문제 상황
발생한 문제
데이터를 수집할 때, 많은 시간(대략 8시간) 소요
문제의 원인
- 짧은 시간, 많은 요청
데이터 크롤링을 반복하는 과정에서, 짧은 기간 내에 요청을 반복했더니 사이트에서 접근을 차단했다.
접근 차단을 회피하기 위해서 일정 간격을 두고 time.sleep()을 주었는데, 이로 인해 전체적인 프로세스를 완료하기까지 많은 시간이 소요되었다.
- 동기 방식
처음으로 직접 데이터를 수집하고 가공하여 적재하는 업무를 하게 되어서, 아무것도 모르는 상태로 데이터 수집 과정을 구현했다.
시간을 단축하기 위한 방법을 찾다가 많은 네트워크의 요청 또는 크롤링에서는 비동기 방식을 활용하여 유연하고 빠르게 데이터를 수집할 수 있다는 것을 알게 되었다.
비동기로 데이터 수집하기
데이터 수집은 다음과 같은 순서로 이루어졌다.
(1) 데이터 1차 수집
(2) 1차 데이터 기반 2차 데이터 수집
(3) 데이터 가공
(4) DB INSERT
여기서 데이터를 순차적으로 가공하고 적재하는 (3), (4) 과정은 기존의 동기 방식을 이용하고, 순서와 상관없이 데이터를 수집하는 (1), (2) 과정은 비동기 방식을 이용하기로 했다.
비동기 모듈 사용하기
import asyncio
import aiohttp비동기로 작업을 처리하기 위해서는 asyncio를 사용하고, 비동기 네트워킹으로 데이터를 수집하기 위해서는 aiohttp를 사용한다.
발생한 오류
🚨 HTTPSConnectionPool: Max retries exceeded with ~
비동기 메소드를 구현하고 데이터를 수집하다가 마주한 오류이다.
서버가 일정 시간 동안 응답하지 않거나 네트워크 문제로 요청에 실패할 때 발생하는데, 요청을 재시도할 수 있도록 retries를 이용했다.
async def get_data(session, max_retries=5, retry_delay=2):
retries = 0
while retries < max_retries:
try:
async with session.get(url, params=params, headers=headers, timeout=10) as response:
response.raise_for_status() # HTTP 에러 발생 시 예외 발생
return await response.json() # JSON 응답 처리
except (ClientError, asyncio.TimeoutError) as e:
print(f"Error: {e}")
retries += 1
if retries < max_retries:
print(f"Retrying ({retries}/{max_retries}) after {retry_delay} seconds...")
await asyncio.sleep(retry_delay) # 재시도 전에 지연
else:
print(f"Failed to get data")
return None # 실패 시 None 반환비동기로 데이터 수집할 때, 요청에 실패한다면 max_retries까지 재시도한다.
요청에 실패한 경우에는 다음 요청을 보내기 전에 retry_delay만큼 asyncio.sleep()을 사용한다.
이 방법으로 첫 요청에 실패할 경우에 바로 프로세스를 종료하지 않고, 다시 요청을 시도해서 데이터를 무사히 수집했다.
요청에 실패할 때, 많게는 3~4회 정도의 재시도를 통해 데이터를 수집할 수 있었기 때문에 재시도는 최대 5회까지로 작성했다.
🚨 ValueError: too many file descriptors in select()
요청 재시도 코드를 추가한 상태로 데이터를 수집하다가 마주한 오류이다.
동시에 너무 많은 파일 디스크립터(소켓 등)를 열었을 때 발생하는 문제로 대규모 비동기 요청에서 나타나는데, 멀티프로그래밍 환경에서 공유된 자원에 접근하는 방법인 Semaphore를 이용해서 문제를 해결할 수 있었다.
semaphore = asyncio.Semaphore(100)먼저 비동기 작업에 사용할 세마포어를 선언했다.
처음에는 100개로 선언했는데, 100개의 세마포어를 사용했을 때 동일한 오류가 발생해서 이후에는 50~80개 정도로 사용했다.
async def get_data(session, semaphore, max_retries=5, retry_delay=2):
retries = 0
async with semaphore: # 세마포어 사용하여 동시 요청 수 제한
while retries < max_retries:
try:
async with session.get(url, params=params, headers=headers, timeout=10) as response:
response.raise_for_status()
return await response.json()
except (ClientError, asyncio.TimeoutError) as e:
print(f"Error fetching {url}: {e}")
retries += 1
if retries < max_retries:
print(f"Retrying ({retries}/{max_retries}) after {retry_delay} seconds...")
await asyncio.sleep(retry_delay)
else:
print(f"Failed to get data")
return Noneasync with semaphore를 추가하여 동시 작업 수에 대해 제한했다.
🚨 원격 호스트에 의해 강제로 끊겼습니다.
비동기 방식을 도입하여 작업 속도를 개선하고 세마포어를 사용하여 작업 요청에 대한 제한 문제를 해결했는데 또 다른 연결 끊김 문제가 발생했다.
원격 호스트에 의해 강제로 끊어지는 문제는 해당 사이트에서 접근하는 사용자가 기계라고 인식하여 접근을 제한할 때 발생한다.
접근자가 일반 사용자임을 증명하기 위해서는 User-Agent값에 변동을 주어 문제를 해결할 수 있었다.
headers = {
'User-Agent': 'Mozilla/5.0 ... '
}기존에는 하나의 User-Agent 값을 사용하여 모든 요청을 반복했는데, 강제 연결 종료 문제를 해결하기 위해서는 아래와 같이 변경했다.
import random
agent_lst = [
"user-agent-value 1",
"user-agent-value 2"
...
]
headers = {
'User-Agent': random.choice(agent_lst)
}User-Agent는 HTTP 요청을 보낼 때 해당 요청을 보내는 디바이스나 브라우저 등의 정보를 가지고 있다.
따라서 하나의 User-Agent를 모든 요청에 사용한다면, 결국에는 한 사람이 대량의 데이터를 요구하는 것이므로 사이트는 기계라고 판단하게 된다.
그래서 User-Agent 값을 여러 개 사용하는 방법을 생각했다.
여기서 Fake User, 가상의 User-Agent를 여러 개 생성하여 사용하는 방법이 있다.
Fake User를 생성하면 브라우저 정보 또한 랜덤으로 생성한다. 브라우저 정보가 랜덤일 경우, 요청할 사이트에서 지원하지 않는 브라우저 사용자 정보가 생성될 수 있다는 문제가 있다.
나는 매번 가상의 유저를 생성할 정도의 규모가 아니고, 브라우저 예외 처리를 하는 것보다 테스트 과정에서 접근에 문제가 없었던 유저 정보를 활용하는 것이 당장 문제를 해결하는 것에 더 빠르다고 생각해서 Fake User를 생성하는 방법은 사용하지 않았다.
마무리
데이터 수집 소요 시간을 줄이기 위해 비동기 방식을 도입하고, 접근 제한 오류를 해결하면서 데이터를 원활하게 수집하는 방법에 대해 조금 더 배울 수 있었다.
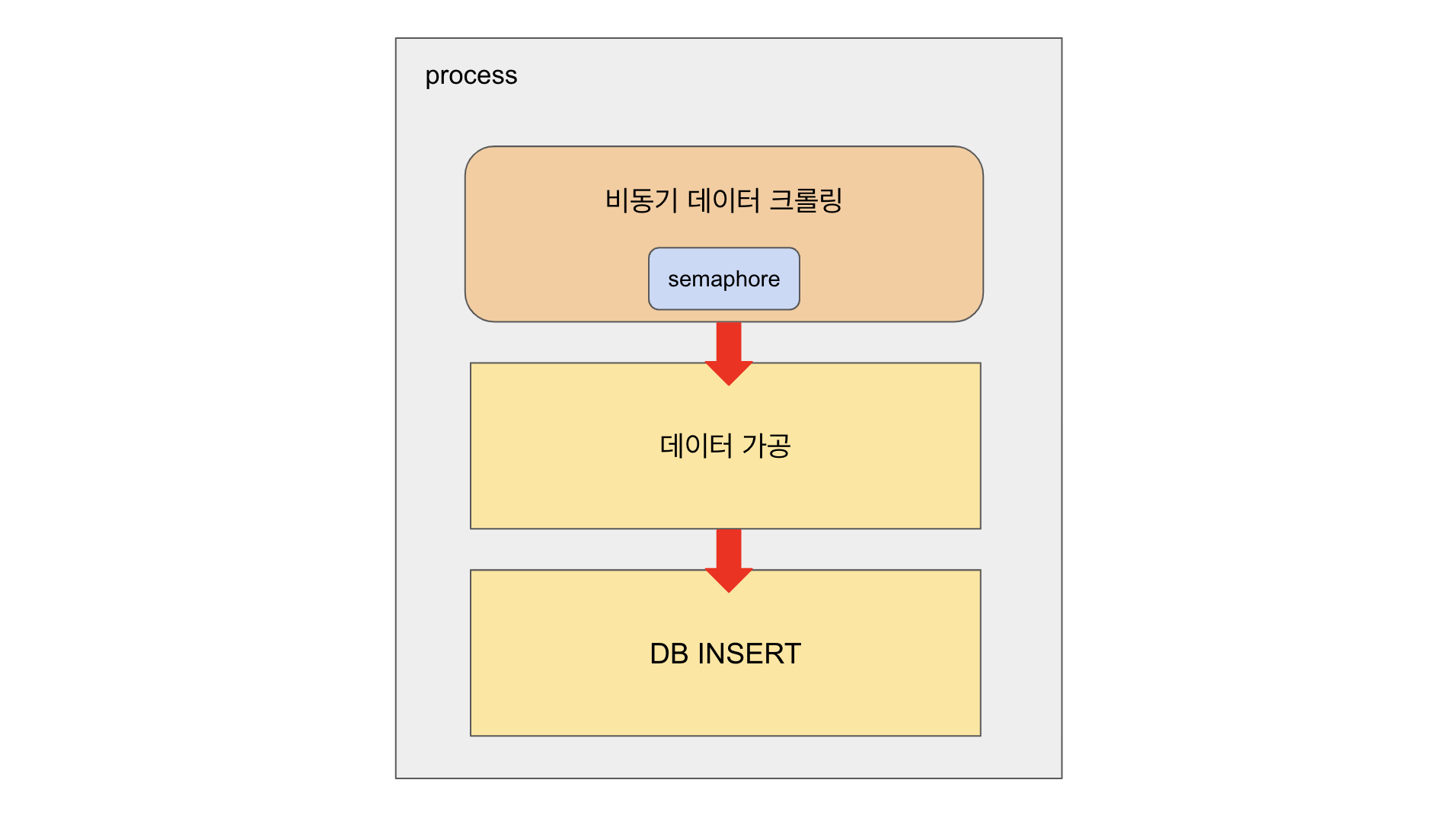
결과적으로 데이터 수집 프로세스는 위와 같이 비동기 수집과 동기 가공, 적재로 수정했고 이를 통해 데이터 수집 소요 시간을 8시간에서 40분 대로 단축할 수 있었다.
서비스를 구현하기 위해서는 데이터가 필수적인 요소라고 생각해서 데이터를 다루는 일에 관심을 가지게 되었는데, 서비스에서 활용할 수 있도록 데이터를 직접 수집하고 가공하는 과정을 경험할 수 있어서 흥미로웠다.
