1. Project 소개
본 프로젝트는 빅데이터 연합동아리 투빅스 제 13회 데이터 분석 컨퍼런스에서 발표한 프로젝트입니다.
저는 본 프로젝트에서 데이터 전처리, 모델링, 웹 백엔드 구현을 담당했습니다.
본 프로젝트는 Kakao Arena에서 제공하는 Melon Playlist Continuation 데이터를 가지고 진행했습니다.
본 프로젝트는 사용자가 선택한 유사한 노래를 추천해주는 것을 목표로, 유사한 노래의 기준을 멜로디, 분위기, 상황, 장르 등으로 정의하였습니다.
유사한 노래라는 정의가 다양하기 때문에 이를 반영할 수 있는 다양한 Embedding을 생성하고자 Music2Vec, Time Convolutional AutoEncoder, ConsineEmbeddingLoss Multimodal 모델을 구현했습니다.
Embedding의 Cosine Similarity를 구하여 Retrieval을 구성하고, 추천 결과를 Ensembel 하기 위해서 Each Embedding Top 3, Socre Total Top 10 등의 Ranking Method를 사용했습니다.
최종적으로 Score Total Top 10 Ranking Method를 가지고 Web Page를 제작하여 추천 결과를 Serving 했습니다.
2. Project 요약
- 사용자가 선택한 노래와 유사한 노래를 추천해주는 것이 목표
- Data (Pandas, Numpy)
- Kakao Arena, Melon Playlist Continuation 데이터
- Song Meta Data (추천 노래 리스트, 7M)
- Playlist Data (상황 · 장르 등을 반영, 1M)
- Song Mel-Spectrogram (멜로디 · 분위기 등을 반영, 200GB)
- Kakao Arena, Melon Playlist Continuation 데이터
- Model (Pytorch)
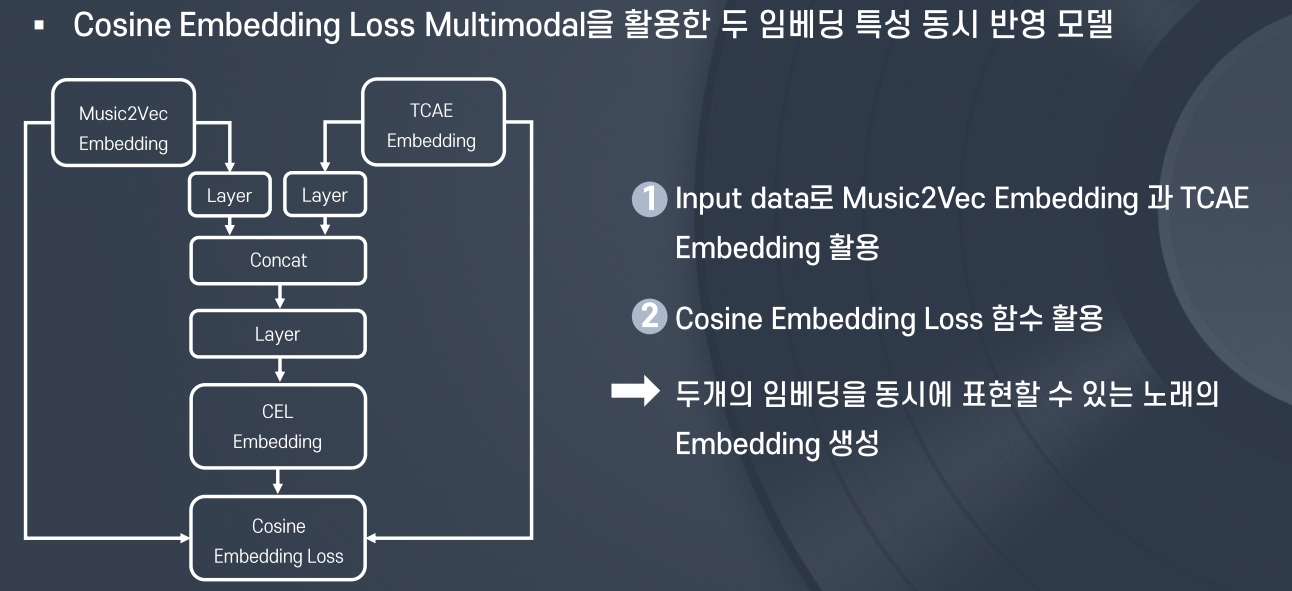
- CosineEmbeddingLoss Multimodal (CEL Multimodal)
- Music2Vec + TCAE Embedding
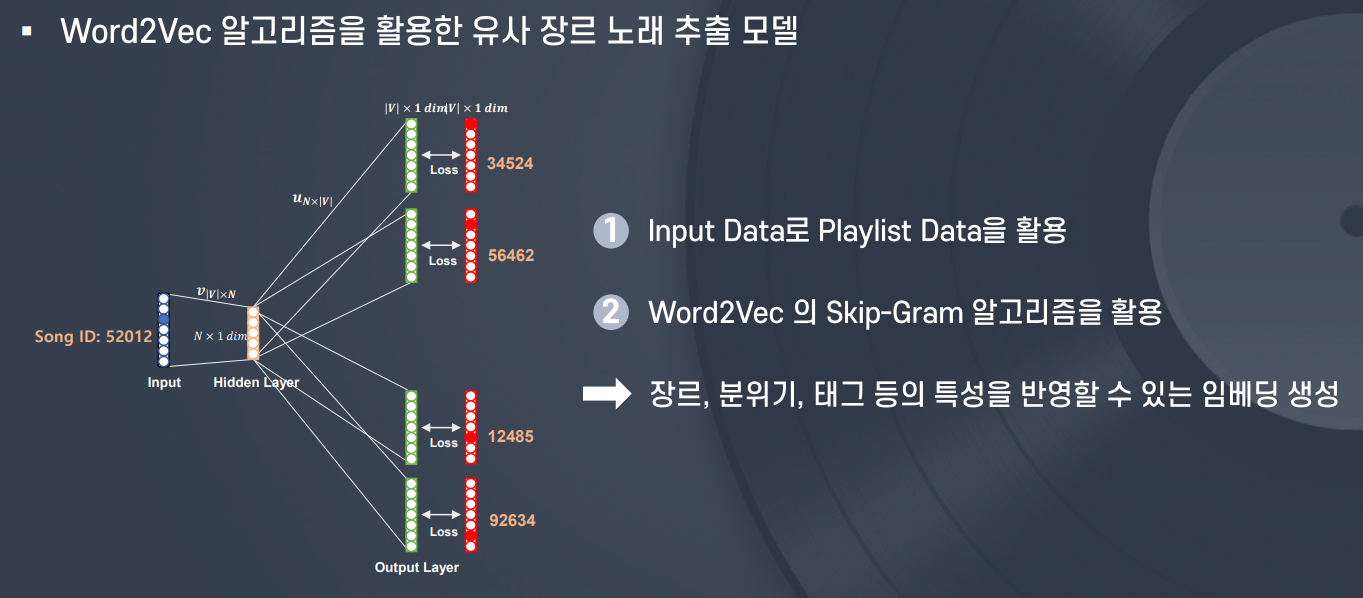
- Music2Vec
- 장르, 상황 등의 정보 반영
- Skip-gram 사용(중심 노래로 주변 노래 예측)
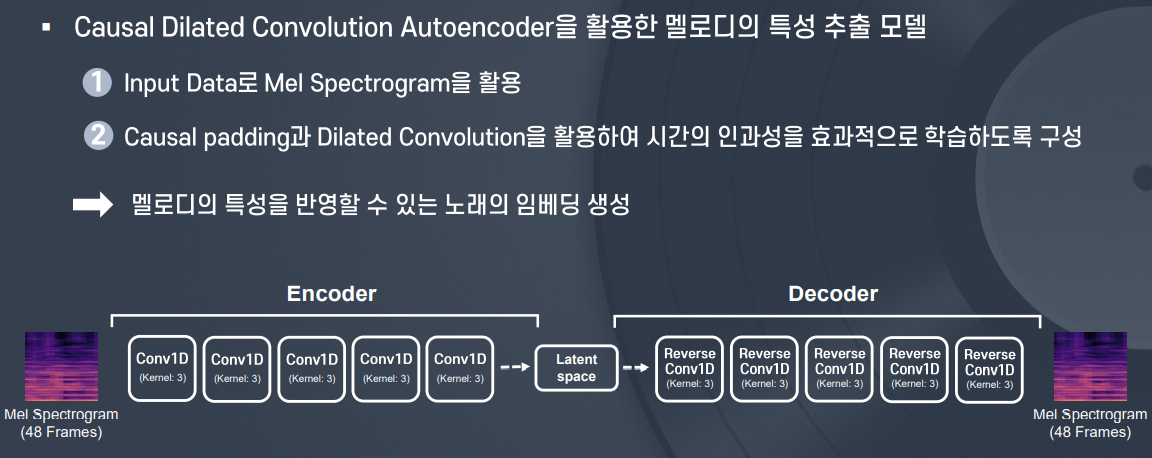
- Time Convolutional AutoEncoder (TCAE Embedding)
- 멜로디, 분위기 등의 정보 반영
- Dilated Convolution, Causal Pading 사용
- CosineEmbeddingLoss Multimodal (CEL Multimodal)
- Deploy (Flask)
- 최종적으로 Score Total Top 10 Ranking Method의 추천 결과를 저장
- Flask를 이용해 Ranking 결과 Serving
- 전체 코드 및 프로젝트 소개
- 발표 영상
- 최종 보고서
3. Project 내용
1) Motivation
- 프로젝트의 목표는 사용자가 들었던 노래와 유사한 노래를 추천해주는 것
- 유사한 노래에 대한 정의
- 유사한 멜로디의 노래
- 비슷한 분위기의 노래
- 유사한 상황에서 듣는 노래 (이별, 여행 등)
- 비슷한 장르의 노래 (힙합, 발라드 등)
→ 유사한 노래에 대한 정의가 다양하기 때문에 이에 맞는 다양한 Embedding을 생성하는 것이 주된 목표
- 단순히 유명한 노래들을 가지고 추천해주는 것보다는 고객의 입장에서 다양한 경험을 할 수 있도록 숨은 명곡과 같은 잘 알려지지 않은 노래 또한 추천할 수 있도록 결과를 구현
2) Process
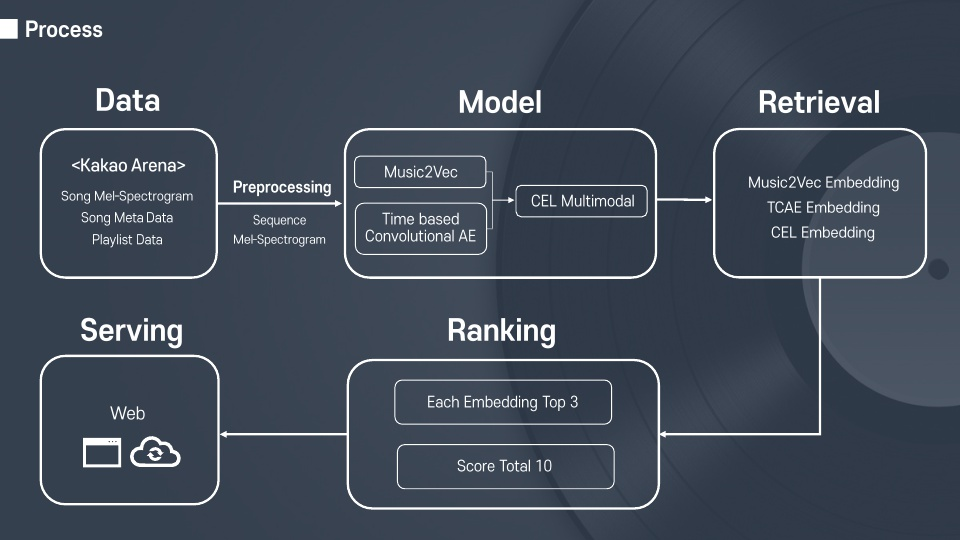
- Data
- kakao arena에 있는 Melon Playlist Continuation 데이터
- Song Meta Data (추천 노래 리스트)
- Playlist Data (상황, 장르 등을 반영)
- Song Mel-Spectrogram (멜로디, 분위기 등을 반영)
- Preprocessing
- 기본적인 노래 전처리 진행(중복, 불필요 노래 제거 등)
- Playlist Data를 가지고 Sequence Data를 생성하여 Music2Vec의 학습용 데이터로 사용
- 용량이 큰 Song Mel-Spectrogram를 효율적으로 활용하기 위하여 Batch 단위 데이터로 생성하여 TCAE의 학습용 데이터로 사용
- Model
- '유사성'의 기준을 멜로디, 분위기, 상황, 장르 등으로 정의하여 다음과 같은 모델 구현
- Music2Vec
- Time Convolutional Autoencoder
- CosineEmbeddingLoss Multimodal
- '유사성'의 기준을 멜로디, 분위기, 상황, 장르 등으로 정의하여 다음과 같은 모델 구현
- Retrieval (Embedding)
- Embedding의 Cosine Similarity를 구하여 다음과 같은 Retrieval 구성
- Music2Vec Embedding : 장르, 상황 등에 대한 정보가 반영
- TCAE Embedding : 멜로디에 대한 정보가 반영
- CEL Embedding : 두 임베딩에 대한 정보가 반영
- Embedding의 Cosine Similarity를 구하여 다음과 같은 Retrieval 구성
- Ranking (Ensemble)
- Each Embedding Top 3
- Socre Total Top 10
- Serving
- Web 제작
3) Model
(1) Music2Vec

(2) Time Convolutional Autoencoder (TCAE)

(3) CosineEmbeddingLoss Multimodal (CEL Multimodal)

4) Retrieval (Embedding)
(1) Music2Vec Embedding
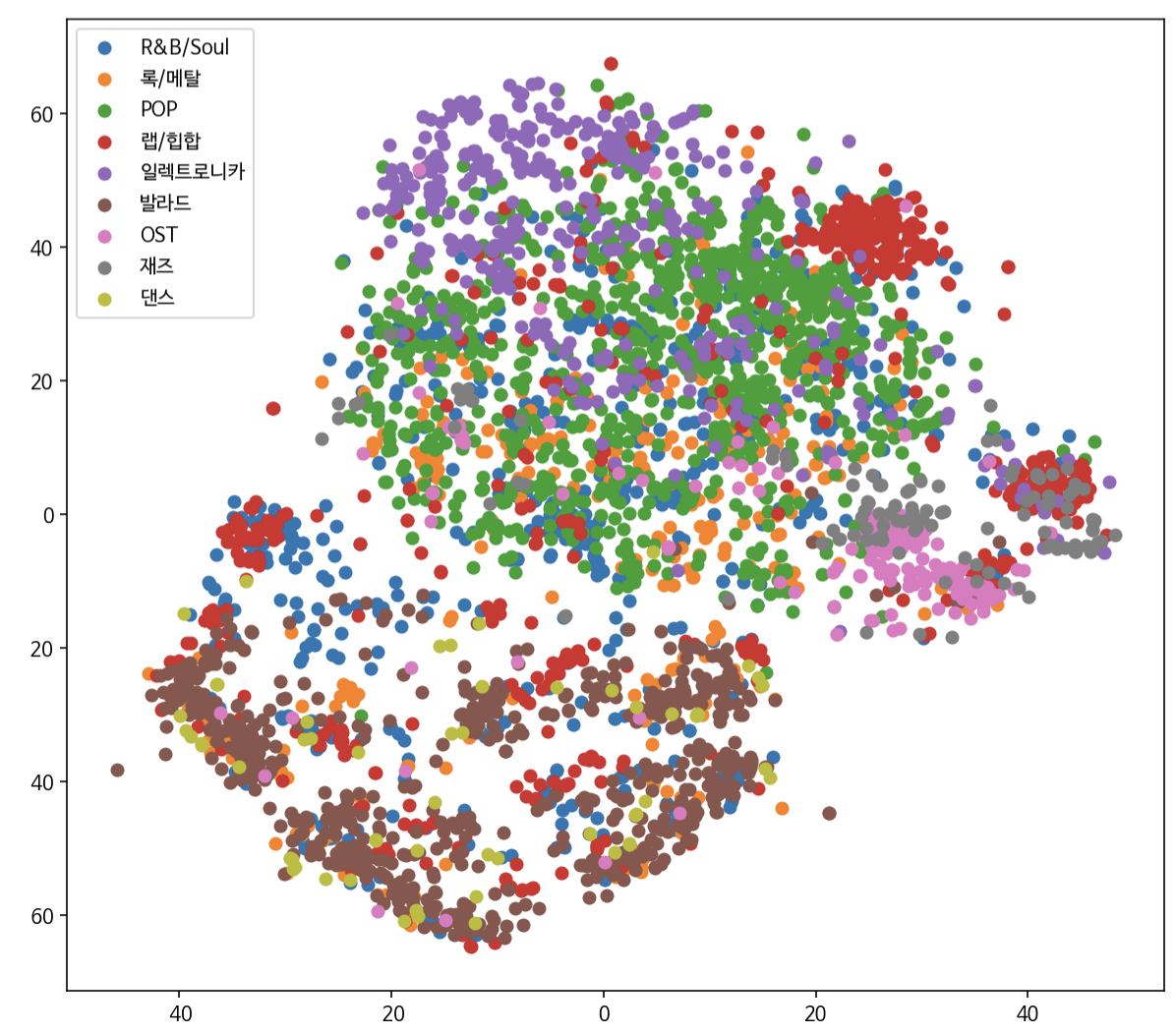
- 상황, 장르 등의 정보가 반영된 Playlist 데이터로 학습
- t-SNE 알고리즘을 활용한 2차원 시각화 결과, 임베딩에 장르라는 특성이 반영되어 있다는 것을 확인 가능(장르로 군집화됨)
- 본 임베딩 값을 가지고 노래 간의 Cosine Similarity를 계산하여 Retrieval을 구성
(2) TCAE Embedding
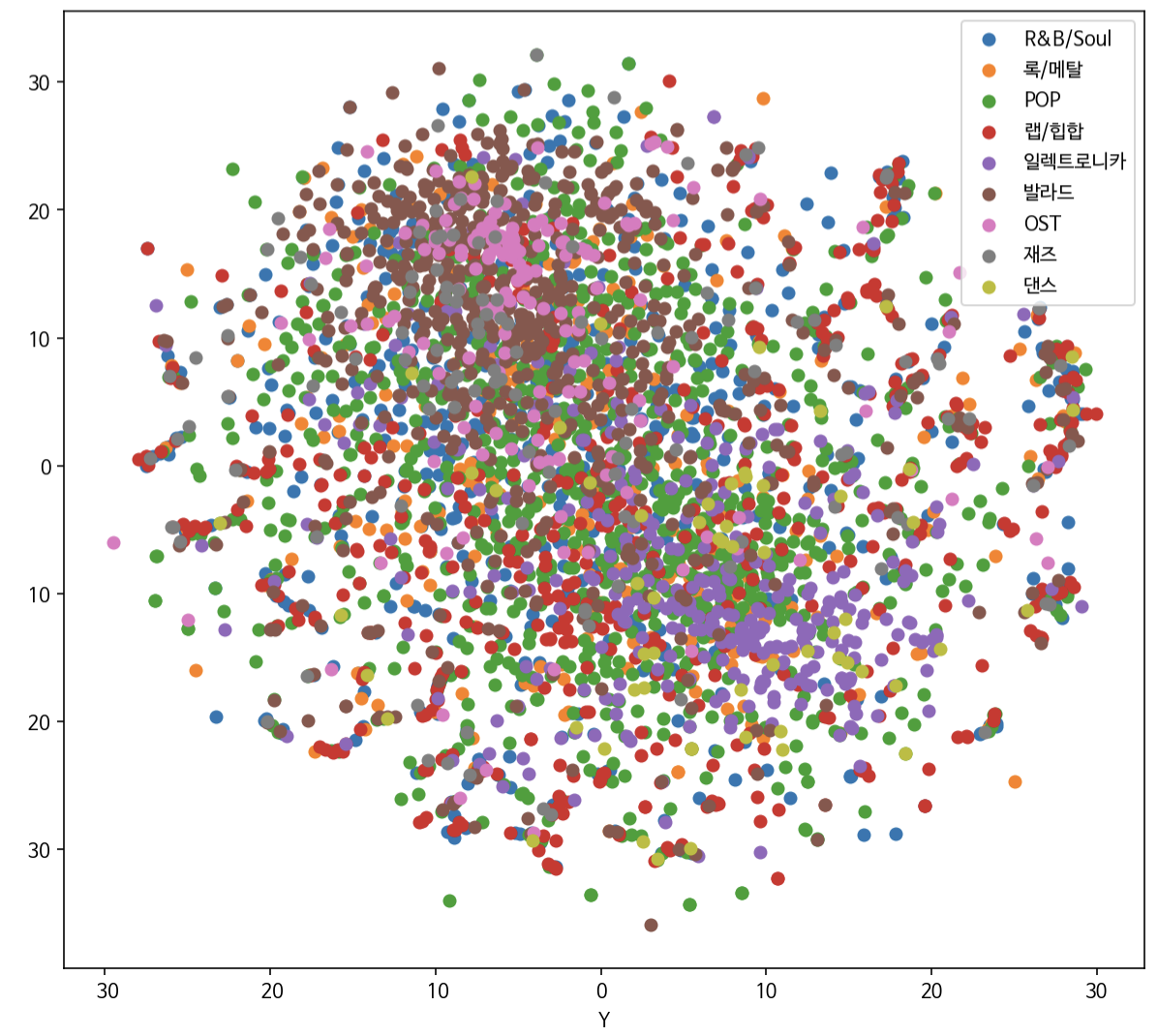
- 멜로디, 분위기 등의 정보가 반영된 Mel-Spectrogram 데이터로 학습
- t-SNE 알고리즘을 활용한 2차원 시각화 결과, 멜로디로는 장르의 특성을 반영하기 어렵다는 것을 확인할 수 있음
- 임베딩의 Cosine Similarity를 구했을 때 동일한 노래의 영어, 한국어 버전 등의 노래가 가장 유사하게 나오는 것으로 보아, 본 임베딩의 경우 멜로디의 특성이 반영되었다는 것을 확인할 수 있음
- 본 임베딩 값을 가지고 노래 간의 Cosine Similarity를 계산하여 Retrieval을 구성
(3) CEL Multimodal Embedding
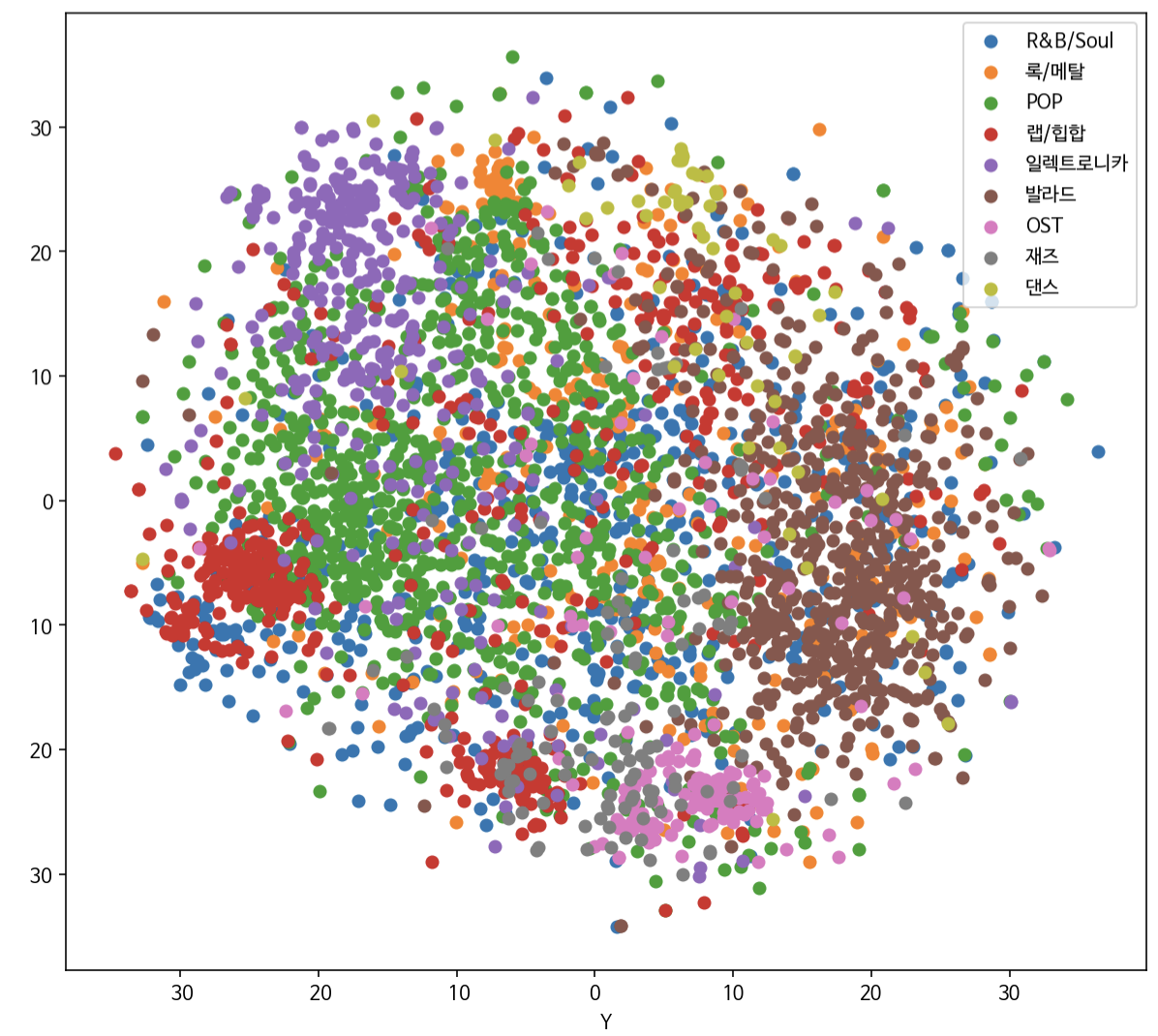
- 장르, 상황 등의 특성이 반영된 Music2Vec Embedding과 멜로디의 특성이 반영된 TCAE Embedding을 데이터로 학습
- t-SNE 알고리즘을 활용한 2차원 시각화 결과, 두 임베딩의 특징이 골고루 적용되어 있다는 것을 확인할 수 있음
- 본 임베딩 값을 가지고 노래 간의 Cosine Similarity를 계산하여 Retrieval을 구성
5) Ranking (Ensembel)
(1) Each Embedding Top 3
- 각 임베딩 모델별 상위 Top 3로 구성
- 각 임베딩의 공통된 노래가 존재하지 않아도 선택될 수 있기 때문에 각 임베딩 모델의 특징을 살릴 수 있는 노래만 선별됨
(2) Socre Total Top 10
- 각 임베딩 모델별 순위에 역수를 Score로 하여 Total Score를 구하고 상위 Top 10 노래를 선별
- 각 임베딩에 공통되게 존재하는 노래일수록 선택될 가능성이 높아지기 때문에 각 임베딩 모델의 특징을 골고루 살릴 수 있는 노래가 선별됨
6) Result
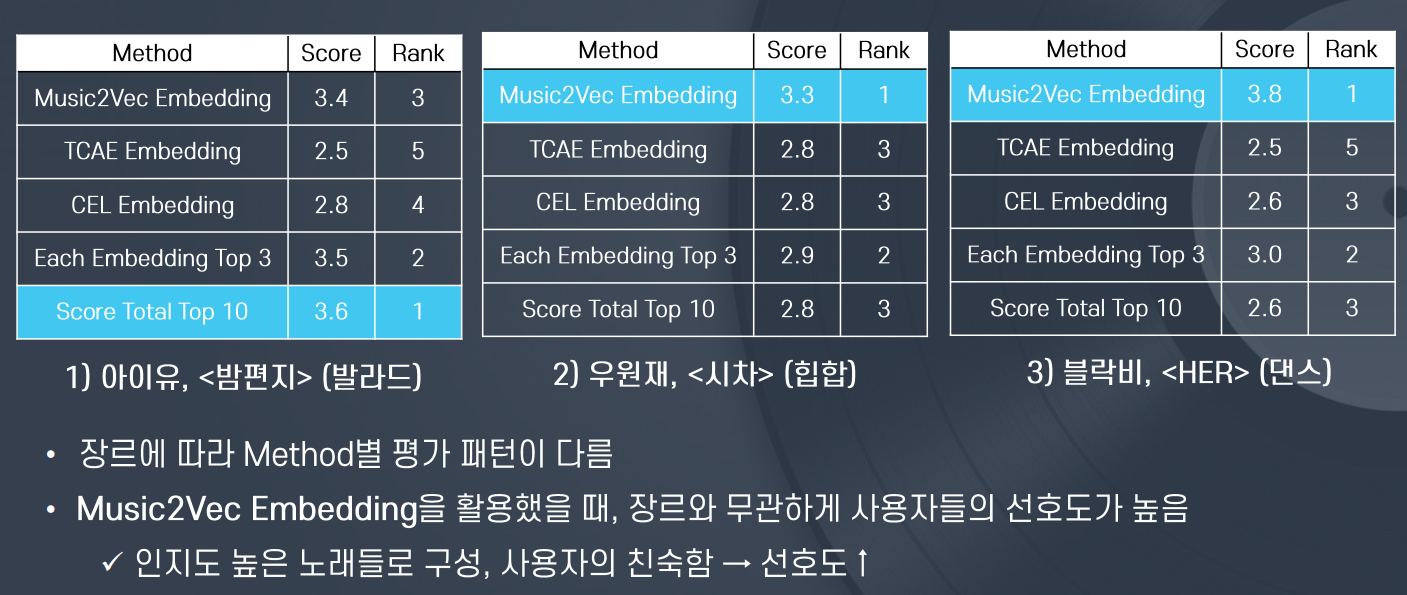
7) Web
4. 아쉬운 점
- 멜 데이터의 정보 부족
- 30초 분량의 데이터로 많은 정보를 포함하고 있지 않음
- 개인화된 정보의 부족
- 개인의 선호에 대한 정보가 존재하지 않음
- 불확실한 성능 평가 지표
- 개인마다 선호하는 기준이 다르며, 성능 평가 및 목적 함수의 모호성 존재
- 가사 데이터를 활용한 모델 성능 향상의 가능성
- 플레이리스트, 멜, 가사 등 3가지 데이터를 활용한 Multimodal로의 발전 가능성 존재
- User 정보를 활용한 모델 개발의 가능성
- item 기반이 아닌 user 기반의 데이터를 활용한 모델 개발 가능
- 두 가지 데이터를 모두 활용한 Hybrid Model 개발 가능

Machine Learning Engineer at Konan Technology