Claude Desktop을 이용한 MCP Server 구현하기 1
MCP 서버 테스트 이력
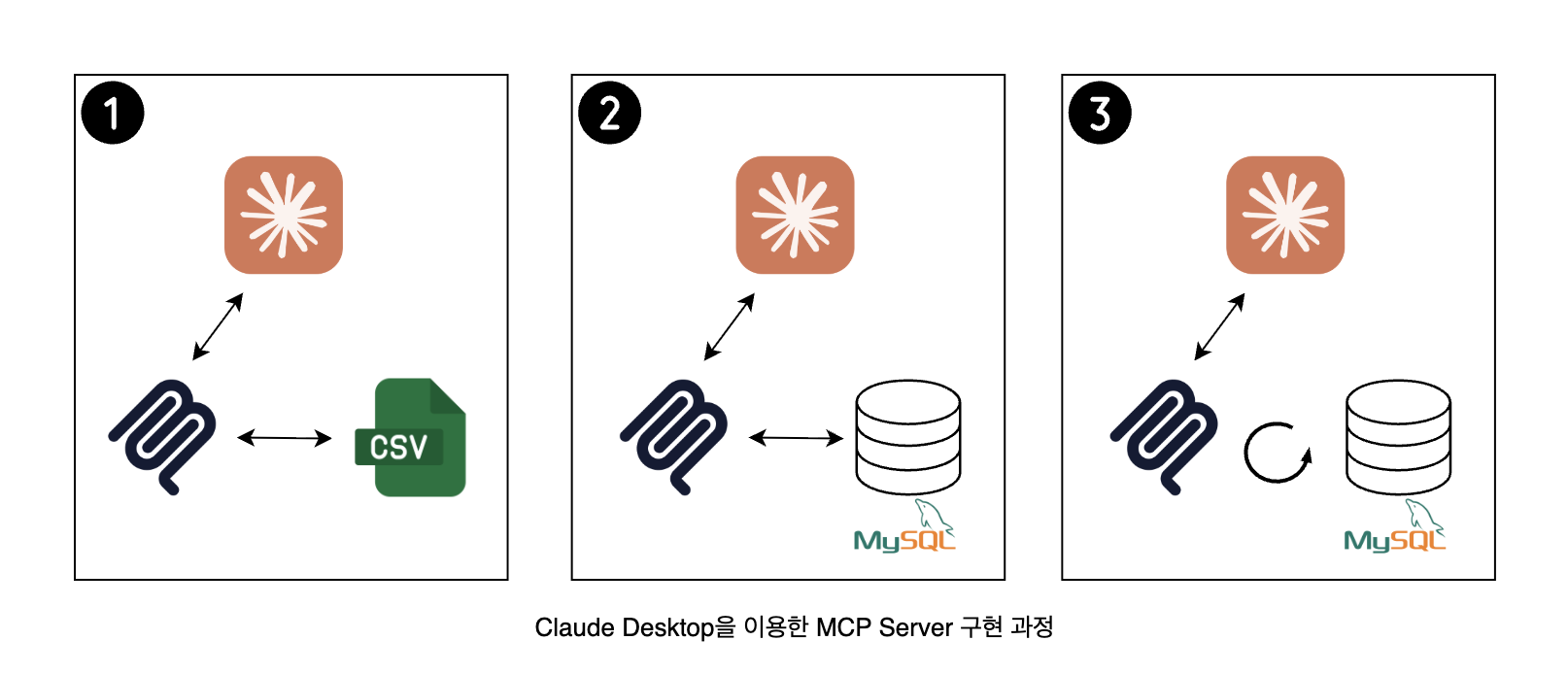
MCP 기반의 서비스를 구현하기 전에, 로컬에서 MCP 서버를 테스트하게 되었다.
로컬 환경에서의 테스트는 총 3단계로, 단계별 구조는 다음과 같다.
이번 포스트는 1번 테스트 과정을 담고 있다.
1. CSV 파일을 사용한 서버
MCP 서버가 어떠한 방식으로 데이터를 활용하고 답변하는지 확인하는 테스트를 진행했다. 데이터는 일부만 파일 형태로 추출하여 사용했다.
2. MySQL과 연동한 서버
운영 데이터를 활용한 구체적인 답변을 위해 데이터베이스와 연동했다.
FastMCP 모듈을 이용하여 쉽게 연동할 수 있었지만, 서비스 확장성을 위해 비동기 전환이 필요하다는 점을 이해했다.
3. MySQL과 비동기로 연동한 서버
MySQL과의 비동기 연동에 성공했다.
이후에는 로컬 환경이 아닌 운영 환경에서 구현할 예정이다.
테스트를 위한 환경 조성하기
로컬 환경에서 MCP 서버를 테스트하기 위해서는 Claude Desktop 앱과 Node.js의 설치가 필요하다.
Claude Desktop 설치하기
가장 먼저, Claude Desktop을 설치한다.
Node.js 설치하기
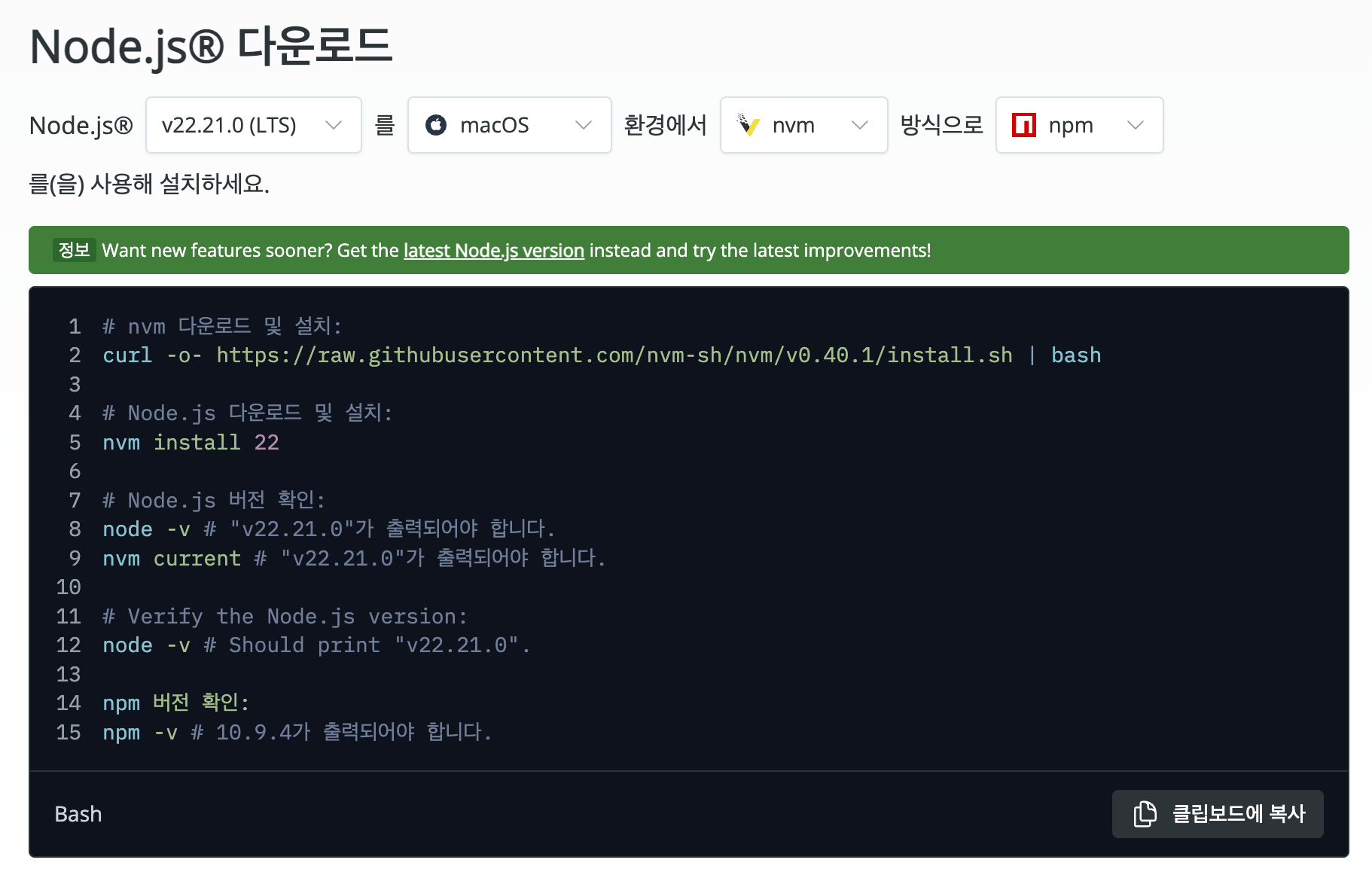
Node.js를 설치한다.
nvm 설치가 끝나면 아래와 같은 내용이 보이는데, 안내한 내용대로 nvm 환경 변수를 설정해야 무사히 사용할 수 있다.
=> Appending nvm source string to /Users/[사용자 이름]/.zshrc
=> Appending bash_completion source string to /Users/[사용자 이름]/.zshrc
=> Close and reopen your terminal to start using nvm or run the following to use it now:
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completionnvm 환경 변수 설정하기
vi /User/[사용자 이름]/.zshrc.zshrc 파일을 편집한다.
# .zshrc
...
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh"
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion"안내한 내용 그대로 붙여넣는다.
source ~/.zshrc파일을 저장하고, 이를 적용한다.
이후부터 Node.js 설치 및 나머지 nvm, node, npm 커맨드 사용이 가능해진다.
MCP 서버 설정하기
MCP Server 작성하기
[MCP 서버 경로]/
├── server/
│ └── mcp_server.py
└── data/
└── 데이터 파일.csvMCP 서버를 구현하기 위해 Documents 경로 하위에 위와 같이 생성했다.
이후에 해당 경로를 claude_desktop_config.json 파일에 추가하여 Claude Desktop이 인식할 수 있게 한다.
MCP 서버 구현 내용
import pandas as pd
from mcp.server.stdio import stdio_server
from mcp.server import Server
from mcp.types import Tool, TextContent
import json
import os
import asyncio
# 서버 시작 시 CSV 파일 로드
DATA_PATH = os.path.join(os.path.dirname(__file__), '..', 'data', '데이터 파일.csv')
df = None
# 파일 데이터 불러오기
def load_data():
global df
try:
for encoding in ['cp949', 'euc-kr', 'utf-8']:
try:
df = pd.read_csv(DATA_PATH, encoding=encoding)
return
...
# 서버 인스턴스 생성
server = Server("mcp_server")
# 사용 가능한 도구(Tool) 목록
@server.list_tools()
async def list_tools():
return [
Tool(
name="get_data_info",
description="CSV 데이터의 기본 정보 조회 (행/열 개수, 컬럼명)",
inputSchema={
"type": "object",
"properties": {},
}
),
...
]
# 도구 실행
@server.call_tool()
async def call_tool(name: str, arguments: dict):
global df
try:
if name == "get_data_info":
info = {
"행 개수": len(df),
"열 개수": len(df.columns),
"컬럼명": df.columns.tolist(),
"데이터 타입": df.dtypes.astype(str).to_dict()
}
return [TextContent(type="text", text=json.dumps(info, ensure_ascii=False, indent=2))]
...
async def main():
# 데이터 로드
load_data()
# 서버 실행
async with stdio_server() as (read_stream, write_stream):
await server.run(read_stream, write_stream, server.create_initialization_options())
if __name__ == "__main__":
asyncio.run(main())
서버를 실행하면 파일 데이터를 불러와서 DataFrame 형태로 변환한다.
서버에서는 요청에 따라 툴을 사용하고, 응답을 반환한다.
툴은 모두 비동기로 사용한다.
서버 설정 파일 생성하기
vi ~/Library/Application Support/Claude/claude_desktop_config.jsonClaude Desktop을 설치하면, ~/Claude까지의 경로가 생성된다. claude_desktop_config.json 파일은 처음에는 존재하지 않으니 새롭게 생성해서 작성하면 된다.
{
"mcpServers": {
"[MCP 서버 이름]": {
"command": "python",
"args": [
"/Users/[사용자 이름]/Documents/[MCP 서버 경로]"
]
}
}
}위와 같이 서버 설정 파일을 작성하고, Claude Desktop 앱을 실행했을 때 오류가 발생했다.
서버 설정 파일 내 "command": "python" 부분에서 파이썬을 제대로 인식하지 못한 것이 원인이었다.
which python명령어를 통해 파이썬 경로를 확인하고, 이를 기존 "python" 위치에 대치하면 제대로 인식하게 된다.
실행 성공
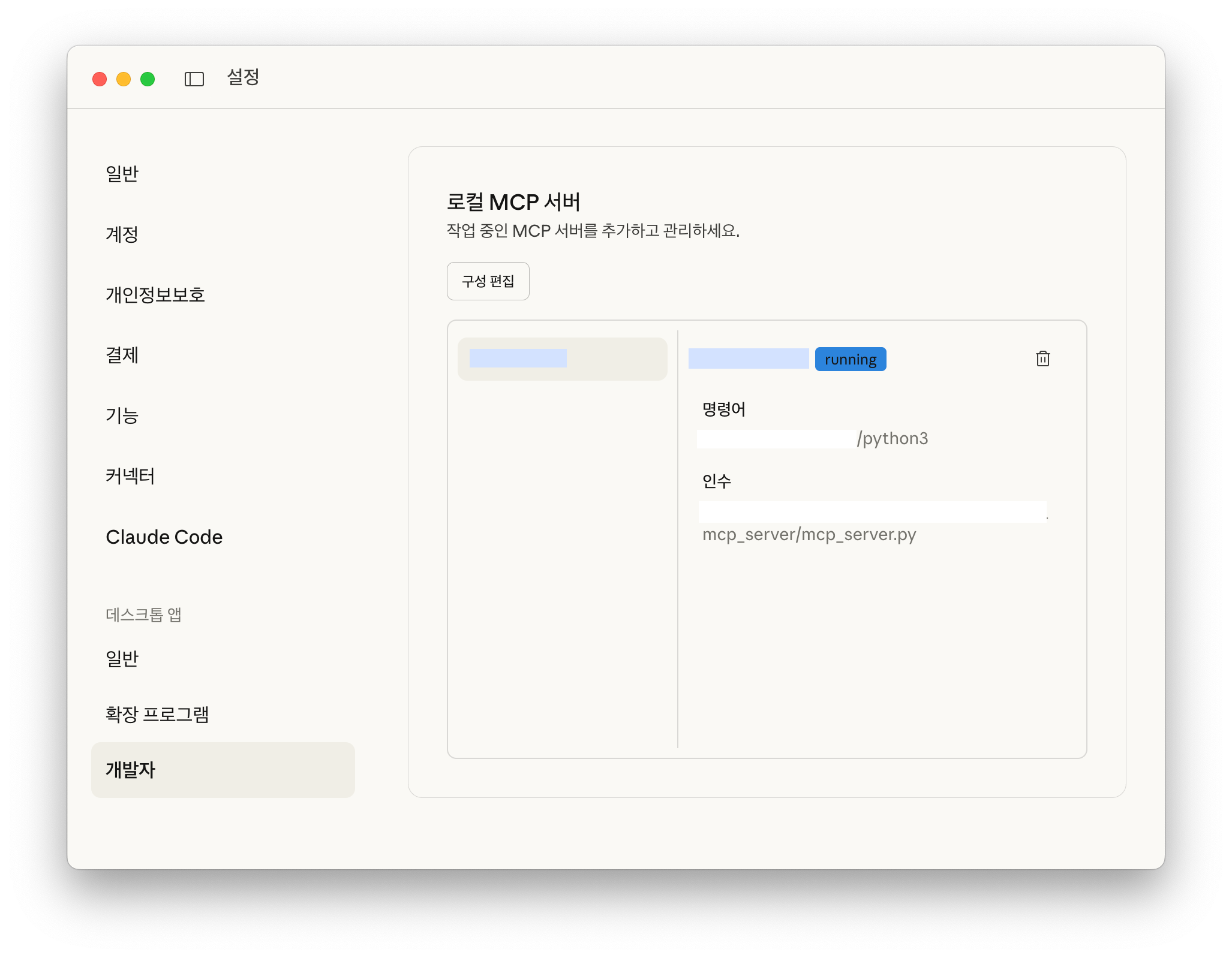
작성한 MCP 서버의 실행 단계에서 문제가 발생하지 않는다면, Claude Desktop 앱을 실행했을 때 위와 같이 running 상태임을 확인할 수 있다.
테스트 채팅 내용은 운영 서비스와 데이터를 담고 있어 첨부할 수 없지만, 성공적인 답변을 얻을 수 있었다.
마무리
MCP 기반의 서비스를 구현하기 전에, LLM은 우리가 가진 데이터를 어떻게 사용하여 답변할지 궁금해서 로컬 환경에서 먼저 테스트했다.
간단하게 파일 데이터를 활용한 로컬 서버를 구현했는데, 구체적인 테스트를 위해서는 운영 DB와 연동이 필요하다.
MCP 서버를 실제로 구현하고 테스트하기 전에는 Tool 정의에 대해 막연한 부담감이 있었다. 아직 서비스 고도화 단계가 아니라 간단하게만 구현했지만 지금도 충분히 요구에 따른 응답을 할 수 있는 상태인 것 같다.
