물리적 메모리의 주소변환은 운영체제가 관리하지 않는다
하지만 가상메모리 기법은 운영체제가 관여
디맨드 페이징

요청이 있을 때 페이징을 메모리에 올린다
- 페이징기법 사용한다고 가정 (대부분이 페이징 사용)
- 한정된 메모리 공간에 의미있는 것을 올려놓자
- 효과
- I/O 양이 줄어든다
- 필요한 것만 메모리에 올릴 수 있다
물리적 메모리 사용량 감소,
현대의 멀티 프로그래밍 환경에서 더 많은 사용자가 동시에 메모리에 올라가서 효과적,
빠른 응답 시간 기대
유효 무효 비트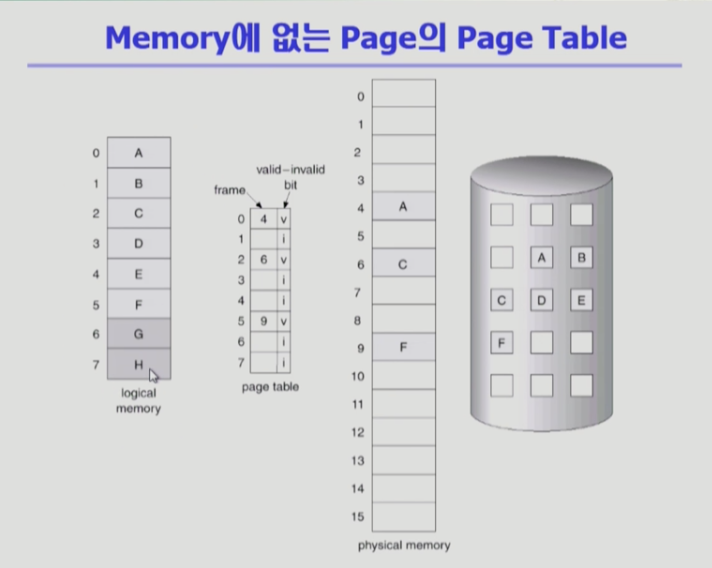
- valid / invalid bit
- 장표에 여러 개 페이지, 페이지 테이블, 주소 변환, 스왑 에리어 존재
- 당장 필요한 부분은 디멘드 페이징에 의해 메모리에 올라가있고 그렇지 않은 부분은 스왑 영역에 내려가 있다
* invalid bit- 물리적 메모리에 페이지가 없는 경우
- 사용하지 않는 주소 영역인 경우 (스왑 영역)
- 사용하지 않는 주소 영역이 있더라도
페이지 테이블 엔트리는 주소공간 크기만큼 만들어지고 invalid로 표시- G, H가 사용안되는 페이지라면 만들어진 후, invalid로 표시
- 프로그램 최초로 실행시키면 처음에 invalid >
메모리에 올라가면 invalid로 표시됐던 비트가 valid로 바뀌면서 해당 페이지 번호가 엔트리에 적힌다
* 주소 변환할 때 invalid면 메모리에 해당 페이지가 없다는 의미 > 디스크에서 메모리로 올리는 I/O 작업 해야함
- 페이지 폴트 현상 발행
- 요청한 페이지가 메모리에 없는 경우를 말한다
CPU는 자동적으로 운영체제에 넘어간다 (일종의 트랩)
운영체제가 CPU를 가지고 메모리에 다시 폴트가 발생했던 페이지를 올린다
- 요청한 페이지가 메모리에 없는 경우를 말한다
페이지 폴트
- invlid로 표시된 페이지 접근하면 하드웨어가 트랩을 발생시킴
- CPU가 자동적으로 운영체제로 넘어가서 페이지 페이지 폴트 핸들러 시작
- 잘못된 요청이 아닌지 확인 후,
정상적 요청이면 디스크에서 메모리로 올려야 한다- 메모리 꽉차있으면 페이지를 하나 쫓아내야한다
- 쫓아내서 빈 페이지 획득됐다면 디스크에서 페이지를 메모리로 올린다 (느린 작업)
디스크 I/O 작업을 하게되면 CPU를 가지고 있어봐야 낭비 >
페이지 폴트가 발생했어도 CPU 뺐어서 블락을 만들어주고 당장 사용할 수 있는 레디 프로세스한테 넘겨준다 >
페이지 읽어오라고 부탁 >
I/O 작업 끝나게 되면 인터럽트가 걸려서 페이지 처리 끝났구나 확인 > 다시 valid 표시 >
CPU를 다시 잡게 되면 정상적으로 러닝
페이지 폴트 핸들링 단계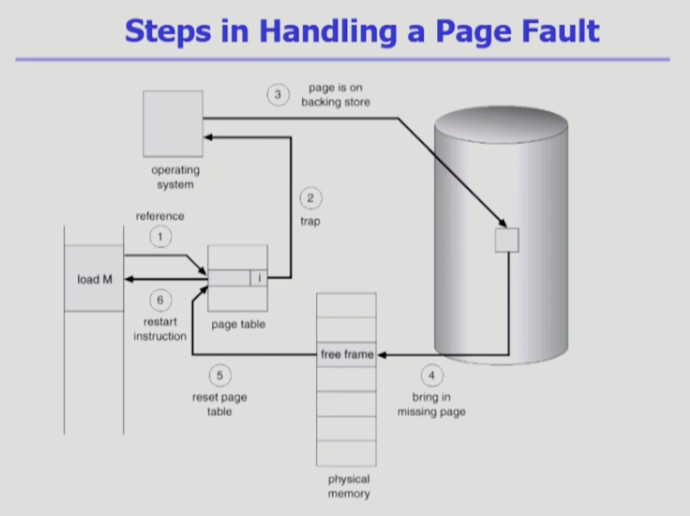
주소변환 하려고했더니 invalid >
CPU가 운영체제로 넘어감 >
운영체제는 스왑영역에 있는 페이지를 물리적 메모리로 올린다 >
올려놨으면 해당 프레임 번호를 엔트리에 적고 valid로 변환 >
그 다음 CPU를 얻어서 주소 변환할 수 있다
디맨드 페이징 성능
페이지 폴트가 났을 때 디스크 접근 작업은 오래 걸린다
- 페이지 폴트가 0이면 모두 메모리에서 참조할 수 있는 경우
- 페이지 폴트가 1이면 매번 폴트 발생(페이지 부재)한 경우
대부분 경우에는 페이지 폴트가 나지 않는다
메모리 접근 시간을 폴트 시간까지 생각해서 계산
(1-p)는 페이지 폴트가 나지 않는 비율
p 는 페이지 폴트가 나는 비율 => 엄청 많은 시간이 걸린다 (거의 0에 가까움, 폴트 비율이 많이 없음)
- 폴트 났을 때 여러 오버헤드
- 운영체제로 CPU가 넘어가서 처리하는 오버헤드
- 메모리 공간 없으면 쫓아내는 것
- OS가 valid로 포함하는 작업 끝나고 다시 시작하게 되는 경우
빈 페이지가 없는 경우
- 페이지 교체
- 빈 페이지 없을 때 쫓아내는 것 (OS가 하는 영역)
- 나중에 쫓아내고 다시 참조되면 시간 오래걸린다
- 시간 순서에 따라 페이지에 다른 번호 붙이고 참조된 순서를 붙인 reference string
- 여기서 참조해서 쓸 수 있다

어떤 것 쫓아낼지 결정 후 디스크로 쫓아낸다
- 메모리로 올라온 이후에 내용 변경된 내용이 있다면( write 됐다고 하면) 백킹 스토어에 써야 한다
- 쫓아내고 새로운 페이지 올려야 한다
- 쫓아낸 페이지애 대한 테이블 엔트리 invalid로 변경
- 올라온 페이지는 프레임 번호를 엔트리에 적어주고 비트를 valid로 변경
- 위 역할을 운영체제가 하게 된다
최적 알고리즘
- 어떤 알고리즘이 좋은 알고리즘?
- 페이지 폴트 가장 적게하는 알고리즘
* 미래 참조 페이지를 미리 안다고 가정 - 오프라인 옵티멀 알고리즘
- 페이지 레퍼런스 스트링을 알고있다는 가정 하에 운영하기 때문에 저렇게 부른다
- 페이지 폴트 가장 적게하는 알고리즘
- 가장 먼 미래에 참조되는 페이지 쫒아낸다
- 상황
- 1번이 메모리에 올라오고 2, 3, 4 마찬가지
- 1번은 메모리에 올라와있기 때문에 폴트 나지 않고 직접 참조
- 빨강은 폴트 난 경우
- 연보라색은 메모리에 올라와 있어서 직접 참조된 경우
- 5번 요청했을 때 없어서 페이지 폴트
- 하나 쫓아내야 한다
- 옵티멀은 가장 먼미래에 참조되는 페이지 쫓아냄
- 1번은 5번 바로 다음에 참조, 2번은 다음에 참조, 3번은 그 다음에 참조, 4번이 4개 중에 가장 먼 미래에 참조될 예정
- 5번 메모리 보관하기 위해 4번 쫓아내고 5번 집어넣는다
- 총 6번의 페이지 폴트 발생
- 어떤 알고리즘 이더라도 6보다 적을 수 없다
- 실제 사용되는 알고리즘의 upper 바운드 제공
- 아무리 좋아도 이것보다 더 좋을 수 없다
오프라인 옵티멀 알고리즘과 성능 비슷하다면 더 좋은 알고리즘 만들 수 없다- 빌래디가 만들었고, 적어서 MIN, 줄여서 OPT
- 아무리 좋아도 이것보다 더 좋을 수 없다
FIFO 알고리즘
미래 모르는 상태에서 운영하는 알고리즘
가장 먼저 들어온 것을 쫓아낸다 (이후 또 사용이 됐더라도)
- 미래 모를 때 제일 참고할만한 중요한 단서는 과거
- FIFO
(선입선출)- 페이지 프레임 3개, 4개인 경우의 예시
- 특이한 점
- 메모리 크기 늘리면 보통 성능이 좋아야 하는데 안좋아짐 (페이지 폴트가 올라가서)
- 피포 아노멀리. 기묘한 현상
메모리 프레임 늘려줬는데 성능 더 나빠지는 현상
LRU 알고리즘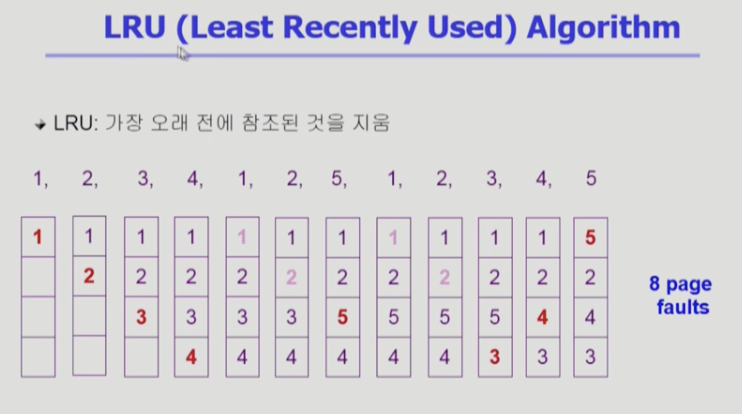
가장 많이 쓰는 알고리즘
오래전에 사용된 것을 쫓아낸다
- 처음 1, 2, 3, 4 에서는 어쩔 수 없이 페이지 폴트 발생 >
1, 2는 이미 올라와있어서 직접 참조 >
5를 보관하기 위해 하나 쫓아내야 하는데 가장 오래 전에 사용된 3번을 쫓아내고 5번을 집어넣음 - 비교적 페이지 폴트 줄일 수 있다
LFU 알고리즘
가장 덜 빈번히 사용된 것을 쫓아낸다
- 참조 횟수가 가장 적은 알고리즘을 메모리에서 쫓아낸다
- 과거에 참조 많았으면 미래에도 참조할 가능성 높다
- 참조가 동률인 페이지 중에서는 마지막 참조시점이 더 오래된 것을 쫓아낸다

페이지 레퍼런스 스트링 주어짐
페이지 프레임은 4개
오른쪽은 언제 참조되었는지에 대한 것
1번이 4차례 참조 2번이 2번 3번이 2번 ... 참조
5번 참조되니까 4개 중 하나 쫓아낸다
LRU는 1 쫓아냄
=> 마지막 참조시점만 본다, 참조 횟수는 많아도 고려하지 않는다
LFU는 제일 참조횟수가 적은 4번 쫓아냄
=> 막 참조 시작되는데도 불구하고 쫓아낸다
LRU & LFU 알고리즘 구현 방식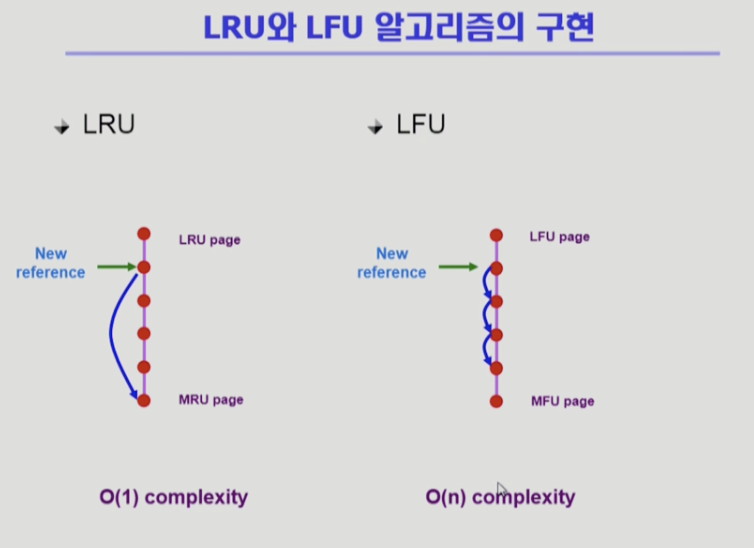
- LRU
- 메모리 안의 페이지를 시간 순서에 따라 줄세운다
- 맨위가 가장 오래전에 참조됨
- 참조 시점이 가장 최근이면 제일 아래쪽으로 보낸다
- 쫓아낼 때는 제일 위의 것을 쫗아낸다
- O(1)
- 쫓아내기 위해 비교 필요 없다 (아래 놓고 위를 쫓고) > 효율적
- 만약 시간 기록해놓으면 페이지 개수가 n개라고 하면 n개의 시간을 다 비교하고 쫓아낸다 > 비효율적
- LFU
- 가장 참조횟수가 적은 페이지가 맨 위,
밑으로 내려갈수록 참조횟수가 많은 페이지 - 쫓아낼 때는 참조횟수 적은 페이지를 쫓아낸다
- 사실 한 줄 줄세우기 할 수 없다
- 비교해서 어디까지 내려갈 수 있는지 확인해야 한다 (누가 참조횟수가 더 많은가)
- 가장 참조횟수가 적은 페이지가 맨 위,
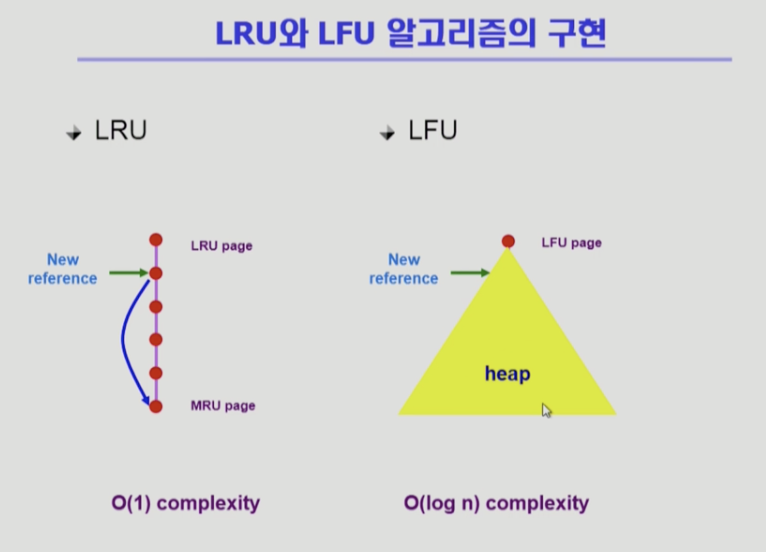

- 따라서 LFU는 자료구조 시간에 배운 힙을 이용해 구현
- 힙은 자식이 두 개 씩 있는 이진트리
- 맨 위는 참조횟수 적은 페이지
- 아래로 갈수록 횟수 많은 페이지
- 직계자식과 비교해서 많으면 아래로 내려간다
- 전체가 N개면 비교횟수가 이진트리는 높이가 log n
- 쫓아낼 때는 루트 쫓아내고 힙 재구성 하면 된다
- 힙은 자식이 두 개 씩 있는 이진트리
다양한 캐슁환경
교체 알고리즘은 컴퓨터 시스템의 다양한 환경에서 사용된다 > 캐슁
캐슁
빠른 공간(캐쉬)에 무엇을 보관하고 무엇을 쫓아낼 것인가
- 물리적 메모리가 빠른공간 / 디스크 백킹 스토리가 느린 공간
- 빠른 공간은 개수가 한정되어 있음
- 캐쉬메모리가 빠른 공간에 해당 / 메인 메모리가 느린 공간
* 버퍼 캐싱- 파일 시스템에서 한정된 빠른 공간에 보관해서 다음에 다시 요청했을 때 재사용 빠르게 함
- 페이징 시스템과 버퍼 캐싱은 물리적 매체가 같다
- 빠른 공간이 메모리, 느린 공간이 디스크
- 페이징 시스템에서는 느린 공간이 스왑 영역, 버퍼에서는 디스크의 파일 시스템이라는게 차이점
- 둘다 빠른 공간은 메모리에 해당
* 웹 캐싱 - 하나의 컴퓨터 시스템안에서 매체 속도 차이를 완화히기 위해 쓰는 것
- 웹 캐싱은 웹브라우저에 주소 치면 들 때, 멀리 있는 서버에서 웹페이지를 읽어와서 보여주는 것
한번 받아온 웹페이지 내용 내 하드 디스크에 저장해놓고 바로 보여주는 것- 매체 속도 차이 완화가 아니라 지리적으로 떨어진 컴퓨터에서 읽어오는 시간 완화
- 캐슁 기법은 다양한 환경에서 사용되고 있다
- 꼭 지켜야 하는 시간 제약 조건
- n개 데이터 저장할 수 있다고 할 때 어떤 것 쫓아낼지 결정하는 방법은 order of n
- 하나 쫓아내려고 모든 것을 살펴보는 것은 비효율적
- 캐싱에서는 O(1)(비교 필요없음), O(logn)까지만 허용
- n개 데이터 저장할 수 있다고 할 때 어떤 것 쫓아낼지 결정하는 방법은 order of n
-
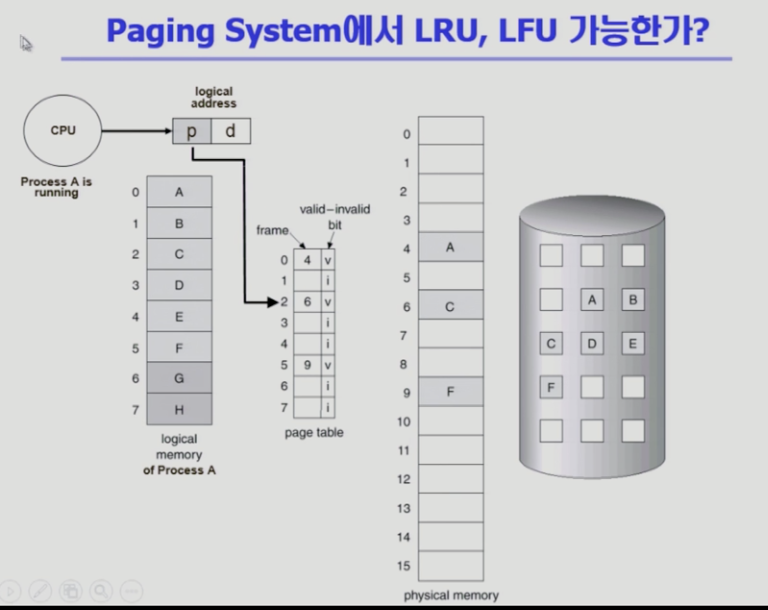
페이징 시스템에서는 실제로 알고리즘을 활용할 수가 없다
- 프로세스 A가 CPU 가지고 러닝중
- 프로그램이 메모리 참조하려면 주소변환 필요
- 이미 물리적 메모리에 올라와있다
- 이 페이지를 바로 CPU가 가지고 간다
- 중간에 운영체제가 개입하는 것이 없다
- 주소변환에서 운영체제가 전혀 개입하지 않고 하드웨어적으로 변환
- 페이지 언제 사용했는지 운영체제가 모른다
-
알고리즘 사용 위해서는 사용되는 시점을 그때그때 알아야 하는데 이미 메모리 존재하는 페이지 사용되면 시점을 알 수 없다
-
메모리에 없고 디스크(오른쪽)에 있는 경우 > 폴트가 난 경우
- CPU 제어권이 프로세스 A로부터 운영체제로 넘어감
- 운영체제가 백킹 스토리지에 있는것을 메모리에 올려놓고 언제 올려놨는지 시간을 알 수 있다
-
운영체제가 페이지 부재가 났을 때의 정보만 알고 있기 때문에 줄세우기 관리 자체가 불가능
(가장 최근에 사용됐는지 등을 모른다)
클락 알고리즘

LRU를 근사시킨 알고리즘
실제 페이징 시스템에서 사용된다
- 동작 원리
- 사각형은 메모리 안의 페이지 프레임 하나하나
- 새로운 페이지 올리기 위해 쫓아내야 한다 => 운영체제가 무엇을 쫓아낼지 결정
- 비트가 1이면 최근에 사용된 페이지(적어도 한번은 사용 됐다)
0이면 최근에 사용 안된 페이지(한바퀴 돌 동안 사용 안됐다)라는 뜻 - LRU는 가장 오래전에 사용한 페이지 쫓아냄
- 클락은 비트 하나만 가지고 쫓아낼 페이지 결정
- 0으로 표시된 페이지를 쫓아내게 된다
(가장 오래전에 사용한 페이지는 아님, 최근에 사용 안한 페이지는 맞다)
오랫동안 참조가 없던 페이지라고 판단 - 하드웨어가 비트를 바꿔준다
- 0으로 표시된 페이지를 쫓아내게 된다
- 시계바늘이 돌면서 비트가 1이면 최근 사용됐다고 판단하고 0으로 바꾸고 다음칸으로 이동
이동하면서 비트가 0이면 쫓아낸다 - 비트를 1로 바꾸는 것은 주소변환하는 하드웨어가 실행
0으로 바꾸는 것은 운영체제가 실행 - modified bit(dirty bit)
- 읽기가 발생했을 때는 레퍼런스핏만 1
- 쓰기가 발생했을 때는 레퍼런스와 modified bit 둘 다 1 (적어도 한 번 수정됐다)
modified 왜 사용?- 수정됐으면 그냥 지우는 것이 아니라 수정된 내용을 쓰고 쫓아내야 하기 때문
(디스크와 내용이 다르면 써주고 쫓아내야 한다)
- 수정됐으면 그냥 지우는 것이 아니라 수정된 내용을 쓰고 쫓아내야 하기 때문
페이징 프레임 할당
위 알고리즘들은 페이지를 쫓아낼 때 프로그램에 대한 고려를 하지 않았다
Allocation 은 프로그램 별로 얼만큼 할당할지 정하는 것
각 프로그램마다 어느 정도 페이지 프레임을 가지고 있어야 한다 (원활히 실행될 수 있는 최소 메모리 공간이 필요, 어느정도 메모리 할당이 필요)
- 이퀄 얼로케이션 : 모두 똑같이 할당
- 프로그램 얼로케이션 : 크기에 비례해서 할당
- 프라이오리티 얼로케이션 : CPU 우선순위가 높은 프로세스한테 더 많이 할당
글로벌 교체 vs 로컬 교체 
할당 개념 없이 그냥 경쟁하면서 메모리 사용할 수도 있다
- 글로벌 교체
- 프로세스한테 할당 안한다
- 가장 오래전에 사용된 페이지 쫓아낸다 > 어떤 프로세스의 페이지인지 고려하지 않는다
- 장점
- 메모리 많이 사용하는 프로그램한테 많이 할당되고 적게 사용하면 뺏긴다
필요한 쪽에 많이 줄 수 있다 - 알아서 자율적으로 할당량이 조절된다
무한경쟁
- 메모리 많이 사용하는 프로그램한테 많이 할당되고 적게 사용하면 뺏긴다
- 단점
- 특정 프로그램의 독식 가능성
- 로컬 교체
- 일단 할당하고 그 안에서 쫓아내는 것을 결정
- 알고리즘은 앞서 설명하나 것 사용
Thrashing 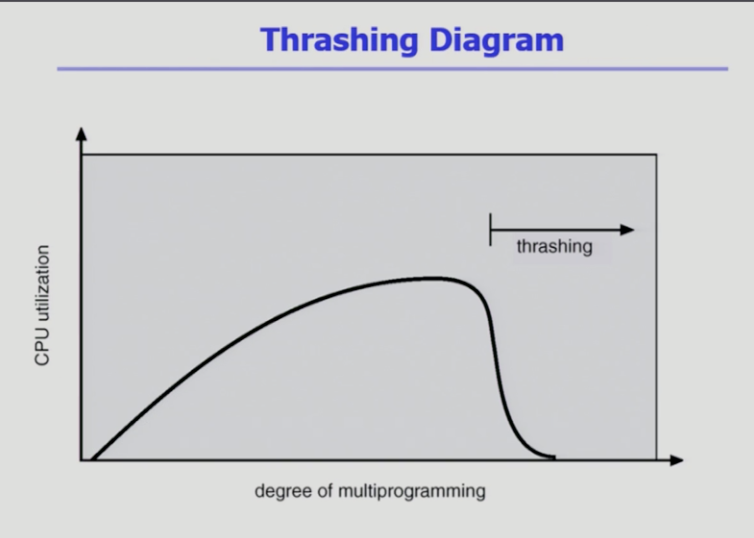
- x축
- 메모리에 올라가있는 프로그램 개수
- y축
- CPU 이용률
- 프로그램 하나만 올라가 있을 때 CPU 쓰다가 I/O 작업하러가는 동안 CPU가 놀고 있기 때문에 이용률 낮다 >
또 다른 프로그램이 쓰면 다시 올라감 >
동시에 10개를 올려놨으면 모두 I/O를 하지 않는 이상 CPU는 일할 것 > - 갑자기 뚝 떨어지는 (스래싱) 구간
- 메모리에 너무 많은 프로그램이 올라갔다
- 프로그램 원활히 돌아가는 최소한 메모리도 얻지 못한 상황
- CPU 줘봐야 페이지 부재
누구한테 줘도 페이지 폴트 발생
- CPU 이용률이 낮으면 메모리에 프로그램을 올려서 점차 올라간다
- 스래싱 막기위한 방법
- 최소한의 메모리 보장해주기
스래싱 방지 알고리즘 2가지
워킹 셋 모델
- 프로세스는 특정 시간 동안 특정 메모리 집중적으로 사용한다
- 특정 시점에 집중 사용되는 페이지 집합을 로컬리 셋이라고 한다
- 몰려서 사용되는 현상이 있다
워킹 셋 모델
한꺼번에 있어야지만 효율적으로 사용되는 페이지의 집합 - 만약 메모리 부족해서 워킹 셋이 메모리에 다 못올라가면 완전히 메모리 반납하고 스왑 아웃 (서스펜디드)
워킹 셋 알고리즘
시간 순서에 따라서 페이지 레퍼런스 스트링 나열 (특정 프로세스의 페이징)
- 워킹셋(같이 올라가 있어야 하는 페이지들)을 어떻게 알고리즘이 판단?
- 과거를 통해 추정
- 워킹 셋 보장해준다
- 과거 델타만큼의 페이지 셋을 유지한다
- 10개 유지했을 때 앞의 시점에서는 각각 다른 것만을 할당
구멍 뚫어놓고 구멍을 이동시키면서 유지해준다 - 특정 윈도우 크기 이내 페이지만을 워킹 셋이라고 간주
- 메모리가 필요한 만큼 없으면 스왑아웃시킴
- 스래싱 방지
- 워킹 셋 보장받을 수 있는 만큼만 메모리 올려놓는다
- 시간에 따라 워킹 셋이 변하고 매 시간마다 필요한 메모리 크기 보장해서 스래싱 방지
- 할당의 개념이 들어감
- 필요한 만큼 할당하니까
PFF 스킴
각 프로세스 페이지 폴트를 확인하면서
- 메모리 할당함에 따라 페이지 폴트 비율 확인
- 너무 적게 주면 페이지 폴트 나고
너무 많이 주면 적게 난다 - 어느 순간 이후에 메모리 많이 줘도 페이지 폴트 줄일 수 있는 폭이 낮아진다
- 그래프를 보고 메모리 할당량을 적절히 조절할 수 있다
- 너무 적게 주면 페이지 폴트 나고
- 더 필요할 때 메모리 여분이 없다면
전부 반납하고 스왑아웃 상태 - 올라와있는 프로세스만이라도 적당히 사용하게 해서 스래싱 방지
페이지 사이즈 결정

-
보통 페이지 사이즈 4KB
-
전체 메모리 커지면서 메모리 쪼개쓰는 페이지 크기도 4KB 바이트보다 커지는 추세
-
페이지 사이즈 감소되면
같은 논리적 메모리를 더 작게 쪼개고 페이지 테이블 엔트리도 그만큼 늘어난다
물리적 메모리에서 낭비되는 공간은 줄어든다 -
어떤 위치가 사용댔을 때 인접위치 사용될 경우가 높다 (로컬리티 측면에서 좋지 않다)
- 어느 정도 크기를 같이 읽어오면 페이지 폴트가 안나는데 필요한 것만 읽어와서 페이지 폴트 나면 디스크에 또 접근해야하니까 디스크 트랜스퍼 효율성이 감소
- 정말 필요한 것만 읽어와서 메모리 이용은 효율적이다
