 성능 측면에서 RegNetx를 최종 모델로 선택함
- 모델의 경우 전체 Class를 분류하는 모델과 Age를 분류하는 모델을 만듬
- 전체 Class를 예측하는 모델의 예측 결과를 바탕으로 Age를 재분류하여, 조금더 Age를 잘 분류할 수 있도록 모델을 설계함
- 모델 학습의 경우 Pseudo Labeling, Test Time Augmentation을 진행하여 다양한 모델의 예측 결과를 생성하고, 이를 Hard Voting 하여 전케 Class를 골고룰 맞출 수 있는 최종 예측 결과를 얻음
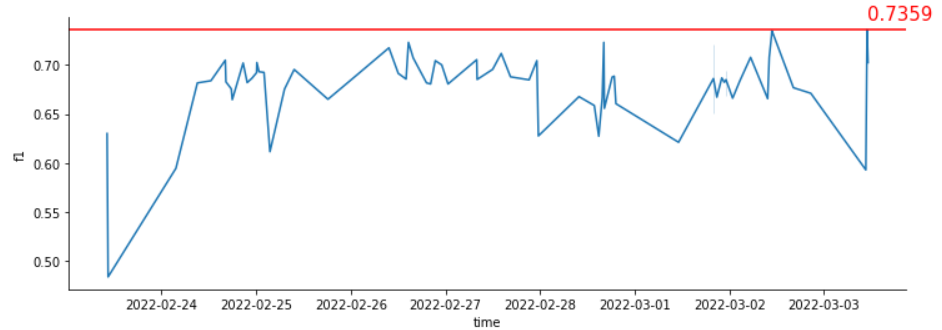
- 프로젝트를 진행하면서 다양한 실험을 진행했지만, 검증 데이터 셋에 대하여 성능이 향상되었어도, 리더보드 상에 점수는 항상 낮게 측정됐었다. 이에 모델에 성능을 올리는 것에만 급급해져 실험 일지 작성 등 가장 기본적인 것을 놓치게 되었고, 리더보드의 점수는 계속 침체기에 빠지게 되었다. 결국 이러한 악조건들이 계속 겹치면서 프로젝트에서 좋은 성적을 얻지는 못했다. 하지만 이번 대회를 통해서 잘못된 것을 많이 경험할 수 있었기 때문에, 앞으로는 똑같은 실수를 하지 않도록 할 것이고, 이제 시작이라는 마음으로 앞으로의 대회에서는 더 좋은 성적을 낼 수 있도록 최선을 다하여 공부할 것이다!
4. 새롭게 배운 내용
이번 대회를 진행하면서 배운 내용과 앞으로의 대회를 위해서 무엇을 중요하게 생각해야 할 것인가에 대해 하나 하나씩 적어볼 예정이다.
- 실험일지 작성의 중요성
- 코드의 모듈, 함수화의 중요성
- 사전 조사의 중요성
- 프로젝트 방향성의 중요성
- 모델 학습 내용 등 자료 공유의 중요성(wandb)
- 처음부터 다시 시작할 수 있는 용기의 중요성
- Train과 Test 데이터 사이에 오류가 존재할 수 있다는 것
- ImageNet DataSet pre-trained CNN Model Architecture
- imbalanced Data Split(out-of-fold)
- imbalanced Data Batch Split(Batch Data)
- FaceCrop
- MixUp
- GrayScale
- Contrast Limited Adaptive Histogram Equalization(CLAHE)
- Data Augmentation
- Test Time Augmentation(TTA)
- Stochastic Weight Averaging(SWA)
- Pseudo Labeling
- optimizer의 중요성(Adam이 만능이 아니다....)
- Ensemble의 중요성
- Learning Rate와 Batch Size의 중요성
- Loss Fuction에 대한 중요성
- ...

Machine Learning Engineer at Konan Technology