물리적 메모리 관리는 다음 챕터의 가상 메모리 관리와 대비되는 측면이 있다
물리적 메모리 관리 사실 운영체제가 하는 일이 아니다
여기서 가장 중요한 것은 주소 변환(하드웨어가 함)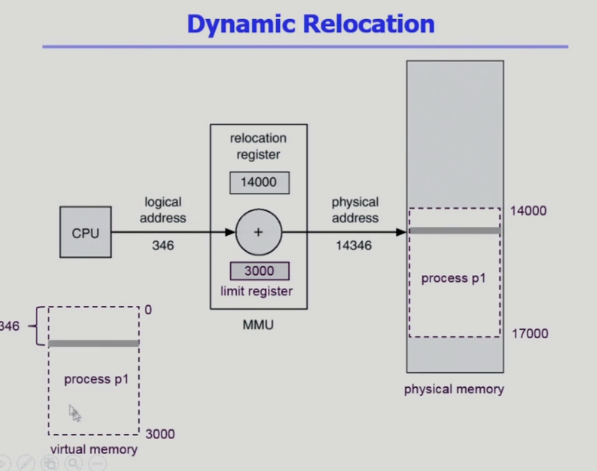
- 각 프로세스마다 논리적 메모리, 가상메모리가 있고 물리적 메모리에 올라가서 실행된다
- CPU가 각 프로세스의 논리적 주소를 가지고 메모리 내용을 달라고하면 주소변환이 되어 물리적 메모리에 접근할 수 있다
- 주소변환 과정은 전적으로 하드웨어의 역할 > 운영체제(OS)가 하는 일이 아니다
- 운영체제 통해서 하는 것은 I/O 연산과 I/O 접근
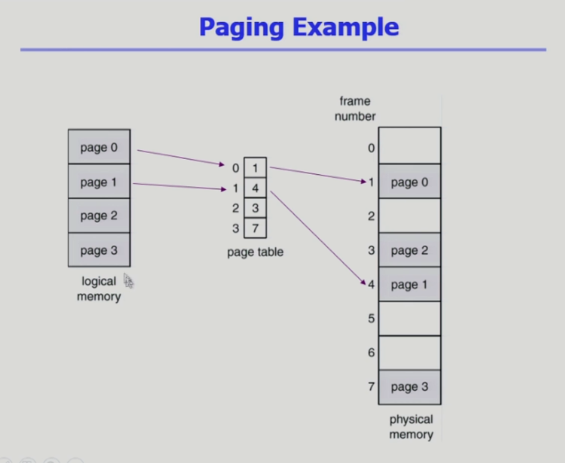
- 각각의 프로세스마다 독자적인 주소공간 논리적 메모리를 가지고 있기 때문에 주소변환 하려면 페이지 테이블도 프로세스마다 존재
- 각 프로세스 페이지 별로 주소 변환을 위한 엔트리들이 존재
2단계 / 다단계 페이징
32비트 주소체계 환경 하에서는 페이지 테이블 엔트리가 4KB 페이지를 쓴다면 1메가 개 백만개 이상의 엔트리가 존재하는 오버헤드가 존재했다
오버헤드 줄이기 위해서 다단계 페이지 기법 사용해서
안쪽 페아지 테이블(사용되지 않는 주소 영역)에 대해서 낭비되는 메모리 공간 줄였다
메모리 프로텍션
- 프로텍션을 위한 비트 : 보호나 보안을 위한 목적
페이지 테이블은 프로세스마다 각각 존재하기 때문에 주소변환 하더라도 자신의 페이지만 접근 가능 - 다른 프로그램의 페이지, 다른 프로그램의 주소공간은 접근 못하게 되는데 보호가 왜 필요한가?
프로텍션은 접근 주체에 대한 프로텍션이 아니고 일종의 접근 연산이다 (접근 권한은 그 프로세스한테 있다)
접근 권한이 아니라 접근 연산에 대한 정보를 표시하는 것이 protection bit
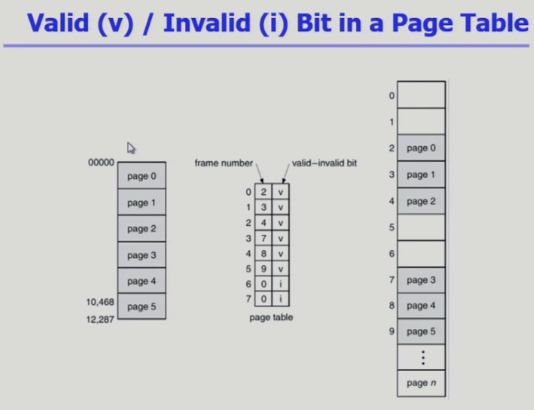
- 각각의 페이지는 프로세스 주소공간을 코드 / 데이터 / 스택으로 구성
- 코드는 함수, 기계어를 담고있다, 코드 담은 페이지는 읽기만 해야 한다
- 코드 페이지 write를 못하게 막아주는 목적으로 protection bit가 사용된다
인버티드 페이지 테이블 (역방향)
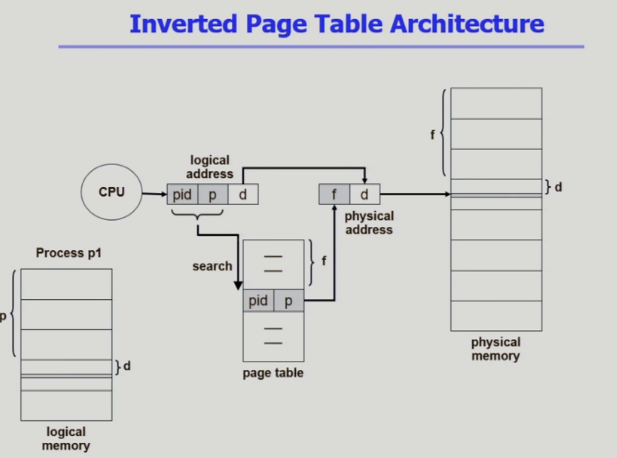
-
원래 페이지 테이블은 논리 주소로부터 물리주소를 얻는 과정
CPU가 논리주소 주면 페이지 번호에 해당하는 엔트리에 가서 페이지 p는 물리적 메모리 몇 번째 프레임에 올라가있는가- 페이지 테이블을 위한 공간 낭비가 상당히 심했다
-
인버티드 페이지 테이블은 물리적 메모리 프레임 하나하나당 페이지 테이블 엔트리가 하나씩 존재
물리적 페이지 프레임 번호를 봤을 때 f번째 엔트리에는 p가 있다
즉, 프로세스 논리적 메모리 공간에서 위에서부터 p번째에 페이지가 올라가 있다 -
인버티드는 물리적 주소를 가지고 논리적인 주소를 얻어낼 수 있는 구조
-
장점
- 물리적 메모리가 하나니까 페이지 테이블 하나만 있으면 된다
-
하지만 주소 변환 자체는 큰 도움이 안된다
주소변환은 논리적 > 물리적인 것으로 변환하는 것
인버티드는 물리적 > 논리적 주소를 알 수 있는 것
단점 2가지
-
주소 변환 이루어지는 과정
- CPU가 논리적 주소를 전달 >
p번째 페이지가 물리적 주소에서 어디 올라가 있는지 확인 필요 >
p번쩨 페이지가 몇번째 프레임에 있는지 다 찾아봐야 한다 >
p가 페이지 테이블에서 몇 번째 엔트리에 있는지 찾는다 >
만약 4번째 엔트리라면 4번째 프레임에 올라가있구나 알 수 있다
- CPU가 논리적 주소를 전달 >
-
물리적 메모리에 없다면 다 찾아도 없는 오버헤드가 생김
-
페이지 테이블 쓰는 이유는 공간 차지해도
위에서부터 p번째 엔트리로 가면 바로 주소변환이 되는 것이 장점이었다 -
인버티드는 위 장점이 없다(인덱스를 이용해서 바로되는게 아님)
-
페이지 번호 p가 논리적 페이지기 때문에 여러 프로세스마다 p번째 페이지는 각각 존재한다
- f번째 프레임에 올라가있는 페이지 p가 도대체 누구의 p번째 페이지인지에 대한 정보도 가지고 있어야 한다
사용 이유
페이지 테이블이 워낙 크고 프로세스마다 별도로 테이블을 가지고 있어서 공간 오버헤드가 심했다
물리적 페이지 프레임 하나당 엔트리를 하나씩 두기 때문에 시스템 전체에 페이지 테이블 한 개만 있어도 되는 장점이 있기 때문에 사용
주소변환하려면 전체 검색해야해서 오버헤드로인해 비효율
- 물리적 메모리에 넣어놓고 하나씩 검색해서 p번 페이지가 들어있는 엔트리 있는지 검색하는건 비효율적이다
- 모든 위치 병렬적으로 한번에 탐색하는 하드웨어를 이용해서 구현
- 한꺼번에 검색할 수 있도록 하면 메모리 공간도 줄이면서 시간도 줄인다
- 그러면 캐시가 비싼건 단점
쉐어드 페이지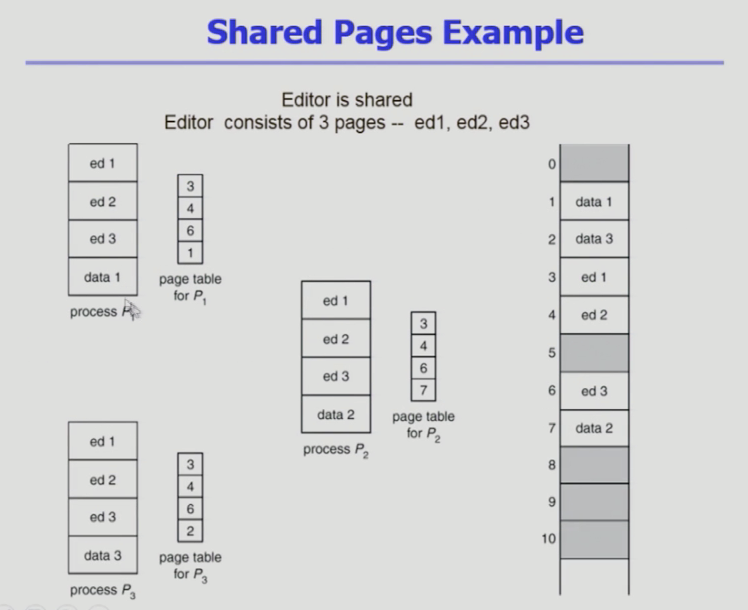
프로세스 1의 주소공간과 프로세스2의 주소공간 3의 주소공간이 있다
프로세스들이 페이징 기법을 써서 동일한 페이지로 잘려있고
주소변환을 위한 페이지 테이블이 존재(인버티드 아님)
오른쪽이 물리적 메모리
- P1의 첫 페이지는 3번 프레임이라고 페이지 테이블에 있어서 3번 프레임 확인
그런데 프로세스 3개인데 동일한 프로그램이라고 했을 때
그럼 동일 프로그램이 프로세스 3개 만들고 있으면 프로그램의 코드 부분은 같다, 데이터 부분만 다르다 - 프로세스가 다르기 때문에 동일한 코드를 물리적 메모리에 각각 올리면 동일하게 여러 개 올라가면 메모리 낭비
이를 방지하기 위해 쉐어드 코드 담는 페이지에 어차피 똑같으면 메모리에 한 카피만 올리고 공유한다

*쉐어드 메모리는 읽기와 쓰기가 다 가능한 방식
여기는 리드 온리로 되어잇는 동일한 코드 부분을 한 카피만 올리자는 것으로 완전 다른 것
쉐어드 코드
- 영어로 재진입 가능 코드, 퓨어 코드
- 쉐어드 코드의 두 가지 제약조건
- 첫번째는 리드 온리
- 3개의 페이지가 같은 물리적 위치로 맵핑이 되어잇는데 3개 페이지는 리드 온리로 세팅되어 있어야 한다
- 두번째는 3개 페이지는 동일한 논리적 주소에 잇어야 한다, 동일한 물리적 주소에는 당연히 있다(쉐어드)
- 주소공간 전체에서 같은 위치에 있어야 한다
- 페이지 번호가 같아야 한다
- 첫번째는 리드 온리
왜 이런 조건이 필요?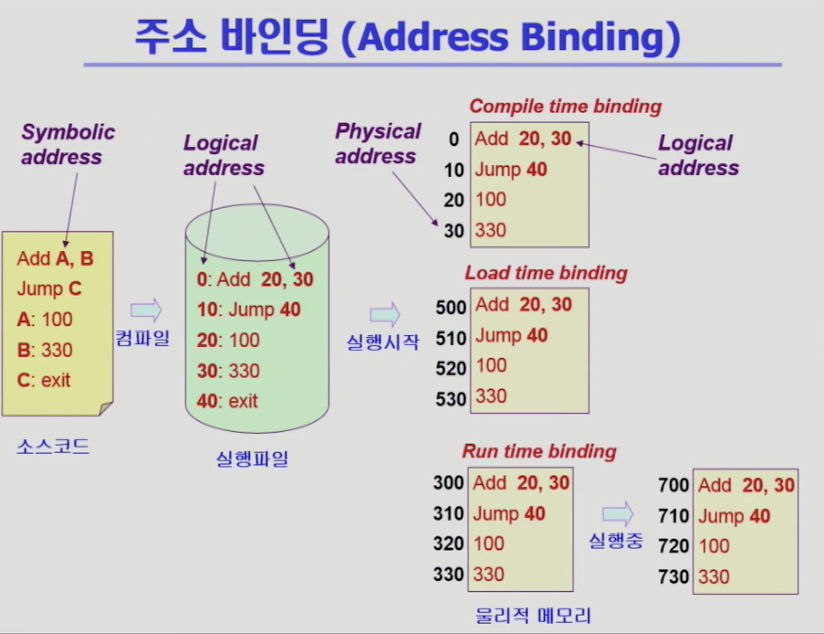
위 그림으로 이해할 수 있다
컴파일된 기계어(초록색) 자체는 물리적 메모리의 어디?
물리적 메모리에서 0번지가 500, 300에 올라가기도 하는데
기계어 내부의 논리적 주소들은 그대로 남아있다
500으로 바뀌었다고 내부의 기계어 자체 바꿀 수 없다
컴파일을 통해 어디에 올려놓을 것인가만 바꾼다
그 안의 논리적 주소도 다르면 안된다
기계어 자체가 동일하다고 하면 논리적 주소체계도 같아야 하기 때문에 이런 제약조건이 있다
각자 가지는 코드는 프라이빗 코드
- 이것도 필요
- 각자 주소변환이 되어서 다른 위치에 있는 것
불연속 할당 중 세그멘테이션 기법
페이징은 동일크기 페이지로 자른것
- 세그멘테이션은 동일 크기가 아니라 의미 단위로 잘라서 물리적 메모리의 서로 다른 위치에 올린다
- 프로세스 구성하는 주소 공간을 코드 / 데이터 / 스택이라고 하면 각 세그먼트가 존재
- 주소공간이 담고있는 의미 기준으로 자른다
- 각 세그먼트는 물리적 메모리의 서로 다른 위치에 올라가게한다
- 의미 단위로 자르면 세그먼트 크기가 다 다르다
물리적 메모리를 페이지 하나 담을 수 있는 동일 크기로 잘라서 관리 못한다(페이징과의 차이점)

- 크게는 코드 데이터 스택이 하나의 세그먼트 형성

- 주소 변환
- 앞에는 세그먼트 번호, 뒤에는 세그먼트 내에서 얼만큼 떨어져 있는지 나타내는 오프셋(페이징과 비슷)
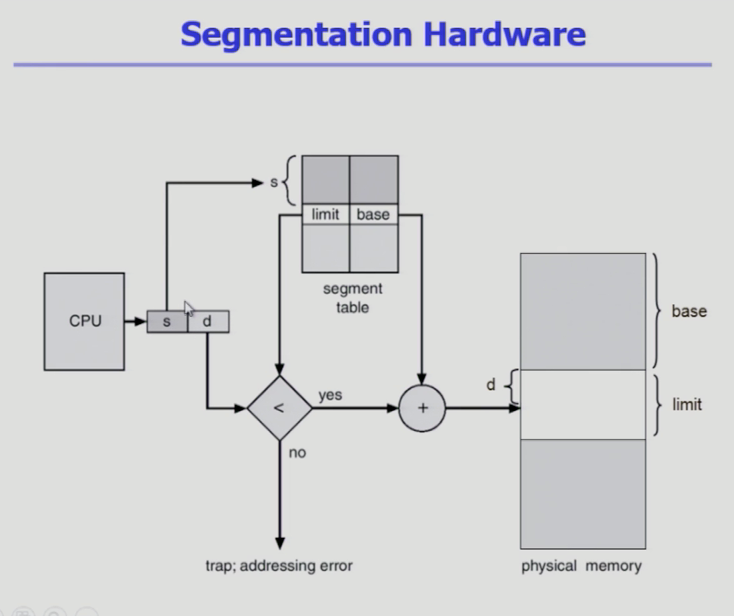
-
CPU가 논리주소를 주면 세그먼트 기법에서는 논리주소의 앞부분을 번호, 뒷부분 떨어져있는지 나타내는 오프셋으로 본다
-
세그먼트 테이블에 의해서 s 번째 세그먼트는 물리적 메모리 s번째 엔트리가면 물리적 메모리에서 시작위치가 어디인지 확인
-
시작위치에서 그 안에서 얼만큼 떨어져잇는지 오프셋으로 확인
-
페이징 기법과 다르게 세그먼트 기법은 시작위치만 담는게 아니고 세그먼트의 길이 정보도 있다 (limit)
- 어차피 페이지는 크기가 똑같으니까 페이징 기법에서는 길이가 필요 없었다
- 세그먼트가 다 다르니까 시작위치로부터 얼마만큼에 걸쳐서 존재하는가를 테이블이 담고 있어야 한다
-
주소변환할 때 무조건 시작위치에서 d 만큼 떨어트리는게 아니다
오프셋이 세그먼트 길이 벗어난 위치 지정하고 있다면 주소변환하면 안된다 => 불순한 메모리 접근 시도
주소 변환 할 때는 s 번째 엔트리에서 세그먼트 길이와 세그먼트 오프셋 비교해서 오프셋이 길이 벗어난 위치 접근하려고하면 트랩을 걸어준다 => 메모리 접근 자체 막아야 한다 -
주소 변환 위에서 레지스터 두 개 제공됨
- 연속할당에서는 베이스와 리밋
- 페이징에서는 레지스터 두 개를 페이지 테이블 시작위치와 길이를 담는 용도로 사용
-
세그멘테이션 기법에서도 두 개의 레지스터
- 메모리 상에 세그먼트가 어딧는지 시작위치
- length는 세그먼트 길이가 얼마인지 (프로세스가 몇 개의 세그먼트로 구성되어 있는가)
- 프로세스가 세그먼트 n개로 구성됐다하면 엔트리 수가 n개가 있다
-
주소변환하는 과정에서 프로세스가 사용하는 세그먼트 수가 3개인데 논리주소로 세그 번호 5번 주면 잘못된 메모리 접근 시도
5번을 줬다는 것은 위에서 5번째 엔트리 주소변환을 가지고 하겠다는 것.
즉, 세그먼트 개수를 넘어서는 시도도 접근 막는다
* 길이와 개수를 넘어서는지 체크가 필요 -
페이징기법과의 차이점
- 페이징은 메모리가 동일한 크기로 나눠짐
페이지 프레임 번호가 물리적 주소에 있으면 된다 주소변환을 위한 것
- 페이징은 메모리가 동일한 크기로 나눠짐
-
근데 세그먼트는 세그먼트 길이가 균일하지 않고 바이트 단위로 다르 수 잇기 때문에
세그먼트 시작 위치 나타내는 베이스 값은 바이트 주소가 된다
물리적에서 몇번째 위치가 아니라 바이트 단위 주소를 가리키고 한다 -
이전 연속할당의 문재점
크기가 달라서 종료되고 어떤 프로세스가 종료되고 빈 홀이 프로세스 크기보다 작으면 비어있어도 못들어가는 문제- 세그먼트 기법에서도 생긴다(크가가 제각각이기 때문)
세그멘트 예제
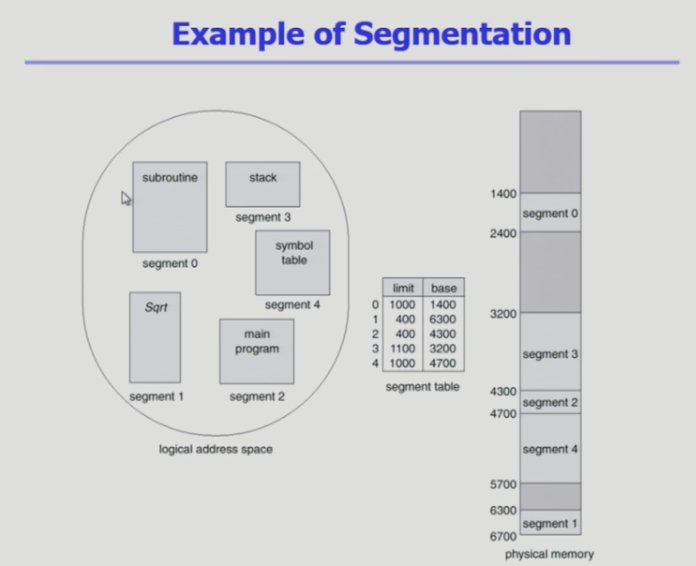
- 프로세스가 5개의 세그먼트로 구성
- 세그먼트 테이블에 엔트리 5개 존재
- 물리적 메모리 시작위치 / 세그먼트 길이 라는 두 개 값 존재
- 0번 세그먼트는 1400번째에 시작위치가 있고 길이가 1000이면 2400번째 까지 메모리에 존재
- 빠져나가면 크기가 다른 외부조각이 생긴다
할당 문제
세그먼트를 어느 조각에 집어넣어야 할 것인지에 대한 문제가 발생 (페이징과의 차이점)
빈 조각 활용 법에 대한 문제
-
퍼스트 핏 / 베스트 핏과 같은 방법들
-
페이징과 비교한 장점
- 공유나 보안 측면에서 동일한 크기에 대한 것이 아니라 의미 단위로 하기 때문에 세그먼테이션이 훨씬 유리
코드 세그먼트랑 스택 세그먼트가 있을 때 스택은 읽기 쓰기가 가능하고 코드는 읽기만 가능하게 세팅할 수 있다
실행권한을 줄 때 세그먼트에서는 의미 단위로 관리할 수 있어서 효과적
* 페이징 기법에서도 가능은 함(엔트리에 표시해서) => 페이지는 동일한 크기로 자르기 때문에 (4kb) 일부는 코드, 일부는 데이터 이런 식으로 잘라질 수 있다
따라서 페이징 기법은 프로텍션 하기가 어렵다
즉, 의미단위로 해야하는 공유 보안은 세그먼트가 유리
가변크기로 인해 생기는 문제에서는 페이징이 유리
- 공유나 보안 측면에서 동일한 크기에 대한 것이 아니라 의미 단위로 하기 때문에 세그먼테이션이 훨씬 유리
-
현실적인 구현에서는 다른 문제가 존재
- 세그먼트는 엔트리가 많지 않다 (코드 / 데이터 스택)
- 페이징은 엔트리 수가 100만 개 넘는다
- 주소변환을 위한 메모리 공간 낭비는 페이징이 심하다 => 따라서 다단계 테이블을 활용
- 퓨어 세그먼테이션을 적용해서 하는 상황은 많이 없다, 세그먼트 + 페이징 혼합을 많이 사용
세그먼트와 페이징 혼합 기법
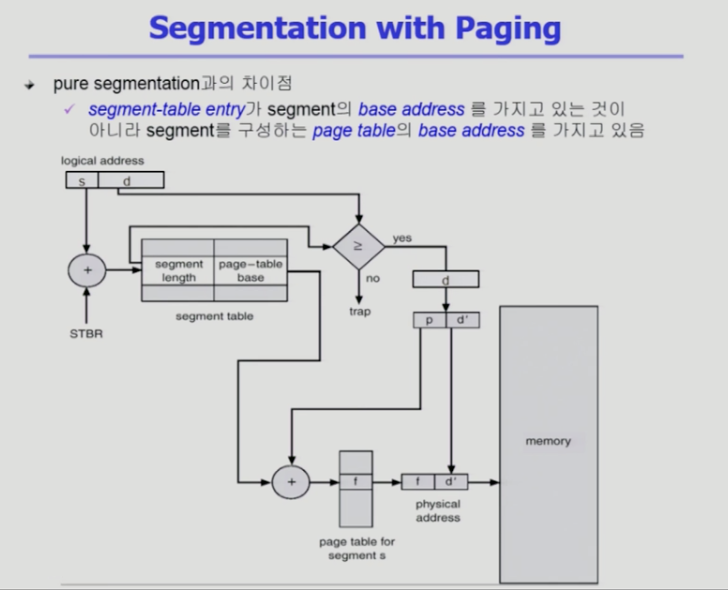
의미 단위의 세그먼트로 나누지만 동일한 크기가 되도록 한다
하나의 세그먼트 크기는 페이지 길이의 배수
-
세그먼트 구성하는 페이지를 쪼개서 페이지 단위로 물리적 메모리에 올라간다 (기존 페이지와 동일)
-
의미 단위는 세그먼트 테이블을 이용
-
두 단계의 테이블 이용
-
CPU가 논리적 메모리 주소 전달 >
세그먼트 번호, 세그먼트 오프셋 값 으로 주소변환 필요 >
세그먼트 테이블 시작위치는 세그먼트 테이블 베이스 레지스터에서 확인 위에서 S번째 엔트리로 감 >
혼합된 기법에서는 세그먼트 구성하는 페이지들이 어디 있는지 나타내는 페이지 테이블 존재 (세그먼트마다 페이지 테이블이 존재, 프로세스마다 존재 X) >
해당 세그먼트 구성하는 페이지 테이블을 확인 >
위에서부터 몇번째 엔트리인지 확인해서 주소변환 >
오프셋(d)을 둘로 쪼개서 앞은 페이지 번호(p) 뒤는 페이지 오프셋(d') >
시작 위치는 세그먼트 테이블에서 확인, 몇 번째인지는 주소 안(p/d')에서 확인 >
위에서부터 f 번째 프레임에 있구나 확인 -
위 방법은 얼로케이션 문제가 없다
- 동일크기 페이지로 메모리 올라감
-
공유 보안 문제 없다
- 세그먼트 테이블에서 관리
-
세그먼트 길이를 세그먼트 테이블이 가진다
- 세그먼트가 페이지 10개로 구성되는데 세그먼트 내 페이지 번호가 15면 불순한 시도를 통제한다
