Elasticsearch를 이용해서 검색 기능을 구현할 때, 한글을 사용하기 위해서는 nori라는 한글 형태소 분석 플러그인이 필요하다는 것을 알게 되었다.
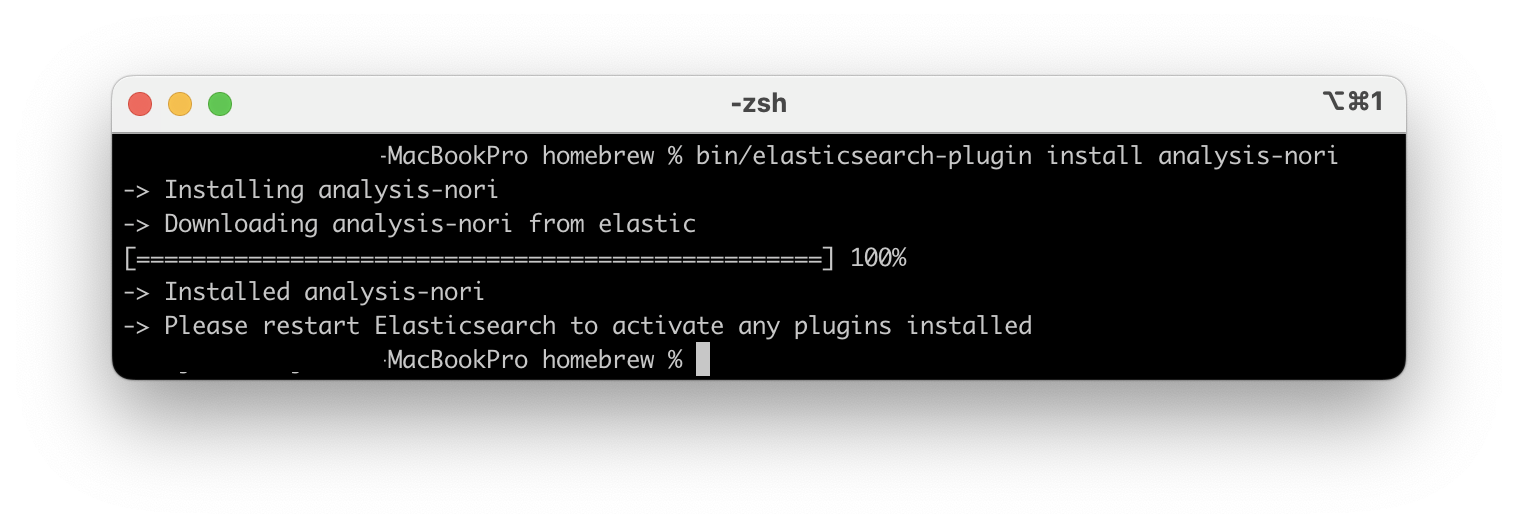
nori 설치하기
Elasticsearch의 홈 디렉토리에서 아래의 설치 명령어를 실행해야 한다.
$ bin/elasticsearch-plugin install analysis-nori내가 사용하는 환경에서는 /opt/homebrew/bin/elasticsearch ... 의 디렉토리 구조를 가지고 있었기 때문에 /opt/homebrew/ 위치에서 실행했을 때 성공적으로 설치할 수 있었다.
tokenizer란?
데이터 색인 과정에서 검색 기능에 가장 큰 영향을 미치는 항목으로, 어떤 방식으로 형태소를 분리하는지 결정하는 역할을 한다.
데이터 분석 과정에서는 하나의 tokenizer만 사용할 수 있다.
Elasticsearch 에서는 분석된 문장을 _analyze API를 이용해서 확인할 수 있다.
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"stop",
"snowball"
]
}토크나이저는 tokenizer에 작성하고, 토큰 필터는 사용하려는 필터를 배열의 형태로 filter에 작성하여 문장을 분석할 수 있다.
다음은 하나의 문장을 3개의 토크나이저로 각각 분석한 결과이다

Standard는 공백으로 term을 구분하고, “@“과 같은 특수 문제를 제거한다. “jumped!”의 느낌표와 “meters.”의 마침표처럼 단어 끝에 있는 특수문자는 제거하지만, “quick.brown_FOx”나 “3.5”처럼 중간에 있는 특수문자는 분리되지 않는다.
Letter는 알파벳을 제외한 모든 공백, 숫자, 기호를 기준으로 term을 구분한다.
Whitespace는 스페이스, 탭, 줄바꿈 같은 공백을 기준으로 term을 생성한다. 특수문자를 제거하지 않는다.
일반적으로 Standard를 많이 사용하는데, Letter는 검색 범위가 넓어져서 원하지 않는 결과가 많이 나올 수 있고, Whitespace는 특수문자를 거르지 않기 때문에 정확한 검색어를 입력하지 않으면 검색 결과의 효율이 떨어질 수 있기 때문이다.
nori_tokenizer 사용하기
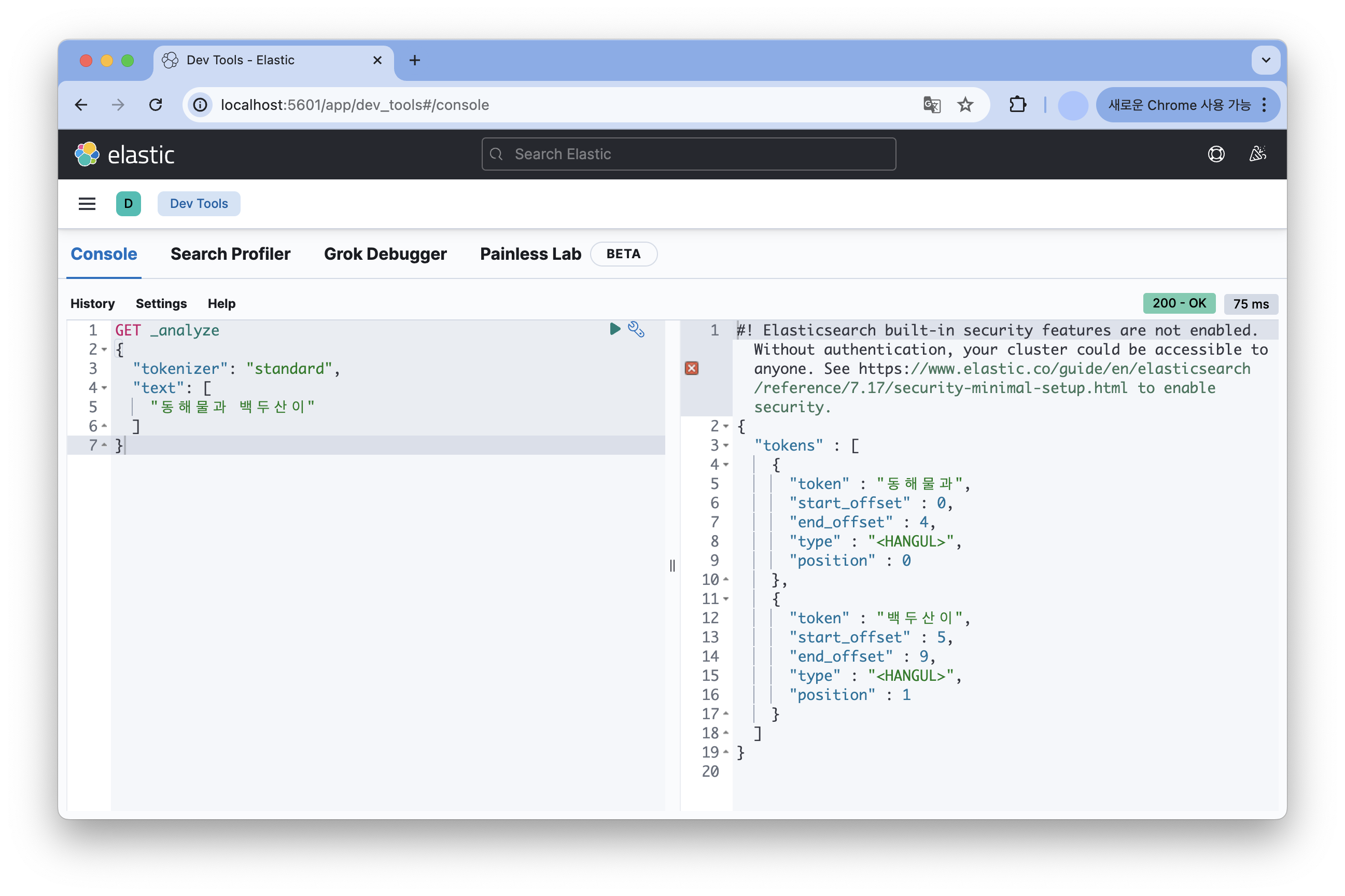
먼저 Standard 토크나이저를 이용하여 한글로 작성한 문장을 분석했을 때는 공백을 기준으로만 분리한 결과를 얻을 수 있었다.
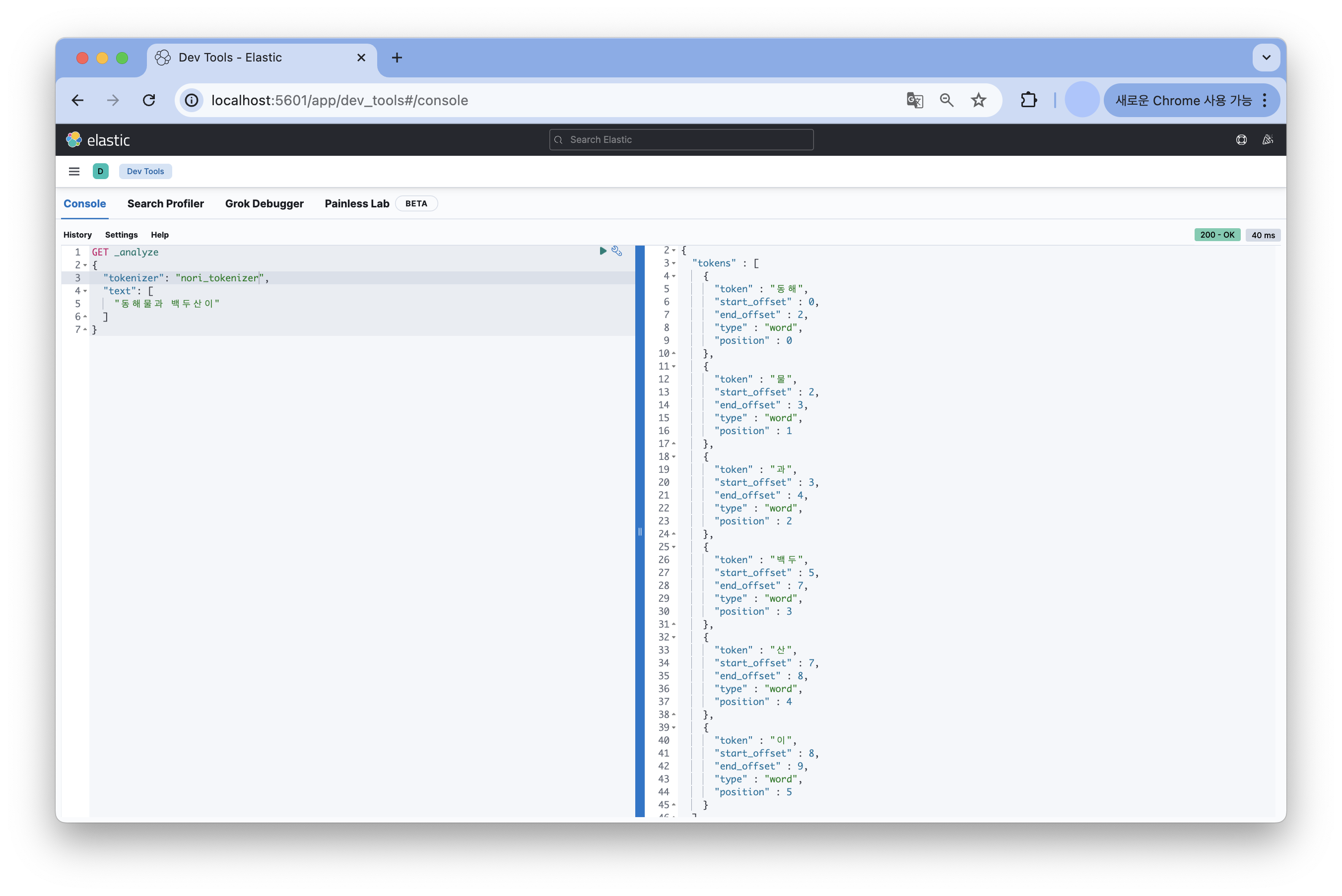
nori 토크나이저를 이용했을 때는 한국어 사전 정보를 이용하여 [동해, 물, 백두, 산]과 [과, 이]와 같은 형태로 문장을 분석한 결과를 얻을 수 있었다.
nori_tokenizer에서 제공하는 기능
user_dicionary
사용자 사전이 저장된 파일의 경로를 입력한다.
user_dictionary_rules
사용자 정의 사전을 배열로 입력한다. 정의한 단어를 기준으로 우선순위를 반영하여 문장을 분리하는 역할을 부여한다.
decompound_mode
합성어 저장 방식을 결정한다.
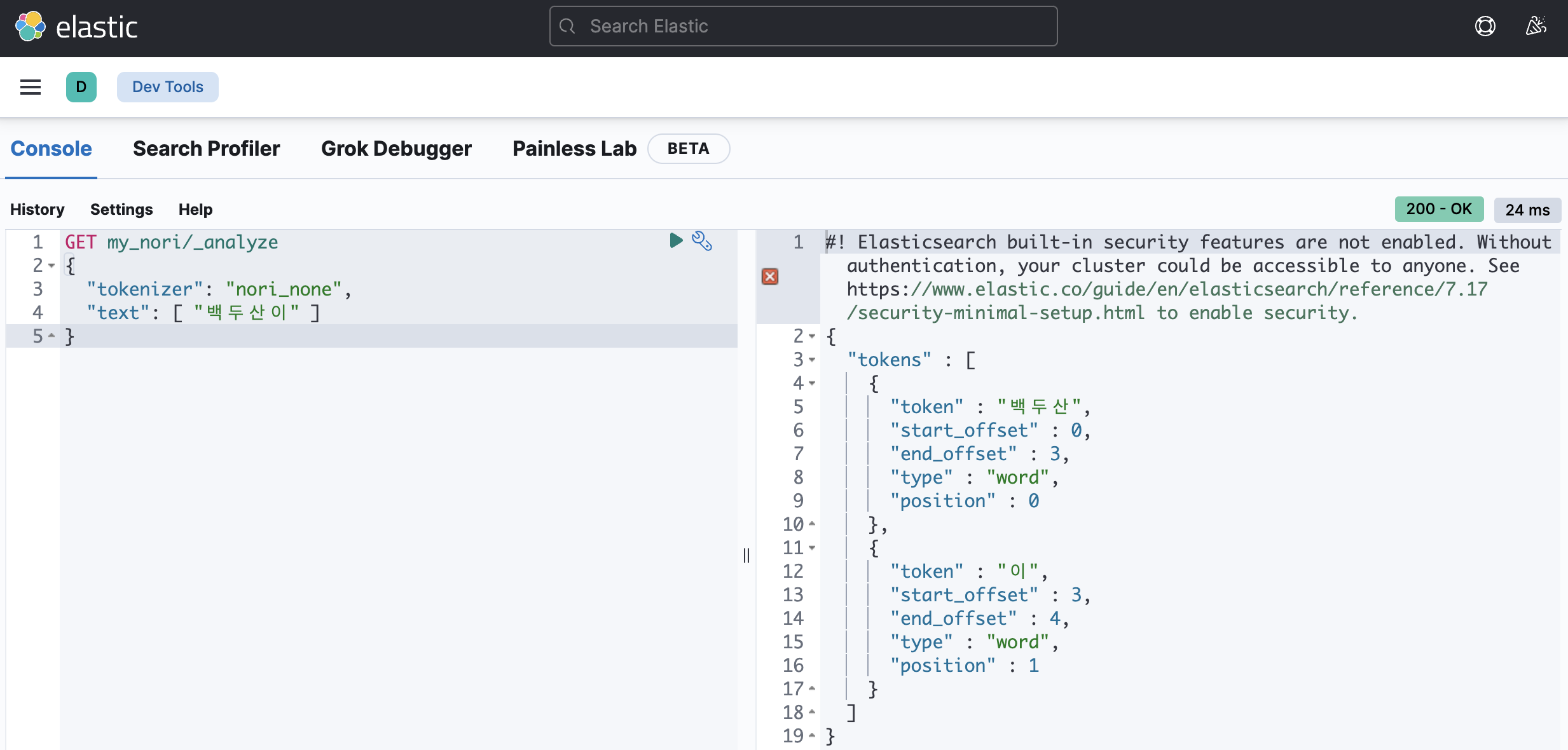
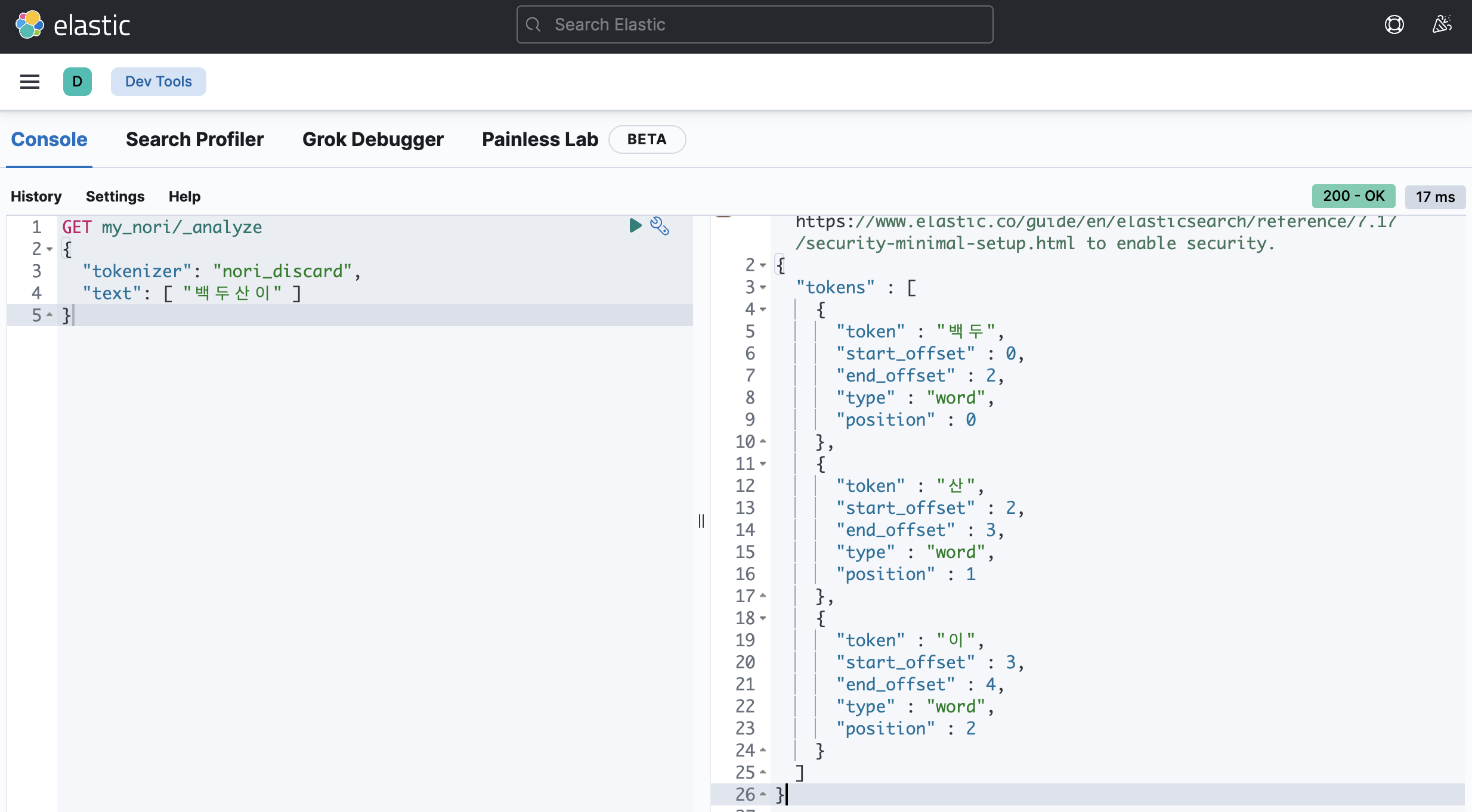
none: 어근을 분리하지 않고 완성된 합성어만 저장discard: 합성어를 분리하여 각 어근만 저장 (default)mixed: 어근과 합성어 모두 저장
decompound_mode를 활용한 문장 분석의 차이
custom tokenizer 생성
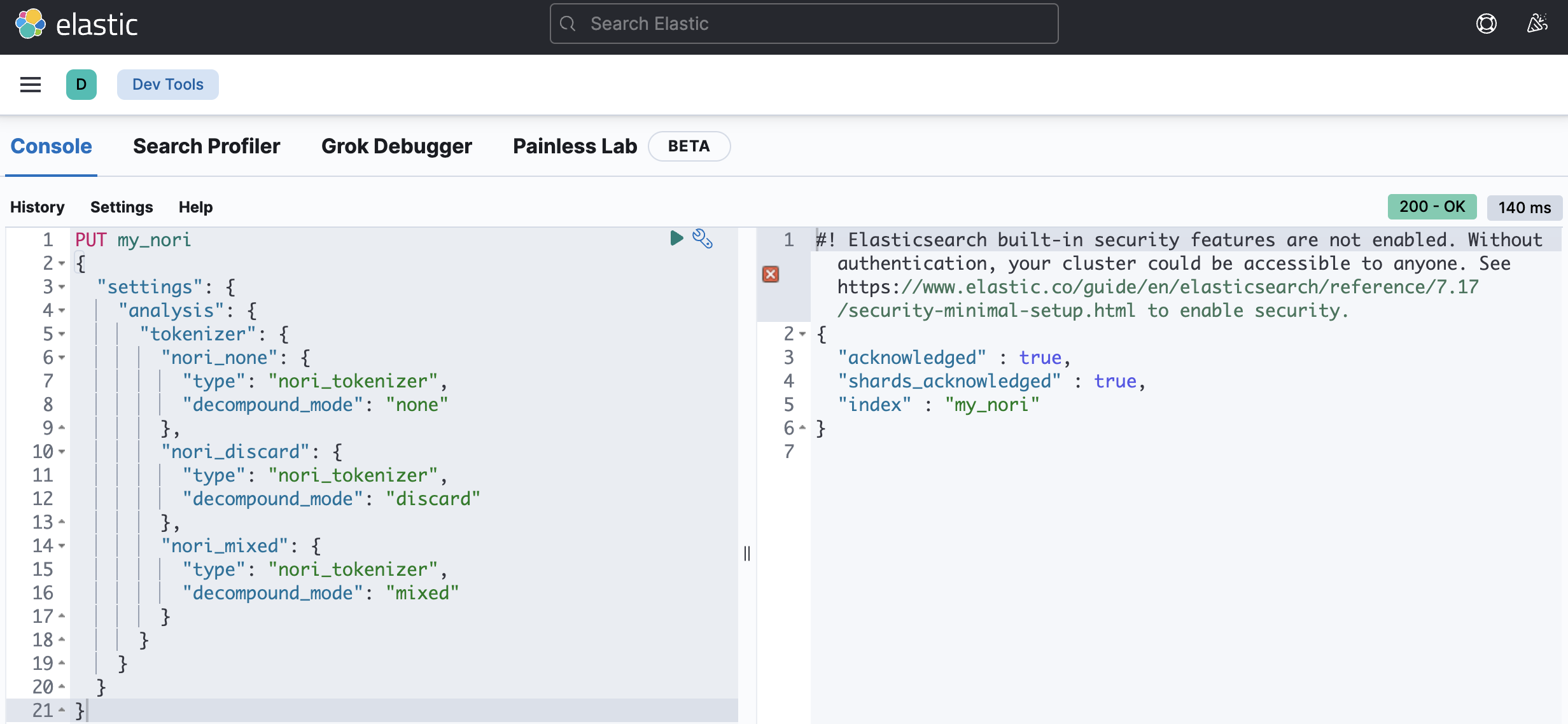
합성어 저장 방식의 차이를 테스트해보기 위해서 합성어 저장 방식에 대해 지정한 토크나이저를 생성했다.
custom tokenizer를 이용한 문장 분석
decompound_mode: none
decompound_mode: discard
decompound_mode: mixed
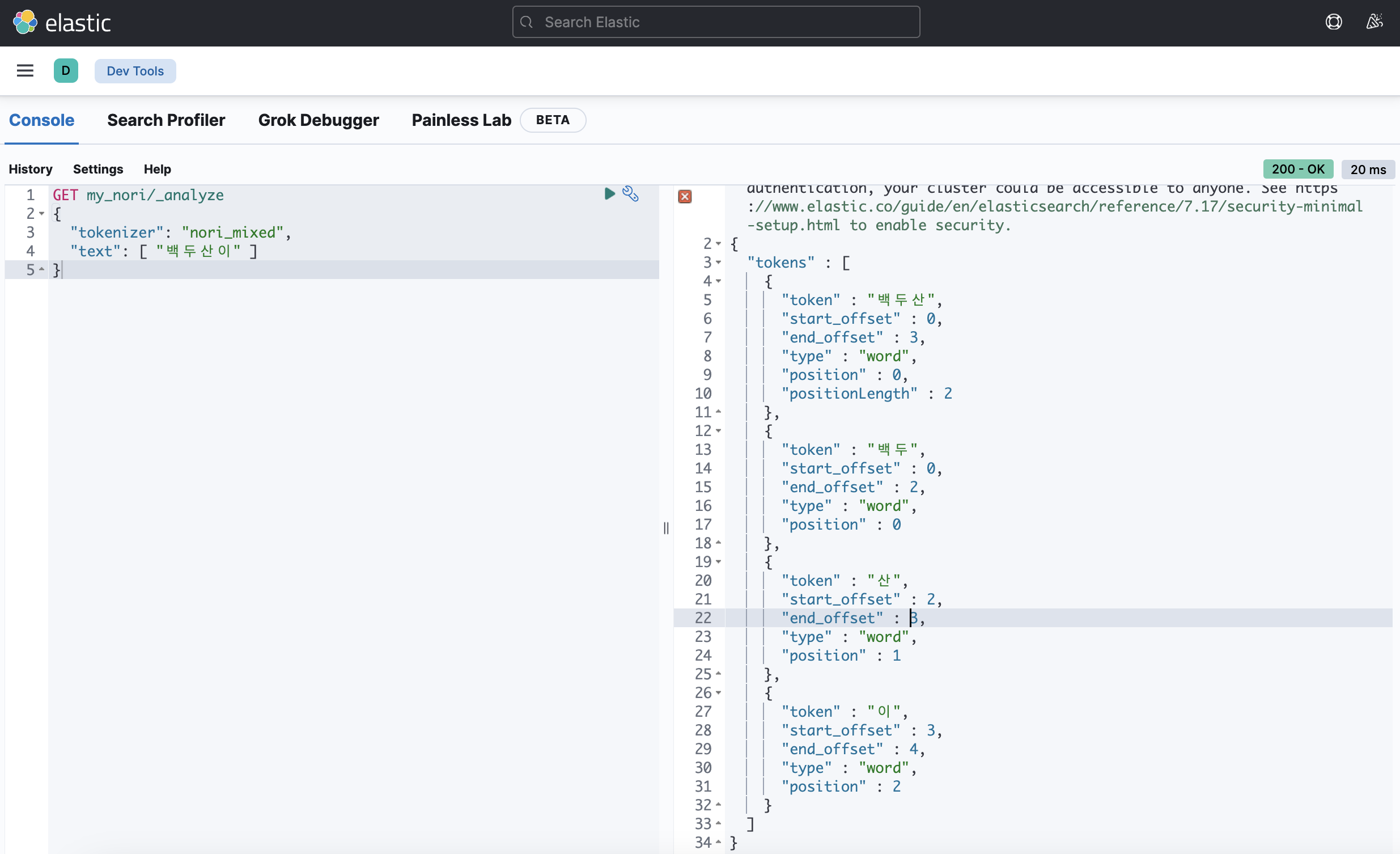
각각의 합성어 저장 방식에 따라 문장을 다르게 분석한 결과를 확인할 수 있었다.
nori_part_of_speech
한글 문장을 이용한 검색에서는 필요한 데이터를 효율적으로 얻기 위해 명사나 동명사 정도의 정보만 필요할 때가 많다. nori_part_of_speech 토큰 필터를 이용해서 제거할 품사 정보를 지정할 수 있고, stoptags 값에 제외할 품사 코드를 배열로 입력하여 사용할 수 있다.
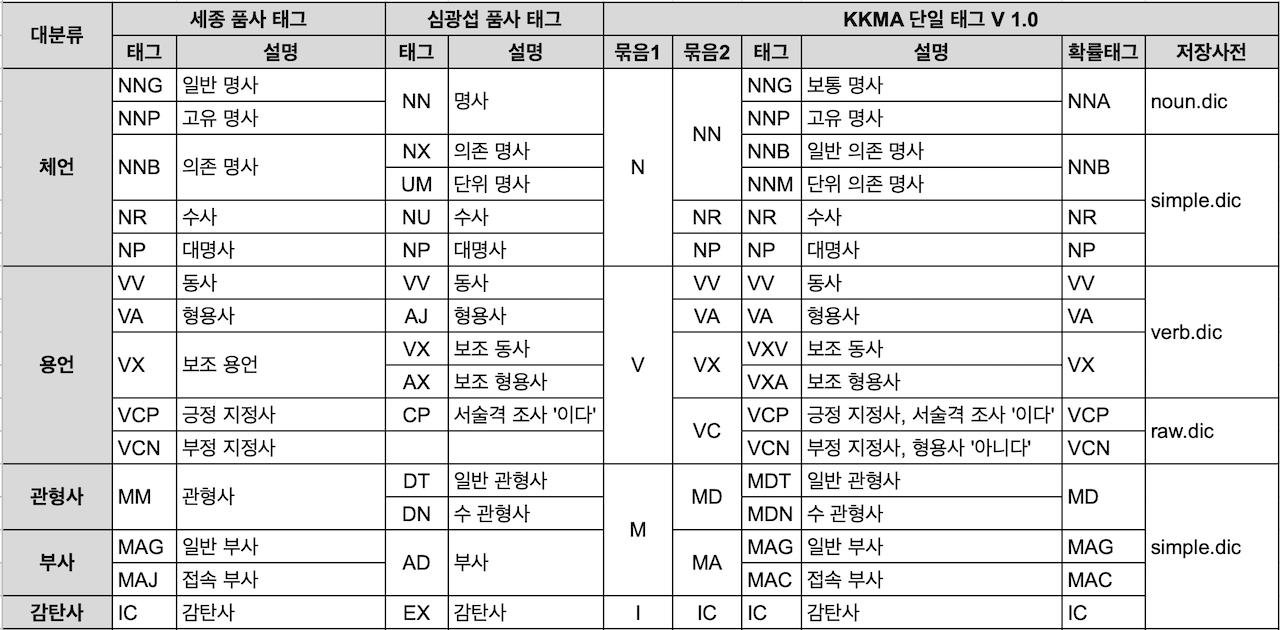
stoptags의 default options
"stoptags": [
"E", "IC", "J", "MAG", "MAJ",
"MM", "SP", "SSC", "SSO", "SC",
"SE", "XPN", "XSA", "XSN", "XSV",
"UNA", "NA", "VSV"
]마무리
편리한 검색 기능을 만들고 싶다는 꿈을 위해 공부하면서 느낀 점이 있다.
사실 편리하게 살고 싶은 사람은 누구보다 부지런할 수밖에 없다는 것이다.
편리한 검색 기능을 위해서는 구현할 줄 알아야 하니까 많은 기술을 알아야 하고, 한글 검색을 위해서는 문장을 효율적으로 분석하는 것에 고민하기 위해 한글도 잘 알아야 한다. 원하는 형태로 분리해서 필요한 것만 활용할 줄 알아야 하니까.
진짜 쉽지 않다.
그런데 공부를 할수록 내가 원하는 것을 이룰 수 있을 것 같다는 기분이 들어서 재미있다.
