[Paper & Code Review] (2018, KDD) Graph Convolutional Neural Networks for Web-Scale Recommender Systems
RecSys Paper
목록 보기
9/9
솔직히 바로 이전에 다룬 GraphSAGE와 매우 비슷한 구조를 가지고 있고, 다르다면 Loss와 이분그래프를 이용한 노드 Embedding, 중요도를 이용한 Random Sampling, 중요도를 활용한 Agreegate 정도라고 생각됨
INTRODUCTION
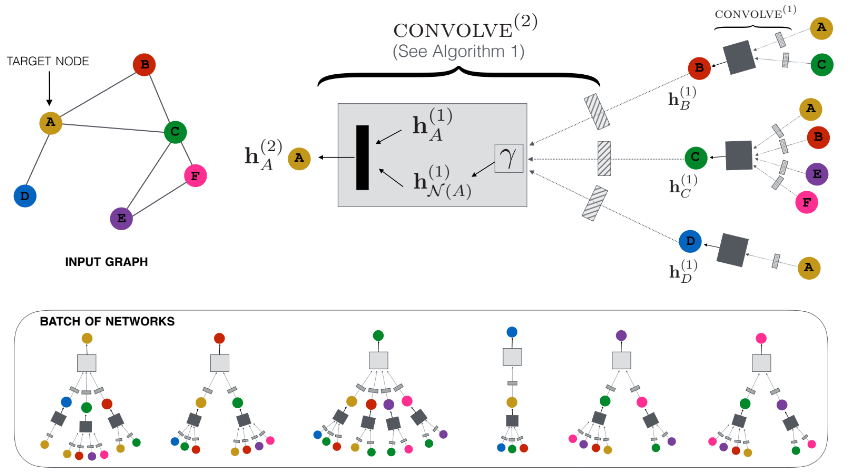
- 본 논문은 Pinterest의 Contents인 pin-board를, 이분그래프로 나타내어 Pin의 Embedding을 구하는 PinSage 알고리즘에 대한 논문임
- Graph Convolutional Network의 핵심은 NN을 사용해서 주변 노드의 정보를 반복적으로 aggregate하는 것임(위 그림)
- 즉, convolution과 feature information을 aggregate하는 Layer를 여러개 쌓은 모델이 바로 Graph Convolutional Network 임
- 따라서 GCN 모델은 feature information 뿐만 아니라 Graph structure까지 포함된 Embedding을 생성할 수 있음
- 아이템 or 유저에 대한 Embedding을 구할 수 있다면 Item-to-Itme, Uset-to-Item과 같은 추천이 가능해지기 때문에 GCN은 추천시스템에서 점점 더 중요한 역할을 하고 있음
- 그런데 GCN-based recommender system은 graph의 scale에 매우 큰 영향을 받음, (billions of nodes and tens of billions of edges 같이 graph의 scale이 너무 크면 연산이 불가능할 수 있음)
- 본 논문 이전 까지 나온 GCN 모델들은 full graph Laplacian을 사용하여, 현실의 문제를 풀기에는 매우 어려움이 있음(현실의 Graph는 매우 큰 사이즈이기 때문에 계산이 불가능할 수 있음)
- 그래서 Pinterest는 이러한 문제를 Random-walk에 기반한 PinSage 알고리즘을 만들어 해결함
- PinSage는 full graph Laplacian을 사용하는 전통적인 GCN 모델과 달리, 주변 노드를 샘플링하고 샘플링된 노드를 바탕으로 계산 그래프를 생성하여 localized convolution을 진행하기 때문에 효율적이다.
- PinSage는 모델 학습에는 GPU를 사용하고, 그래프 생성과 같은 큰 메모리가 드는 작업은 CPU를 사용한다.(학습에는 한번에 많은 행렬곱 연산을 할 수 있는 GPU가 유리하고, 데이터 생성 등 많은 메모리가 필요한 작업은 CPU가 유리함, 솔직히 이 부분은 너무 당연한 이야기라서 PinSage 만의 특징이라고 말하기는 조금 그럼)
- 학습된 PinSage는 효율적인 MapReduce inference를 통해서 빠르게 embedding을 생성함
- 추가적으로 PinSage는 새로운 학습 techniques과 혁신을 통해서 representation quality를 상승시켰다고 함
- PinSage는 노드의 importance score에 기반한 편향된 random walks를 사용하여 계산 그래프를 생성하고, importance score는 pooling/aggregation step에서도 사용한다고 함
- PinSage는 학습 시에 harder-and-harder example을 사용하여 성능을 향상시킴
RELATED WORK
- PinSage는 entire graph Laplacian을 사용하는 다른 알고리즘들과 달리 random walk로 노드를 샘플링하여 사용하는 GraphSAGE와 매우 유사하며, GraphSAGE에 새로움을 조금 추가한 방식이라고 함(편향된 Random-walk, importance score, MapReduce inference 등)
METHOD
- PinSage는 localized graph convolutions을 사용하고, local graph의 neighborhood 노드의 feature information을 aggregate하여 노드의 embedding을 생성하고, 각 레이어 마다의 파라미터는 서로 공유하고(이러니깐 합성곱), 그래프의 사이즈에 독립적인 파라미터 수를 가짐(feature information을 사용하니깐, feature information의 크기에 종속적임)
1) Problem Setup
- Pinterest의 graph는 2 billion pins, 1 billion boards, and over 18 billion edges로 구성됨
- Pinterest는 추천에 사용하기 위해 high-quality Pin embedding을 생성하는 것이 목표힘
- Pinterest는 I(Pin의 집합) - C(Board의 집합) 로 구성된 이분그래프로 그래프를 표현함
- Pin과 Board의 feature information은 이미지, 글 등 다양한 metadata가 사용될 수 있음
- PinSage로 생성한 Embedding은 Ranking Model의 input으로 사용하여 Candidate 내에서 순위를 정하는데 활용할 수도 았음
2) Model Architecture
(1) Forward propagation algorithm
- 먼저 처음에 정의한 node features를(이미지, 글 등 다양한 metadata로 구해진 feature) 모델의 처음 input으로 사용함

- 위와 같이 transform and aggregate features를 이용하여 노드의 Embedding을 계산함 (위 그림은 제일 위에 그림에 convolve에 해당함)
- 위에서 z_u는 transform을 통해서 표현된 Embedding을 의미, 람다는 aggregator/pooling fuction을 의미(element-wise mean or weighted sum 등)
- 이 부분에서 GraphSAGE와의 차이는 ggregator/pooling fuction에 set of neighbor weights가 들어간 것 말고는 없는 것 같음
(2) Importance-based neighborhoods
- random walk을 이용하여 Node들의 Visit count를 구하고, Visit count에 상위 노드를 neighborhood node로 정의하였고, Visit count를 L1 정규화를 하여 set of neighbor weights로 사용했다고 함(이걸 논문에서는 importance pooling이라 부름)
(3) Stacking convolutions

- Forward propagation algorithm에 있는 convolution을 여러개 쌓아서 모델을 만듬
- layer 1개의 학습 파라미터는 Q, q, W, w 이며, 이러한 따라서 전체 학습 파라미터의 개수는 4 * K 라고 할 수 있음(여기서 K는 convolution layer의 개수, 여기 까지는 GraphSAGE와 동일)
- 그런데 마지막에 Layer로 구해진 임베딩에 final dense neural network layer로 G1, G2, and g를 거침
- 따라서 전체 학습 파라미터는 4(Q, q, W, w) * K + 3(G1, G2, g) 개 라고 할 수 있음
3) Model Training
(1) Loss function
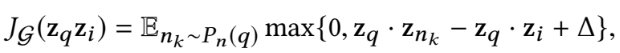
- PinSage는 위와 같은 max-margin ranking loss를 사용하여 학습이 이루어짐(논문에서는 지도학습 방식이라고 하는데, 아마 그 이유가 query item이 사전에 정의되었기 때문인 것으로 생각됨)
- good recommendation candidate인 query item q와 positive examples인 i는 서로 가까워지게, negative examples인 nk는 서로 멀어지게 학습됨
- 추가로 델타는 hyper-parameter로 우리가 직접 설정해주는 것이라고 함
- 잘 보면 솔직히 이 부분도 GraphSAGE와 크게 다를 것이 없다고 생각됨
- positive examples을 Target 노드로, query item q를 positive examples을 임베딩 하기 위해 사용한 노드들로 보면, 결국 pos set을 이용하여 Embedding 된 노드들은 서로 가깝게, neg set을 이용하여 Embedding 된 노드들은 서로 멀게 학습되는 것임 (그런데 본 논문에서 query item q는 따로 또 샘플링 한 것으로 보여짐)
- 따라서 max-margin ranking loss를 사용한 것 말고는 GraphSAGE와 크게 다를 것이 없는 것 같음
(2) Multi-GPU training with large minibatches & (3) Producer-consumer minibatch construction
- 이 부분은 모델 학습에는 GPU를 사용해서 배치 사이즈를 크게하여 학습하고, 학습하는 동안 CPU로 학습 그래프를 생성한다는 이야기를 하는 부분으로, 당연한 이야기이기 때문에 생략함
(4) Sampling negative items
- 500개의 negative item을 Sampling하여 1 epoch에 모든 minibatch에 동일하게 사용함 (매우 큰 batch size로 학습하기 때문인 것으로 생각됨)

- negative item을 Sampling할 때는 위 처럼 단순히 random이 아니라 Query와 비슷하지만 다른 item으로 Sampling 해야함
- 이것을 본 논문에서는 hard negative items이라고 부르며, first epoch에서는 no hard negative item을 사용하고, 학습이 되면 될 수록 점점더 어려운 hard negative items을 Sampling하여 사용함
4) Node Embeddings via MapReduce
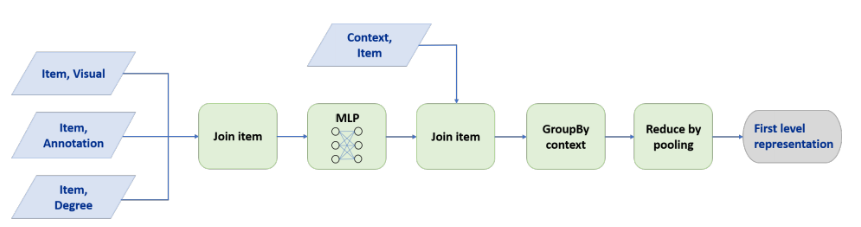
- 위와 같은 MapReduce 절차를 통하여 Node Embedding을 구했다고 함
- 그냥 다양한 정보를 가지는 Node의 Embedding을 구하기 위하여 MLP를 사용한 것으로 생각됨(이미지, 텍스트 등의 정보를 Multimodal로 사용하기 위해서 라는 느낌으로)
CONCLUSION
- PinSage는 편향된 random-walk에 기반한 graph convolutional network임
- PinSage는 확장 가능성이 매우 높은 알고리즘임 (subgraph로 모델을 학습시키기 때문에)
- importance pooling과 curriculum training으로 embedding performance를 향상 시킴
- A/B test 결과 PinSage를 활용한 추전은 매우 좋은 결과를 보여줬다고 함
Code
- https://github.com/SeongBeomLEE/RecsysTutorial/tree/main/PinSage
- 나는 본 그래프를 단순히 영화-영화 형식의 그래프로 표현했고, 물론 유저-영화 형식의 이분 그래프로 표현할 수 있음(여기에 추가로 유저의 feature도 필요함)
- 유저-영화 형식의 인접 행렬을 구한다(adj1)
- (유저의 수 + 영화의 수), (유저의 수 + 영화의 수) 크기의 값이 0으로 초기화된 인접 행렬을 구한다(adj2)
- adj2[:유저의 수][유저의 수:] = adj1로 초기화
- adj2[유저의 수:][:유저의 수] = adj1.T로 초기화
- 위의 방식으로 구해진 adj2가 곧 이분 그래프의 인접 행렬이고, 이를 활용하여 모델을 학습시킬 수 있음
- 본 논문에서는 importance pooling을 적용했다고 했지만, 나는 단순히 MeanPooling을 적용했고, 만약에 importance pooling을 적용한다면 각 노드의 importance score을 각 노드에 embedding에 추가해주면 될 것임
- 본 논문에서는 편향된 random-walk을 적용했다고 했지만, 나는 단순히 random-walk을 적용함, 만약에 편향된 random-walk을 적용하고 싶다면 각 노드의 중요도를 정의하고 그 값에 따라서 방문할 노드를 샘플링하면 됨
- 나는 학습에 pos(1개) : query(1개) : (1개)의 비율로 모델을 학습 시킴, 만약에 query나 neg의 비율을 높여서 학습한다면, loss 계산 식을 행렬곱으로 변환하면 됨
- 본 논문에서는 hard negative items을 사용했지만, 나는 단순히 유저가 시청하지않은 영화 중에 무작위로 negative item을 샘플링함(자신의 Task에 맞추어 hard negative items을 정해서 샘플링을 진행하면 될듯함)
Reference
- https://arxiv.org/abs/1806.01973
- https://velog.io/@tobigs-recsys/Graph-Convolutional-Neural-Networks-for-Web-Scale-Recommender-System
- https://greeksharifa.github.io/machine_learning/2021/02/21/Pin-Sage/
- https://medium.com/pinterest-engineering/pinsage-a-new-graph-convolutional-neural-network-for-web-scale-recommender-systems-88795a107f48
- https://yamalab.tistory.com/164?category=747907
- https://yamalab.tistory.com/159?category=948370

Machine Learning Engineer at Konan Technology