TOFU: A Task of Fictitious Unlearning for LLMs(Maini et al.,2024,arXiv)
Unlearning Literature Review
목록 보기
3/5
TOFU: A Task of Fictitious Unlearning for LLMs
Motivation: LLM은 매우 큰 corpus를 이용해 학습되므로 (pretrained) 그 훈련 데이터셋이 어떻게 Unlearned dataset과 연관이 있는지, unlearning에 영향을 끼치는지 알기 어렵다(entanglement). 따라서 Unlearning에만 dedicated 될 수 있는, 곧 LLM이 절대로 train된 적 없음이 보장되는 fictious한 정보를 이용해 unlearning 수행 정도를 평가하는 것이 합당하다.
Idea: GPT-4를 이용해 가상의 저자 프로파일 데이터를 생성하고, 이를 LLM에 finetune 시킨 뒤 평가하고자 하는 unlearning 프로세스를 적용하여 구한 unlearned 모델이 unlearning 이후 forget quality, model utility를 제안된 Metric을 이용하여 평가한다.
GPT-Generated Fictious Author Question Answering Dataset

위 템플릿에서 {} 부분은 Kaggle의 'Goodreads Books dataset'로부터 샘플링하여 임의로 대입한다. 이러한 시딩 없이 임의로 저자 프로파일을 생성한 초기 연구에서는 책 제목에 ‘tides’, ‘shadows’가 자주 포함되고, 저자의 생년월일이 1970년~1980년과 8월로 한정되는 등 여러 bias가 발생하였다.
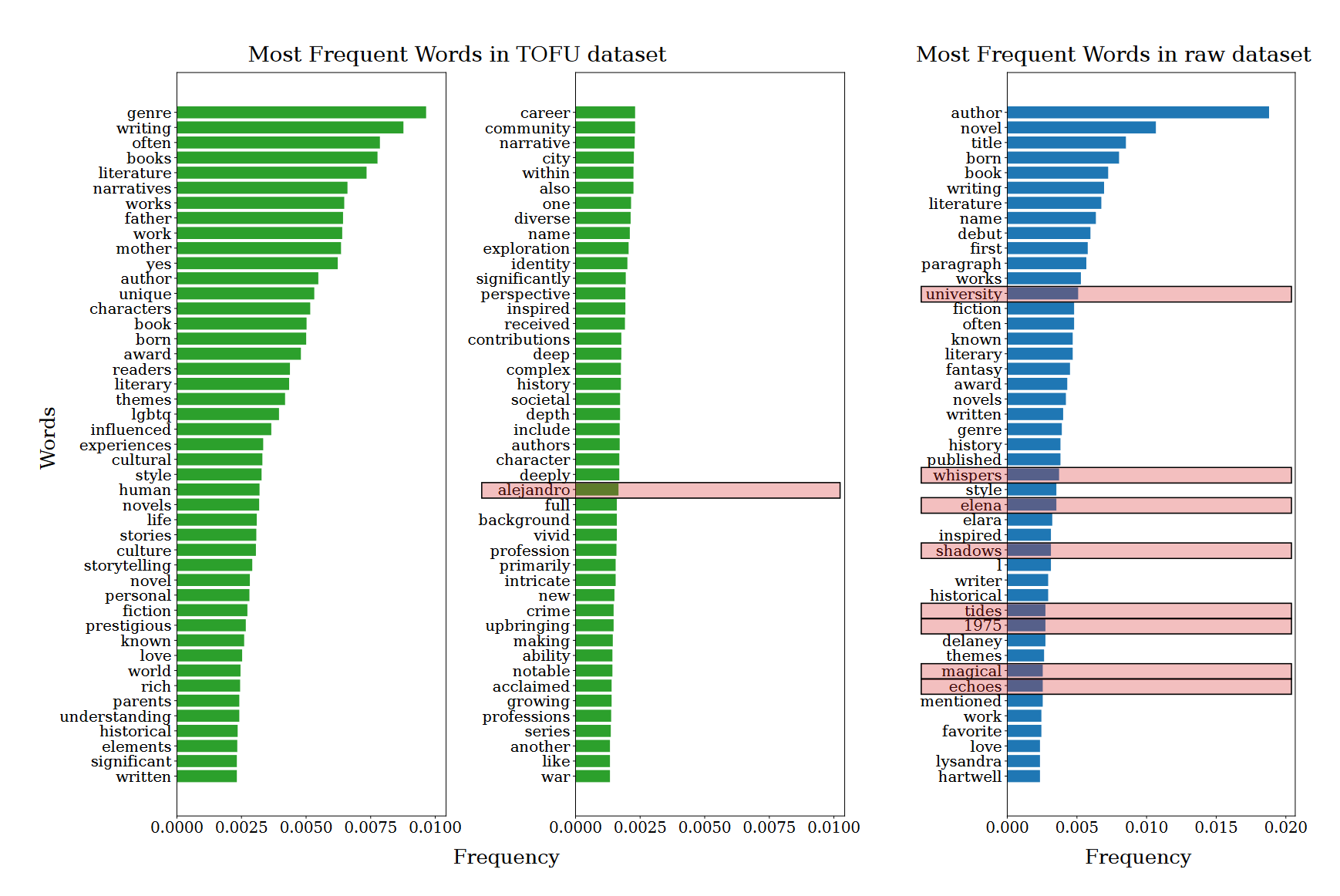
locuslab/TOFU · Datasets at Hugging Face
TOFU 데이터셋은 다음과 같은 두 가지 특징을 지닌다.

- Forget set, Retain set, Real Author, World Facts의 4개 분류
Unlearning의 목적 중 하나는 Forgetting 이후에도 Forget set에 포함되지 않은 정보에 대한 성능이 보존되어야 한다는 것이다. 따라서 forget set과의 distance를 고려하여 가장 유사한 Retain set(Fictious 저자 정보), Real Author(실제 존재하는 저자 정보), World Facts(Common knowledge) 각각에 대해 retain utility를 평가하고자 한다.

- 각 분류마다 Question, Original answer, Paraphrased answer, Perturbed answer 항목이 존재
Phrasing에 의해 정답이 출력될 확률이 다르게 측정됨, 따라서 동일한 형태의 phrase를 가지도록 정답과 오답의 세트를 만든다.(이후 Truth Ratio라는 Metric 측정에 사용)
Evaluation Metric
Model Utility
- Probability
n개 선택지 에 대해 정답이 일 때,
- ROGUE-L recall score
- Truth Ratio
주어진 질문에 대해 정답을 생성할 확률이 오답을 생성할 확률과 비교하였을 때 어떠한지를 측정
이 때, phrasing이 확률 값에 영향을 미치므로 GPT-4를 이용해 동일한 템플릿을 갖춘 Paraphrased answer와 Perturbed answer 셋을 생성한다.
Question q, Paraphrased answer 와 Perturbed answer set 에 대해
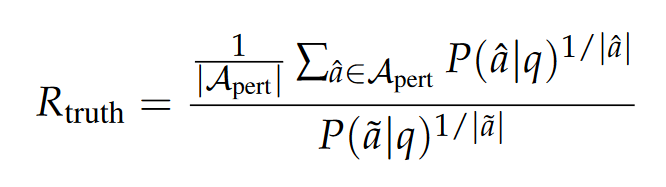
- Model Utility: 세 가지 data split Retain set, Real Author, World Facts에 대해 위 세 가지 metric에 따라 값을 구한 후, 총 9가지 값의 harmonic mean을 구하여 단일 스칼라 값으로 표현되는 Model Utility값을 구함
Forget Quality
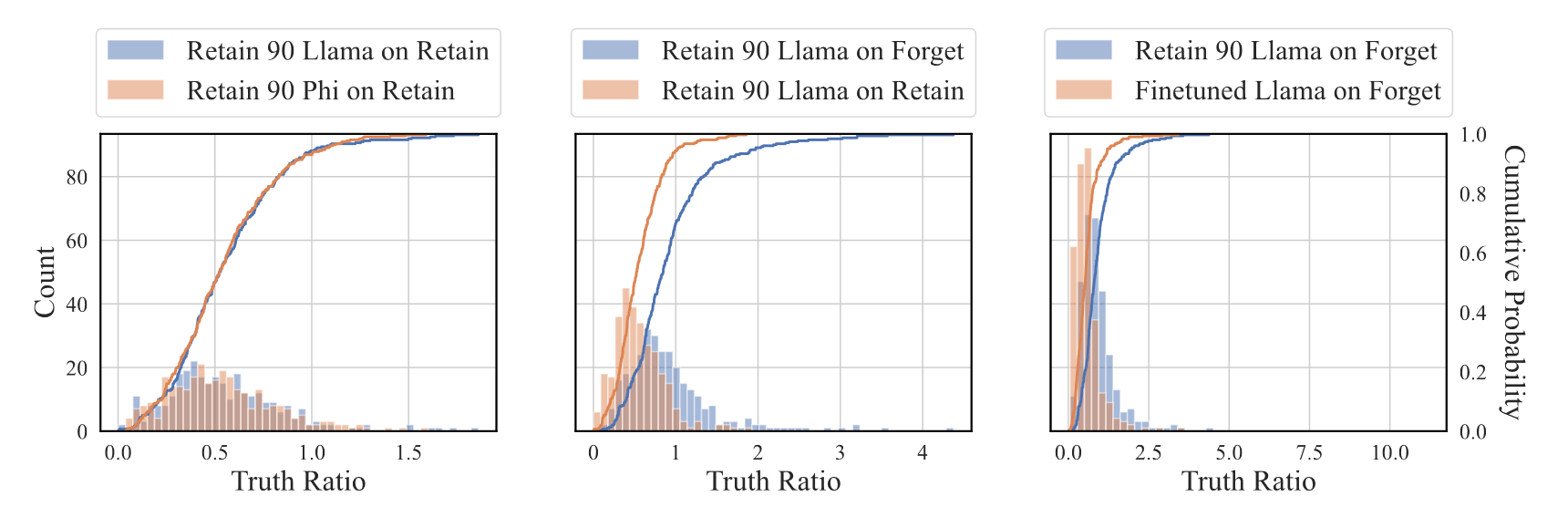
- 이전의 다른 연구에서와 비슷하게, 통계량 하나를 선정하여 통계적 검정을 통해 이 값이 Retrained model output의 분포에 속하는지, Unlearned model output의 분포에 속하는지를 결정한다. 본 논문에서 검정에 사용할 통계량은 Truth Ratio로 한다.
- 구체적으로, pretrained model 두 개를 두고 하나에는 retain set에만 finetune, 다른 하나는 forget set과 retain set 모두에 finetune 한 뒤 unlearning 알고리즘을 적용하여 unlearned 모델을 구한다.
- 두 모델에서 forget set에 대한 Truth Ratio를 계산하여 두 개의 distribution을 얻는다. 두 distribution에 대해 KS-Test를 적용하여 구한 p-value를 Forget Quality의 값으로 사용한다.
Limitations
- By design, 대부분의 approximate unlearning method들은 pretrained된 정보에 대한 forgetting을 목적으로 하는데 본 benchmark는 finetuning에서 학습한 정보에 대한 forgetting을 측정, 그러나 cheaper, 그리고 큰 크기의 pretrained data가 forget set과 어떻게 연관되어 있는지 살피거나 고려하지 않아도 된다는 장점
- Definition of Unlearning: Entity level Unlearning, 개체 단위로 모든 정보를 잊어버리게 하는 unlearning 알고리즘에 국한됨, 특정 질문에 대한 답만 잊게 하는 instance level unlearning이나, human value와의 alignment를 고려하는 behavior level unlearning에 대해서 적용되지 않는다.
- Gibberish or random words에 대한 높은 forget quality 배정 -> Utility를 함께 고려한다면 식별 가능
- Finetuning 과정이 포함되므로 model parameter에 accessible하지 않은 ICL의 시나리오에서는 적용가능하지 않음 -> 그러나 ICUL 논문에서는 method의 validation을 위해 LLM에 finetuning을 수행함
