Claude Desktop을 이용한 MCP Server 구현하기 2
이전에 파일 데이터를 이용한 MCP 서버 테스트에 성공했기 때문에, 운영 중인 데이터를 활용할 수 있도록 MySQL과 연동하는 방법에 대해 알아보았다.
FastMCP를 이용한 MCP 서버 구현하기
파일 데이터 대신 데이터베이스로 대치하는 과정에서 MCP Tool 작성을 포함한 많은 오류가 발생했다.
간단하고 빠르게 데이터베이스 연결과 응답 확인을 목적으로 FastMCP를 사용하여 서버를 다시 작성했다.
FastMCP Server 테스트
import pymysql
import pandas as pd
from mcp.server.fastmcp import FastMCP
# 데이터베이스 연결
def get_connection():
conn = pymysql.connect(
user='',
passwd='',
host='',
db='',
charset='utf8',
connect_timeout=2
)
return conn
# 데이터 기본 정보 조회
@tool
def get_data_info():
conn = get_connection()
cursor = conn.cursor()
cursor.execute(f"SELECT COLUMN_NAME, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME='{TABLE_NAME}'")
result = cursor.fetchall()
conn.close()
return result
...
if __name__ == "__main__":
mcp = FastMCP("[서버 이름]")
mcp.add_tool(get_data_info)
...
mcp.run()
최근에 데이터 마트 테이블을 구현한 적이 있어서 해당 테이블을 사용하여 MCP 서버를 테스트했다.
서버 인스턴스를 생성하고, add_tool()을 통해 선언한 툴을 추가했다.
테스트 결과
1. 데코레이터 인식 오류 발생
@tool 데코레이터를 사용한 구간에서 오류가 발생했다.
이를 삭제하고 mcp.add_tool()만 작성해도 해당 툴을 사용할 수 있었다.
2. 비동기: 효율적인 서비스로 확장하기 위한 선택
MCP Tool은 DB 질의(네트워크 I/O), 백엔드 서버와의 통신(HTTP I/O) 등 여러 I/O 바운드 작업을 수행한다.
이러한 작업들을 동기 방식으로 수행할 경우, I/O 대기 시간 동안 이벤트 루프가 멈추는 비효율이 발생한다.
이는 서버의 동시성을 상실하게 만들고, 동시 요청이 커지면 병목 현상이 발생하게 된다.
따라서 작업을 효율적으로 수행하기 위해서는 비동기 처리가 필수적이고, DB와의 연결에서도 pool이 비동기로 connection을 가져와서 사용하게 해야 한다.
비동기로 전환하기
DB Connection 분리하기
import aiomysql
import asyncio
class DatabasePool:
def __init__(self):
self.pool = None;
async def init_pool(self, minsize=1, maxsize=10):
self.pool = await aiomysql.create_pool(
user='',
passwd='',
host='',
db='',
charset='utf8',
connect_timeout=2,
minsize=minsize,
maxsize=maxsize,
autoCommit=True
)
async def fetch_all(self, query, params=None):
async with self.pool.acquire() as conn:
async with conn.cursor(aiomysql.DictCursor) as cur:
await cur.execute(query, params or ())
return await cur.fetchall()
async def close(self):
if self.pool:
self.pool.close()
await self.pool.wait_closed()비동기 DB 드라이버를 사용할 수 있도록 별도로 작성했다.
이를 사용하여 서버가 시작될 때, DB Connection Pool을 1회 생성하도록 한다.
비동기 서버 구현하기
import asyncio
from mcp.server.stdio import stdio_server
from mcp.server import Server
from mcp.types import Tool, TextContent
from db.mysql_client import DatabasePool
# 서버 인스턴스 생성
server = Server("서버 이름")
# 사용 가능한 도구 목록
@server.list_tools()
async def list_tools():
return [
Tool(...),
...
]
# 도구 실행
@server.call_tool()
async def call_tool(name: str, arguments: dict):
try:
if name == "tool 이름":
...
async def main():
db = DatabasePool()
await db.init_pool()
async with stdio_server() as (read_stream, write_stream):
await server.run(read_stream, write_stream, server.create_initialization_options())
await db.close()
if __name__ == "__main__":
asyncio.run(main())위에서 작성한 MySQL 모듈을 사용하는 비동기 서버를 구현했다.
빠른 테스트를 위해 사용했던 FastMCP 대신 앞으로의 서비스 확장성을 고려하여 다시 MCP SDK로 작성했다.
서버 실행 과정에서 발생한 오류
1. ModuleNotFoundError 오류 발생
데이터베이스 연동 모듈을 인식하지 못하는 오류가 발생했다.
이는 내가 작성한 모듈을 패키지로 인식하지 못하는 문제였는데, DB 모듈을 작성한 경로에 __init__.py를 추가하여 패키지로 인식할 수 있게 수정하고 해결했다.
Documents/
├── mcp_server/
│ ├── mcp_server.py
│ ├── db/
│ │ ├── __init__.py
│ │ └── mysql_client.py해당 내용을 추가한 이후에는 모듈을 제대로 인식했다.
2. TypeError 오류 발생
TypeError: connect() got an unexpected keyword argument 'autoCommit'정확하게는 위와 같은 오류가 발생했는데, DB 커넥션 생성을 위해 작성한 내용을 인식하지 못하는 문제였다.
기존 FastMCP에서 사용하던 변수명과 차이가 있어서 발생하는 문제였기 때문에 모듈 내 init_pool()을 수정했다.
autoCommit을 autocommit으로 변경하는 것 이외에도 passwd를 password로 변경해서 문제를 해결했다.
수정한 코드는 아래와 같다.
async def init_pool(self, minsize=1, maxsize=10):
self.pool = await aiomysql.create_pool(
user='',
password='',
host='',
db='',
charset='utf8',
connect_timeout=2,
minsize=minsize,
maxsize=maxsize,
autocommit=True
)3. DatabasePool() 인식 오류
기존에는 async def main() 내부에 db = DatabasePool()을 작성하여 사용했는데, 이렇게 선언할 경우 Tool을 실행할 때는 db를 인식하지 못하는 오류가 발생했다.
따라서 db를 전역 변수로 작성하여 Tool이 인식할 수 있도록 변경했다.
Tool 수정하기
TextContent()로 응답하기
위와 같은 과정을 거쳐 비동기로 작성한 MCP 서버가 무사히 실행되는 것을 확인했다. 하지만 Claude Desktop에서 질문을 했을 때, MCP Tool이 제대로 답변하지 못하는 오류를 확인했다.
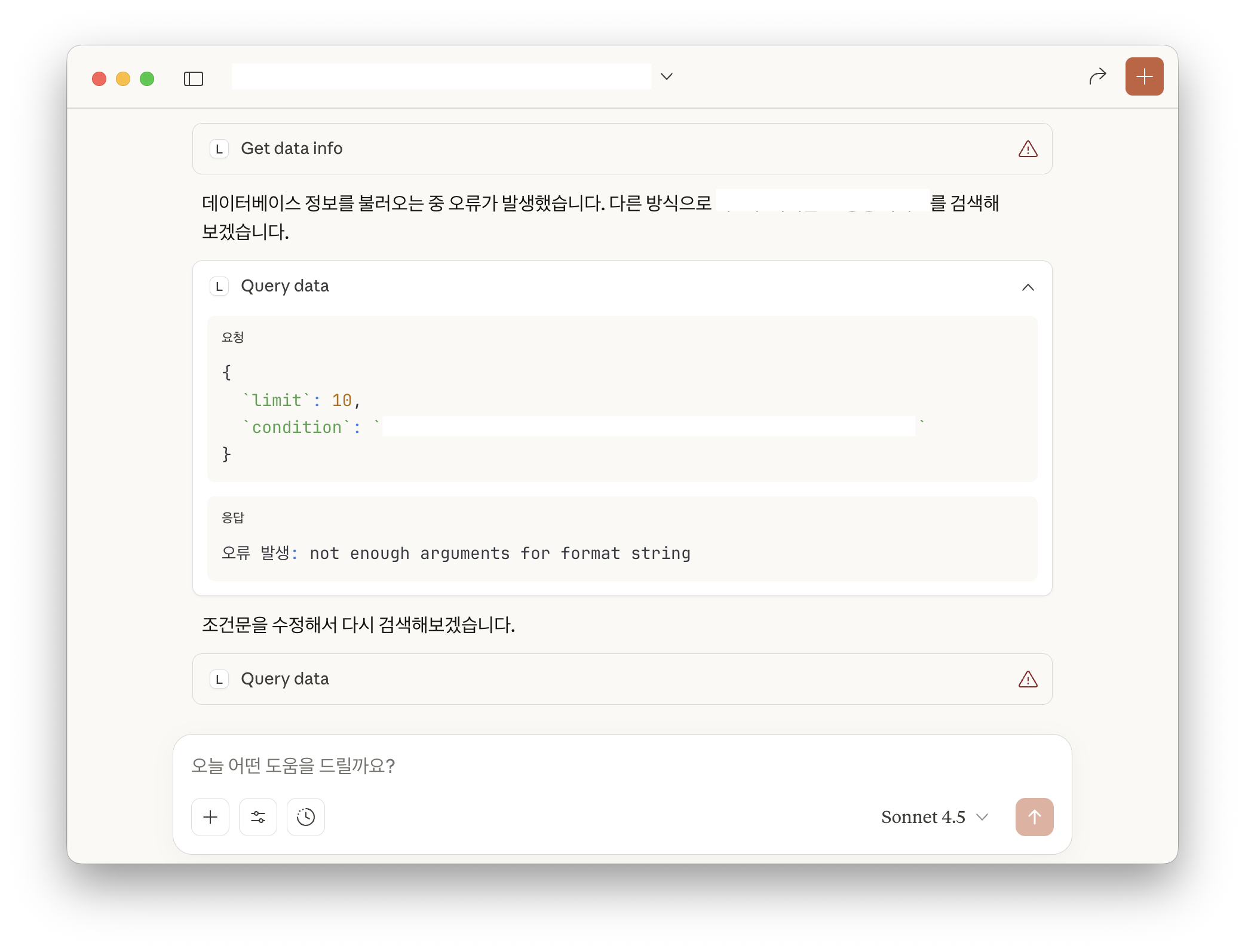
MCP Tool에서 쿼리 실행 결과를 그대로 반환하거나, 형식에 맞지 않은 방법으로 전달하려고 해서 문제가 발생했다.
@server.call_tool()
async def call_tool(name: str, arguments: dict):
try:
if name == 'get_data_info':
query = f'select column_name, data_type, from information_schema.columns where table_name = "{TABLE_NAME}"; '
result = await db.fetch_all(query)
return result예시로 get_data_info라는 이름의 Tool은 특정 데이터베이스의 정보를 전달하는데, 쿼리 실행 결과를 그대로 전달하는 과정에서 오류가 발생했다.
1521 validation errors for CallToolResult\ncontent.0.TextContent.type\n Field required ... 따라서 해당 툴이 TextContent()를 사용한 값을 반환할 수 있도록 수정했다.
return [TextContent(type="text", text=json.dumps(result, ensure_ascii=False, indent=2))]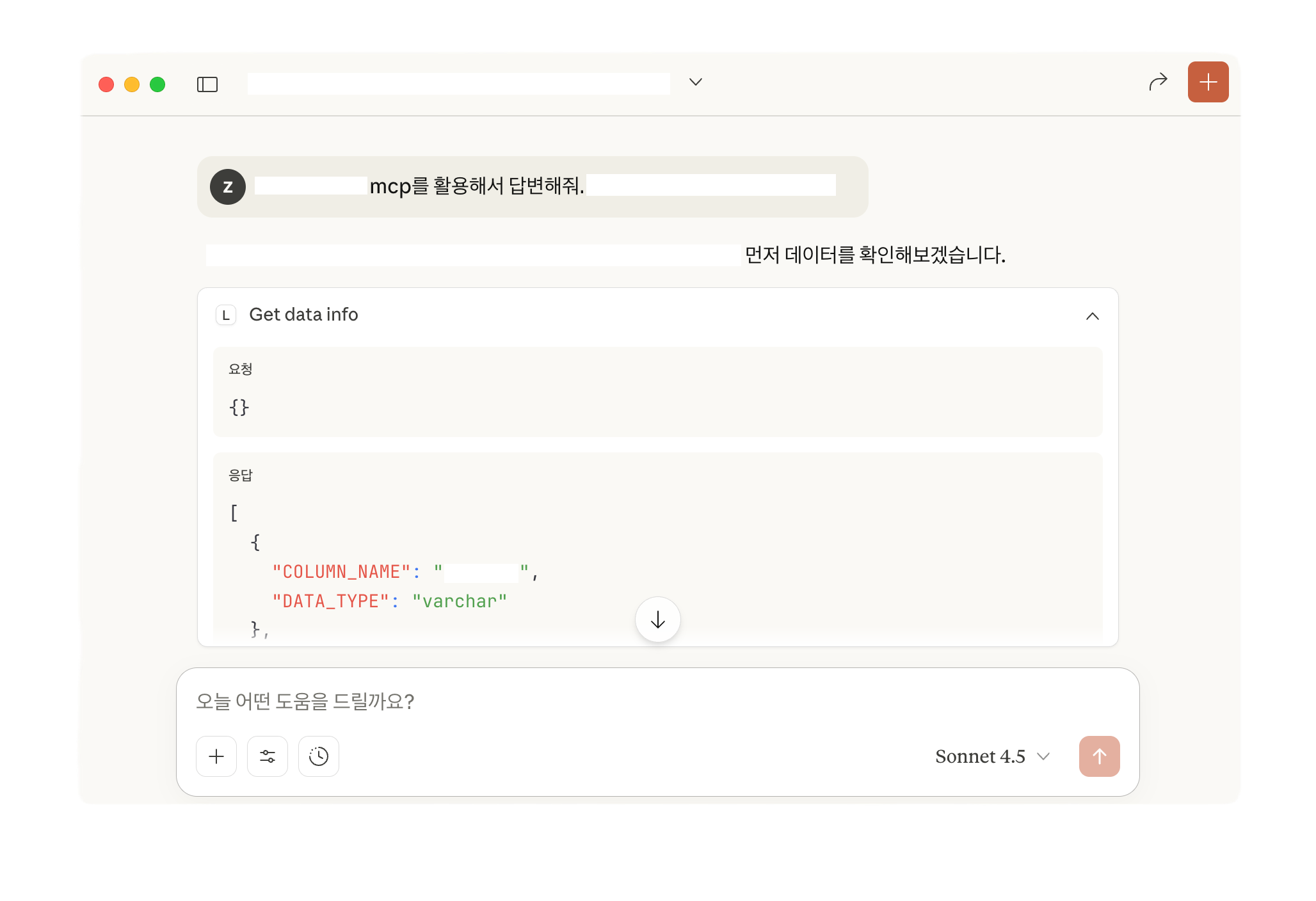
수정한 이후에는 제대로 컬럼 데이터를 확인할 수 있었다.
JSON 직렬화 오류 수정하기
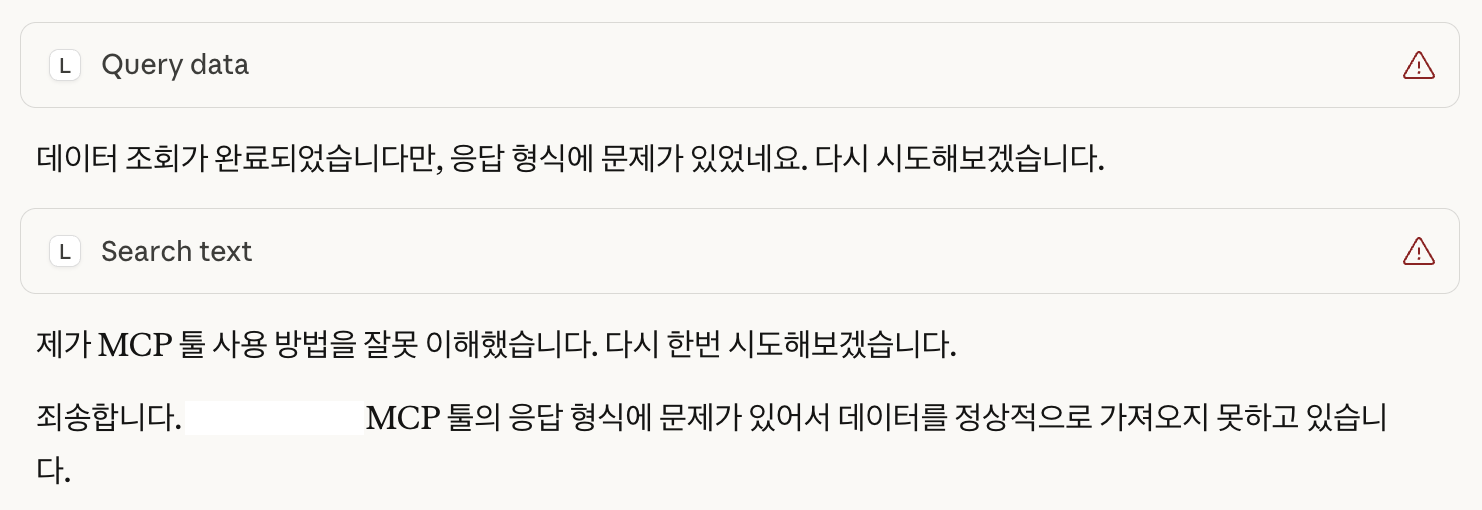
다른 툴도 TextContent()를 사용하여 반환할 수 있도록 수정했으나, 또 다른 문제가 발생했다.
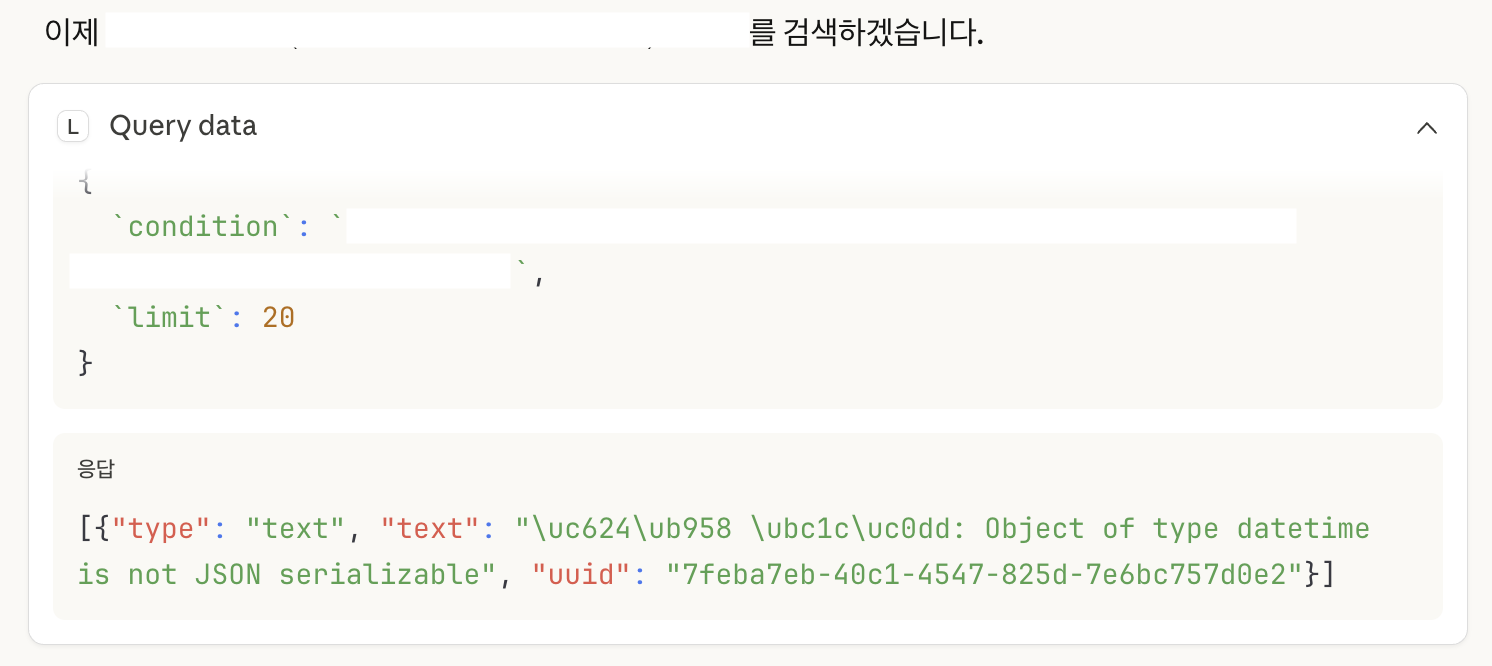
json.dumps() 과정에서 직렬화 오류가 발생했다.
나는 datetime에서 오류가 발생했는데, 이 부분은 문자열로 치환하여 인식할 수 있도록 수정해서 해결했다.
마무리
로컬 환경이지만 MCP를 기반으로 하는 서비스의 기초적인 테스트를 해볼 수 있는 경험이었다.
테스트를 하기 전까지는 MCP Tool에는 구체적인 컬럼을 지정한 쿼리를 작성해서 데이터를 검색하고 이를 답변할 수 있도록 작성해야 하는 줄 알고 있었는데, 실제로는 MCP 서버와 LLM이 서로 말이 통하게 만드는 수준의 일을 하면 된다는 점을 직접 경험할 수 있었다. 그리고 이번 테스트 과정에서 다시 한번 깨달은 점은 역시나 서비스를 위해서 데이터가 정말 중요하고, 나는 데이터를 다루는 일을 하고 싶다는 거였다.
항상 새로운 내용을 배우거나 도입할 때는 모든 추상적인 개념이 어렵게 다가오는데, 이렇게 직접 테스트 과정에서 부딪혀가며 이해하고 나면 더 이상 두려울 게 없어지는 기분이다.
지금까지 테스트한 내용을 앞으로는 서비스로 운영할 수 있도록 더 확장해서 구현해야 할 텐데, 이 과정에서 데이터베이스도 변경될 것 같고 기존에 사용해 보지 못했던 클라우드 서버를 활용할 수도 있을 것 같다.
