학습 내용
데이터를 읽고 집계하는 과정을 지나 시각화하고 분석하는 것들을 배우기 시작했다. 내가 관람하고 별점을 남긴 약 150개의 영화 데이터를 이용하여 분석하고 시각화하면서 조금 더 재밌게 공부하려고 시도해 봤다.
데이터는 스프레드시트에 직접 영화의 제목, 장르, 국가, 개봉연도, 평점 작성했다. 장르는 왓챠피디아의 데이터를 참고했고, 평점은 내가 왓챠피디아에 기록한 내용을 입력했다.
과연 어떤 장르의 영화를 가장 많이 시청했을까?
# 장르별 통계 구하기
my_genre = df['장르']
genre_list = []
# 내 별점 목록에 있는 모든 영화 장르 구하기
for mg in my_genre:
genre_str = mg.split(',')
for gs in genre_str:
gs = gs.strip()
genre_list.append(gs)
genre_df = pd.DataFrame(genre_list)
genre_df.columns = ['장르']
genre_df먼저, 영화 평점 데이터 목록에 존재하는 모든 장르를 구해서 genre_list[]에 담았다.
genre_counts = genre_df['장르'].value_counts()
genre_counts그리고 영화 평점 데이터 목록에서 장르별 총합을 구하고 시각화했다.
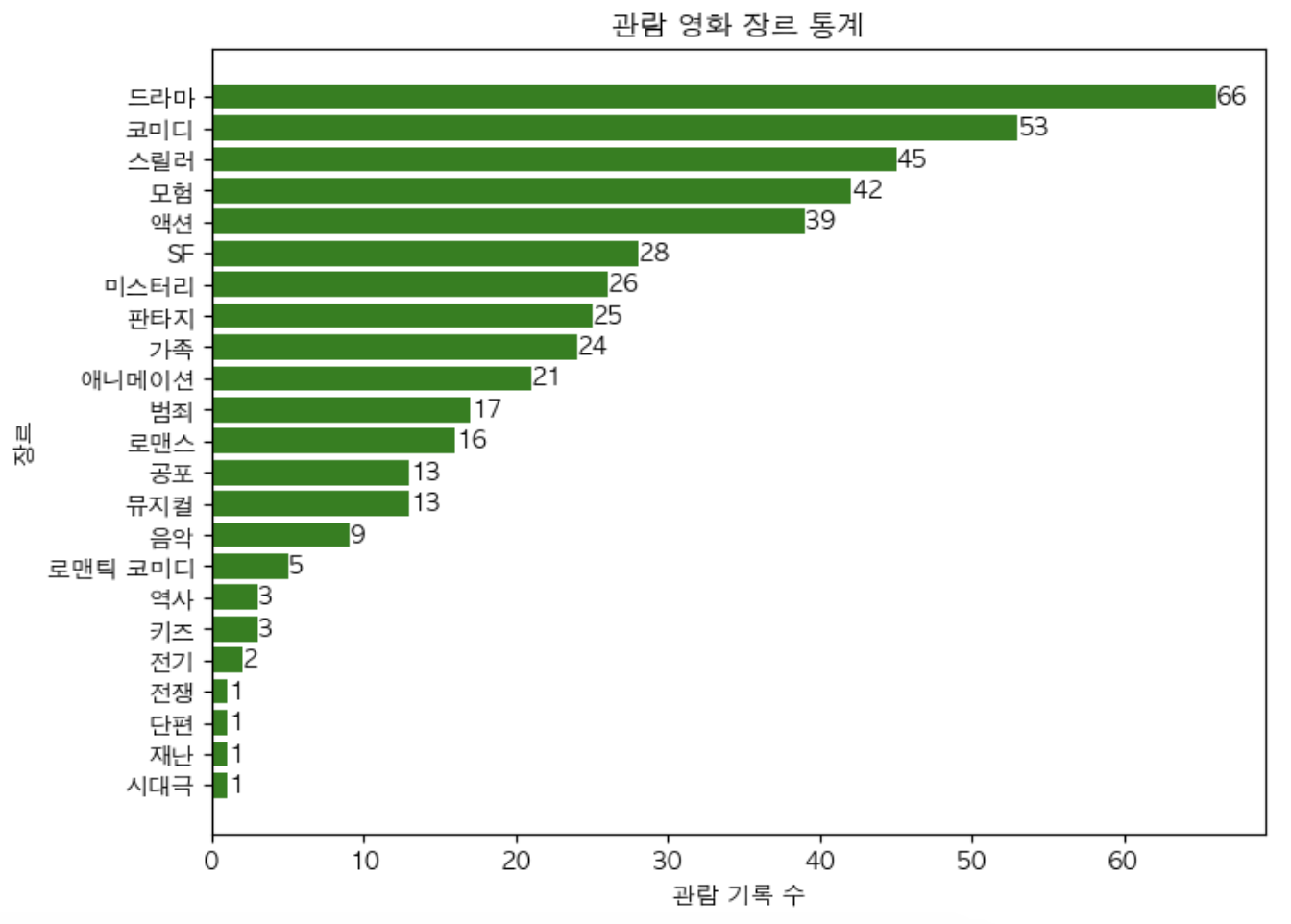
나는 평소에 스릴러나 미스터리 장르의 영화를 즐겨 본다고 생각했는데 의외로 드라마, 코미디 장르의 집계 수가 더 높았다.
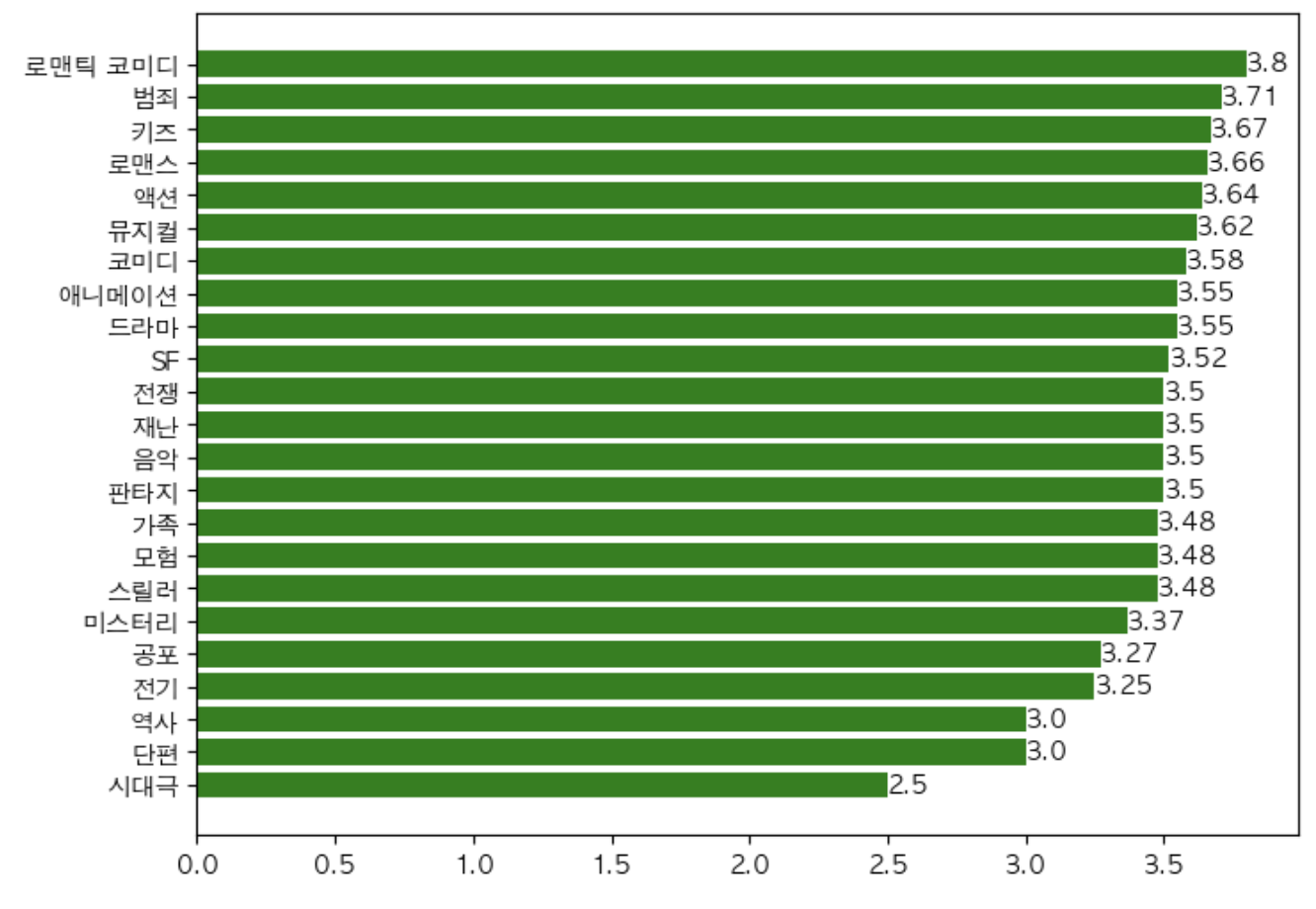
장르별 평점의 평균 값을 이용한 통계이다.
평점이 가장 높은 로맨틱 코미디는 실제로 5편 밖에 시청하지 않았지만 대체로 높은 평점을 가지고 있어서 1위를 하고 있다.
총 66편으로 가장 많이 시청한 드라마는 3.55로 내가 대체로 괜찮다고 생각하고 부여하는 점수에 가까웠다.
데이터가 많을수록 통계 값의 편차가 줄어들지만, 이를 통해서 더 작은 차이를 찾아내고 비교한다면 정교한 추천 시스템을 만들어갈 수 있을 것이라고 생각했다.
마무리
데이터 사이언스 스터디를 들으면서 데이터를 분석하는 것과 인사이트를 찾는 것도 즐겁지만 확실히 데이터를 엔지니어로써 다루는 일이 더 즐겁다는 것을 알게 되었다. 이번 주에는 데이터를 수집하기 위한 방법을 탐색하면서 새로운 지식을 쌓기도 하고, 궁금한 결과를 간단하게 확인하기 위해 시각화하는 과정을 통해 학습하는 시간을 가질 수 있었다.
