01. Introduction
-
collaborative filtering은 아이템과 유저의 과거 interaction 정보를 바탕으로 모델링 되어지는 개인화된 추천시스템이다.
-
대표적인 collaborative filtering 모델은 Matrix Factorization 이다. 본 모델은 유저와 아이템의 interaction을 latent vector의 inner product 으로 학습된다. 그리고 만들어진 latent space의 경우는 유저와 아이템이 모두 공유를 하게된다.
-
그런데 MF 모델의 interaction function으로 사용되는 inner product은 단순한 선형 결합이기 때문에 유저와 아이템의 복잡한 interaction 정보를 capture하는 것이 매우 어렵다.
-
그래서 본 논문은 Data로 부터 interaction function을 학습하는 neural network 기반의 collaborative filtering 모델인 Neural network based Collaborative Filtering, NCF framework를 제안한다.(Neural network 기반이기 때문에 비선형 결합이 가능하여 유저와 아이템의 복잡한 상호작용을 더 잘 capture 할 수 있음)
-
그리고 본 논문은 주로 implicit feedback에 집중한다. implicit feedback은 수집하기 쉬운 데이터이지만, 사용자 만족도가 관찰되지 않고 부정적인 피드백이 부족하기 때문에 활용하기 까다롭다고 한다. 이에 본 논문에서는 노이즈가 많은 implicit feedback Data를 모델링하는 방법을 다룬다.
02. Preliminaries
1) Learning from Implicit Data

-
implicit feedback Data는 위 그림 처럼 관측이 되면 1, 아니면 0인 행렬 형태의 데이터이다.
-
그런데 1인 경우 반드시 유저가 해당 아이템을 선호한다는 것을 의미하지 않는다. 반대로 0인 경우에도 반드시 유저가 해당 아이템을 비선호한다는 것을 의미하지 않는다. 0인 경우 단순히 유저가 해당 아이템의 존재 여부를 몰랐을 수도 있다.
-
이처럼 implicit feedback Data는 자연적인 negative feedback의 부족을 겪을 뿐 아니라, noisy signal을 제공하여 모델의 학습에 어려움을 야기한다. 따라서 implicit feedback Data에서는 negative sampling이 매우 중요함
-
본 논문에서는 implicit feedback Data의 negative feedback을 얻기 위해서 유저에게 관찰되지 않은 아이템 중 n개를 샘플링하여 negative feedback으로 활용하였다. 개인적으로 이 방법이 좋은 negative sampling 방법은 아니라고 생각하지만, 본 논문은 이 방법의 단점을 최소화 하기 위해서 NDCG@K와 Hit@k을 메트릭으로 사용한 것으로 생각됨. 왜냐하면 본 메트릭은 관찰된 아이템이 관찰되지 않은 아이템 보다 높은 순위에 존재하면 좋은 평가를 내리기 때문임
2) Matrix Factorization
- 본 장에서는 MF의 interaction function으로 사용되는 inner product의 단점에 대하여 이야기 한다.
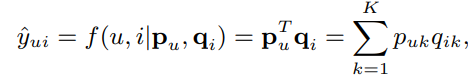
- 위와 같은 식으로 이루어진 inner product는 같은 가중치로 선형 결합이 일어나고, 각 차원의 latent vector 들은 서로 독립적이다.
-
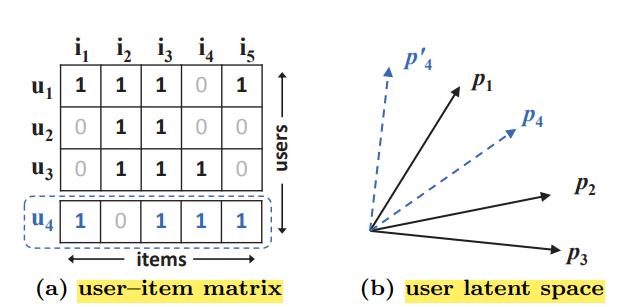
따라서 단순하고 고정적인 inner product의 방식은 유저와 아이템의 복잡한 상호작용을 제대로 캡쳐하지 못해, 위 그림처럼 a large ranking loss를 발생시킨다. (실제 u4는 u2와 가장 멀리 위치해야하는데 latent space 상에서 u3과 가장 멀리 위치하게 된)
-
위 방법을 해결하기 위해서 latent vector인 K의 차원을 늘릴 수도 있지만 이는 overfitting과 같은 문제를 야기하게 된다.
-
따라서 본 논문은 이러한 문제를 해결하기 위해서 DNN을 사용한다고 함 (진짜 이 논문은 정말 잘 쓴 논문인 것 같음.... 문제 정의와 해결 방법에 대한 빌드업이 대단함)
03. Neural Collaborative Filtering
1) General Framework
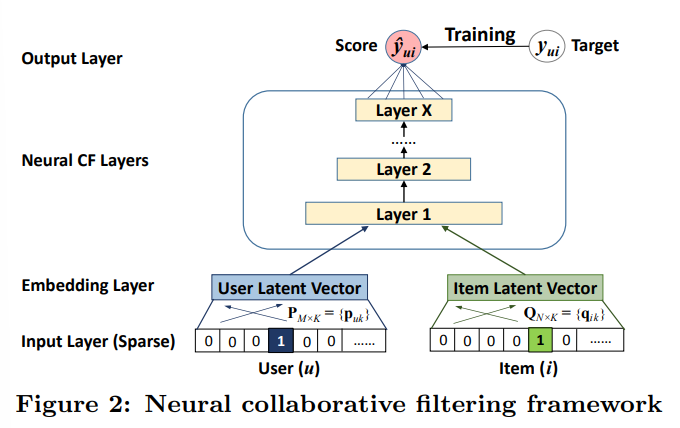
-
Neural Collaborative Filtering의 일반적인 구조는 위 그림과 같으며, 이제 Neural CF Layers를 어떻게 구성하느냐에 따라서 GMF, MLP, GMF와 MLP를 퓨전한 NueMF로 나뉘어짐
-
input data가 Neural CF Layers를 통과하면서 interaction function이 만들어진다고 보면됨
-
그리고 본 논문에서는 관측된 유저와 아이템의 Embedding만 쓸 수 있기 때문에 cold-start problem을 해결하기 위해서 Embedding Layer 대신 유저와 아이템을 표현하는 content feature를 사용할 수 있다고 함
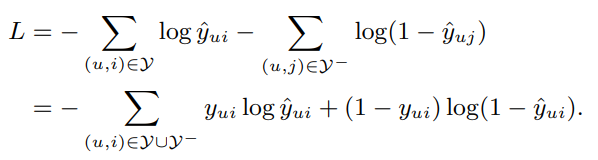
- 그리고 본 모델은 아웃풋으로 유저가 해당 아이템과 상호작용 할 확률 값으로 사용하기 때문에 위 그림처럼 Loss로 binary cross-entropy loss를 사용함
2) Generalized Matrix Factorization (GMF)
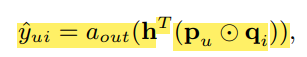
-
GMF는 위처럼 Neural CF Layer는 user embedding과 item embedding의 내적이고, Output Layer는 W와 activation function으로 이루어졌다.
-
그냥 단순히 내적의 차원을 1차원으로 바꿔주는 하나의 선형 레이어를 지나서 활성화 함수를 거치는 구조라고 생각하면 된다. Output Layer의 활성화 함수는 Sigmoid를 사용한다.
3) Multi-Layer Perceptron (MLP)
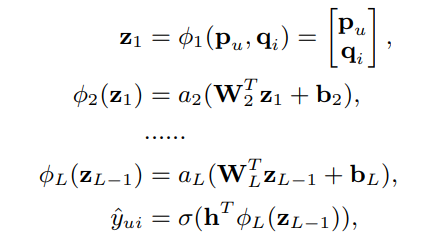
-
MLP는 위처럼 Embedding을 서로 내적이 아닌 concat하여 사용하고, Neural CF Layer는 bias가 포함된 MLP 구조로 이루어지고, Output Layer는 W와 activation function으로 이루어졌다.
-
본 논문에서는 Embedding의 concat이 유저와 아이템의 상호작용을 의미하지 않기 때문에, 상호 작용을 표현하기 위해서 MLP 구조를 거쳤다고 함
-
그리고 MLP의 활성화 함수로는 ReLU를 사용했고, 다른 활성화 함수 보다 덜 overfitting 되는 경향을 보여줬다 하고, Output Layer의 활성화 함수는 Sigmoid를 사용했다 함
4) Fusion of GMF and MLP
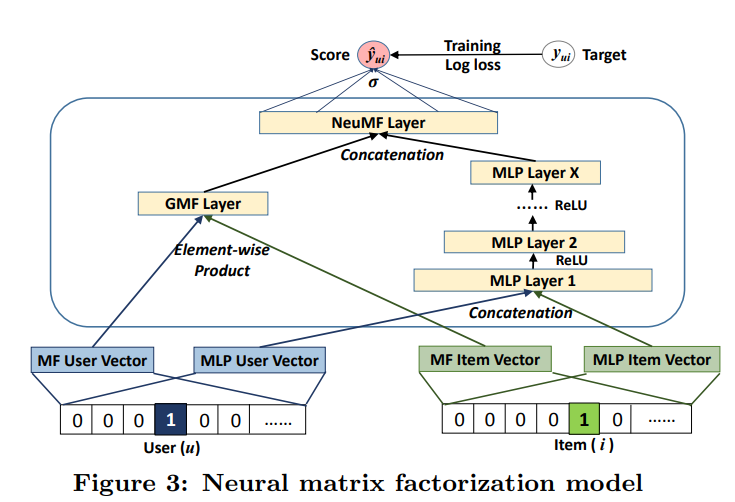
-
GMF는 유저와 아이템의 상호 작용에 선형성을 표현하고, MLP는 비선형성을 표현한다. NeuMF는 위 그림처럼 GMF와 MLP의 퓨전하여 두 모델의 장점을 모두 표현함
-
NeuMF는 GMF와 MLP의 임베딩을 서로 분리하여 학습함으로써 모델의 확장성을 높이고, 조금 더 최적화되게 모델을 앙상블함
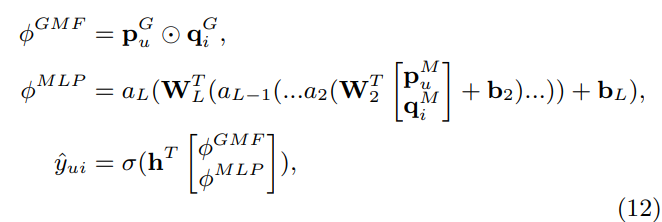
-
위처럼 각 GMF와 MLP의 아웃풋은 서로 concat 되고, Output Layer를 거쳐서 NeuMF의 최종 아웃풋이 결정됨
-
NeuMF의 objective function은 non-convexity하기 때문에 gradient-based optimization을 사용하게 되면 locally-optimal solution에만 도달하게 된다. 이에 NeuMF에 초깃값으로 pre-trained 된 GMF와 MLP의 파라미터 값을 사용하라고 한다. (즉, NeuMF를 사용하기 위해서는 먼저 GMF와 MLP를 학습시켜야 함)
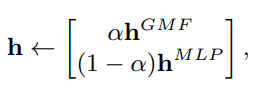
-
그리고 위처럼 GMF와 MLP의 concat 비율도 하이퍼 파라미터로써 우리가 직접 결정할 수 있다고 함
-
GMF와 MLP의 학습 시에는 optimizer로 Adam을 사용하였지만, NeuMF는 Adam이 아닌 SGD를 사용함
-
왜냐하면 Adam의 경우 초기의 momentum information 정보가 필요한데, NeuMF는 초깃값으로 사전 훈련된 GMF와 MLP의 파라미터를 사용했기 때문에 초기의 momentum information 정보를 버린 것이나 마찬가지기 때문임. 따라서 NeuMF는 momentum 기반의 optimizer는 사용할 수 없음. 실제로 직접 내가 실험한 결과도 Adam 보다 SGD가 더 좋은 성능을 보여줌
04. Experiments
1) Experimental Settings
- 본 논문은 모델을 성능을 평가하기 위해서 데이터 셋으로는 MovieLens와 Pinterest를 사용했다고 함
- 모델의 평가 메트릭은 Hit Ratio (HR)과 Normalized Discounted Cumulative Gain (NDCG)를 사용함
- GMF와 MLP의 초기 임베딩은 평균이 0이고, 표준편차가 0.01인 가우시안 분포에서 랜덤으로 설정함
- NeuMF에 알파 값은 0.5로 설정함(GMF와 MLP의 앙상블 비율)
2) Performance Comparison (RQ1)
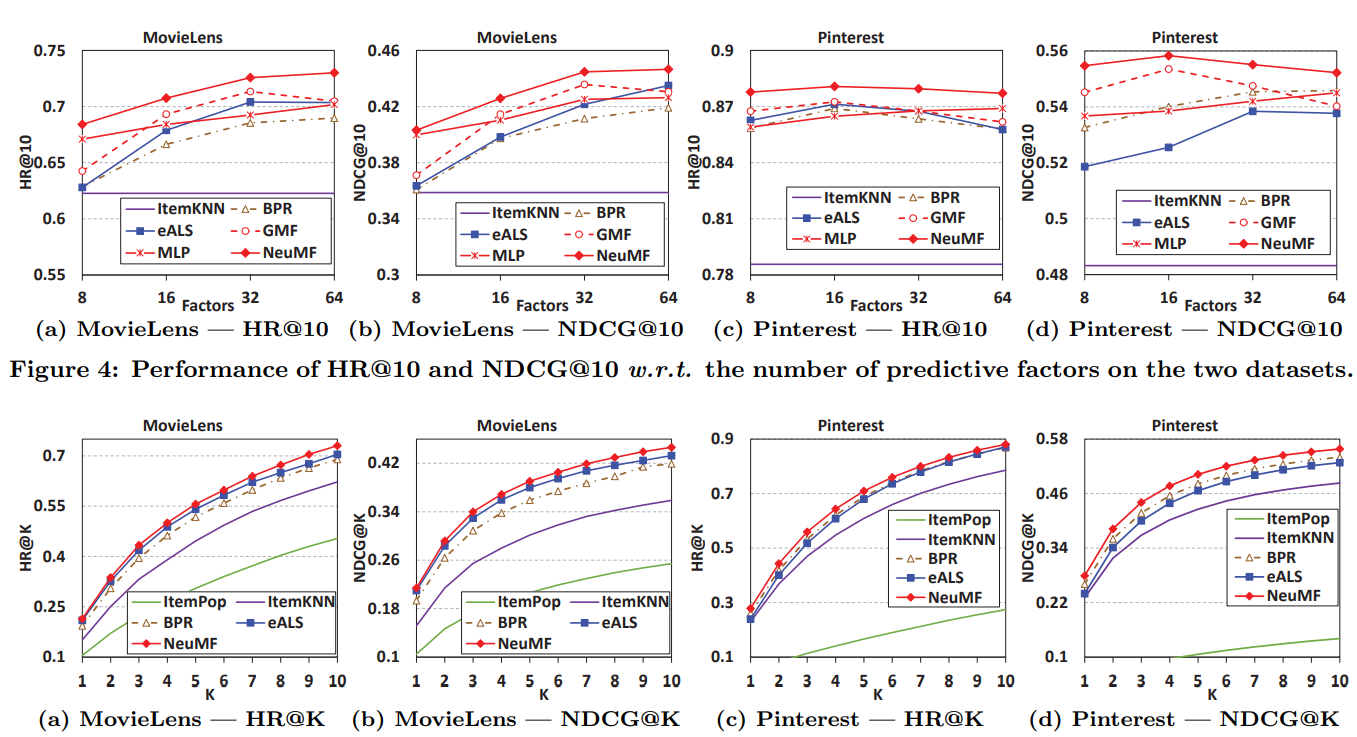
- NeuMF는 SOTA 모델의 성능을 능가함
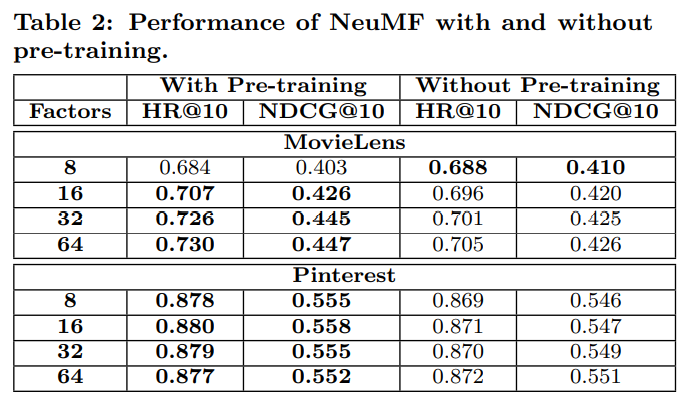
- pre-trained 된 GMF와 MLP의 파라미터 값을 사용하는 것이 제일 성능이 좋음
3) Log Loss with Negative Sampling (RQ2)
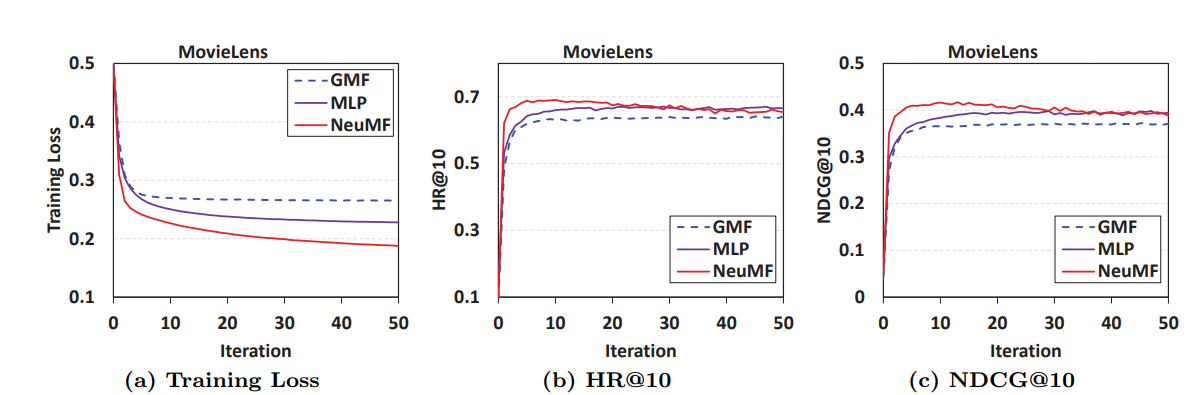
- NeuMF는 학습 횟수가 많아짐에 따라 과적합이 발생되는 경향을 보임
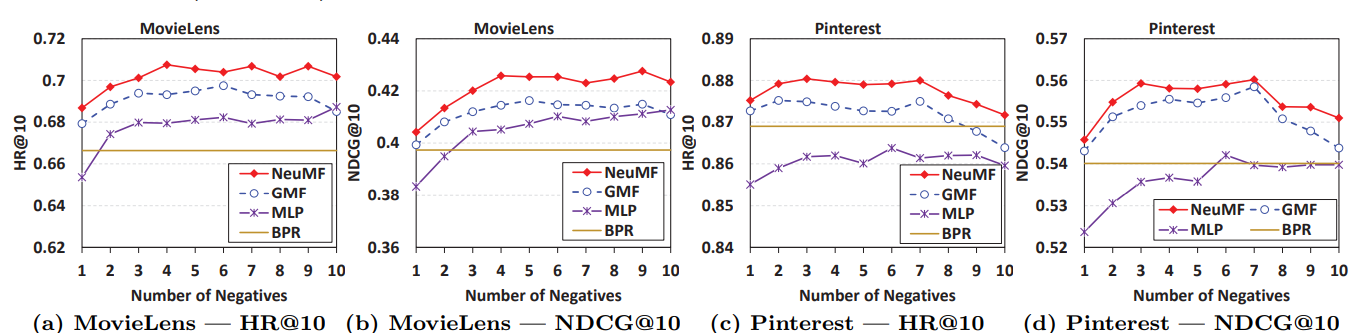
- Negative Sampling 비율은 3 ~ 6 이 적당함
4) Is Deep Learning Helpful? (RQ3)
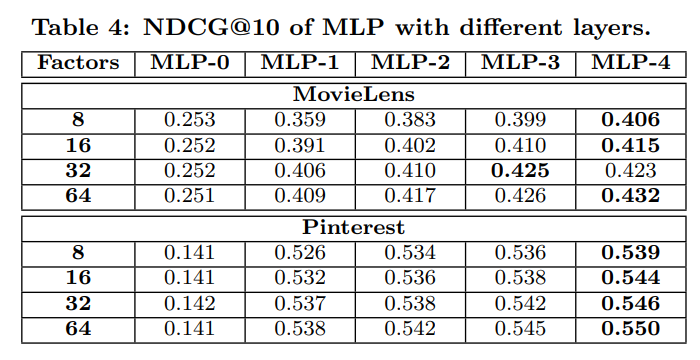
- MLP의 경우 모델의 깊이가 더 깊어질 수록 더 좋은 성능을 보여줬다 함 (개인적으로 너무 깊으면 오버피팅이 발생할 수 있기 때문에 너무 깊게 쌓으면 안된다고 생각함)
Code
Reference
