Elasticsearch를 공부하는 과정에서 당장 궁금했던 부분만 학습하고 사용했더니 전체적으로 어떤 방식으로 데이터를 저장하고 텍스트를 분석하는가에 대한 흐름 이해가 부족한 것 같아서 정리하기로 했다.
내가 이해한 방식으로 문장을 재구성하는 것이 확실히 공부할 수 있는 방법인 것 같아서 Elasticsearch가 데이터를 생성하고 텍스트를 분석하는 과정을 옮겨 적었다.
역 인덱스(Inverted Index)
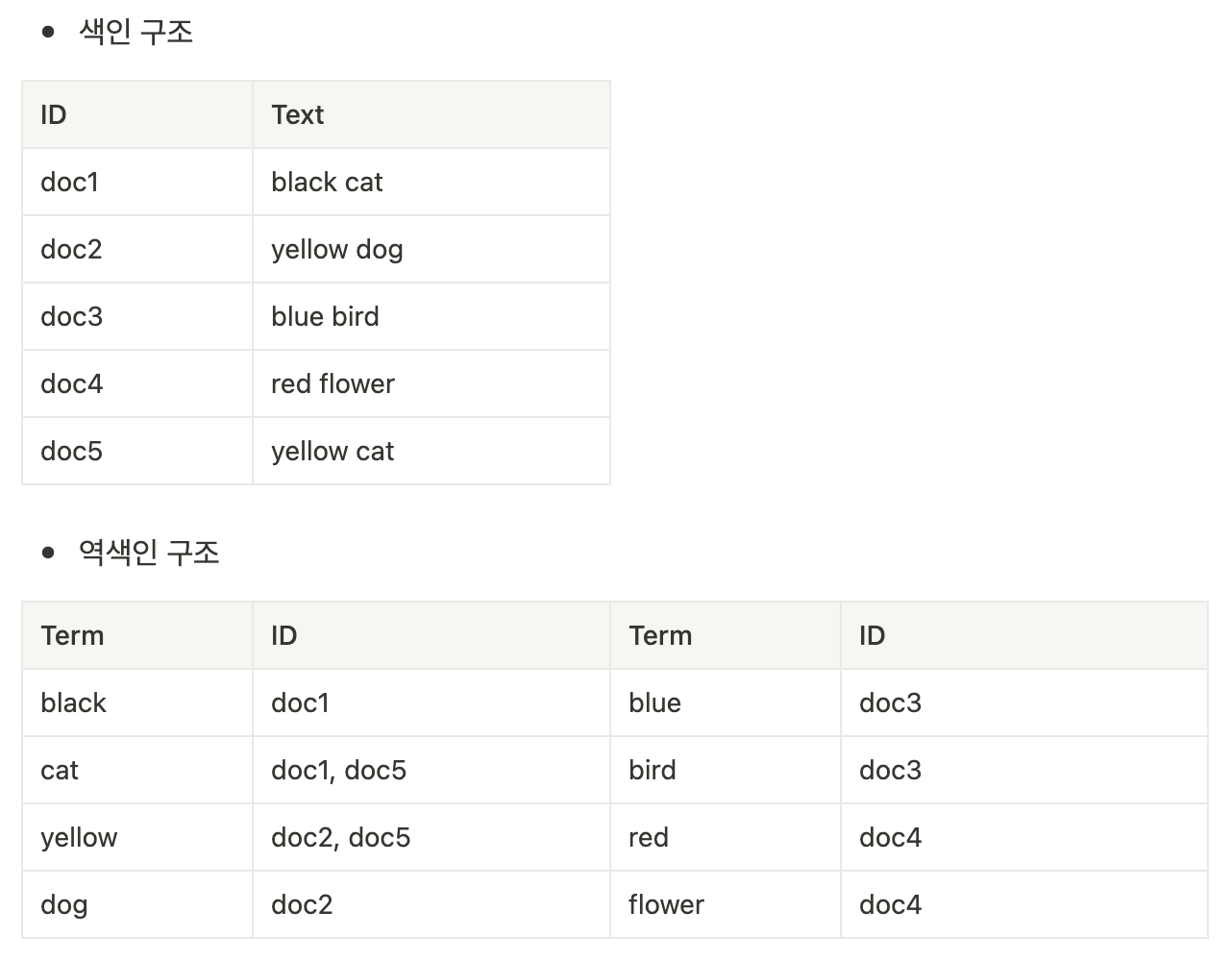
Elasticsearch에서는 추출된 각 키워드를 term이라고 부르는데, 추출된 키워드를 이용하여 역 인덱스라는 구조를 만들어 데이터를 저장한다.
역 인덱스 구조는 term이 존재하는 도큐먼트의 ID를 배열 형식으로 저장한다.
역 인덱스가 있으면 키워드가 존재하는 도큐먼트의 ID를 바로 얻을 수 있다.
Elasticsearch에서는 데이터가 늘어나면 역 인덱스가 가리키는 ID의 배열 값이 추가되는 형식이라 큰 속도 저하 없이 빠른 속도로 검색이 가능하다.
데이터를 저장하는 과정에서 역 인덱스를 만들기 때문에 데이터를 입력할 때 색인한다고 표현한다.
텍스트 분석(Text Analysis)
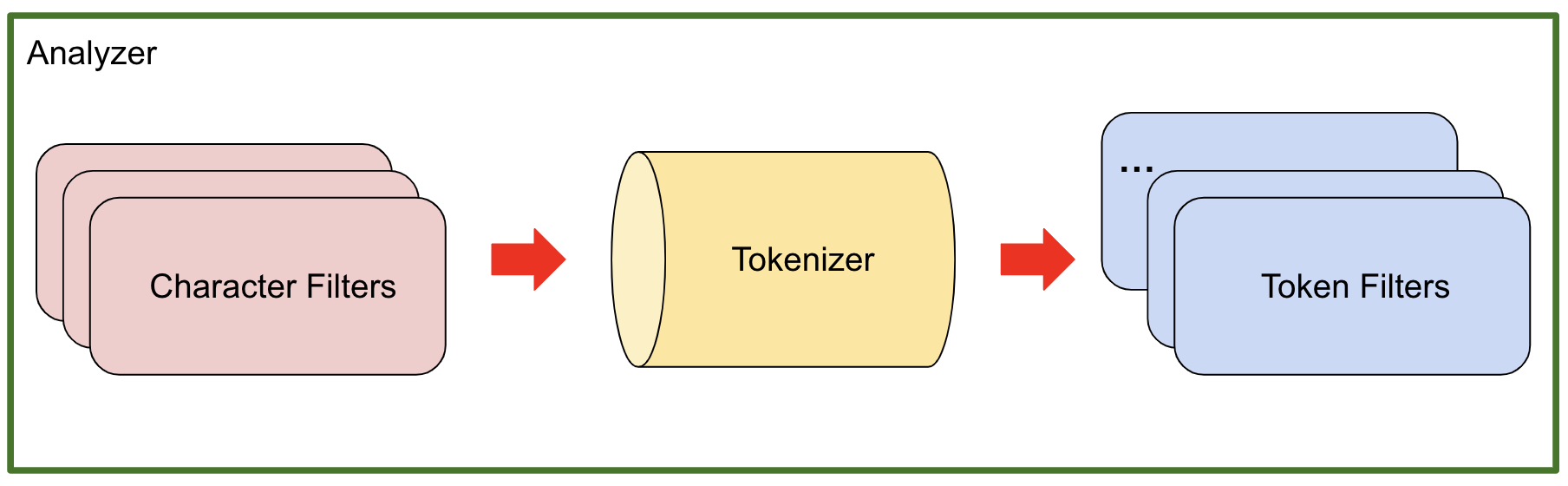
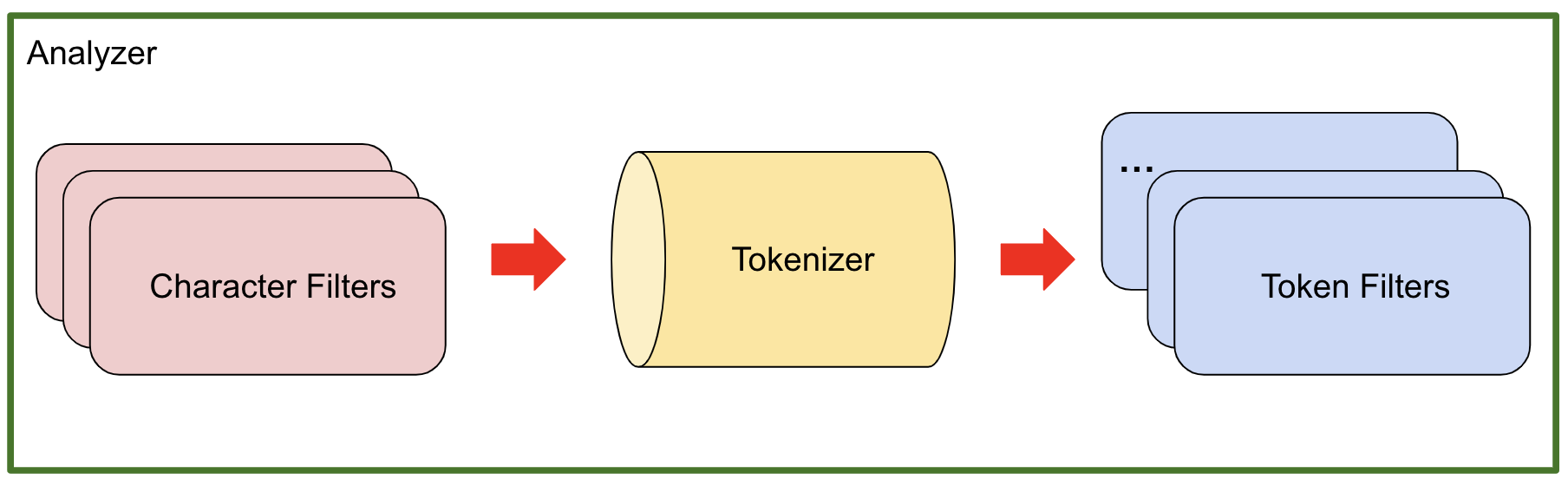
Elasticsearch에 저장되는 도큐먼트는 모든 문자열(text) 필드 별로 역 인덱스를 생성한다.
문자열 필드가 저장될 때 데이터에서 검색어 토큰을 저장하기 위한 처리 과정을 거친다.
이 과정을 텍스트 분석이라고 하고, 이 과정을 처리하는 것을 분석기(Analyzer)라고 한다.
분석기는 0~3개의 캐릭터 필터, 1개의 토크나이저, 여러 개의 토큰 필터로 구성할 수 있다.
캐릭터 필터(Character Filter)
텍스트를 개별 토큰화하기 전에 텍스트 데이터의 전체 문장에서 특정 문자를 대치하거나 제거하는 것처럼 문장을 특정한 규칙에 의해 수정하는 과정을 담당한다.
HTML 태그를 제거하거나, 특정 단어를 치환하거나, 정규식을 이용해서 복잡한 패턴을 치환한다.
토크나이저(Tokenizer)
문장에 속한 단어들을 term 단위로 분리하는 처리 과정을 담당한다.
토크나이저는 반드시 하나만 적용할 수 있다.
공백, 특수문자, 숫자를 이용하여 해당 조건을 적용한 방식으로 토큰 분리할 수 있다.
토큰 필터(Token Filter)
분리된 term을 지정한 규칙에 따라 하나씩 가공하는 과정을 처리한다.
토큰 필터를 사용해서 대문자를 소문자로 바꿔서 대소문자 구분 없이 검색 가능하게 만들거나, 검색어로서 가치가 없는 불용어를 제거하거나, quick이라는 term에 fast라는 동의어를 지정해서 같은 의미를 포함한 도큐먼트를 검색할 수 있게 만든다.
형태소 분석(Stemming)
검색할 때 문법에 따른 단어 변형에 구애받지 않고 검색할 수 있도록 텍스트 데이터를 분석할 때 term 단어의 기본 형태인 어간을 추출하는 역할을 한다.
한글 형태소를 분석하기 위해서는 nori라는 플러그인을 이용하여 토크나이저와 토큰 필터를 사용할 수 있다.
내 프로젝트에 응용하기
현재 Spring Boot를 공부하며 구현하고 있는 MyCafe의 엔티티를 Elasticsearch로 처음부터 다시 구현한다면 어떤 것들에 대한 고민이 필요할지 생각해 봤다.
인덱스 설정(Setting)과 매핑(Mapping)
인덱스를 생성할 때 설정(Setting)정보에 대해 작성할 수 있는데 analyzer, tokenizer, token filter에 대한 정보도 설정할 수 있다.
또한 인덱스의 매핑(Mapping)정보를 미리 정의하면 정의한 매핑에 맞추어 데이터가 입력된다. 나는 이전에 Elasticsearch를 사용하면서 매핑 정보에서 도큐먼트 엔티티의 Field Type에 대해 무지한 상태로 text 또는 keyword로 선언하여 생성하는 실수를 했다.
고려하고 있는 항목
- 한글 형태소 분리를 위한
nori_tokenizer사용한다. 아아,아아메와 같은 줄임말 검색어로아이스 아메리카노라는 결과를 얻으려면 어떤 설정이 필요할까?차가운=아이스,뜨거운=핫처럼 메뉴 온도에 따른 동의어 설정이 필요할 수도 있겠다.- 메뉴 도큐먼트 엔티티를 어떻게 구성해야 할까?
4-1. 카테고리 이름을 검색했을 때, 해당 카테고리에 포함되는 메뉴가 나오는 방법도 구현이 필요할까?
4-2. 필요하다면 메뉴 도큐먼트 엔티티는 카테고리 ID와 카테고리 이름을 모두 가지는 구조로 사용해야 할까?
구체적으로는 조금 더 생각할 필요가 있지만, 이런 항목들을 고려한 후에 인덱스를 생성하고 도큐먼트를 추가해야 한다.
데이터 모델은 당장 눈에 보이는 값뿐만 아니라 앞으로 사용할 용도를 고려한 구조를 만들어야 한다는 점에서 정답이 없다고 생각하는데, 정답이 없다는 점이 어렵고 재밌는 것 같다.
마무리
Elasticsearch를 이용해서 데이터를 색인(=저장)하고 가공하는 과정에 대해 정리하면서 데이터 가공 절차와 구조에 대해 이해할 수 있었다. 그리고 이러한 과정을 통해 검색을 위한 인덱스를 설정하고, 생성할 도큐먼트 엔티티에 대해 고민하는 시간을 가졌다. 조금 더 구체적으로 설정에 대해 고민하고 적용한 인덱스를 생성한다면, 효과적인 검색 기능을 구현할 수 있을 것이라고 생각한다.
