[Paper & Code Review] (2015, WWW) AutoRec: Autoencoders Meet Collaborative Filtering
RecSys Paper
목록 보기
2/9
01. Introduction
- Collaborative filtering (CF) model은 아이템에 대한 유저의 선호도(ex, 평점)를 바탕으로 개인화된 추천을 제공하는 것이 목표이다.
- 대중적으로 Matrix Factorisation, Neighbourhood model이 사용되지만, 본 논문에서는 Autoencoder에 기반한 새로운 CF model인 AutoRec을 제안한다.
- 본 논문에서 AutoRec은 최근의 CF state-of-the-art 모델들 보다 표현력, 계산상에 더 많은 이점을 가지고 성능 또한 우수한 것이 경험적으로 입증되었다고 말한다. (AutoRec은 NCF 보다 학습 속도가 빠르다는 장점이 있다고 생각함)
02. The AutoRec Model
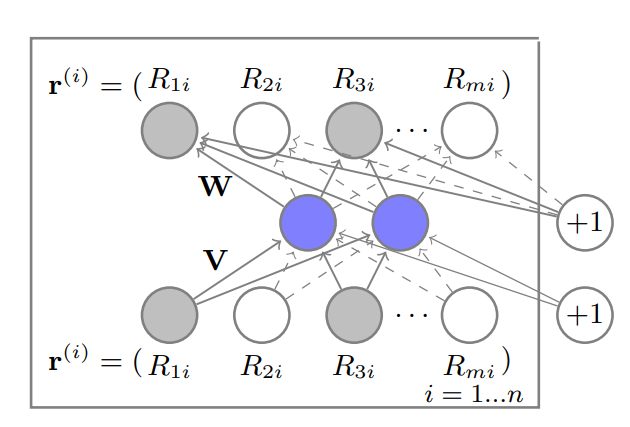
- 본 논문에서 제안한 AutoRec Model은 위처럼 Autoencoder 기반의 Model임
- 모델의 인풋으로는 관측된 유저와 아이템의 평점 행렬이 사용됨(모델에 관점으로 보면 학습시 사용되는 데이터는 아이템의 평점 벡터가 될 것임)
- 그림을 기준으로는 행이 유저고, 각 차원이 아이템에 대한 평점이 되기 때문에 item-based AutoRec model임, 물론 행렬이 반대로 구성되면 user-based가 됨. (개인적으로 이 기준은 주어진 데이터셋의 크기에 맞춰서 활용하는 것이 좋다고 생각됨, 왜나하면 차원이 너무 커지면 그 만큼 모델의 파라미터의 수도 증가하기 때문에)
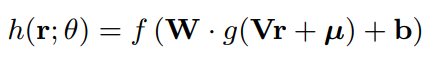
- 본 논문은 위처럼 2개 Layer를 가지고 Encoder와 Decoder를 만들었고, g에는 sigmoid를 활성화 함수로 두고, f에는 활성화 함수를 두지 않은 것이 성능이 제일 좋았다고 함.(현재 시점을 기준으로 보면 ReLU 함수 등을 활용해 조금더 모델을 깊게 쌓아도 좋다고 생각됨)
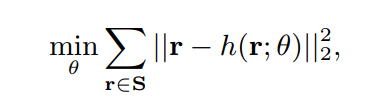
- 본 논문은 위처럼 Input 평점 행렬과 reconstruct 평점 행렬 사이에 MSE 오차를 최소화 하는 방향으로 학습이 진행됨
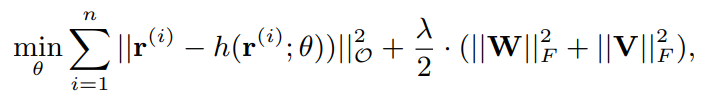
- 파라미터의 경우 관측된 행렬에 대해서만 backpropagation을 진행하여 업데이트를 진행함(Masked MSE Loss를 쓰는 것이 본 논문의 핵심이라고 생각함)
- 또한 위 식처럼 파라미터의 규제를 가하여 일반화된 모델을 얻는다고 함
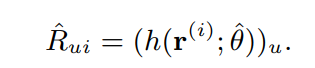
- 그리고 Decoder를 통해서 reconstruct된 평점 행렬을 가지고 아이템에 대한 추천을 한다고 함
- AE 구조상 모든 행렬에 값이 복원되어 있을 텐데 학습 시에 양의 정수만 가지고 모델을 학습시켰더라도 분명 음수가 존재할 것이라고 생각됨, 따라서 개인적으로 음수 데이터에 대해서는 어떻게 처리할지 생각해보는 것이 중요하다고 생각함
- 본 논문에서 제안된 AutoRec은 RBM-based CF 모델과 4가지 차이점이 존재한다고 함
- autoencoder 기반의 모델이라는 점
- MSE Loss를 기반으로 평점을 맞추는 방식으로 학습이 진행된다는 점
- 경사하강법 기반의 역전파를 통해서 파라미터를 더 빠르게 업데이트 한다는 점
- 더 적은양의 파라미터를 모델이 가지기 때문에 메모리가 덜 필요하고, 오버피팅에 강하다는 점
- 본 논문에서 제안된 AutoRec은 기존의 MF 모델과 2가지 차이점이 존재한다고 함
- MF는 user와 item이 latent space를 공유하지만, item-based AutoRec은 오직 item의 latent space만을 가진다.
- MF는 선형성만을 표현할 수 있지만, AutoRec은 활성화함수를 통해서 비선형성을 표현할 수 있다.(이 논문 추후에 나온 NCF는 MF에 비선형성이 추가된 방식임)
03. Experimental Evaluation
- 본 논문에서는 Data를 9:1로 나눠서 학습 및 검증을 진행했다고 한다.

- 본 논문에서는 위처럼 Item-based AutoRec이 가장 좋은 성능을 보여줬다고 말한다.
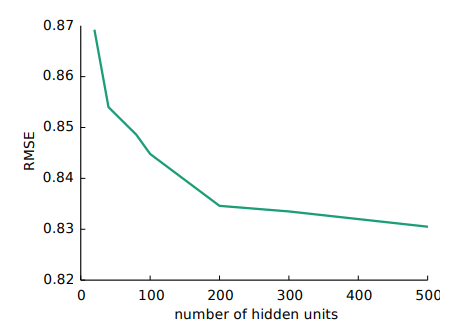
- AutoRec의 경우 위처럼 hidden unit의 수가 커질 수록 더 좋은 성능을 보여줬다고 한다.
Code
Reference

Machine Learning Engineer at Konan Technology