[Paper & Code Review] (2017, NIPS) Inductive Representation Learning on Large Graphs
RecSys Paper
목록 보기
8/9
본 논문은 추천 시스템 관련 논문은 아니고 GraphSAGE가 처음 제안된 논문이다. 본 논문을 정리한 이유는 본 논문 이후에 바로 다룰 모델인 PinSAGE(GraphSAGE를 Pinterest의 Task에 맞춰서 커스텀한 모델)를 조금 더 잘 이해하기 위해서 이다.
Introduction
- 저차원의 Vector로 매우 큰 그래프 안에 노드를 Embedding 하는 것은 매우 유용함 (노드 예측, 링크 예측, 군집화 등 그래프 분석과 관련된 Task에 feature로 사용할 수 있음)
- 본 논문이 나오기 이전에 논문들은 전체 그래프를 가지고 노드를 임베딩함(노드의 Embedding을 먼저 구하고 해당 Embedding을 학습 시키는 방식, Embedding Look Up 방식)
- 그래서 새로운 노드가 생기면 해당 노드를 임베딩할 수 없다는 문제점이 존재함
- 실제 현실에서는 새롭게 생기는 노드나 그래프를 빠르게 임베딩하는 것이 중요함(새롭게 생긴 노드를 빠르게 현재 Task에 활용하기 위해서)
- 따라서 본 논문에서는 GraphSAGE(SAmple and aggreGatE)라는 모델을 사용하여, 임베딩을 학습하는 것이 아닌, node의 정보를(degree, text 등) input으로 하여 임베딩을 생성함 (새롭게 생긴 노드의 Embedding을 빠르게 생성할 수 있음)
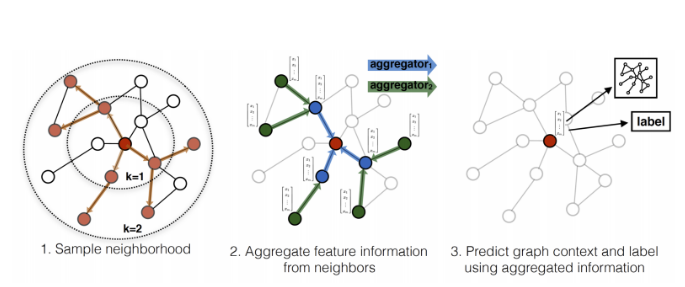
- GraphSAGE는 위의 그림과 같은 형식으로 이루어졌고, 비지도학습으로 모델이 학습됨
- 우선 임베딩을 하고자 하는 Target 노드의 이웃을 샘플링 한 후, 이웃 노드의 정보를 Aggregate하여 Target 노드의 Embedding을 생성함
- GraphSAGE의 핵심은 비지도학습을 위한 Loss function, Target 노드의 이웃을 샘플링, 이웃 노드의 정보를 Aggregate 하는 것임
Related work
- Factorization-based embedding approaches / Supervised learning over graphs / Graph convolutional networks 등의 방식은 새로운 노드에 대한 임베딩을 구할 수 없거나, 존재하는 노드에 대한 임베딩을 표현하거나, full graph Laplacian을 알아야 모델을 학습시킬 수 있다는 단점이 존재함
Proposed method: GraphSAGE
- GraphSAGE는 이웃 노드의 정보를 aggregate하는 방식으로 모델이 학습됨
- 학습된 GraphSAGE는 새로운 노드에 대한 임베딩을 생성할 수 있음
- GraphSAGE는 SGD와 backpropagation을 사용하여 파라미터를 업데이트 함
1) Embedding generation (i.e., forward propagation) algorithm

- Embedding generation을 algorithm은 위와 같은 수도 코드로 이루어짐
- 본 알고리즘의 직관은 각 반복 또는 검색 깊이에서 노드가 정보를 계속 합치면서, 노드의 임베딩을 구하는 것임
- 우리는 노드를 Embedding 하기 위해서 노드 x feature로 이루어진 행렬이 필요함
- 우리는 이웃 노드 정보를 aggregate하는 K개의 AGGREGAE가 필요함
- 우리는 전파된 정보와 이전 레이어의 정보를 합치는 K개의 W가 필요함
- 여기서 K는 Target 노드를 임베딩 하기 위한 탐색의 깊이를 의미함(k-hop의 개념, k가 1이면 Target 노드를 중심으로 이웃 노드만 사용하고, k가 2라면 Target 노드를 중심으로 이웃 노드에 이웃 노드 까지 사용함)
- K는 0에 노드 임베딩은 노드의 기존 feature로 설정하고, 그 후 K-1의 노드 정보를 AGGREGATE 하여 노드의 feature를 구하고, 해당 레이어의 노드 정보를 K-1 노드 정보와 concat 후 비선형함수를 통과하여 현재 K에 해당하는 노드의 Embedding을 얻고, Embedding을 정규화하고,(값이 너무 커지는 것을 방지) 이와 같은 과정을 K번 반복 해줌
- GraphSAGE 알고리즘은 Weisfeiler-Lehman Isomorphism Test에 영감을 받아서 만들어졌다고 함
- GraphSAGE 알고리즘은 학습 시에 고정된 크기의 이웃 set을 샘플링하여 사용함(고정된 크기의 subgraph를 만들었다는 것)
- K가 2라면 각 Target 노드를 중심으로 이웃 노드에 이웃 노드 까지 사용한 것이고, 각 k에 위치하는 노드의 수는 자기가 직접 설정하는 것임(각 k 마다의 이웃 노드의 수가 많아지면 그 만큼 그래프의 크기가 커지기 때문에 모델의 학습 속도는 느려질 것)
2) Learning the parameters of GraphSAGE
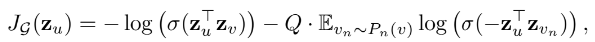
- GraphSAGE는 비지도학습을 위하여 위와 같은 Loss function을 사용함
- 우선 내가 이해한 바로는 Target 노드의 실제 이웃만으로 sampling된 pos set과 Target 노드와 이웃하지 않은 노드 만으로 sampling된 neg set이 필요함
- 그 후 pos set의 노드들을 Embedding, neg set의 노드들을 Embedding 함
- 그리고 pos set을 이용하여 Embedding 된 노드들(식에서는 v)은 Target 노드의 이웃이기 때문에 pos set으로 임베딩된 Target 노드(식에서는 u)와 서로 가깝게, neg set을 이용하여 Embedding 된 노드들은 Target 노드의 이웃이 아니기 때문에 pos set으로 임베딩된 Target 노드(식에서는 u)와 서로 멀어지게 학습됨
- 즉, pos 노드와는 유사하게, neg 노드와는 유사하지 않게 학습 하는 것이 본 loss의 목표라고 할 수 있음
3) Aggregator Architectures
- Aggregator Architectures는 이웃 노드의 정보를 집계하는 방식임
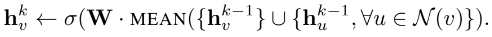
-
위와 같이 각 노드의 정보를 취합 후에 각 노드의 degree로 나눠 평균 정보를 구한 후 비선형 변환을 하는 Mean aggregator가 있음
-
또는 각 노드의 정보를 LSTM을 사용하여 합취는 LSTM aggregator도 있음, 그러나 본질적으로 이웃 노드의 순서는 정렬되지 않기 때문에 LSTM을 사용하는 것은 적합하지 않을 수 있음(아직 논문은 읽지 않았지만 이러한 이유 때문에 Attention을 사용하는 GAT가 나오지 않았을까 생각됨)
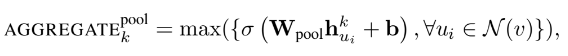
- 또는 위와 같이 각 노드의 기능 마다 제일 큰 값을 사용하는 MaxPooling aggregator도 있음
- 그런데 본 논문에서는 Mean aggregator와 MaxPooling aggregator 사이에 큰 차이가 없었다고 함 (나는 구현이 좀 더 쉬운 Mean aggregator를 사용하여 본 모델을 구현함)

- aggregator를 구현하는 것은 본 논문의 수식만으로는 이해하기 어려워서 설명하자면, 위처럼 노드들의 feature 행렬과 subgraph를 인접 행렬로 나타낸 행렬을 서로 행렬곱 하면 이웃 노드의 정보를 취합하는 aggregator를 구현할 수 있음(GCN 논문을 보면 이해해하기 쉬울 것임)
Experiments
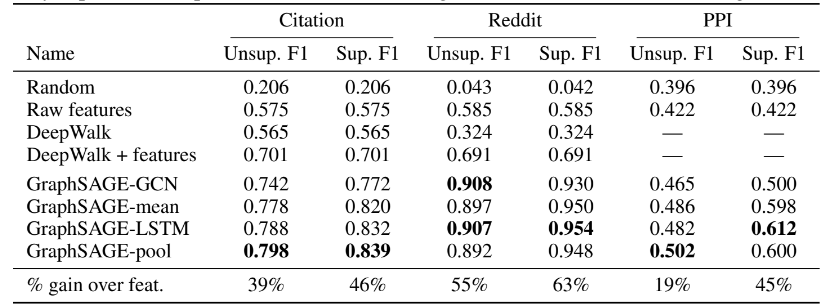
- 본 모델을 citation dataset, Reddit dataset, PPI dataset을 가지고 평가를 함
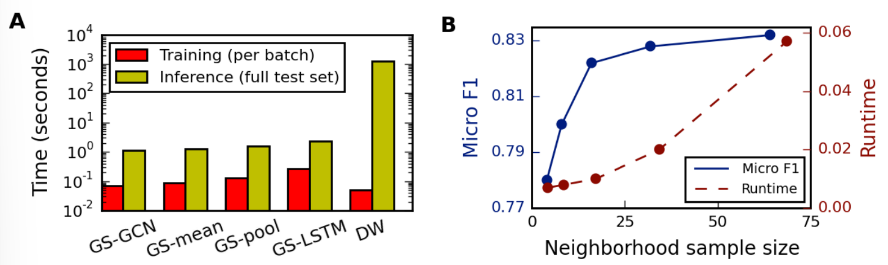
- 학습 시에는 batches size는 512로 설정하고, K=2, S1=25, S2=10으로 설정하여 모델을 학습 시킴
- 학습 후 Embedding을 생성할 때는 전체 그래프를 사용하여 노드의 임베딩을 생성함(나는 MovieLens 데이터를 사용했기 때문에 노드 임베딩 생성시에도 subgraph를 생성하여 임베딩을 생성함. 왜냐하면 MovieLens 자체가 이분 그래프(유저 - 영화)라서 전체 그래프로 표현하기 애매했기 때문임. 추후에 MultiSAGE나 PinSAGE 같은 경우는 이분 그래프를 사용할 수 있지 않을까 생각됨)
Conclusion
- 학습시에 존재하지 않았던 노드에 대해서 임베딩을 구할 수 있는 방법을 제안함
- 이웃 노드를 샘플링하여 학습하는 GraphSAGE는 학습 속도도 빠르며 성능도 좋아 다른 베이스라인 모델을 뛰어넘는 SOTA 모델이다.
Code
Reference
- https://arxiv.org/abs/1706.02216
- https://greeksharifa.github.io/machine_learning/2020/12/31/Graph-Sage/
- https://kangbk0120.github.io/articles/2020-03/graphsage
- https://yamalab.tistory.com/164?category=747907
- https://github.com/raunakkmr/GraphSAGE/blob/master/src/models.py
- https://github.com/williamleif/GraphSAGE

Machine Learning Engineer at Konan Technology