파일과 파일 시스템

- 파일은 하드디스크에 저장하는 단위
- 메모리는 주소를 통해 접근하는 장치
- 파일
- 이름을 통해 접근
- 파일은 비휘발성의 보조기억장치에 저장 (하드디스크 등)
- 운영체제에서는 장치들을 관리하기 위해 file 이름 사용 (일반 파일과는 다르다)
- 파일 연산
- 생성
- 삭제
- 읽고 쓰기 (대표적)
- 리포지셔닝 (lseek)
- 어느 위치를 읽고 쓰는지 가리키는 포인터가 있다
- 한번 읽고 나면 다음 부분 가리킨다
- 필요에 따라 다른 부분을 읽고 쓰고 싶을 때 위치를 수정해주는 것
- 오픈과 클로즈
- 읽고 쓰기 전과 후에 필요
- 오픈은 파일의 메타데이터를 메모리로 올려놓는 작업
- 메타데이터는 파일을 관리하기 위한 정보(이름, 유형, 위치, 사이즈 등)
- 파일 시스템
- 파일 자체의 내용과 메타데이터 같이 저장 및 관리
- 일차원적 저장이 아니라 루트 디렉토리부터 계층적으로 저장
- 파일을 어떻게 저장하고 관리할지를 담당
디렉토리와 로지컬 디스크

- 디렉토리
- 이것도 하나의 파일
- 디렉토리 파일의 내용은 아래 파일이 어떤건지 알려주는 파일
- 디렉토리 파일의 일부 메타데이터는 디렉토리에 직접 저장 일부는 다른 곳에 저장
- 연산
- 파일 찾기, 생성, 삭제, 리네임, 파일 시스템 전체 탐색 등
- 결국 파일 시스템이 하드디스크에 저장, 디스크는 논리적 디스크와 물리적 디스크가 있다
- 운영체제가 보는 디스크는 논리적 디스크 (파티션)
- 디스크 하나 사서 파티션 나누면 논리적 디스크 여러 개가 만들어진다
- 파티션에 파일 시스템 설치할 수 있다
- 또는 논리적 디스크를 가상 메모리 스왑 공간 용도로도 사용할 수 있다
오픈()
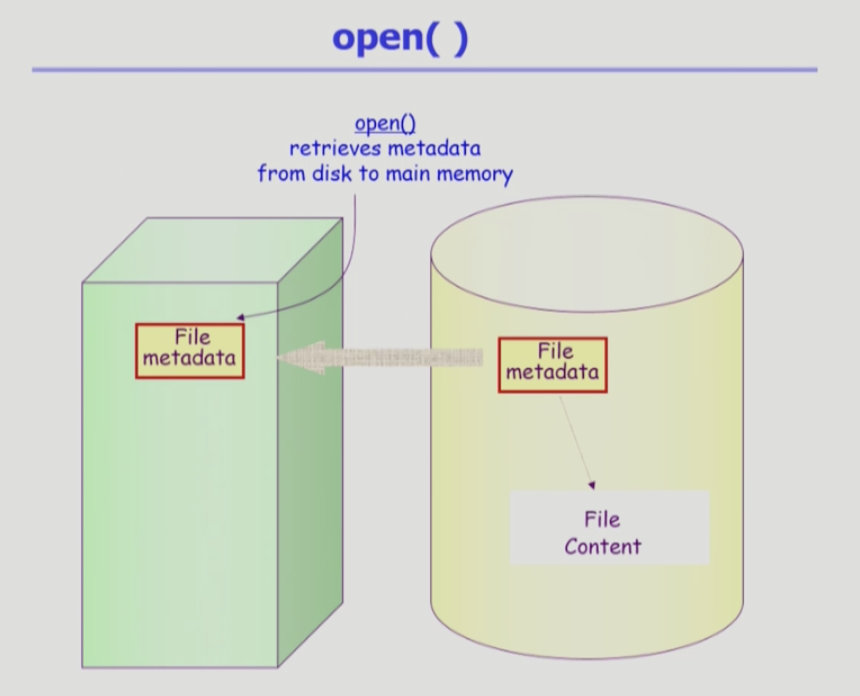
파일의 메타 데이터를 메모리로 올려놓는 것
- 논리적 디스크 안에 파일 시스템이 있으면 메타데이터와 파일 내용이 저장되어 있다
- 파일 오픈하게 되면 메타데이터가 메모리로 올라간다

- a/b/c를 오픈하면 c 파일의 메타데이터가 메모리로 올라간다
- 계층적으로 구성되어있을 때 C의 메타데이터가 어디 저장되어있는지 찾아야 한다
- 루트 디렉토리부터 경로 따라 내려가면서 위치를 찾는다
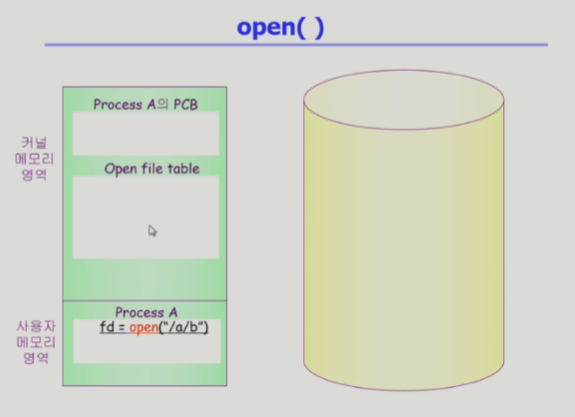
- 왼쪽이 물리적 메모리 오른쪽이 논리적 디스크
- 사용자 프로그램이 시스템 콜(오픈) >
b 파일을 오픈하겠다 >
CPU 제어권이 운영체제로 넘어간다 >
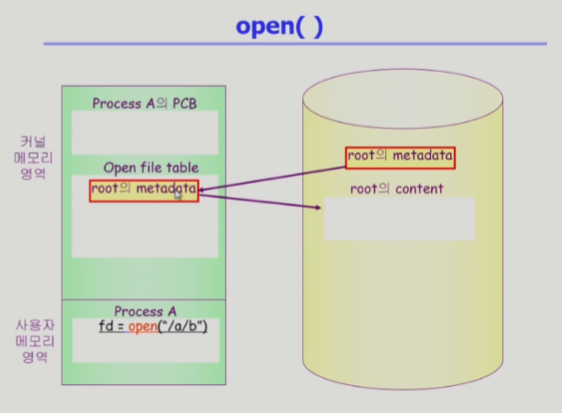 루트 디렉토리의 메타데이터는 이미 운영체제가 알고 있기 때문에 먼저 메모리에 올린다 (루트를 먼저 오픈) >
루트 디렉토리의 메타데이터는 이미 운영체제가 알고 있기 때문에 먼저 메모리에 올린다 (루트를 먼저 오픈) >
루트 디렉토리 실제 컨텐츠의 위치를 찾을 수 있다
(내용은 디렉토리 밑의 파일의 메타데이터를 가지고 있다) >
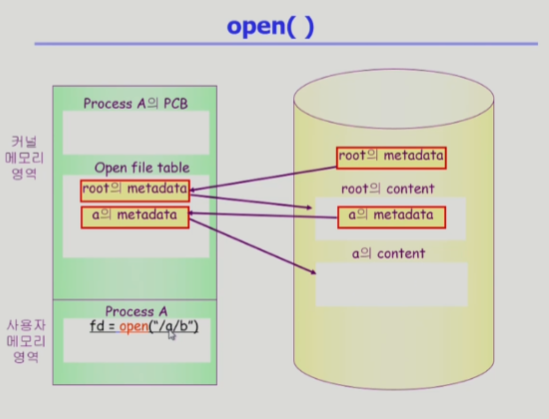 루트 디렉토리의 내용에서 a라는 파일의 메타데이터를 찾아서 메모리에 올린다 (a 오픈) >
루트 디렉토리의 내용에서 a라는 파일의 메타데이터를 찾아서 메모리에 올린다 (a 오픈) >
a의 메타데이터 중에는 a의 파일 시스템 상의 위치 정보가 들어있어서 a의 내용을 찾을 수 있다 >
a는 디렉토리 파일이라서 그 밑의 파일에 대한 메타데이터가 있다 >
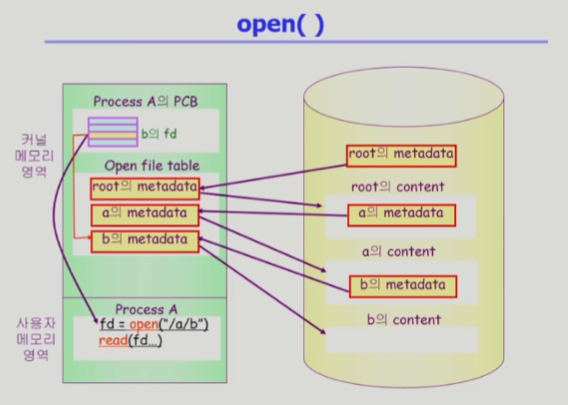 b의 메타 데이터를 찾아서 메모리에 올려놓는다 (오픈 이제 끝) >
b의 메타 데이터를 찾아서 메모리에 올려놓는다 (오픈 이제 끝) >
시스템콜의 결과값을 리턴 - 각 프로세스마다 프로세스가 오픈한 파일들에 대한 메타데이터 포인트를 가지고 있는 배열이 생긴다
- b라는 메타데이터의 위치가 있는 배열의 인덱스(fd 파일 디스크립터가 됨)를 리턴
- 이 숫자를 가지고 읽기 / 쓰기를 요청을 할 수 있다
- 파일 디스크립터를 적어서 입력으로 넣어주게 된다 (다시 CPU가 운영체제한테 넘어간다) >
프로세스 A의 PCB에 가서 해당 디스크립터에 대응하는 메타데이터를 오픈 파일 테이블에서 읽고,
여기서 디스크에서의 파일 위치 정보를 확인해서 거기있는 내용(콘텐츠)을 전달
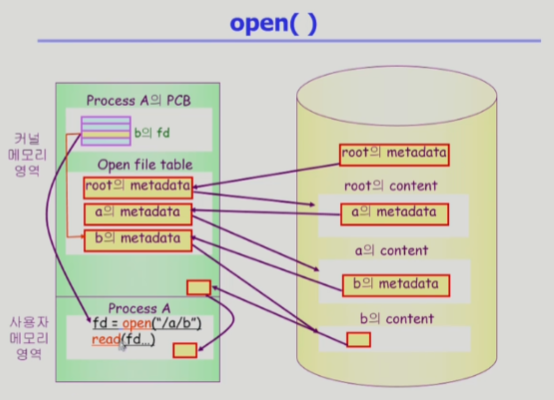
- 이 과정에서 읽어서 직접주는게 아니라 자신의 메모리 공간 일부에 읽어놓는다
- 그 후 사용자 프로그램에 내용을 카피해서 전달
- 만약, 이 프로그램이 동일한 파일의 동일한 위치를 요청하면 디스크까지 가는게 아니라 이미 읽어놓은 것을 바로 전달해줄 수 있다 (버퍼 캐싱)
- 요청한 내용이 버퍼 캐시 안에 있든 없든 운영체제한테 CPU 제어권이 넘어간다
- 이미 메모리에 있는 것에 대해 프로그램이 요청하면 시스템 콜이기 때문에 CPU 제어권은 운영체제로 넘어간다
- 요청한게 없으면 디스크에 읽어와서 버퍼캐시에 올려놓고 카피해서 사용자 프로그램에게 전달
- 버퍼캐시 있든 없든 시스템 콜 통해 운영체제로 넘어와서 LRU, LFU 알고리즘 사용할 수 있다 (모든 정보를 운영체제가 알고 있기 때문에)

- 여러 이론
- per-process file descriptor table
- 프로세스마다 가지고 있는 파일 디스크립터 테이블
- system-wide open file table
- 파일을 오픈했으면 시스템 와이드하게 파일을 한꺼번에 관리
- 시스템 전체에 하나 존재하는 테이블
- per-process file descriptor table
운영체제 구현에 따라 테이블이 여러 종류 있는 경우도 있다
- 메타데이터가 디스크에 있을 때는 기본정보가 메타데이터
- 이걸 메모리에 올려놓게 되면 추가적으로 한 가지 메타데이터 또 필요
- 현재 이 프로세스가 이 파일의 어느 위치에 접근하고 있다는 오프셋
누가 A라는 파일을 오픈하고 또 다른 프로그램이 같은 A 파일을 오픈하면 시스템와이드하게 메타데이터는 하나만 존재
히지만 오프셋은 각 프로그램이 동일한 파일을 읽어도 프로세스마다 별도로 가지고 있어야 한다
오픈파일테이블은 두 개로 나뉘어서 프로세스와 무관하게 하나만 가지고 있으면 되는 것과 프로세스가 어디에 접근하는지 별도로 가져야 하는 오프셋을 따로 두는것이 일반적
메타데이터 위치만 가지고 있는 것은 내용을 가지고 있지 않다
메타데이터가 메모리에 올라오면 각 프로세스 별로 필요한 정보가 있고, 이미 디스크에 적혀있는 메타데이터가 있다 (구분 해주기)
파일 보호

메모리에 대한 보호는 읽기/쓰기 권한 있냐 없냐(접근 권한) 정도만 본다
파일은 여러 사용자와 여러 프로그램이 같이 사용할 수 있기 때문에 파일 접근 권한이 누구한테 있는지 해당하는 것과 연산이 어떠어떠한 것이 가능한지 두 가지를 같이 가져야 한다
접근 권한 제어하는 방법은 크게 세 가지
1. Access control Matrix
- 행렬 사용
- 행과 열에 사용자와 파일 이름을 나열
- 각 사용자가 각 파일에 대해 어떤 권한이 있는지 표시하는 것
- 권한 체크해보고 권한이 있는 경우에만 허락
- 행렬 칸을 다 만들면 낭비
- 액세스 컨트롤 리스트
- 파일을 주체로 해서 접근 권한이 있는 사용자들을 리스트로 묶어놓는 것
- 각 파일에 대해서 사용권한이 없는 사용자는 리스트에서 빼는 것 (행렬 공간 낭비 방지)
- Capability
- 사용자 중심으로 권한 있는 파일을 리스트로 연결
- 위는 부가적 오버헤드가 크다
- 그루핑 (일반적)
모든 사용자에 대해 다루는게 아니라 사용자 그룹을 세 가지로 나눈다
각 파일 소유주에 대해 접근권한을 표시
사용자와 동일 그룹의 접근 권한 표시
나머지 전체 외부 사용자에 대한 접근 권한 표시
총 9개의 비트만 있으면 된다
권한 있으면 1, 없으면 0 - 패스워드
모든 파일에 대해 패스워드를 통해 관리
접근 권한이 읽기, 쓰기, 실행이 있기 때문에 접근 권한 별로 패스워드를 따로 둔다
패스워드를 기억하기 어려워진다 너무 많아서
따라서 관리 문제가 있다
파일 시스템의 마운팅
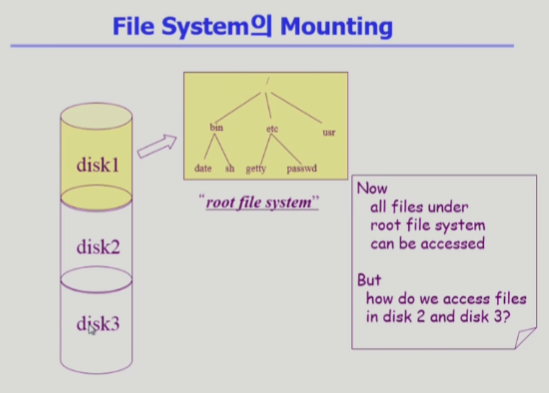
- 루트 파일 시스템
특정 운영체제에 대해 파일 시스템 하나가 접근이 가능
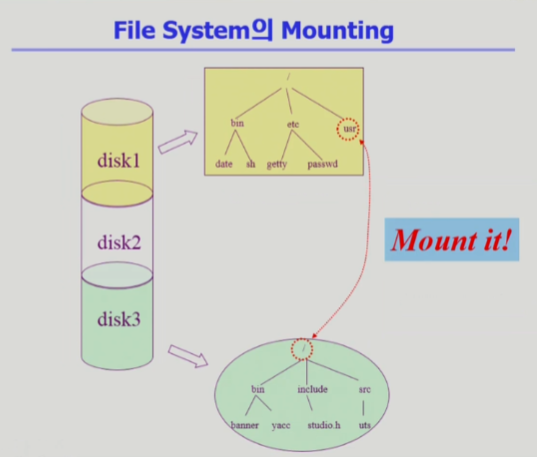
만약 다른 파티션에 있는 파일 시스템에 접근하려면 어떻게? - 마운팅 연산
- 루트 파일 시스템 특정 디렉토리 이름에 또 다른 파티션의 파일 시스템을 마운팅해주면
마운트 된 디렉토리 접근하게 되면 또 다른 파일 시스템의 루트 디렉토리 접근하는 것과 같아진다 => 서로 다른 파티션에 있는 파일 시스템에 접근할 수 있게 된다
- 루트 파일 시스템 특정 디렉토리 이름에 또 다른 파티션의 파일 시스템을 마운팅해주면
액세스 방법
- 파일에 접근하는 방법
- 순차 접근
카세트 테이프처럼 - 직접 접근
이메일 접근
요즘은 직접 접근이 많아졌다
특정 위치 접근 후 그 다음 위치 건너 뛴 다음 다른 위치 접근하는 것이 가능
직접 접근이 가능한 매체라 하더라도 데이터 어떻게 관리하느냐에 따라 가능할 수도 안할 수도 있다매체에 따라 되는 것도 있고 안되는 것도 있다
- 순차 접근
디스크에 파일 데이터 할당(저장)하는 방법 3가지

- 연속 할당
- 링크드 할당
- 인덱스 할당
연속 할당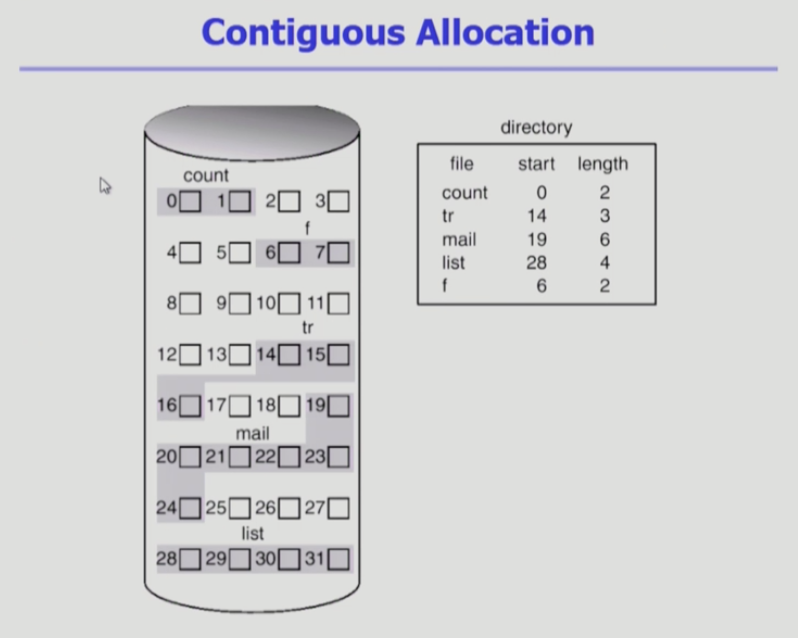
디스크에 파일 저장할 때는 동일한 크기의 섹터 단위로 나누어서 저장
- 논리적인 블럭이라고 부른다
- 임의 크기 파일을 동일 크기 블럭으로 나누어서 저장 (페이징 기법과 유사)
하나의 파일이 디스크 상에 연속해서 저장이 되는 방법
- 블럭 2 개로 구성된 파일은 1, 2가 인접하게 저장
- 디렉토리에 파일이 5개가 있고 메타데이터도 함께 저장되어 있다
- count가 연속할당되어있다고 하면 start인 0부터 길이가 2인 채로 연속해서 저장되어 있다

- 단점
- 외부 조각이 생길 수 있다
중간중간 내용이 들어가 있지 않은 조각들이 존재 - 파일 크기가 중간중간 바뀔 수 있는데 빈 블럭이 중간중간 있기 때문에 파일 크기 키우는데 있어서 제약이 있다
- 대비해서 미리 빈 공간 확보해놓는 방법
이렇게 할 경우 내부조각 발생(할당되었지만 사용되지 않는 공간 > 공간 낭비)
- 대비해서 미리 빈 공간 확보해놓는 방법
- 외부 조각이 생길 수 있다
- 장점
- 빠른 I/O 작업이 가능(헤드 이동 시간 단축)
한번 이동을 해서 많은 양의 데이터를 받아올 수 있다- 임시로 저장해놓고 필요하면 메모리로 올리는 스왑 공간용(공간 효율성보다 속도 효율성이 중요하다)
- 파일 중에서 데드라인이 있는 리얼타임용으로도 사용
- 직접 접근이 가능
19에서 연속으로 6개 저장되어 있을 경우 앞에서 5개 보고 싶을 때 19 + 5 = 24를 바로 접근 가능
- 빠른 I/O 작업이 가능(헤드 이동 시간 단축)
링크드 할당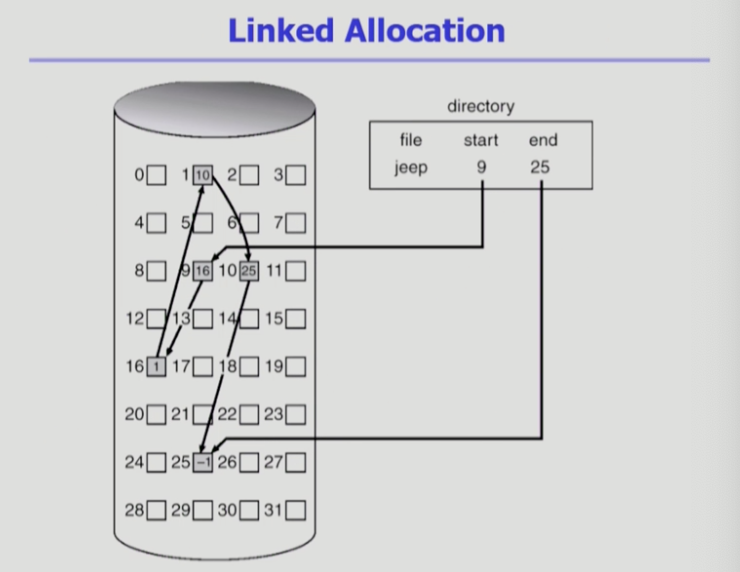
빈 위치면 아무곳이나 들어갈 수 있게 배치
- jeep 파일의 첫번째는 9에 있고, 9에 가면 두번째 블럭 내용이 존재... 끝은 25에 있다고 표시
- 시작 위치만 가지고 있고 각 위치마다 그 다음 위치 표시

- 장점
- 외부조각 문제가 발생하지 않는다
- 단점
- 직접접근이 안된다
연결되어있기 때문에 탐색하면서 첫번째부터 쭉 가봐야 한다 - 신뢰성 문제
파일 구성하는 섹터 개수가 1000개인데 중간 하나가 배드 섹터라면 포인터가 유실되어 뒷 부분을 놓치게 된다 - 보통 디스크에서 하나의 섹터는 512바이트
디스크 외부에서 데이터 저장하는 단위가 512바이트의 배수로 구성
다음 위치 가리키는 포인터로 4바이트 소요된다면 이 때문에 한 섹터에 들어갈 내용이 포인터의 비트 때문에 두 개의 섹터에 저장이 된다 (4바이트를 갉아먹음)
- 직접접근이 안된다
- 효율적으로 변형
- FAT 파일 시스템
(뒷 부분에 설명)
- FAT 파일 시스템
인덱스 할당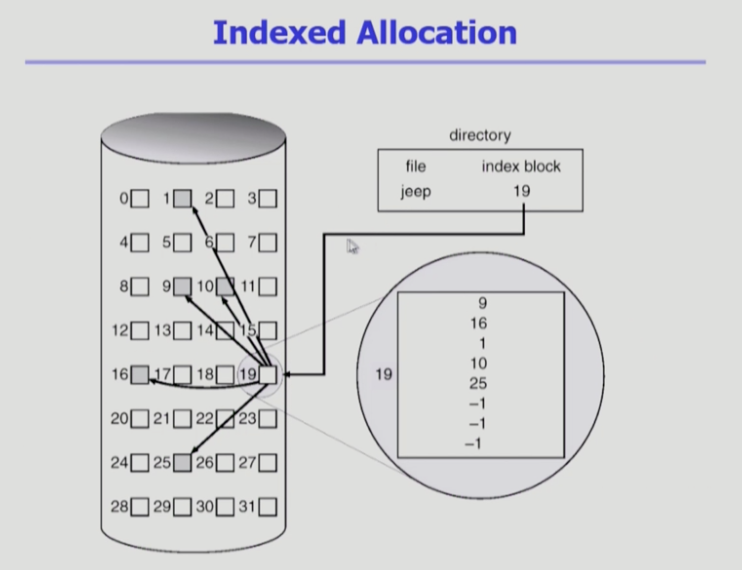
하나하나 따라가는 문제를 해결하기 위해서 먼저 인덱스를 가리키게 한다
인덱스 블럭은 파일이 저장되어있는 위치정보를 블럭 하나에 열거

- jeep 파일은 총 5개의 블럭으로 구성되어 있다 (9, 10, ... 25)
- 장점
- 직접접근 가능
인덱스 블럭만 살펴보면 바로 앞에서 4번째 블럭을 볼 수 있다 - 외부조각이 생기지 않는다
홀이 생기는 문제도 방지
- 직접접근 가능
- 단점
- 아무리 작은 조각이라 하더라도 블럭이 두개 필요
인덱스를 위한 블럭 / 실제 데이터를 위한 블럭
너무 작으면 공간 낭비가 생긴다 - 큰 파일의 경우에 하나의 인덱스 블럭으로 위치를 다 표현하지 못한다 (개수가 한정)
- 이를 해결하기 위해 링크드 스킴 / 멀티레벨 인덱스 사용
- 아무리 작은 조각이라 하더라도 블럭이 두개 필요
유닉스의 파일시스템 (실제로 어떻게 사용?)
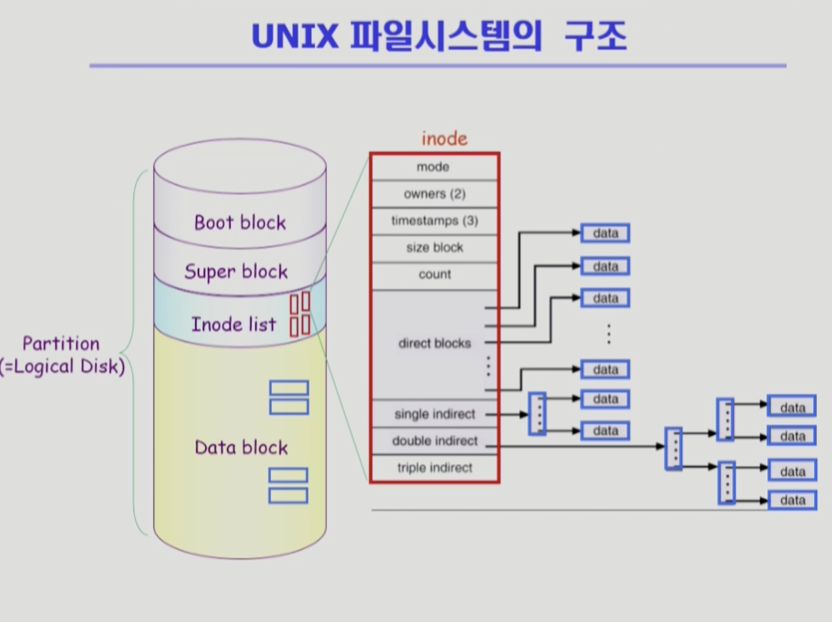
- 기본적 파일 시스템 구조
여기서 점점 발전되어갔다 - 하나의 논리적 디스크 (파티션)에 파일 시스템 설치
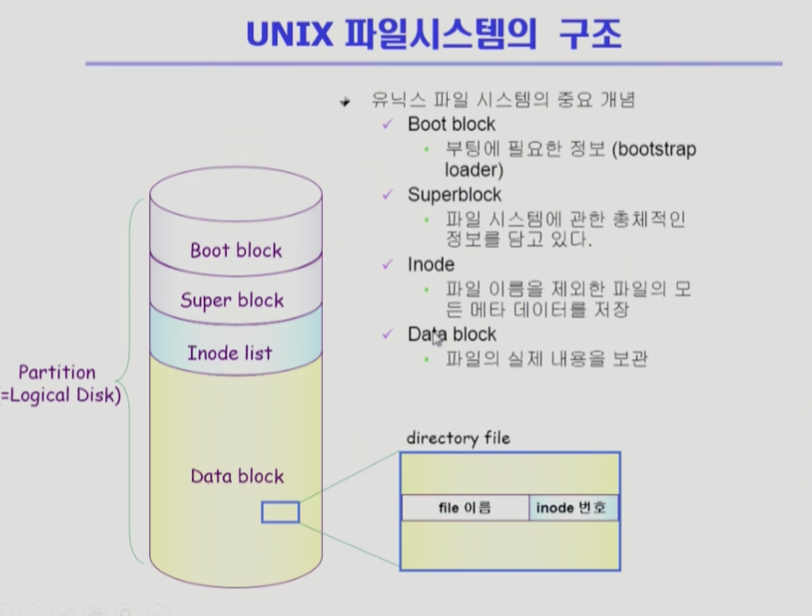
- 저장되는 구조 4가지
- 부트 블록
- 모든 파일 시스템 앞에는 부트 볼록이 나온다
- 부팅에 필요한 정보
맨 처음 부팅할 때 0번 블록을 올리는데 여기에 부팅을 하기 위한 기본 정보가 들어가 있다
- 슈퍼 블록
- 파일 시스템에 관한 총체적 정보를 담고 있다
어디가 빈 블럭, 파일이 사용중인 블럭이 어디인지 등
- 파일 시스템에 관한 총체적 정보를 담고 있다
- 아이노드 리스트
- 디렉토리가 메타데이터를 다 가지고 있지는 않다
아이노드 리스트에 메타데이터가 저장되어있을 수도 있다 - 파일 하나당 아이노드가 하나씩 할당
- 메타데이터 중 파일의 이름은 디렉토리가 직접 가지고 있다
나머지 데이터는 아이노드에 저장되어 있다
아이노드 10번이면 아이노드의 10번째가면 메타데이터 존재
- 디렉토리가 메타데이터를 다 가지고 있지는 않다
- 부트 블록
- 파일의 위치 정보
- 각 파일당 아이노드는 크기가 고정되어 있다
- 위치정보를 나타내는 포인터 개수도 유한하다
- 유닉스에서는 다이렉트 / 싱글 / 더블 / 트리플 4가지로 파일 위치 정보 구성한다
굉장히 작은 데이터는 다이렉트만 가지고 위치 표현
굉장히 큰 파일은 싱글 인다이렉트를 이용해서 인덱스 블록을 찾아서 포인트 여러 개를 확인
더 큰 파일은 더블 인다이렉트를 이용해서 두 번 이동해서 위치 확인
더 더 크면 트리플 인다이렉트를 이용해서 3단계의 인덱스 구조를 통과해서 확인- 아이노드만 오픈되어 있으면 파일 위치 바로 확인 가능
즉, 유닉스에서는 4가지 블록으로 디스크 관리
그 중 메타데이터는 아이노드에 별도로 관리
FAT 파일 시스템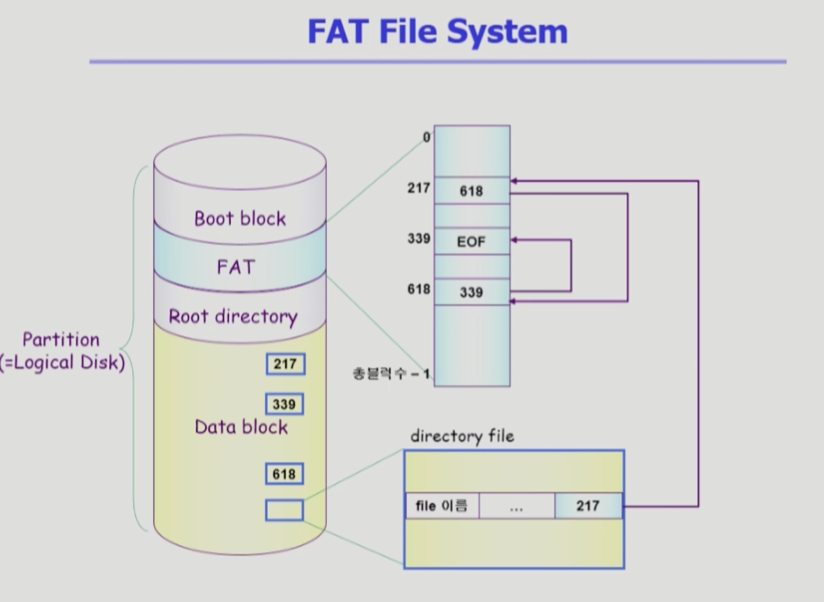
마소가 MS 도스를 만들었을 때 처음 만들어짐
최근 윈도우즈에서 사용, 모바일기기에서 사용
- 부트블럭
- 부팅과 관련된 정보
- FAT
- 파일의 메타 데이터 중 일부를 보관
- 위치 정보
- 나머지는 디렉토리가 가지고 있다
- 링크드 할당에서 나타날 수 있는 문제가 있었다
FAT은 이것을 해결- FAT이라는 별도의 배열에 위치 정보 저장
- 배열의 크기는 디스크가 관리하는 데이터 블록 개수와 같다 (n개 블럭있으면 배열 크기 n개)
- 배열에 숫자는 그 블럭의 다음 블럭이 어딘지 담고 있다
- 첫번째 블럭 217번 > 두번째 블럭은 FAT에서 217가면 618 표시 > 618로 가면 339 표시 > 339에 갔더니 파일 끝 표시
실제 블럭 접근하는게 아니라 FAT만 확인
- FAT이라는 별도의 배열에 위치 정보 저장
- 파일의 메타 데이터 중 일부를 보관
- 장점
- 직접 접근이 가능하다
- FAT은 작은 테이블
테이블을 메모리에 올려놓고 쭉 따라가면 된다
- FAT은 작은 테이블
- 포인터 하나가 배드섹터 나더라도 FAT에 내용이 있다
데이터 블럭과 FAT은 분리되어 있고 두 카피 이상이 있다 (유실 방지) - 링크드 할당을 응용했지만 단점을 극복
- 직접 접근이 가능하다
프리 스페이스 매니지먼트


비어 있는 블럭 어떻게 관리?
- 비트맵
디스크에 있는 데이터 개수만큼 배열을 만들어서 보관
- 유닉스 같은 경우 비트를 줘서 사용중인지 아닌지 0과 1로 표시
- 0이면 비어있고 1이면 이미 할당 됨
- 슈퍼 블럭 부분에 저장됨
- 장점
- 연속적인 빈 블럭을 찾는데 효과적이다(0이 6개인 것 찾기)
디스크 헤드 이동할 필요없이 많은 양을 한꺼번에 읽어올 수 있다
링크드 리스트
- 비어있는 블럭들을 링크로 연결

회색이 비어있는 블럭
다음 비어있는 위치가 어딘지 저장할 수 있다
비어있는 첫번째 위치만 포인터로 가지고 있다
비트맵에 비해 추가적 공간낭비가 없지만 빈공간 찾으려면 탐색해야해서 비효율적
그룹핑
인덱스 할당을 활용
처음 빈 위치에 가면 비어있는 블록의 포인트들이 저장되어 있는 방식
마지막 포인터는 또 인덱스 역할로 빈공간 기리킴
비어있는 블럭 찾기에는 효과적이지만 연속적인 블럭을 찾기에는 효과적이지 않다
카운팅
연속적 빈블럭 찾기 위해 빈블럭의 첫번째에 위치하고 몇 개가 빈블럭인지 쌍으로 관리
연속적인 빈블럭 찾는데 효과적

디렉토리 파일의 내용 어떻게 저장?
1. 리니어 리스트
- 파일의 이름과 파일의 메타데이터 등을 순차적으로 저장하는 것
- 메타데이터는 크기가 고정적
- 디렉토리에 대한 연산이 주어졌을 때 파일 찾아야하면 순차적으로 탐색하면 된다
- 모두 탐색해야해서 비효율적이다
- 해쉬 테이블 방식
- 파일 이름을 해쉬함수를 적용해서 결과값이 특정 범위 안의 숫자로 한정이 된다
- 해슁은 어떤 인풋 주어지든 간에 유한한 값 중 하나로 나온다
- 결과값에 해당하는 엔트리에 파일의 이름과 메타데이터를 저장
- 서로 다른 파일의 이름에 대해 같은 엔트리로 맵핑되는 충돌이 발생할 수 있다
 메타 데이터가 일부는 직접가지고 있고 일부는 파일시스템에서 별도로 보관한다
메타 데이터가 일부는 직접가지고 있고 일부는 파일시스템에서 별도로 보관한다
유닉스는 아이노드 / FAT 파일 시스템에는 FAT에 보관
- 긴 파일 이름 지원
- 엔트리 크기는 보통 고정되어 있다
- 메타 데이터 길이는 보통 한정되어 있다
- 문제는 파일 이름
길이를 제한할 수 있지만 비효율적
- 무작정 길게하는게 아니라 어느정도로 한정해놓고
파일 이름을 엔트리에 앞 부분부터 저장하다가 길어서 엔트리를 벗어나게되면 포인터를 둬서 따로 맨 끝에서부터 거꾸로 저장되도록 한다
VFS & NFS

- VFS (버츄얼 파일 시스템)
- 파일 시스템 종류가 많다
- 사용자가 파일 시스템 접근하기 위해서는 시스템 콜을 통해 운영체제에 요청해야한다
파일 시스템 종류별로 서로 다른 인터페이스를 쓰려고하면 혼란스럽다 - 어떤 파일 시스템이 사용되든 계층 맨 위에 VFS를 두어서 사용한다
- 다양한 종류의 파일 시스템이 있지만 사용자는 동일한 API 콜을 통해 모든 파일 시스템을 동일한 방법으로 접근할 수 있게 해준다
- NFS (네트워크 파일 시스템)
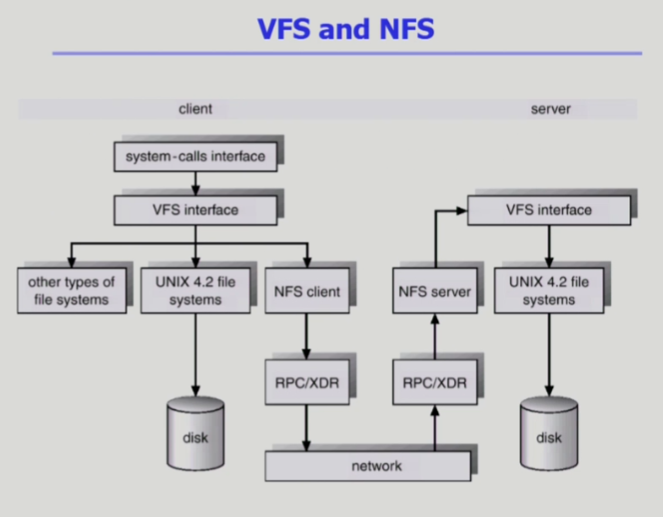
- 로컬 스토리지에 저장될 수 있지만 원격에 저장되어있는 파일 시스템 접근해야할 수도 있다
- 그림에 컴퓨터가 두 대 (클라이언트 / 서버)
두 대가 네트워크로 연결되어있다 - 클라이언트가 외부의 파일 시스템을 접근하기 위해서 VFS를 써서 접근 요청 > NFS 발동 원격 네트워크 통해서 서버 쪽을 접근 > 자기 사용자가 요청하는 것처럼 요청해서 내용을 전달한다
- 서버 쪽 NFS 모듈, 클라이언트 NFS 모듈도 있어서 같은 약속을 가지고 접근할 수 있게 해줘야 한다
페이지 캐시와 버퍼 캐시

- 페이지 캐시
- 가상 메모리의 페이지 프레임
- 페이지 캐시는 운영체제한테 주어지는 정보가 제한적 (클락알고리즘 사용)
이미 올라온 페이지에 접근할 때는 운영체제 개입이 없다 - 당장 사용되는 것을 올려놓는다 안쓰면 스왑 영역에 내려놓는다
- 버퍼 캐시
- 파일 데이터를 사용자가 요청했을 때 운영체제가 읽어온 내용을 영역중 일부에 저장해놓고 똑같은 파일 데이터를 나중에 요청받으면 디스크한테까지 가지 않고 버퍼캐시에서 가져온다
- 페이지 캐시보다 운영체제한테 주어지는 정보가 많다
- 파일 시스템에서 당장 사용되는 것을 버퍼캐시에 올려놓고 아니면 디스크의 파일 시스템에 내려놓는다
- 가상메모리 관점에서는 페이지 캐시, 파일 시스템 관점에서는 버퍼 캐시
- 유니파이드 버퍼 캐시
- 페이지 캐시, 버퍼 캐시 통합
버퍼 캐시도 페이지 단위로 관리를 한다
- 페이지 캐시, 버퍼 캐시 통합
- 메모리-맵 I/O
- 파일을 원래 접근할 때 오픈하고 읽기/쓰기 시스템 콜을 통해 접근하는 보통 방식이 아니라 파일의 일정부분을 가상 메모리에 맵핑 시켜놓고 쓰는 것
- 메모리 맵 시스템 콜 하고나면 메모리에 접근하는 연산을 통해 파일 입출력
파일 읽거나 쓰기 => 메모리에 접근해서 처리해라
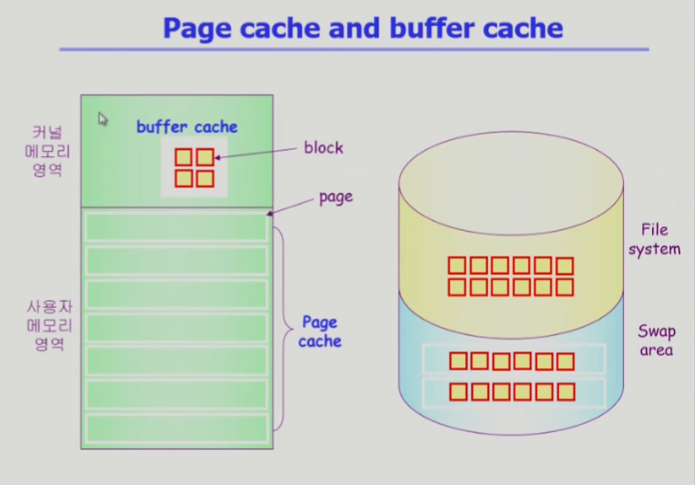
물리적 메모리에 커널과 사용자 메모리 영역(하얀색)이 있다
- 커널 메모리 영역에 버퍼 캐시 존재
- 읽어와서 버퍼 캐시에 저장한 다음에 사용자한테 전달하는 식으로 관리
- 프로그램 실행되다가 시스템콜 되어서 파일 읽어달라고 요청받으면 운영체제한테 읽기/쓰기 시스템 콜 요청해서 운영체제는 요청한 파일을 읽어서 사용자 프로그램한테 직접 전달하는게 아니라 버퍼 캐시에 먼저 읽은 뒤 사용자 프로그램에게 복제해서 전달
- 사용자가 요청한 파일을 버리지 않고 보관하고 있다가 같은 파일에 대해서 나중에 다시 한번 요청할 수 있다
- 파일의 내용이 이미 올라와있다면 디스크까지 갈 필요 없이 바로 전달
- 디스크(파일 시스템)가 느린 저장장치고 버퍼 캐시가 빠른 저장장치
- 사용자 메모리 영역은 하얀색 페이지 단위로 잘려서 존재 (페이지 캐시)
- 당장 필요한 부분이 올라와 있다
- 캐시는 상대적으로 빠른 저장장치
- 버추얼 메모리 시스템에서 스왑영역은 상대적으로 느린 장치
* 페이지는 보통 4KB 단위, 블럭 하나는 512bytes
최근에는 유니파이드 버퍼 캐시로 버퍼 / 페이지 합쳐져서 버퍼캐시도 4KB 페이지 단위로 관리
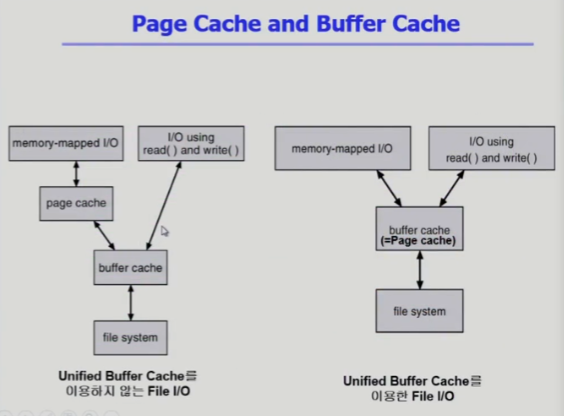
과거에는 페이지와 버퍼 캐시가 분리되어있었다(왼쪽)
- 파일 읽기 / 쓰기 요청 받으면 파일 시스템에 있는 블럭을 운영체제 버퍼 캐시에 읽어들이고 사용자 프로그램에 카피해서 전달 >
만약에 읽기 / 쓰기 요청했는데 버퍼캐시에 이미 올라와 있다면 전달.
메모리 맵 아이오를 쓰겠다고 하면 파일의 내용을 사용자 메모리 영역의 주소 공간에 맵핑 시켜놓는다
그때부터 사용자 프로그램이 자기 메모리에 데이터를 쓰거나 읽거나 하는 내용이 파일에 읽거나 쓰는 것으로 연결이 된다
버퍼와 페이지 캐시가 통합(오른쪽)
- 페이지 캐시와 버퍼 캐시가 같이 쓰인다
파일에 읽기 쓰기 요청하면 디스크 요청을 버퍼 캐시로 읽어서 전달을 하고 다른 프로그램이 동일하한 내용 전달하면 그대로 전달
메모리 맵 I/O 쓸 경우에 사용자 프로그램의 페이지 캐시로 바로 맵핑
만약 메모리 맵 I/O 쓰면 버퍼캐시로 읽는 단계가 없다 => 더 효율적
* I/O는 피할수 없는 단계
파일의 특정 부분을 주소공간에 맵핑해서 메모리 영역 읽고싶다면 읽으려는 순간 페이지 부재가 발생, 페이지 부재 핸들러가 운영체제를 통해 호출되고
이전에는 스왑 영역에 있던 페이지가 메모리로 올라갔는데 그러지 않고 해당 파일에 해당하는 내용이 올라간다 이후 다음번부터는 바로 접근이 가능
참고 설명
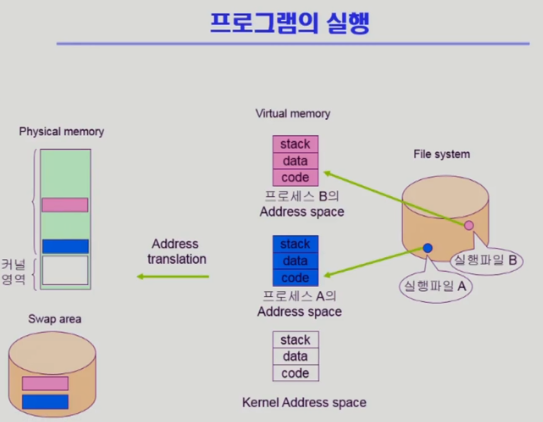
프로그램 실행되려면 파일 시스템은 실행파일이 가상메모리에 올라가서 실행
독자적 주소공간이 만들어서 당장 사용되는 부분은 물리적 메모리에 올라가고 아니면 스왑 영역에 올라간다
여기서 코드 부분은 당장 사용되지 않으면 이미 실행파일 형태로 저장되어 있다 (스왑으로 가지 않고)
필요 없으면 그냥 지워버리기만 하면 된다 이미 코드는 파일 시스템에 존재
필요하면 파일 시스템에서 올리면 된다
프로그램을 메모리에 올리는 역할을 로더가 한다
실행파일 부분을 주소공간에 맵핑을 해놓는다
주소공간이기도 하지만 파일의 일부 영역에 맵핑을 해놓는 것
코드 부분이 메모리에 없어서 스왑 영역을 뒤지는 것이 아니라 맵핑되어있는 실행파일을 찾아서 해당 부분을 메모리에 올려서 사용한다
(프로그래머가 하는것이 아니라 자동적으로 활용)
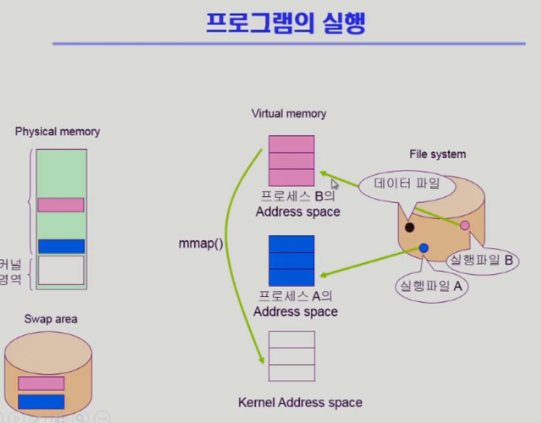
데이터 파일도 프로그램 실행되는 도중에 파일을 읽어서 사용할 수 있다고 요청할 수 있다
데이터 파일 사용하는 도중에도
- 읽기 / 쓰기 시스템 콜
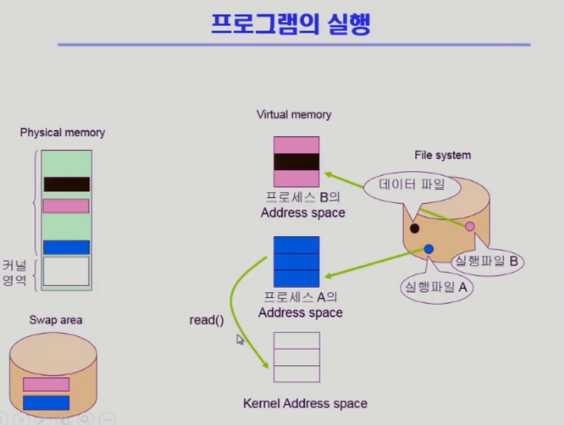
- 운영체제한테 파일 내용달라고 요청
운영체제 입장에서 관리하는 내용이 버퍼 캐시에 올라와 있지 않기 때문에 읽어들인 후 사용자 주소공간에 카피해서 전달
- 운영체제한테 파일 내용달라고 요청
- 메모리 맵 I/O
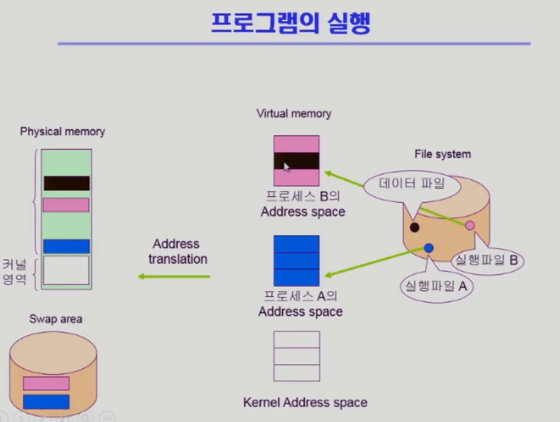
- 파일을 프로세스 B가 사용하겠다고 하고 시스템 콜 해서 맵핑 시켜놓는다
주소공간 일부가 물리적 메모리에 맵핑 되어있다(검은색 부분)
그 일부분은 파일과 맵핑되어 있는 상황
이 상황에서 프로그램이 메모리 영역을 읽겠다고 하면(메모리 맵 I/O)
아직 메모리에 안 올라와있는 상황 => 페이지 부재
페이지 부재 핸들러가 파일의 내용을 올려서 끝나면 읽혀진 내용을 접근할 수 있게 한다 - 장점
- 한번 해놓으면 자신의 주소공간에 직접 메모리 읽기 쓰기로 파일 I/O 작업을 할 수 있다
- 단점
- 여러 명이 같이 사용할 때의 일관성 문제
- 수정했는데 최신화되지 않는 등
- 파일을 프로세스 B가 사용하겠다고 하고 시스템 콜 해서 맵핑 시켜놓는다
